
Polina Kirichenko
@polkirichenko
Followers
3,003
Following
1,129
Media
42
Statuses
211
Machine learning researcher; prev. PhD at New York University, Visiting Researcher at @MetaAI FAIR Labs 🇺🇦
New York City, NY
Joined November 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Judge
• 132800 Tweets
Internacional
• 114261 Tweets
Karol G
• 100781 Tweets
Yellowstone
• 99138 Tweets
Carolina
• 62053 Tweets
土用の丑の日
• 50356 Tweets
SUPERPOWER OUT NOW
• 46022 Tweets
デッドプール
• 33279 Tweets
Rosário
• 31427 Tweets
Mets
• 31317 Tweets
#WWENXT
• 28777 Tweets
Saint Dr MSG Insan
• 25463 Tweets
ゲリラ豪雨
• 23294 Tweets
श्री गणेश
• 22214 Tweets
#GiftOfSmile
• 19302 Tweets
Renê
• 17145 Tweets
KIMPAU MovieAnncmnt OnSHOWTIME
• 17036 Tweets
Toy Bank
• 16413 Tweets
#DesafioXX
• 16232 Tweets
Soto
• 16200 Tweets
EFM94 X JAM
• 15917 Tweets
Guru Purnima Celebration
• 15720 Tweets
Vatican
• 15661 Tweets
Skenes
• 13475 Tweets




















Pinned Tweet

I recently defended my PhD thesis and graduated from NYU! 🎉 Thank you so much to my committee members
@andrewgwils
@sainingxie
@mengyer
@Qi_Lei_
@orussakovsky
@rob_fergus
(sadly I forgot to take a common zoom picture)
Happy graduation photos below! 👩🎓


46
4
357
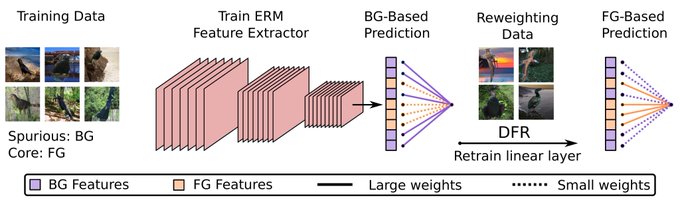
Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations. ERM learns multiple features that can be reweighted for SOTA on spurious correlations, reducing texture bias on ImageNet, & more!
w/
@Pavel_Izmailov
and
@andrewgwils
1/11
13
71
525
Excited to share our
#NeurIPS
paper analyzing the good, the bad and the ugly sides of data augmentation (DA)! DA is crucial for computer vision but can introduce class-level performance disparities. We explain and address these negative effects in: 1/9

4
74
427
Why Normalizing Flows Fail to Detect
Out-of-Distribution Data
We explore the inductive biases of normalizing flows based on coupling layers in the context of OOD detection (1/6)


The inductive biases of normalizing flows can be more of a curse than a blessing. Our new paper, "Why Normalizing Flows Fail to Detect Out-of-Distribution Data", with
@polkirichenko
and
@Pavel_Izmailov
:

5
62
344
1
65
351
Excited to share that
(1) It is my birthday 🎂
(2) We have a new paper "Task-agnostic Continual Learning with Hybrid Probabilistic Models" on arxiv today! We design a hybrid generative-discriminative model based on normalizing flows for continual learning

11
50
343
We are excited to present our breakout session on robustness to distribution shift at
@WiMLworkshop
@icmlconf
together with
@shiorisagawa
@LotfiSanae
! Join our session & discussion tomorrow, Monday July 18, at 11am at the Exhibit Hall G at Level 100 Exhibition Halls 🙂
#ICML2022

1
26
271
We will be presenting "Why Normalizing Flows Fail to Detect Out-of-Distribution Data" at
@NeurIPSConf
tomorrow at 12 EST!
Why Normalizing Flows Fail to Detect
Out-of-Distribution Data
We explore the inductive biases of normalizing flows based on coupling layers in the context of OOD detection (1/6)
1
65
351
1
20
219
Come see our paper "Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations" at
#ICLR2023
(notable-top-25%)! Spotlight talk on Wed 10:10am Oral 6 Track 5 and poster session 6 at 10:30am! (joint work w/
@Pavel_Izmailov
@andrewgwils
)

Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations. ERM learns multiple features that can be reweighted for SOTA on spurious correlations, reducing texture bias on ImageNet, & more!
w/
@Pavel_Izmailov
and
@andrewgwils
1/11
13
71
525
2
28
203
I’m in Baltimore for
#ICML2022
! Really excited to attend the first in-person conference in a few years, connect with people and meet old friends! Ping me if you want to grab coffee or chat about research in deep learning robustness or other topics 🙂

1
8
198
💯 I will add my two cents here as a Russian student on F-1 visa in the US. While a PhD program typically takes 5-6 years (which is also indicated in all the legal documents, school invitation etc), Russian citizens can only get a student F-1 visa for 1 YEAR max!! 🤯😭 1/🧵

Thread:
I live in the US on a work visa. I’m among thousands of Indians unable to see their families because US consulates in India haven’t fully functioned through the pandemic. If I leave the US to see my parents, I won’t be able to return unless I get a consular appointment.
266
2K
9K
3
25
188
Excited to be in New Orleans for
#NeurIPS2022
! Ping me if you want to grab coffee or lunch and chat about distribution shift, robustness, OOD generalization, jazz and other topics! 1/2


5
7
188
Excited to lead a breakout session on Uncertainty in Deep Learning at WiML Un-Workshop
@icmlconf
tomorrow, July 13 at 6:35pm GMT (2:35pm EDT)!
Together with
@MelaniePradier
and Weiwei Pan


1
13
120
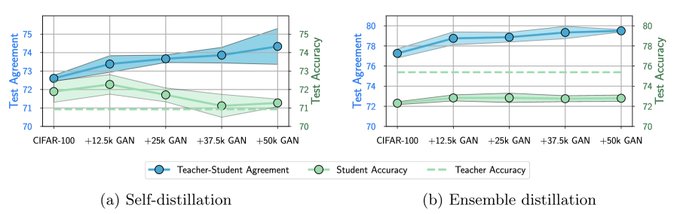
While most papers on knowledge distillation focus on student accuracy, we investigate the agreement between teacher and student networks. Turns out, it is very challenging to match the teacher (even on train data!), despite the student having enough capacity and lots of data.
Does knowledge distillation really work?
While distillation can improve student generalization, we show it is extremely difficult to achieve good agreement between student and teacher.
With
@samscub
,
@Pavel_Izmailov
,
@polkirichenko
, Alex Alemi. 1/10
7
73
344
3
15
118
An image is worth more than one caption!
In our
#ICML2024
paper “Modeling Caption Diversity in Vision-Language Pretraining” we explicitly bake in that observation in our VLM called Llip and condition the visual representations on the latent context.
🧵1/6

5
20
119
We will be presenting "Why Normalizing Flows Fail to Detect Out-of-Distribution Data" tomorrow 1pm EST at the INNF+ workshop
#ICML2020
! Will be very happy to chat about flows and OOD detection :)
Why Normalizing Flows Fail to Detect
Out-of-Distribution Data
We explore the inductive biases of normalizing flows based on coupling layers in the context of OOD detection (1/6)
1
65
351
2
11
117
Happy to share I am presenting on applications of normalizing flows at two
@icmlconf
workshops on Friday! First, I am giving an invited talk at the Workshop on Representation Learning for Finance and e-Commerce at 11:30-12pm EST (already available online)

1
12
103
Carol of the Bells (actually, originally it's a Ukrainian folk song about a bird!). Merry Christmas!🎄
4
3
90
Join our breakout discussion session "Leveraging Large Scale Models for Identifying and Fixing Deep Neural Networks Biases" at
@WiMLworkshop
@icmlconf
tomorrow Friday July 28, 11am in room 316C, with
@megan_richards_
@ReyhaneAskari
@vpacela
@mpezeshki91
!
#ICML2023
@trustworthy_ml

1
15
79
I am presenting a spotlight talk on our paper "Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations" at the
#ICML2022
SCIS workshop ()!
Tmrw 11:40am with poster sessions 1:30 & 5:45pm (rooms 340-342)
w/
@Pavel_Izmailov
&
@andrewgwils
Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations. ERM learns multiple features that can be reweighted for SOTA on spurious correlations, reducing texture bias on ImageNet, & more!
w/
@Pavel_Izmailov
and
@andrewgwils
1/11
13
71
525
0
10
72
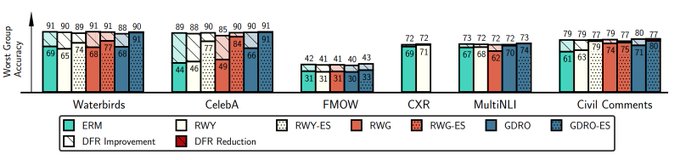
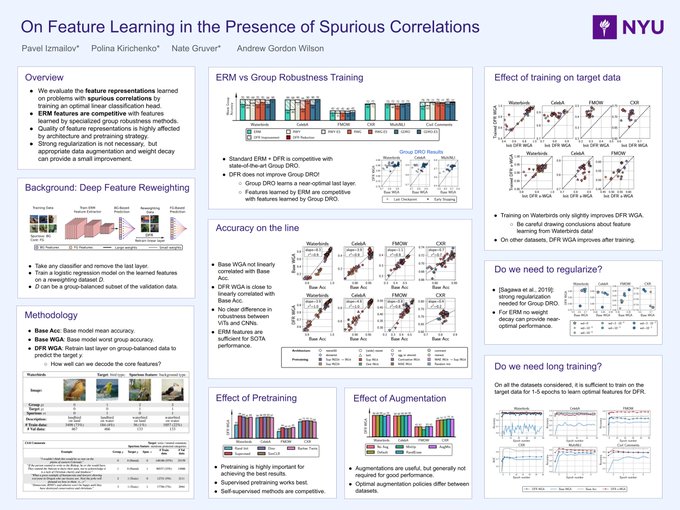
Excited to share our
#NeurIPS2022
paper “On Feature Learning in the Presence of Spurious Correlations”! We show that features learned by ERM are enough for SOTA performance, while group robustness methods are actually not learning better representations.


Spurious features are a major issue for deep learning. Our new
#NeurIPS2022
paper w/
@pol_kirichenko
,
@gruver_nate
and
@andrewgwils
explores the representations trained on data with spurious features with many surprising findings, and SOTA results.
🧵1/6
5
55
327
1
13
73
Very excited to give a talk about our research on normalizing flows at this seminar on 10/21 10am EST!

Are you interested in Normalizing flows?
Feel free to join our online seminar this Wednesday (21/10) at 16:00 CET.
@__DiracDelta
,
@polkirichenko
and
@WehenkelAntoine
will give us a short introduction and present their research.
More info:
3
14
97
0
3
64
Come to our poster on data augmentation biases today at the Poster Session 6 at 5-7pm, poster
#1619
!
#NeurIPS
@trustworthy_ml
Excited to share our
#NeurIPS
paper analyzing the good, the bad and the ugly sides of data augmentation (DA)! DA is crucial for computer vision but can introduce class-level performance disparities. We explain and address these negative effects in: 1/9
4
74
427
2
6
61
Check out this video series on uncertainty in ML! I made a talk on Uncertainty Estimation via Generative Models, and there’s a lot of interesting talks from collaborators covering fundamentals & best practices. Thanks
@AndreyMalinin
for putting this together!

I would like to share our Uncertainty in ML video series which broadly covers range of topics in uncertainty estimation.
Thanks to
@senya_ashuha
@polkirichenko
@DanHendrycks
@provilkov
@LProkhorenkova
@BMlodozeniec
@ekolodin98
for making this possible!

1
22
101
0
5
55
Excited to co-lead this breakout session on uncertainty estimation at WiML Un-Workshop
@icmlconf
! Join us today at 7:25pm ET

Join us July 21 7:25 pm ET at WiML Un-Workshop at
@icmlconf
for a breakout session on "Does your model know what it doesn’t know? Uncertainty estimation and OOD detection in DL"
Together with
@polkirichenko
@AkramiHaleh
@sharonyixuanli
@sergulaydore
0
4
17
0
8
50
Excited to share our
#ICLR2024
work led by
@megan_richards_
on geographical fairness of vision models! 🌍
We show that even the SOTA vision models have large disparities in accuracy between different geographic regions.

Does Progress on Object Recognition Benchmarks Improve Generalization on Crowdsourced, Global Data?
In our
#ICLR2024
paper, we find vast gaps (~40%!) between the field’s progress on ImageNet-based benchmarks and crowdsourced, globally representative data.
w/
@polkirichenko
,

1
0
22
1
5
40
The whole experience is just so frustrating and stressful, and wastes SO much of our time, effort, money and nerves which could've been spent elsewhere. For anyone going through this nonsense: I feel your pain, pls hang in there. 🙏 8/8
4
0
37
Come to our poster presentation on knowledge distillation at
#NeurIPS2021
7:30pm EST! 🙂

We are presenting our paper "Does Knowledge Distillation Really Work?" at
#NeurIPS2021
poster session 2 today - come check it out! Joint work with
@Pavel_Izmailov
,
@polkirichenko
,
@alemi
, and
@andrewgwils
.
Poster:
Paper:

2
14
83
3
6
35
Come see our work "SWALP: Stochastic Weight Averaging in Low-Precision Training" at
@icmlconf
!
Spotlight: 5:05pm in Hall B, poster: 6:30-9pm in Pacific Ballroom
#58
. Joint work with
@YangGuandao
,
@Tianyi_Zh
, Junwen Bai,
@andrewgwils
,
@chrismdesa
.
Paper:

0
10
29
Next, a spotlight talk on our recent paper "Task-agnostic Continual Learning with Hybrid Probabilistic Models" at the INNF+ workshop at 1:20pm EST.
I am very excited for the poster session at INNF+ 1:30-2:30pm EST, please join to discuss generative models & continual learning!

1
4
25
Many of my Russian friends have been stuck in the US for years not being able to see their families or go anywhere abroad. Some of my friends are stuck in Russia not being able go come back to the US to resume their studies and were forced to take leave of absence by schools 7/
1
0
24
At NeurIPS we are presenting "On Feature Learning in the Presence of Spurious Correlations" on Tue Nov 29 and "Chroma-VAE: Mitigating Shortcut Learning with Generative Classifiers" on Thu Dec 1. Come say hi! 🙂 2/2
0
2
24
During my PhD I received tremendous support from my mentors, friends and family — I feel extremely lucky to have such an amazing support system ❤️


1
0
21
I am very grateful to
@andrewgwils
for his advising and support and for many exciting research projects we worked on together! It was a huge privilege to have been a part of Wilson lab and to do my PhD in a great lab environment with incredibly smart and ambitious colleagues!



1
0
19
To this day there is no way to get any US visa type in Russia at all and not clear whether it would be possible to do ever again. Similarly to
@newspaperwallah
story, we have to monitor visa appointment slots in Telegram in other countries and the # of slots is very limited 4/
1
0
19
Due to COVID restrictions there are very few countries where it is allowed to apply as a non-resident. For most of these few countries, ironically, we also need to get a visa to go there which makes the whole process so absurdly complex 🤦♀️5/
1
0
19

I will miss NYU and my colleagues and it feels bittersweet to graduate, but I am excited for what’s coming next!


0
0
18
To make things worse, many of us who work in tech field have to go through additional administrative processing (for no good reason) which currently takes 2-4 months 6/
1
0
16
Surprisingly applying DA only to the classes that benefit from it still doesn’t recover the accuracy on the other 5% of classes 🤔 We analyze the model's predictions as we vary the DA strength, and propose a simple class-conditional DA which addresses class disparities. 3/9
1
1
16
In March 2021 I travelled home to see my family and was lucky to get a visa appointment, but then my F-1 student visa was rejected w/o explanation. A few weeks later, ALL the US embassies in Russia were shut down with no plans for when to reopen 3/
2
0
15
It was manageable before COVID since we travelled home every ~6 months anyway but since the pandemic it has become impossible. In 2020 the US embassy in Moscow operated on minimal capacity and processed only a few (!) applications within a year 2/
1
0
15
The works featured in the talks are:
- semi-supervised learning
- anomaly detection
- continual learning
and a 🧵on the continual learning paper:
Excited to share that
(1) It is my birthday 🎂
(2) We have a new paper "Task-agnostic Continual Learning with Hybrid Probabilistic Models" on arxiv today! We design a hybrid generative-discriminative model based on normalizing flows for continual learning
11
50
343
0
0
14
Come to our poster at NeurIPS!
W/ amazing co-authors
@randall_balestr
Mark Ibarhim
@D_Bouchacourt
@rama_vedantam
@mamhamed
@andrewgwils
And check out Randall’s thread too!
9/9

Excited to share our
#NeurIPS2023
paper explaining part of the per-class accuracy degradation that data augmentation introduces: it creates asymmetric label-noise between coarse/fine classes of the same object e.g. car and wheel! We also find a remedy⬇️

1
12
82
2
1
15
Come talk to us about spurious correlations robustness today at 4-6pm in Hall J 103!
#NeurIPS2022

We will be presenting "On Feature Learning in the Presence of Spurious Correlations" today (Nov 29) at
#NeurIPS2022
w/
@polkirichenko
@gruver_nate
@andrewgwils
!
Hall J
#103
, 4-6 pm
Paper:
4
4
25
0
1
14
Using multi-label annotations on ImageNet we found that often class accuracy drops with strong DA are explained by label noise & ambiguity, e.g. the multi-label annotation accuracy on class “barn spider” is improving with stronger DA, while the original accuracy drops by 15%. 4/9

1
2
15
We can help flows focus on semantic content of the data by training them on embeddings extracted by a neural net. Here we use embeddings from EfficientNet trained on ImageNet and get much better OOD detection compared to raw pixels. (5/6)

1
0
13
Several works (incl ) found strong DA is not beneficial for all classes: while the accuracy improves on the majority of ImageNet classes, it drops by as much as 20% on some of them! Check out
@ylecun
thread for more details! 2/9


New paper:
"The Effects of Regularization and Data Augmentation are Class Dependent"
by Randall Balestriero, Leon Bottou, Yann LeCun
TL;DR: Turns out some types of data augmentation helps some categories and hurt others...

10
104
484
1
1
14
We can change the architecture of the flows to change the inductive biases and improve OOD performance. Here we use auto-encoder-like networks in each coupling layer and with smaller bottlenecks we get better OOD detection. (4/6)

1
0
12
For flows, there exists a correspondence between the coordinates in an image and in its learned representation. We can recognize edges of the inputs in their latent representations. Flows do not represent images based on their semantic contents. (2/6)

3
0
11
On Waterbirds data where the background (BG) is a spurious feature, DNNs perform poorly on images with confusing BGs. However, if we remove the BG at test time, the same model performs close to optimally indicating that it learned the foreground features well.
3/11

1
1
10
Often class-level accuracy, e.g. for "wheel" class, drops as it gets confused with another related class, e.g. "car", which is captured by false negative mistakes for "wheels" and false positives for "cars". But to recover "wheel" accuracy we should reduce DA for "cars"! 7/9

1
0
11
Inspired by these results, we propose Deep Feature Reweighting (DFR), a simple and effective method for robustness to spurious correlations: we train a feature extractor with ERM, and retrain the last layer on reweighting data where the spurious feature is not predictive.
6/11
1
0
9
By accounting for the trade-off between class-level false positive and negative mistakes, we can change augmentation policy for a small number (1-5%) of classes to improve the accuracy on the negatively affected classes and reduce disparities! 8/9

1
1
10
A huge shoutout to
@gruver_nate
who will be presenting the talk and poster in person since unfortunately I couldn't travel due to immigration constraints 🙏
0
0
9
We show how exactly flow coupling layers can increase likelihoods for both labeled and unlabeled data: (1) leveraging local correlations and (2) coupling layer co-adaptation. (3/6)

1
0
9
Looking at the models predictions on the affected classes revealed that the mistakes are systematic and models often confuse very related or ambiguous categories, e.g. the reduced accuracy on class “sunglass” is due to the model becoming biased to predict “sunglasses”! 5/9

1
1
9
0
0
8
We categorized the confusion types that get exacerbated with augmentations into ambiguous, co-occurring, fine-grained and semantically unrelated, based on their semantic similarity and overlap in multi-label annotations. 6/9

1
1
9
Moreover, by retraining the last layer of a ResNet or ViT on the stylized ImageNet data we can significantly reduce their texture bias and improve the performance under certain types of covariate shift!
9/11

1
0
8
In short, DFR is extremely easy to implement, significantly improves robustness to spurious correlations, and has almost no computational overhead. Please see the paper for more experiments and details!
Code is available: .
11/11
3
1
8
Prior work often associated poor robustness to spurious correlations with the quality of representations. We present a different view: representations learned with standard ERM are sufficient to achieve state-of-the-art results on popular spurious correlation benchmarks!
2/11
1
0
8
Finally, HCL enables us to automatically detect new tasks as well as recurring tasks! To do so we can use the normalizing flow likelihood, or an advanced anomaly detection technique such as DoSE ().
1
1
8
We can also apply DFR to cheaply fix the biases of large-scale models such as BG-reliance. Here, by retraining the last layer of a ResNet trained on ImageNet, we significantly improve performance on images with confusing backgrounds.
8/11

1
0
7
Recent work () showed that DNNs suffer from extreme simplicity bias: on datasets where the spurious feature is much simpler than the core feature (e.g. MNIST vs CIFAR), DNNs completely ignore the core feature in their predictions.
4/11

1
1
7
We provide insights into the effects of pre-training, data augmentation, architecture and regularization on the feature quality. One of the exciting results is the “accuracy on the line” effect: models w/ better average accuracy learn better core features!

1
0
7
We show that even in these challenging scenarios, DNNs often still learn a high quality representation of the core feature, which can be decoded to make accurate predictions on the minority groups, where the core and spurious features contradict each other.
5/11

1
1
7
With a great team of coauthors at
@DeepMind
@GoogleAI
and
@NYUDataScience
:
@MFarajtabar
,
@drao64
,
@balajiln
, Nir Levine,
@__angli
, Huiyi Hu,
@andrewgwils
and
@rpascanu
!
0
0
7
Oops wrong link! The code can be found here:

0
0
6
In task-agnostic continual learning, we need to train the model continually on a sequence of tasks without knowing the task boundaries. Turns out, we can use a single hybrid model to (1) detect task changes, (2) avoid forgetting and (3) make predictions!
1
0
6
@tdietterich
@Pavel_Izmailov
@andrewgwils
ERM is now common terminology for standard training in the robustness & domain generalization literature to make a distinction with methods like IRM () or GDRO (), which are optimizing a different loss function, not standard risk.
1
0
6
Many more results in the paper incld analysis of representations and adding image patch tokens to the contextualization. See a thread from Sam who led the effort!
Together w/
@lavoiems
@marksibrahim
@mido_assran
@andrewgwils
@AaronCourville
Nicolas Ballas


1
0
6
The discussion will be in the un-workshop format so please submit the questions and topics within this area you would like to discuss. :)

0
0
5
Llip achieves SOTA performance across downstream vision and vision-language tasks, outperforming recent MetaCLIP and SigLIP when fixing the dataset. Given a fixed compute budget, it’s better to contextualize vision representations in the VLMs!
5/6

1
0
4
See paper for many more results!
Huge thanks to my co-authors
@Pavel_Izmailov
,
@gruver_nate
and
@andrewgwils
🙂
1
0
5
To avoid forgetting, we propose two techniques:
- HCL-GR uses generative replay, where we sample data from a snapshot of the model and re-train the model on this data
- HCL-FR uses functional regularization, where we force the model to map replay data to the same latent position

1
0
5
We compare HCL variants with other generative continual learning models, with promising results. HCL performs well both in task-aware and task-agnostic settings!


1
0
4
We evaluate features by retraining the last layer of the models on group-balanced data to decouple the quality of feature extractor vs linear classifier, following . ERM is on par with SOTA Group DRO in terms of worst-group acc after last layer retraining!

1
0
4
If you’re at ICLR check out Megan’s poster on Friday!
Come chat at our poster, Friday 10:45am, Halle B Poster
#213
! :) And see our full paper here: .

1
0
8
0
0
4
We propose HCL, which uses a single normalizing flow to map the data into a latent space where we model the distribution of each class in each task as a Gaussian. When a new task appears we (1) identify it using the flow and (2) initialize the latent Gaussians for the new task.
1
0
4
We propose a simple contextualization approach: we add additional CLS tokens to the vision encoder and cross-attend with the text representation to get the conditioned visual feature vector. The same image results in different visual representations depending on the caption!
2/6

1
0
4
Recently there has been a lot of exciting research on leveraging generative and open-world large-scale models for detecting failure modes and debiasing other models. We invite attendees to discuss opportunities and challenges of such approaches and brainstorm new ideas!
1
0
4
DFR achieves very strong results, matching or outperforming state-of-the-art baselines (Group-DRO, SSA) both when group labels are available on train, and when they are only available on a small validation set.
7/11

1
0
4
DFR can be applied to improve robustness of already trained DNNs which makes it very convenient in practice. We run DFR on ImageNet in a matter of minutes on one GPU. Moreover, DFR only has one hyperparameter and is robust to the base feature extractor hyperparameters.
10/11
1
0
4
@ericjang11
@andrewgwils
@Pavel_Izmailov
I'll have to read more about the VIB objectives, but I think latent variable models are indeed promising for OOD detection. In the paper we are not advocating for using flows or proposing a specialized R-NVP as a new method, it's more about understanding the problem :)
1
0
3
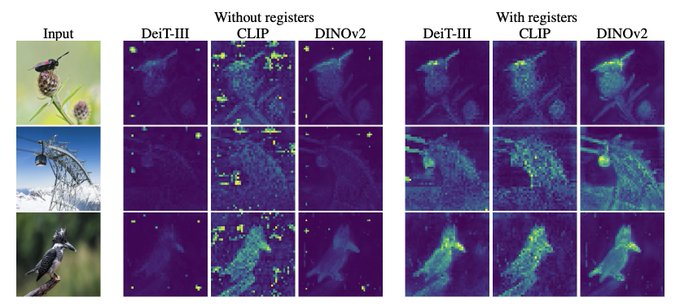
Using additional learnable tokens in ViTs (called registers) was also discussed in the recent paper by
@TimDarcet
et al for improving interpretability of ViT attention maps, but they don’t use the registers for computing the visual representation.
3/6

Vision transformers need registers!
Or at least, it seems they 𝘸𝘢𝘯𝘵 some…
ViTs have artifacts in attention maps. It’s due to the model using these patches as “registers”.
Just add new tokens (“[reg]”):
- no artifacts
- interpretable attention maps 🦖
- improved performances!
43
327
2K
1
0
3
To make predictions, we use the Bayes rule: we predict the class (and task) for which the input has the highest density.
1
0
3
We find that there is a lot of benefit in using the registers' outputs — even a simple non-contextualized average of registers boosts performance (see +Average) but we get the best results with using registers + conditioning on the caption context (see Llip64)!
4/6

1
0
3
HCL-FR provides stronger regularization and prevents forgetting better! In the figure: (b) data distribution with squares showing our replay data; grey is the first and orange is the second task; (c) HCL-GR model and (d) HCL-FR model after training on the second task.

1
0
3
@KateLobacheva
was my mentor during my undergrad, and she's always been an inspiration for me! Check out a new cool paper on deep ensembles from her and other collaborators from
@bayesgroup
:)

Our paper “On Power Laws in Deep Ensembles” has been accepted to
#NeurIPS
as a spotlight! Thanks to my co-authors
@nadiinchi
, Maxim Kodryan, Dmitry Vetrov and to all
@bayesgroup
Paper:
2
8
49
0
0
3
@serrjoa
@andrewgwils
@ericjang11
@Pavel_Izmailov
Hi Joan, we read your paper and connect our observations to your work in sec. 6 :)
1
0
2
@senya_ashuha
@IsomorphicLabs
@maxjaderberg
@wojczarnecki
@SergeiIakhnin
@demishassabis
Congrats Arsenii! 🎉 🥳
0
0
2
@tarantulae
@Pavel_Izmailov
@tdietterich
@andrewgwils
They are quite different. We show that standard ERM learns the core features even when it relies on the spurious features. By retraining just the last layer, we are able to remove the reliance on spurious features in ERM-trained models... 1/2
1
0
2
We use geographically diverse datasets DollarStreet and GeoDE to evaluate models and find that the improvements on ImageNet don’t help and even *exacerbate* the geo disparities: the accuracy gaps between best- and worst-performing regions tripled as we improved ImageNet accuracy!

1
0
2
Model and (web crawled) data scaling are insufficient for robustness to real-world distribution shifts -- we need *representative and curated* training data! We show that lightweight fine-tuning on diverse data can improve generalization and reduce disparities on ID and OOD data.

1
0
2
0
0
2
@ericjang11
@andrewgwils
@Pavel_Izmailov
The experiments in sec. 7 where we change masking and coupling layer networks are aimed at understanding what goes wrong in regular flows, not proposed as a solution
0
0
2
0
0
1
@tomgoldsteincs
I'm super late to the party, but just saw this paper , and it sounds very relevant!

Our paper 'Proper Reuse of Image Classification Features Improves Object Detection'
#backbone_reuse
(with
@viggiebirodkar
and
@dumoulinv
) , will be present at CVPR 2022 as an Oral presentation on June 23. You can check it on
6
7
38
0
0
1