
Roberta Raileanu
@robertarail
Followers
5K
Following
4K
Media
43
Statuses
1K
Research Scientist @Meta & Honorary Lecturer @UCL. Llama Tool Use Lead. ex @DeepMind | @MSFTResearch | @NYU | @Princeton. Llama-3, Toolformer, Rainbow Teaming.
London, UK
Joined April 2013
It really takes a village…of Llama herders 🦙🦙🦙. Working on this has been an absolute privilege. Special shoutout to @mialon_gregoire and @sharathraparthy who worked tirelessly to bring tool use capabilities to Llama-3.1!!.

Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet. Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context
5
3
60
I’m looking for a PhD intern for next year to work at the intersection of LLM-based agents and open-ended learning, part of the Llama Research Team in London. If interested please send me an email with a short paragraph with some research ideas and apply at the link below.
11
106
583
Jakob Foerster (@j_foerst) and I are hiring a PhD student for our FAIR-Oxford program to work at the intersection of language and RL. The student will spend 50% of their time @UniofOxford and 50% @MetaAI (FAIR), while completing a DPhil (Oxford PhD). Deadline: 1st of March.
13
78
364
Our group has multiple openings for internships at FAIR London (@MetaAI). I’m looking for someone to work on language models + decision making e.g. augmenting LMs with actions / tools / goals, interactive / open-ended learning for LMs, or RLHF. Apply at
10
67
336
Super excited to start as a Research Scientist at FAIR London today! . I’m looking for an intern for 2022, so if you’re interested in generalization and representation in RL, unsupervised or continual RL, consider applying via
22
15
331
My team is hiring interns to work on LLMs (part of Meta’s GenAI research lab):. If you’re interested in working together on augmenting LLMs with tools and decision making abilities, or open-ended and continual learning for LLMs, consider applying and don’t.
6
42
277
Excited to share our new paper “Automatic Data Augmentation for Generalization in Deep Reinforcement Learning” w/ @maxagoldstein8, @denisyarats, @ikostrikov, and @rob_fergus!. Paper: Code: Website:
2
49
218
Excited to share our @iclr_conf 2020 paper “RIDE: Rewarding Impact-Driven Exploration For Procedurally-Generated Environments”: w/ @_rockt at @facebookai! Code available at 1/5



5
37
181
Our FAIR London team is hiring multiple Research Scientists to work on tool-augmented LLMs!. Apply here if interested:.
4
45
173
Struggling to keep up with all the recent papers on Augmented Language Models?. Check out our new survey on augmenting LLMs with reasoning, acting, and tool use.


2
25
146
CSP: our new algorithm for scalable continual reinforcement learning. CSP allows users to control the trade-off between performance and model size by adaptively learning a subspace of policies. SOTA on Continual World and Brax. Interactive Website:

An agent able to tackle a sequence of tasks, without forgetting, while keeping a reasonable model size: this is what we propose with Continual Subspace of Policies (CSP) 1/6
1
6
101
I’ll be #NeurIPS2023 from Tues evening until Sat. Look forward to meeting old friends and making new ones. Let me know if you want to chat about:.- augmenting LLMs with tools and decision-making.- open-ended and continual learning with / for LLMs. Here’s where you can find me:.
1
7
100
🚨 New paper 🚨 on teaching LLMs to reason with RL!. 🔎 We find that expert iteration (aka iterative rejection sampling) is a strong baseline, matching PPO's asymptotic performance and sample efficiency. 🙌 Kudos to @Dahoas1 who is a super productive researcher and produced not.

🚨🚨🚨Paper #2 from my time at Meta!.In this work, we set out to understand how different algorithms fare at improving LLM reasoning from feedback. We compare expert iteration, PPO, and return-conditioned RL using Llama-2 as the base model.

0
20
97
I’ll be at #NeurIPS2022 next week and would love to chat about RL, generalization, exploration, or its interaction with language. I’ll be presenting the following papers together with my co-authors:.
1
9
91
Can LLaMA-2 teach agents to play NetHack?. 🤖 Our new method, Motif, helps agents explore vast open-ended environments by distilling an LLM’s prior knowledge of the world. 🕹️ Motif learns an intrinsic reward model using LLM feedback over caption pairs, which is then used to.

Can reinforcement learning from AI feedback unlock new capabilities in AI agents?. Introducing Motif, an LLM-powered method for intrinsic motivation from AI feedback. Motif extracts reward functions from Llama 2's preferences and uses them to train agents with reinforcement
2
14
88
Delighted to give a 𝘀𝗽𝗼𝘁𝗹𝗶𝗴𝗵𝘁 talk about our work at the 𝘐𝘯𝘥𝘶𝘤𝘵𝘪𝘷𝘦 𝘉𝘪𝘢𝘴𝘦𝘴, 𝘐𝘯𝘷𝘢𝘳𝘪𝘢𝘯𝘤𝘦𝘴, 𝘢𝘯𝘥 𝘎𝘦𝘯𝘦𝘳𝘢𝘭𝘪𝘻𝘢𝘵𝘪𝘰𝘯 𝘪𝘯 𝘙𝘓 workshop #ICML2020 on Sat at 12:50pm UTC, followed by a poster session at 1:15pm UTC.
Excited to share our new paper “Automatic Data Augmentation for Generalization in Deep Reinforcement Learning” w/ @maxagoldstein8, @denisyarats, @ikostrikov, and @rob_fergus!. Paper: Code: Website:
1
12
78
Meet Toolformer, a language model that learns to use tools via self-supervision. At test time, Toolformer decides what tool to use and how based on the context, without any additional prompting or finetuning. If you’re interested in this area, we’re hiring interns!.

🎉 New paper 🎉 Introducing the Toolformer, a language model that teaches itself to use various tools in a self-supervised way. This significantly improves zero-shot performance and enables it to outperform much larger models. 🧰. 🔗 Link:
2
11
79
🚨 Introducing ToolVerifier, our new method for generalization to new tools. 🚀 ToolVerifier outperforms GPT-4 on some tasks despite being based on Llama-2 70b. 🤖 Key ideas: .- fine-tune on synthetically generated data for tool use with reasoning traces .- self-verification.

🚨New paper!🚨 .ToolVerifier. - Method to generalize to new tools .- Self-asks contrastive questions to select between best tools and parameter choices.- Fine-tuned on self-built synthetic data.- 22% performance improvement over few-shot baseline.🧵(1/4)

0
13
76
🚨 We’re organizing a new #ICLR2024 workshop on Generative AI for Decision Making and submissions are open!. 🤖 The combination of Generative AI and Decision Making is emerging as one of the most promising paths towards generally capable agents, allowing.

🚨 The call for papers for our #ICLR2024 workshop on Generative AI for Decision Making is out! 🚨. We welcome both short (4 pages) and full (9 pages) technical or positional papers. Details: 1/3.
0
16
70
Super excited to join @UCL_DARK and get the chance to work (even more) closely with this very talented group!! 🚀.

We are super excited to announce that Dr Roberta Raileanu (@robertarail) and Dr Jack Parker-Holder (@jparkerholder) have joined @UCL_DARK as Honorary Lecturers! Both have done impressive work in Reinforcement Learning and Open-Endedness, and our lab is lucky to get their support.

5
2
71
I’ll be at #ICLR2024 on Saturday for the LLM Agents Workshop Panel 🚀. Some of my collaborators will also be there throughout the week presenting our work on:.- how RLHF affects LLM generalisation and diversity with @_robertkirk.- training NetHack agents using LLM feedback with

3
9
70
🤖 Want an agent that can learn new tasks from only a handful of demonstrations and no weight updates?. 🚀 Check out our new work on In-Context Learning for Sequential Decision-Making, where we show how we can use transformers to few-shot learn new Procgen and MiniHack tasks. 👋.

🚨 🚨 !!New Paper Alert!! 🚨 🚨. How can we train agents that learn new tasks (with different states, actions, dynamics and reward functions) from only a few demonstrations and no weight updates?. In-context learning to the rescue!. In our new paper, we show that by training
0
11
70
Our work on “Decoupling Value and Policy for Generalization in Reinforcement Learning” w/ @rob_fergus will be presented as a long talk @icmlconf 2021. Come check it out in Poster Session 1 (Tuesday, 12 - 2pm ET / 5 - 7pm BST):

1
16
66
Happy to finally release our work on “Fast Adaptation via Policy-Dynamics Value Functions” w/ @maxagoldstein8, Arthur Szlam, and @rob_fergus, which will be presented at #icml2020!. Paper: Code: Website:
1
17
65
Very cool work on unsupervised environment design! I really like the idea of an interactive demo where you can test agents on different environments in real time! I hope more RL papers will adopt this in the future, particularly if the focus is on generalization or robustness.

Evolving Curricula with Regret-Based Environment Design. Website: Paper: TL;DR: We introduce a new open-ended RL algorithm that produces complex levels and a robust agent that can solve them (e.g. below). Highlights ⬇️! [1/N]
1
9
56
Check out @RL_Conference's Outstanding Paper Awards and the blog post on the process we used to decide. We awarded 7 papers that excel in one of the following aspects: .- Applications of Reinforcement Learning.- Empirical Reinforcement Learning Research.- Empirical.

In case you are not attending the @RL_Conference this year (I'm really sorry for you), @robertarail and I announced the list of RLC's Oustanding Paper Awards this year. If want to know the awarded papers, or the process we followed, read this piece:
0
8
59
🏆 Synthetic data generation is the new holy grail of AI. But ensuring the data is high-quality, interesting, and useful is non-trivial. 🤖 Our new method, Source2Synth provides a way of automatically generating and curating training examples (with and for LLMs 🦙) grounded in.
🚨New paper: Source2Synth🚨.- Generates synthetic examples grounded in real data .- Curation step makes data high quality based on answerability.- Improves performance on two challenging domains: Multi-hop QA and using tools: SQL for tabular QA .🧵(1/4)

2
6
55
Can’t wait to see what you all build with Llama 3, the best openly available LLM!. Enjoy and stay tuned for more🦙🦙🦙.

Excited to share a preview of Llama3, including the release of an 8B and 70B (82 MMLU, should be the best open weights model!), and preliminary results for a 405B model (still training, but already competitive with GPT4). Lots more still to come.
1
3
53
Very excited our workshop on Agent Learning in Open-Endedness (ALOE) was accepted at #ICLR2022! Look forward to bringing together a diverse community to discuss how we can create more open-ended learning systems.

Announcing the first Agent Learning in Open-Endedness (ALOE) Workshop at #ICLR2022! . We're calling for papers across many fields: If you work on open-ended learning, consider submitting. Paper deadline is February 25, 2022, AoE.

0
5
52
CSP accepted as spotlight at #ICLR2023. Kudos to @jb_gaya who led this project and to all the other wonderful co-authors @doan_tl @LucasPCaccia @LaureSoulier @LudovicDenoyer.
CSP: our new algorithm for scalable continual reinforcement learning. CSP allows users to control the trade-off between performance and model size by adaptively learning a subspace of policies. SOTA on Continual World and Brax. Interactive Website:
4
10
49
Check out our new #ICML paper on “Hyperparameters in RL and How to Tune Them”, led by @The_Eimer who did an amazing job!. We recommend a set of best practices for reporting HP tuning in RL, which we hope will result in better reproducibility and more fair comparisons.

No one likes fiddling with hyperparameters (HPs), especially in RL - but you don’t have to!.Our #ICML paper shows that HP optimization methods outperform 10x more compute-expensive hand tuning - and that underreporting is a reproducibility hazard. 🧵:


1
6
49
A very thorough, insightful, and much needed survey on generalization in deep RL!.

I'm very excited to share a Survey of Generalisation in Deep Reinforcement Learning (, written with @yayitsamyzhang, @egrefen and @_rockt. Curious about generalisation in RL? Then this is the survey for you! Here's a thread giving a quick overview.

0
3
48
New approach for exploration in procedurally generated environments with sparse reward! AMIGo learns to set and achieve increasingly more challenging goals, leading to SOTA performance on MiniGrid.

Got a complicated RL exploration problem? Sparse/no reward? It's dangerous to go alone: bring an AMIGo! This thread introduces work done by Andres Campero, with @robertarail, Josh B. Tenenbaum, @HeinrichKuttler, @_rockt and me during Andres' internship at FAIR London. [1/5]

0
7
47
We started this work back in 2022 with @sharathraparthy and @HenaffMikael when transformers only had 4k context length 😱. This was one of the main bottlenecks in extending our method to longer-horizon tasks like NetHack 👾 or Minecraft 🤖. I’m excited to see what can be achieved.

Fantastic keynote talk by @robertarail at the AutoRL workshop on achieving in-context learning for complex environments like @NetHack_LE / MiniHack and ProcGen. At current rate, I believe we'll see an in-context NetHack agent soon that can in-context imitate from expert play.

1
8
46
🚨 New Paper 🚨. 📜 We study the effects of RLHF on the generalization and diversity of LLMs. - RLHF results in much better OOD generalization than SFT . - RLHF leads to lower output diversity compared to SFT . kudos to @_robertkirk who did an outstanding job leading this work!👇.
Excited to share work from my FAIR internship on understanding the effects of RLHF on LLM generalisation and diversity:. While RLHF outperforms SFT in-distribution and OOD, this comes at the cost of a big drop in output diversity!. Read more below🧵

0
8
47
🚨 Wondering when, where and how to improve your LLM’s reasoning?. 🤖 Look no further! Our new method GLoRe shows how you can do just that. ⏲️ When? Use an outcome-based reward model (ORM) to decide which solutions need refinement. 🎯 Where? Use a step-wise ORM (SORM) to decide.
New paper alert🚨🚨🚨.How to bootstrap the reasoning refinement capabilities of LLMs using synthetic data? Introducing "GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements". Applied on GSM8K we can improve a strong RL finetuned LLama-2 13B by 12%

0
11
46
📢 Check out our new survey on current challenges and applications of LLMs!. There is still plenty to understand, improve, and build, so we hope this survey will lower the barrier for newcomers, researchers, and practitioners to help advance the field.

(1) LLMs are ubiquitous, but what are the challenges requiring further research and in where have LLMs successfully been applied?. In our new paper, Challenges and Applications of Large Language Models, we answer these questions comprehensively. 📚:

1
7
45
NetHack is a great environment for driving research on exploration, planning, transfer, generalization, and many other key RL problems! Very curious to see what insights it will inspire.
Want to help push the boundaries of RL research? Need a rich, difficult, and procedurally-generated environment with loads of structure and intricacy? An astounding amount of human play data? Sophisticated strategies and documentation? We got you (and it's faster than ALE!) [1/6]

1
5
42
Want agents that effectively explore varying environments with high-dimensional observations or huge state spaces? . Check out E3B: Exploration via Elliptical Episodic Bonuses, which achieves a new SOTA on Habitat and MiniHack. Fantastic work led by @MikaelHenaff!.

Excited to share our @NeurIPSConf paper where we propose E3B--a new algorithm for exploration in varying environments. Paper: Website: E3B sets new SOTA for both MiniHack and reward-free exploration on Habitat. A thread [1/N]
0
7
44
In our paper led by @ishitamed ( to be presented #ICLR2024), we found that online RL generalizes much better than offline learning methods (including decision transformers, behavioral cloning, and offline RL), on both Procgen an WebShop. But we were.

What if I told you that there were a combinatorial number of tasks that Decision Transformer like methods overlook? Excited to share our paper which unwraps this by linking trajectory stitching to combinatorial generalization, leading to a practical data augmentation method.
1
6
43
We'll be presenting our work on solving hard exploration tasks via quasi-adversarial intrinsic goals at #ICLR2021 during poster session 2 on Monday. Led by Andres Campero, joint with @HeinrichKuttler, Josh Tenenbaum, @_rockt, and @egrefen.
“Going” to ICLR on Monday? Be sure to “stop by” our poster during session 2. We present a new near-adversarial metalearning-inspired method for structuring exploration in RL by modelling the boundary of the agent’s abilities. Easy to add to your agent!.

1
7
41
Excited to talk about how we can build more general and robust agents at the @AutoRL_Workshop #ICML2024. I'll be discussing the advantages and limitations of using offline methods for learning sequential decision making tasks, such as in-context learning with transformers or.

Up next: Jack Parker-Holder @jparkerholder works on open-endedness as a research scientist at @GoogleDeepMind and honorary lecturer with @UCL_DARK . His focus is on unlimited training data for open-ended RL - being able to generate interactive tasks controllably and at will 🔮.
2
5
40
📢 @UCL_DARK has a few open PhD positions starting next year. If you’re interested in working with us on agents capable of robust decision making and open-ended learning consider applying!.
We (@_rockt, @egrefen, @robertarail, and @jparkerholder) are looking for PhD students to join us in Fall 2024. If you are interested in Open-Endedness, RL & Foundation Models, then apply here: and also write us at ucl-dark-admissions@googlegroups.com.
1
8
40
Thanks @tafm_rlc for organizing an excellent workshop at the @RL_Conference! . I deeply enjoyed the diversity of the posters and talks, debating the future of foundation models and agency with @criticalneuro and @MichaelD1729 (where we all seemed to agree that as a community we.
1
8
38
Had a great time speaking about learning behaviors from large-scale datasets #GameAISchool2022. More details about this work coming out soon.

The fourth day of #GameAISchool2022 kicks off with @robertarail giving a very interesting talk about learning behavior from large-scale datasets, and in particular the @NetHack_LE. I think large-scale imitation learning will be very important to the future of games.

0
4
36
We’re trying something different for the paper awards at the @RL_Conference. Instead of awarding papers for being the overall “best”, we award them for making significant contributions to specific aspects of research, aiming to promote more diverse contributions.
Roberta (@robertarail) and I came up with a different proposal on how to do paper awards. This is what @RL_Conference will do this year. The idea is to award papers for excelling in what they aim to accomplish. If you want to know more, take a look at the blog post we wrote.
0
1
36
If you work on generalization in sequential decision making, reinforcement learning, or planning, consider submitting your work at this #NeurIPS2023 workshop👇.

10 days left to submit your work to #NeurIPS2023 Workshop on Generalization in Planning. We have an exciting speaker lineup: .@FeryalMP, Giuseppe De Giacomo, Hector Geffner, @robertarail, @PeterStone_TX, @yayitsamyzhang . CFP and more info available at

0
3
34
In our new paper led by @yidingjiang, we highlight the importance of exploration for generalization to new environments. Encouraging the agent to visit states with high epistemic uncertainty results in EDE, the first value-based method to achieve SOTA on Procgen and Crafter.

An agent is unlikely to be tested in the exact same environment it’s trained in. In our new work with @zicokolter and @robertarail, we show that exploration during training plays a crucial role in zero-shot generalization to new environments. 🧵 1/.

0
4
35
Thanks @arankomatsuzaki for highlighting our work!. These insights inspired us to develop GLoRe, a new method for refining LLM reasoning using synthetic data:

Meta presents: Teaching Large Language Models to Reason with Reinforcement Learning. Finds the sample complexity of Expert Iteration is similar to that of PPO and performs the best among all algorithms.

0
6
34
Had a blast presenting at the @AutoRL_Workshop #ICML2024, thanks to the organizers and attendees for all the insightful questions!.
Fantastic keynote talk by @robertarail at the AutoRL workshop on achieving in-context learning for complex environments like @NetHack_LE / MiniHack and ProcGen. At current rate, I believe we'll see an in-context NetHack agent soon that can in-context imitate from expert play.
2
2
33
Enjoy our early Christmas gift 🦙🦙🦙. Great to see small open-source models catching up with large proprietary ones 🚀🚀🚀.

Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques including online preference optimization, this model improves core performance at

1
2
34
Had a great time chatting about generalization in RL with Wendelin Böhmer, Cheng Zhang, Harm van Seijen, and Mingfei Sun at the Microsoft Research Summit! Thanks @MSFTResearch for organizing this! You can watch the discussion in the RL - Part 2 track:
0
5
33
Check out our new ICLR paper on MAESTRO led by @_samvelyan. MAESTRO trains robust agents for zero-sum two-player games by generating joint auto-curricula over both environments and co-players.

I’m excited to share our latest #ICLR2023 paper . 🏎️ MAESTRO: Open-Ended Environment Design for Multi-Agent Reinforcement Learning 🏎. Paper: .Website: . Highlights: 👇
0
5
34
Interested in AI and Games and wouldn’t mind spending a week in Greece learning about it? Come join us then!.

One week left of EarlyBird! #GameAISchool Aug29-Sept2 organized by @modl_ai with industry experts from @MSFTResearch @seed @AskBLU_ai @MetaAI @GoogleAI @UbiMassive @Sony and more!.@DominiqueBusso @GalaxyKate @smdvln @l_gisslen @robertarail @RenaudieDavid .
0
4
33
Had a blast debating the future of LLM agents with such legends in the field and hearing everyone’s insights on this timely topic! . Thanks @llmagentsworkshop for the invite and for putting together an excellent workshop 🙏.


1
1
33
Training action-conditioned video generation models is a great feat. Even more impressive to do this fully unsupervised. This paves the way for so many exciting research directions and applications. Can't wait to see such neural simulators being used to train robots or other.
I am really excited to reveal what @GoogleDeepMind's Open Endedness Team has been up to 🚀. We introduce Genie 🧞, a foundation world model trained exclusively from Internet videos that can generate an endless variety of action-controllable 2D worlds given image prompts.
1
4
31
Excited to talk about generalization in RL @ICComputing this week!.

Next seminar coming! 🥳🥳26th of May at 17:00 (UK) we are exited to have @robertarail 🤗from @MetaAI as our next invited speaker to tell us about her latest research on generalisation in deep reinforcement learning @imperialcollege Huxley 308 @ICComputing.
1
4
32
Inspiring talk from @katjahofmann on how we can empower game creators with learned action and world models! The video game generation results look very impressive! At the GenAI for Decision Making workshop #ICLR2024

0
3
32
🚨 DreamCraft 🚨. Ever wanted to generate MineCraft ⛏️💎🏡 structures by simply describing them in natural language? . Our new method DreamCraft does just this using quantized NeRFs 🔥 . DreamCraft can also be combined with functional constraints to ensure the generated 3D.

We introduce DreamCraft 🗣️🧱⛏️, a NeRF-based method for generating MineCraft structures from free-form text prompts. Work with @filippos_kok, @NieYuhe, @togelius and @robertarail at FDG 2024. 📜 E.g.,. "large medieval ship". "old wizard's tree mansion"


0
4
30
Nice idea on using LLMs to inject human priors into the exploration of RL agents. This biases exploration towards behaviors and tasks that humans care about. Could be particularly useful for open-ended environments with large state spaces like NetHack or MineCraft.

How can we encourage RL agents to explore human-meaningful behaviors *without* a human in the loop?. @OliviaGWatkins2 and I are excited to share “Guiding Pretraining in Reinforcement Learning with LLMs”! . 📜🧵1/
0
2
31
Curious how RLHF and SFT compare in terms of OOD generalization and diversity?. Check out @_robertkirk's talk at @itif_workshop workshop at 4pm and our poster at 1pm - 2pm! Room 220 - 222 #NeurIPS2023.
Excited to share work from my FAIR internship on understanding the effects of RLHF on LLM generalisation and diversity:. While RLHF outperforms SFT in-distribution and OOD, this comes at the cost of a big drop in output diversity!. Read more below🧵
1
5
31
Rainbow Teaming poster getting crowded. Come hear @sharathraparthy and @_andreilupu explaining how we can use open-ended learning methods like quality-diversity to generate endless adversarial prompts for LLMs and make them more robust in the process 🌈🌈🌈

@_andreilupu @robertarail and I are presenting Rainbow Teaming 🌈 at Set LLM workshop. Location - Schubert 5. Come chat with us!.
2
5
31
If you’re at #NeurIPS2024 and interested in open-endedness, self-improvement, or LLM safety and robustness, check out our Rainbow Teaming poster, presented today by @_samvelyan and @_andreilupu 🌈🌈🌈.
Presenting our 🌈 Rainbow Teaming paper today at #NeurIPS2024 with @_andreilupu. 📅 December 11.🕚 11 am — 2 pm.📍 East Exhibit Hall A-C, Poster #1906. Stop by to learn how open-endedness can enhance LLM safety—or to see the most colorful poster in town!

1
2
30
Open-endedness is all you need! . Great read from @chalmermagne and @nathanbenaich at @airstreetpress outlining the challenges in building truly useful AI agents that can deal with the conplexity and unpredictability of the real-world. They highlight open-ended learning as an.

New on @airstreetpress: Now that LLMs can convincingly automate much of a bored human’s tasks, attention is turning to “agentic AI”. In this piece, we evaluate how far advanced this work actually is, look at both promising research directions and the challenges ahead. Thread:

0
8
30
Exploration, and more broadly active data collection, is key for generalization, not only in RL but also SL and SSL. We are just scratching the surface on understanding how the two interact.

0
3
29
Very inspiring work and super cool to see open-ended learning ideas being applied to scientific discovery, which is, of course, an open-ended process! . Congrats to everyone involved!.

Introducing The AI Scientist: The world’s first AI system for automating scientific research and open-ended discovery!. From ideation, writing code, running experiments and summarizing results, to writing entire papers and conducting peer-review, The AI




1
0
28
In our new #ICML oral, we find that episodic bonuses are best at exploring environments with little shared structure across episodes, while global bonuses are best for a lot of shared structure. Combining them achieves the best of both worlds and works well in multiple domains.
Exploration is well-studied for singleton MDPs, but many envs of interest change across episodes (i.e. procgen envs or embodied AI tasks). How should we explore in this case?. In our upcoming @icmlconf oral, we study this question. A thread. 1/N.
0
4
28
Great to see evidence that RL helps code agents learn over multiple steps of code execution and feedback. Results look impressive, congrats!.

LLMs for code should do much better if they can iterate on tests -- but they don't. Our new work (RLEF) addresses this with execution feedback at RL *training time* to use execution feedback at *inference time*. is just out! 1/6
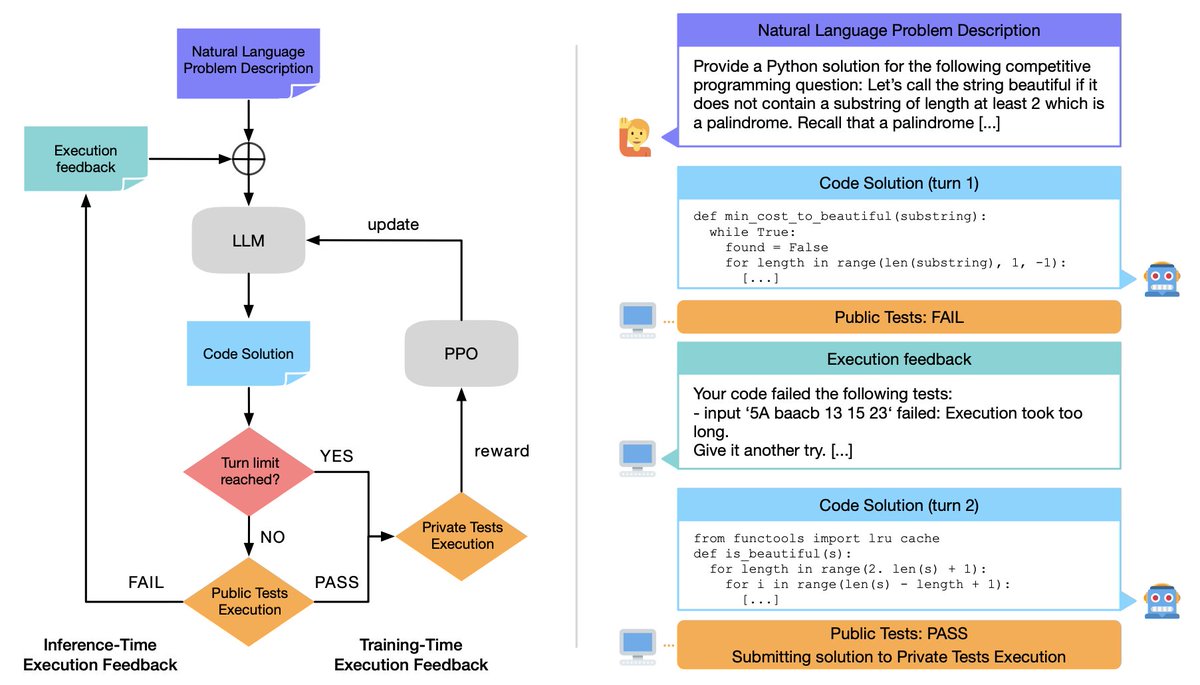
0
3
27
Great to see more work on open-endedness for AI safety! This paper on automatic evaluation and capability discovery in frontier models looks very neat and practical, kudos to the authors @cong_ml @shengranhu @jeffclune. Humbled to hear Rainbow Teaming was a source of.

I am very excited about this work using open-endedness methods for AI safety, which I expect will improve, speed up, and make cheaper pre-deployment assessments of frontier models, by automatically detecting unanticipated surprising new capabilities and weaknesses. Inspired by.
0
6
26
If you are interested in open-ended learning or self-improving models, check out the ALOE workshop at NeurIPS 2023!.
🌱 The 2nd Agent Learning in Open-Endedness Workshop will be held at NeurIPS 2023 (Dec 10–16) in magnificent New Orleans. ⚜️. If your research considers learning in open-ended settings, consider submitting your work (by 11:59 PM Sept. 29th, AoE).
0
3
27
Such a cool paper!. Shows how to use open-ended search to find diverse adversarial scenarios for multi-agent systems. With applications to football!.
Uncovering vulnerabilities in multi-agent systems with the power of Open-Endedness! . Introducing MADRID: Multi-Agent Diagnostics for Robustness via Illuminated Diversity ⚽️. Paper: Site: Code: 🔜. Here's what it's all about: 🧵👇

0
5
26
Great to see this!.

Thrilled to announce the first annual Reinforcement Learning Conference @RL_Conference, which will be held at UMass Amherst August 9-12! RLC is the first strongly peer-reviewed RL venue with proceedings, and our call for papers is now available:

0
2
25
I won’t be attending #ICML2024 in person this year, but many @UCL_DARK members will be there so make sure to check out their excellent work, including a number of orals and spotlights 🙀, as well as some of my own contributions: .- GLoRe: When, Where, and How to Improve LLM.
DARK is going to Vienna🏰🎶! We are excited to present our work at #icml2024, including 3 Orals on; Debate for Scalable Oversight (, Genie (, and a position paper on Open-Endedness (. Come chat with us ⬇️🚀

0
4
25
Come chat with us about the importance of exploration for generalization in RL this afternoon #NeurIPS2023! with @yidingjiang and @zicokolter.
2) "On the Importance of Exploration for Generalization in Reinforcement Learning" led by @yidingjiang .

0
1
25
Proud to work at a company which is such a great champion of open source!.
With today’s launch of our Llama 3.1 collection of models we’re making history with the largest and most capable open source AI model ever released. 128K context length, multilingual support, and new safety tools. Download 405B and our improved 8B & 70B here.
2
0
23
2 new papers on using LLMs to generate game levels! Very cool work. Language seems like a powerful way of generating open-ended tasks for training increasingly more capable and general agents. It’s also a neat way of incorporating human priors, which are currently lacking.
Large language levels can do. lots of things. But can they generate game levels? Playable game levels, where puzzles are solvable? Two papers announced today address this question. The first is by our team at @NYUGameLab - read on for more:

0
1
24
📢 Do you work on LLM safety, alignment, fairness, accountability, or transparency?. 📜 Submit your work to the #NeurIPS2023 SoLaR workshop on Socially Responsible Language Modelling Research!.

We are announcing the NeurIPS 2023 workshop on Socially Responsible Language Modelling Research (SoLaR)! We welcome submissions from all disciplines promoting fairness, accountability, transparency, and safety in language modeling.
0
3
23
Don’t miss out @HenaffMikael presenting our work today on in-context learning of sequential decision making tasks! #ICML2024.
@HenaffMikael will be presenting our work “Generalization to New Sequential Decision Making Tasks with In-context Learning” . Location - Hall C4-9 #2915. #ICML2024.
1
2
23
Great work on using LLMs + evolutionary methods to discover new and well-performing ML algorithms! Feels like we're just scratching the surface on what's possible 🚀.

Excited to share my first work from my internship @SakanaAILabs!. We used LLMs to design and implement new preference optimization algorithms for training LLMs, discovering cutting-edge methods!. Co-led with @samianholt and Claudio Fanconi. Details in thread 🧵 (1/N).
0
1
23
📢Chain-of-Verification (CoVe) reduced hallucinations in LLMs by self-verifying its own answers via simple follow-up questions. Great work from @shehzaadzd during his FAIR internship!.

Chain-of-Verification Reduces Hallucination in LLMs.(work done during my internship at FAIR). - LLMs more likely to hallucinate during longform generation.- We show that generating verification questions for the LLM to self-answer allows the model to deliberate on its outputs 🧵.
0
1
23
Great work on improving sample efficiency in RL via resets, which allows more updates and thus better scaling with compute. Love the simplicity of the method and the many insights in the paper.
Our paper "Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier" has been accepted to ICLR as top 5%! . We show that lots of updates and resets lead to great sample efficiency. Come for the scaling, stay for the insights. .1/N🧵

0
3
23
A new challenge for RL agents based on NetHack! Grateful to have been among the first few people to try it out for research.
I am proud to announce the release of the NetHack Learning Environment (NLE)! NetHack is an extremely difficult procedurally-generated grid-world dungeon-crawl game that strikes a great balance between complexity and speed for single-agent reinforcement learning research. 1/
0
3
21
Check out our poster session at #ICML2020 if you want to learn more about a new framework for fast adaptation in RL using policy-dynamics value functions. Today (Wed) at 8pm UTC and tomorrow at 9am UTC. ICML talk: Paper:
0
4
22
Great to see our survey on the Challenges and Applications of LLMs being cited by the White House.
Very cool to see our work on LLMs being cited by the 2024 Economic Report of the President (p.256 & 371):. @jeankaddour @maximilianmozes @herbiebradley @robertarail.
0
2
21
🌈🌈🌈 Rainbow Teaming 🌈🌈🌈. Beyond excited to share Rainbow Teaming, our new method for open-ended generation of diverse adversarial prompts for LLMs. 🌟 Rainbow Teaming is a generic approach for finding prompts where the model fails according to some metric. For some domains.
Introducing 🌈 Rainbow Teaming, a new method for generating diverse adversarial prompts for LLMs via LLMs. It's a versatile tool 🛠️ for diagnosing model vulnerabilities across domains and creating data to enhance robustness & safety 🦺. Co-lead w/ @sharathraparthy & @_andreilupu
1
4
21
Not at ICML this year but thankfully my collaborators are, so reach out :). @The_Eimer is presenting.Hyperparameters in RL and How to Tune Them. @HenaffMikael is presenting.A Study of Global and Episodic Bonuses in Contextual MDPs.
The timeslot for the poster is Thursday 1:30pm in exhibit hall 1, poster 414 - see you then 👋.
0
4
19
Can LLMs act as embodied agents 🤖 that learn from feedback and interaction with the world?. Can diffusion models be used as world models to enhance planning, RL, or control 🕹️ algorithms?. Can LLMs improve exploration in open-ended environments 🌎 by acting as human priors?.
🚨 Pass by our #ICLR2024 workshop on Generative AI for Decision Making tomorrow, Saturday May 11! 🚨. We have a content-heavy day, including an exciting lineup of invited and contributed talks, as well as two poster sessions!. Details:
0
4
21
🚀🚀🚀AstroLLaMA is out, check it out!!. Fantastic work from the super talented folks @universe_tbd. Can’t wait to see what new insights and discoveries this will enable, right at the intersection of some of my favorite topics. 🔭🪐 🤖.

We are thrilled to announce the release of AstroLLaMa, a LLM fine-tuned for astronomy ✨ it’s just a start of our journey towards harnessing the power of ML for the needs of researchers 🚀 #lettheastrollamaout .

0
0
20
Working at the intersection of GenAI and Decision Making?. Submit your papers to our #ICLR2024 workshop!. Deadline extended to February 9, AOE. Follow @genai4dm for official updates from the organizers.

🚨 Missed the ICML deadline? . Consider submitting a short (4 pages) or long (9 pages) paper to the GenAI+Decision Making workshop at ICLR 2024: Deadline is extended to February 9, AOE.
0
5
20

0
0
20
Cool work on prioritized replay for procedurally generated environments!.
Excited to share Prioritized Level Replay: a simple + effective way to improve generalization and sample efficiency of deep RL agents in procedurally-generated environments, where layout and dynamics can differ per episode. We call these variations "levels."

1
9
18
A very special moment @RL_Conference.

Third keynote by Andy Barto @RL_Conference , arguing that it was always RL, with a standing ovation at the end!

0
2
19
Movie Gen is super impressive, congrats @imisra_ and team!! Amazing to be able to read all the technical details that went into making this model.

So, this is what we were up to for a while :).Building SOTA foundation models for media -- text-to-video, video editing, personalized videos, video-to-audio. One of the most exciting projects I got to tech lead at my time in Meta!.
0
0
19
Great to see this new benchmark for general assistants that requires multi-step reasoning, planning, and tool use, posing a challenge to current LLMs. Looking forward to see what solves this, whether it’s scaling, a new algorithm, or Q* (whatever Q* is).

Happy to share GAIA with the community! 1/4. Joint work with @clefourrier @TechySwift @Thom_Wolf @ylecun @ThomasScialom.
0
1
19
Today we’re presenting NLD, a large-scale dataset of NetHack demonstrations. #NeurIPS2022.
2⃣ Dungeons and Data: A Large-Scale NetHack Dataset 🧙♂️🧝♀️. ⏰: 4:00PM .🚩: Hall J #1028 . Say 👋 to @erichammy @robertarail @_rockt @HeinrichKuttler.
0
4
18
Very neat work on hierarchical RL that will be presented #NeurIPS2022. Key idea: use compression to decompose demonstrations into generalizable skills.
Hierarchical RL aims to break complex tasks into simpler subtasks, but how do we judge the quality of decomposition w/ minimal prior knowledge? In this new work at NeurIPS (, we show that good decompositions arise from compression. 🧵 1/

0
0
18
RIDE achieves SOTA on challenging procedurally-generated MiniGrid tasks. In contrast to other exploration methods, RIDE does not suffer from diminishing intrinsic rewards during training and encourages agents substantially more to interact with objects they can control. 5/5


1
2
16
Excited to give a talk later today at the GenPlan workshop #NeurIPS2023 on In-Context Learning for Sequential Decision-Making Tasks. Thanks to the organizers for putting together this exciting workshop!. 📍Room 238-239.⏰4:00 - 4:35 PM.
1
5
18
Exciting to see more advances in open-ended learning!.
I am thrilled to introduce OMNI-EPIC: Open-endedness via Models of human Notions of Interestingness with Environments Programmed in Code. Led by @maxencefaldor and @jennyzhangzt, with @CULLYAntoine and myself. 🧵👇
0
5
17