

Thomas Scialom
@ThomasScialom
Followers
7K
Following
2K
Media
154
Statuses
1K
AGI Researcher @MetaAI -- I led Llama 2 and Postraining Llama 3. Also CodeLlama, Galactica, Toolformer, Bloom, Nougat, GAIA, ..
Paris, France
Joined December 2017


You too can not follow all the new papers out every day proposing methods to Augment Language Models e.g. CoT, Toolformer, and more?.We thought the same and tried to present and discuss the big lines in this survey 👇.

5
35
278
Personal news: I'm incredibly pleased and overwhelmed to share I will join @MetaAI as Research Scientist. I will work toward accelerating Science through AI, joining @paperswithcode team. Can't wait to see what we'll achieve @rbstojnic @rosstaylor90!. 1/.
15
8
252
We had a small party to celebrate Llama-3 yesterday in Paris! The entire LLM OSS community joined us with @huggingface, @kyutai_labs, @GoogleDeepMind (Gemma), @cohere.As someone said: better that the building remains safe, or ciao the open source for AI 😆

14
9
233
GAIA: a benchmark for General AI Assistant.GPT-4 performs less than 10%. despite non-expert humans obtaining 90%. Are LLMs with Q* all you need to solve GAIA? All bets are off, we look forward to what the Open Source community can achieve😉. with @huggingface @metaai @Auto_GPT.

GAIA: a benchmark for General AI Assistants. paper page: introduce GAIA, a benchmark for General AI Assistants that, if solved, would represent a milestone in AI research. GAIA proposes real-world questions that require a set of fundamental abilities such

5
29
223
🚨Automatic Evaluation in NLG - paper(s) alert🚨 .-> 3 new preprints.-> Summarization, Simplification, Data2Text. Spoiler: farewell BLEU & ROUGE🙈. Results from an international collaboration.@RecitalAI @facebookai @CriteoAILab .@mlia_lip6 @InriaParisNLP @NYUDataScience. Thread👇

4
29
175
Delighted to finally introduce Llama 3: The most capable openly available LLM to date. Long jouney since Llama-2, a big shoutout to the incredible team effort that made this possible, and stay tuned, we will keep building🦙.

16
21
151
Continual-T0: Progressively Instructing 50+ Tasks to Language Models Without Forgetting. Can LLM can learn more and more tasks without forgetting? Apparently yes. Also compositionality and why Continual Learning works well. @TuhinChakr @SmaraMuresanNLP.1/

4
16
131

Episodic Memory in Lifelong Language Learning. Motivation: prevent catastrophic forgetting in neural networks. The authors proposed an episodic memory model that performs sparse experience replay and local adaptation with the following components:.
3
19
95

I am at ICLR. 🦙 Llama-3: I ll be every morning at 11am at the @AIatMeta for Llama-3 QA sessions .🤖 GAIA: General AI Assistant benchmark w/ Gregoire.🔭 NOUGAT: for Scientific OCR w/ Lukas. And if you are interested in post-training, rlhf, agents i m down for ☕&🍺.@iclr_conf.

We're in Vienna for #ICLR2024, stop by our booth to chat with our team or learn more about our latest research this week. 📍Booth A15. This year, teams from Meta are sharing 25+ publications and two workshops. Here are a few booth highlights to add to your agenda this week 🧵.
6
14
85
What if a 120B Language Model was trained 𝙤𝙣𝙡𝙮 on 𝙎𝙘𝙞𝙚𝙣𝙘𝙚?.I think this idea has the potential to change the way we access Science. Feel so lucky to had the opportunity contributing with such a fantastic team @paperswithcode.Keep posted, more to come. .

🪐 Introducing Galactica. A large language model for science. Can summarize academic literature, solve math problems, generate Wiki articles, write scientific code, annotate molecules and proteins, and more. Explore and get weights:
2
7
73
Don't fall into the chinchilla trap if you want your model to be used by billions of people :).

Llama3 8B is trained on almost 100 times the Chinchilla optimal number of tokens

0
6
70
I strongly disagree. There are many paths to success, and doing a PhD is never a suboptimal choice. Both professionally and personally.

Agreed. There's so many opportunities in AI now. It's a pretty suboptimal career choice to do a PhD at the moment. Also, many outstanding AI researchers and hard carry engineers that I know of don't have an AI or CS PhD.
4
1
67
Laurent a raison, la façon dont beaucoup d'écologistes pensent le monde est inquiétante. Cette volonté systématique de purifier le monde est dangereuse. OUI à une écologie positive et progressiste.

Même le plus raisonnable des écologistes @JMJancovici bouleverse le médecin que je suis. Il propose dans @Socialter que l’on ne soigne pas les personnes âgées malades pour diminuer notre empreinte CO2. La dérive anti humaine des écologistes m’affole 😱 NOUS DEVONS LES COMBATTRE

11
24
66
Super excited, I have 5 papers accepted at EMNLP!!! .Guess this is what we call the Punta Cana effect😎. (I'll write a detailed thread for each paper, but next week :)

6
0
67
New #NLProc preprint: . 𝗧𝗼 𝗕𝗲𝗮𝗺, 𝗢𝗿 𝗡𝗼𝘁 𝗧𝗼 𝗕𝗲𝗮𝗺,.𝗧𝗵𝗮𝘁 𝗶𝘀 𝗮 𝗤𝘂𝗲𝘀𝘁𝗶𝗼𝗻 𝗼𝗳 𝗖𝗼𝗼𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻 .𝗳𝗼𝗿 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗚𝗔𝗡𝘀. - SelfGAN: a new simple stable and efficient training algorithm.- Coop-MCTS: a new decoding method . Thread👇. 1/

4
16
56
#NLProc community has recently devoted stong efforts to strengthen multilingual approaches and datasets. I am proud to contribute with our new paper: MLSUM: The Multilingual Summarization Corpus.
1
13
62

Don't expect to recognize me. My PhD, how it started Vs how it's going 🥴



🌸 Behind the scenes 👀 We’re delighted to introduce to you @ThomasScialom! He is co-charing the Extrinsic Evaluation Working Group dedicated to standardizing a suite of application-oriented downstream tasks (e.g., Question Answering, Summarization) on which to evaluate models!

3
1
61
New state of the art for Machine reasoning (CLEVR dataset) : 98.9% thanks to MACnets, the new #DeepLearning architecture by @chrmanning and @stanfordnlp #AI #MachineLearning #ICLR2018
0
35
59
A model that can answer multilingual questions?.Accepted at @emnlpmeeting: . Synthetic Data Augmentation for Zero-Shot Cross-Lingual Question Answering. A collaboration between @RecitalAI, @InriaParisNLP, and @mlia_lip6. Thread👇.1/7

3
12
51
Wanna talk about inaccessibility of science? Pay for accessing it.

2
4
50
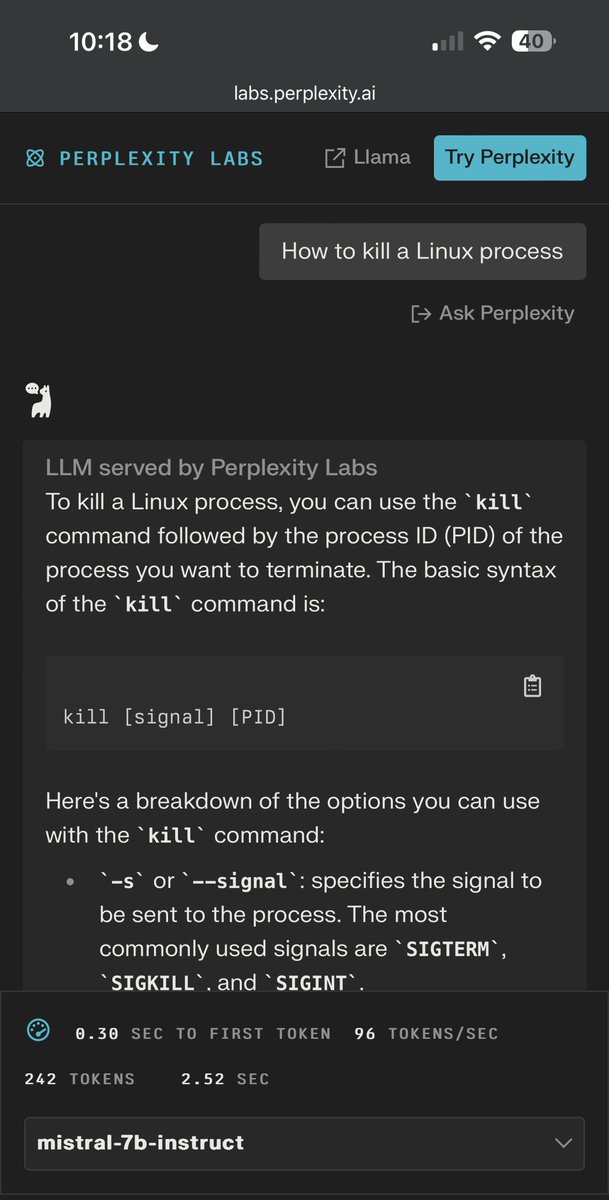
In fact there is on perplexity demo a specific system prompt that amplifes over safe responses. It has been removed from other demos like HF. @perplexity_ai @denisyarats could we deactivate it as well by default please?.

The mistral 7b model (right) is clearly more “helpful” than the llama 70b chat model (left). Trying to bias too much on harmlessness doesn’t let you build a useful general chat assistant.

1
7
45
Just arrived at #EMNLP2021, first conference in person in two years. If you too are lucky as well here and want to discuss about NLG or just grab a 🍹 ping me !

3
1
44
Our @RecitalAI / @mlia_lip6 paper "Self-Attention Architectures for Answer-Agnostic Neural Question Generation" has been accepted !! See you @ACL2019_Italy 🇮🇹.
3
6
40
We propose in this paper the first large scale (1.5M) corpus for summarization in other languages than English. Why does it matter? I recommend you to read the excellent post by @seb_ruder about this topic: . 3/N.
1
10
37
A very new way to reduce the attention cost in transformer inspired by co. science. Skim-Attention: Learning to Focus via Document Layout. Accepted at #EMNLP2021, and first paper for the great Laura Nguyen!. Thread.1/

2
11
38
Very proud to announce two papers accepted at @emnlp2020 about text generation!. 1/ Multilingual Summarization.2/ Stance-based Personas Dialogues. 👇. 1/N.
1
7
37
@RecitalAI is in the top 3 for a machine reading comprehension challenge SQuAD2 by @pranavrajpurkar & @stanfordnlp #DeepLearning #NLP

1
10
36

Large Language Models are Continual Learners! So proud to see our work featured by @ak92501 👇.
Continual-T0: Progressively Instructing 50+ Tasks to Language Models Without Forgetting.abs:

0
5
34
Oui aujourd'hui la startup française @RecitalAI ringardise IBM Watson grâce à sa solution de traitement des messages: notre logiciel aide, de la réception d'un message à la réponse en passant par le lancement de process métiers ou le reporting. Merci @JDNebusiness pour l'article!.

ReciTAL, la start-up française qui peut concurrencer IBM Watson

1
11
30
On the Cross-lingual Transferability of Monolingual Representations. By @artetxem, @seb_ruder & @DaniYogatama. Interesting work on the capacity of models trained for a task in a specific language to transfer well in other languages. New multilingual QA evaluation dataset.TL;DR👇.
1
9
30

🤖 New paper: 𝙐𝙣𝙣𝙖𝙩𝙪𝙧𝙖𝙡 Instructions 🤖.We can now teach LLM to follow instructions without annotating a large instruction corpus. See how to 👇.

Instruction-tuned LLMs are strong zero-shot learners. Can we collect instructions without any humans involved?. We introduce Unnatural Instructions🤖 - a dataset of instructions automatically generated by a LLM. @ThomasScialom @omerlevy_ @timo_schick.

1
4
31
📅 (reci)TALK .𝑪𝒐𝒏𝒕𝒓𝒐𝒍𝒍𝒊𝒏𝒈 𝑺𝒕𝒐𝒄𝒉𝒂𝒔𝒕𝒊𝒄 𝑷𝒂𝒓𝒓𝒐𝒕𝒔 🦜.From @naverlabseurope in two days.Open to everyone: . Looking forward to listening to Hady and Muhammad about their last paper! . #NLP #NLG

2
6
29
Thread: "If Beam Search is the Answer, What was the Question?" .from @ClaraIsabelMei1 @xtimv & @ryandcotterell . Finally finished reading, I recommend it to everyone interesting in NLG. 1/

1
4
27
Delighted that our paper is accepted at #NeurIPS2021 🎉🎉🎉. SelfGAN is a new GAN for Language Generation. It also comes with a new decoding algorithm improving over BeamSearch. See this thread for more details:. A collaboration w/ @RecitalAI & @mlia_lip6

New #NLProc preprint: . 𝗧𝗼 𝗕𝗲𝗮𝗺, 𝗢𝗿 𝗡𝗼𝘁 𝗧𝗼 𝗕𝗲𝗮𝗺,.𝗧𝗵𝗮𝘁 𝗶𝘀 𝗮 𝗤𝘂𝗲𝘀𝘁𝗶𝗼𝗻 𝗼𝗳 𝗖𝗼𝗼𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻 .𝗳𝗼𝗿 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗚𝗔𝗡𝘀. - SelfGAN: a new simple stable and efficient training algorithm.- Coop-MCTS: a new decoding method . Thread👇. 1/
1
8
26
Proud to announce that "ColdGANs: Taming Language GANs with Cautious Sampling Strategies" has been accepted to #NeurIPS as a long Paper!. Preprint: A collaboration with @RecitalAI & @mlia_lip6.With @DrayPAD, @SLamprier, @bpiwowar, and @stjaco. TL;DR👇1/6

2
9
25
My girlfriend asked me why I was speaking so softly at home. I told her I was afraid Mark Zuckerberg @finkdwas was listening!.She laughed. I laughed. Alexa laughed. Siri laughed. #privacy #dataprotection.(found on LinkedIn).
1
6
23
New @Windows update following #GDPR : @Microsoft proposes only two choices : sending "basic" or "complete" data. No option "sending nothing". poke @laquadrature

2
15
18

You can find our last paper about summarization with reinforcement learning now on arxiv. Enjoy 🤖📄.
2
3
20
Really cool talk by Victor @SanhEstPasMoi about his magnitude pruning paper at @NeurIPSConf:.- Motivation: smaller models, eg. on device, loading a model is the main consumption source .- Result: 95% of BERT perf, with 5% of the weights


1
1
22
"𝙇𝙖𝙧𝙜𝙚-𝙨𝙘𝙖𝙡𝙚 𝙩𝙬𝙤-𝙡𝙖𝙮𝙚𝙧 𝙢𝙤𝙙𝙚𝙡" . When you read a ten years old #AI paper. (From Gutmann et al., 2010 - Noise-contrastive estimation: A new estimation principle for unnormalized statistical models)

0
1
20
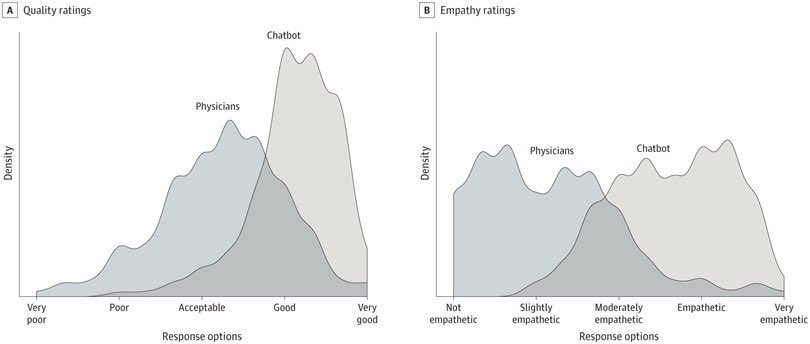
RHLF versus immitation learning explained in one tweet.

Empathy and quality of answers on reddit about common medical issues, doctors vs. GPT-3.5.
0
5
24
📢New Paper Alert.How do metrics perform across tasks?. 𝐁𝐄𝐀𝐌𝐞𝐭𝐫𝐢𝐜𝐬: 𝐀 𝐁𝐞𝐧𝐜𝐡𝐦𝐚𝐫𝐤 𝐟𝐨𝐫 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧 𝐄𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 𝐄𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧.=> Multi Task/Lingual/Modal. Paper: Code: 👇

4
4
19
Despite being an amazing paper, chinchilla did/could not be open-source. Llama-1 has now more than 10x citations than Chinchilla.

I suddenly realized the chinchilla paper has only 200 citations…. It’s a lot for a paper released 18 months ago, but it’s really really tooooooo low for such an art. To some extent, it reflects the diminishing of publishing pretraining research. Getting citations in this.
1
1
19
Our new paper is out:. We propose DAS, a new learnable beam search algorithm for text generation. 1/ It tackles efficiently exposure bias and fits better the training distribution.2/ It doesn't require additional data => self training procedure . #NLProc.Read more 👇.
0
7
19
Yes, we will continue to make sure AI remains an open source technology.

If you have questions about why Meta open-sources its AI, here's a clear answer in Meta's earnings call today from @finkd

0
1
18
"Together, deep learning and symbolic reasoning create a program that learns in a remarkably humanlike way." It should please @GaryMarcus !. Mao & al.

"The approach goes beyond what current deep learning systems can do." @LakeBrenden.
1
7
19
Glad to announce 0 accepted paper on 0 submitted at #ACL2021NLP .Congrats to all of you that have got accepted papers, my "To Read" list just exploded 😅.And a thought for the others, don't take it personally and keep persevering, it will pay.
0
1
17
Automatically create a @Docker from your @github repo and create a @ProjectJupyter notebook too. H / T : Olivia Guest (@o_guest ). #artificialintelligence #docker #github

1
6
16
Language Models acting with tools? Toolformer 👇.

🎉 New paper 🎉 Introducing the Toolformer, a language model that teaches itself to use various tools in a self-supervised way. This significantly improves zero-shot performance and enables it to outperform much larger models. 🧰. 🔗 Link:
0
1
17

@_florianmai Not just* for that, I am seeing several google papers mentioning 'a 137B LM' these days.
3
0
16
😱 .wonder if it was a good timing to start a PhD in #NLProc this year :).Finger crossed for today's @ACL2019_Italy acceptance notification !

2
0
15

3
1
16
Does AI understand French as much as it does English?.We tried to answer this question in a paper accepted at @lrec2020. It comes with a nice French QA dataset. Collab btw @RecitalAI.@Etalab & @mlia_lip6. Sounds one we could add in @huggingface datasets new library @Thom_Wolf 😉.

Bravo @RecitalAI pour cette très belle collaboration avec @Etalab !.@rachelkeraron @stjaco @ThomasScialom @fredallary @psorianom @pa_chevalier @Mathilde_Bras @maxiguillim.
0
2
16

#AI is allowing us to 'draw' web sites without any #coding skills. Learning how to code will not be necessary in tomorrow's world. #education.

1
7
15
It did in fact. RLHF is the technology behind chatgpt and probably dalle3. To panned out on real-world problems it needed nothing more than human feedback rewards.

DeepMind’s big bet was deep reinforcement learning, but it hasn’t panned out on any real-world problems.
0
0
14
Getting gender right in #ArtificialIntelligence.Thanks @Evanmassenhove et al., @scienceirel for getting #AI better. #EMNLP2018

0
5
13
Remember to always take some time for yourself 🙂. #AIMemes #MachineLearning #NeuralNetworks #DeepLearning #ArtificialIntelligence #AIMeme #ML #AI

0
4
14
@douwekiela Actually our extention of T0 knows about COVID. We show that Finetune-LM are pretty good continual learner, no need to train from scratch :) .
0
0
15
@alexandr_wang They actually continue learning ;).
Continual-T0 (CT0) displays Continual Learning capabilities via self-supervision. This fine-tuned language model retains skills while learning new tasks across an unprecedented scale of 70 datasets. It can even combine instructions without prior training.

1
0
15

Gonna present our Multilingual Summarisation dataset at @emnlp2020, join us if you are attending! .I will also offer free beers at our virtual stand 😄 🍻.Session 5I, 7-9pm cet (in 2.5h).@RecitalAI @mlia_lip6.
Very proud to announce two papers accepted at @emnlp2020 about text generation!. 1/ Multilingual Summarization.2/ Stance-based Personas Dialogues. 👇. 1/N.
0
2
15
Deep image reconstruction from human brain activity. Shen et al.: doi: #ArtificialIntelligence #brain #MachineLearning
1
4
14
Quantity doesn't buy quality syntax with neural language models. By @marty_with_an_e, A. Mueller and @tallinzen. Take away: no way to reach human level with BERT like models, only improving the number of data or layers. We are missing something. @GaryMarcus will appreciate it!

0
3
14
I am fascinated by the 𝘦𝘪𝘨𝘩𝘵 𝘱𝘢𝘨𝘦𝘴 miracle:.all my papers fit 8 pages, not one line more, not one line less.

2
0
14
Thanks @emnlp2018 for everything. Good idea to end with Magritte, it seems to be an NLP scientist before the hype - The Art of Conversation (1963) #emnlp2018

0
3
14
Looking forward to present QuestEval for summarization in half an hour at #EMNLP2021, summarization track !.
🚨Automatic Evaluation in NLG - paper(s) alert🚨 .-> 3 new preprints.-> Summarization, Simplification, Data2Text. Spoiler: farewell BLEU & ROUGE🙈. Results from an international collaboration.@RecitalAI @facebookai @CriteoAILab .@mlia_lip6 @InriaParisNLP @NYUDataScience. Thread👇
0
1
13
Looking forward to discussing the recent progress in Language Generation with Criteo AI researchers!.

We can't wait 😍for 🗓️Dec 3 and our talk with @ThomasScialom on the current state-of-the-art for Natural Language Generation, including modeling, decoding, and evaluation practices, with his recent research in this area plus possible future directions. #NLP @mlia_lip6 @RecitalAI.
0
2
14
Just the beginning. Looking forward to see what we will build, thanks to all the great people in this evaluation group. Stay tuned. And if you are interested to join, feel free to reach me out :).
What makes a language model "good", and how can we develop standardized measures and design a diverse, multifaceted evaluation suite? 📖📝🤖. Ellie Pavlick, Thomas Scialom, Dan Garrette, Oskar van der Wal with an update from the Evaluation working groups.

0
4
13
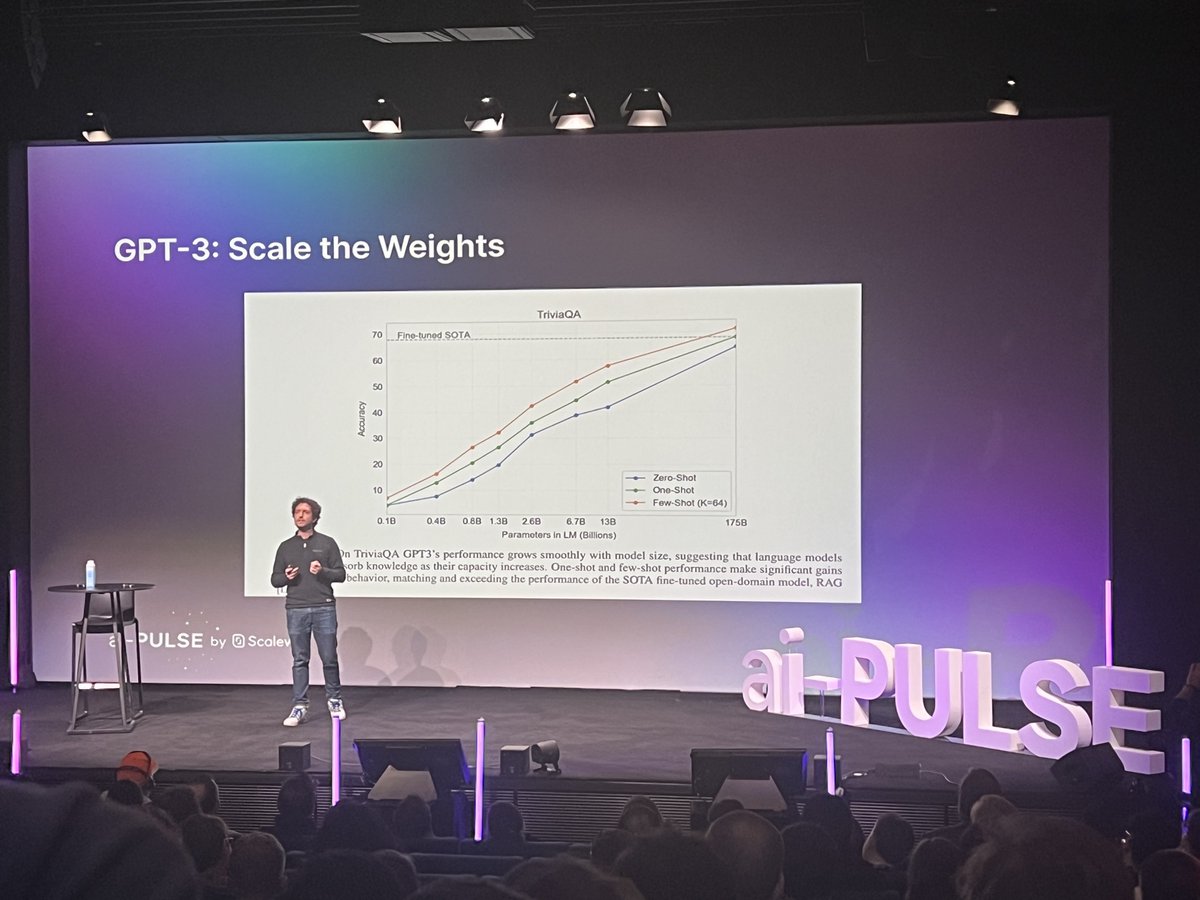
At the AI-pulse today I talked about -- surprise -- LLMs. There short history, a deep dive into Llama 2, the magic behind RLHF, and my vision of where of the future of the field. Thanks @Scaleway for the opportunity!

2
0
14

5
1
12
@YiTayML @_jasonwei @zhansheng @MaartenBosma Yeah, why Continual Learning matters? Next time we will ask your opinion before doing research.
3
0
13
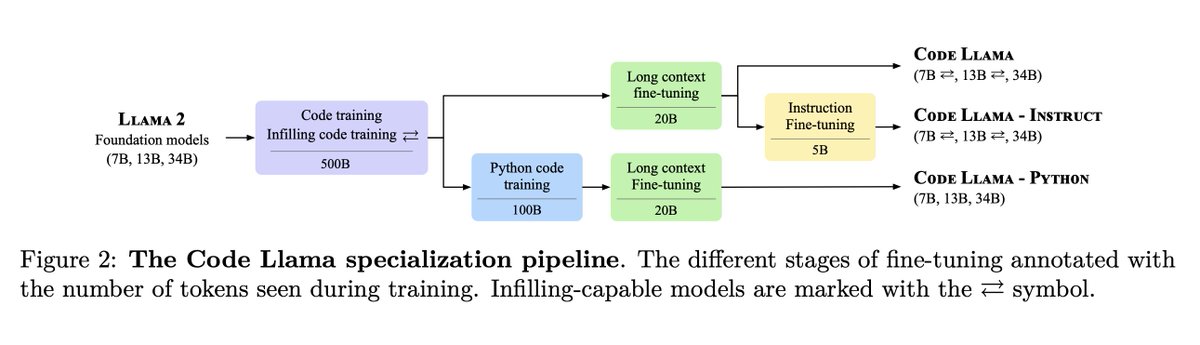
You wanted a better Llama for Code? .👇.

Today, we release CodeLlama, a collection of base and instruct-finetuned models with 7B, 13B and 34B parameters. For coding tasks, CodeLlama 7B is competitive with Llama 2 70B and CodeLlama 34B is state-of-the-art among open models. Paper and weights:
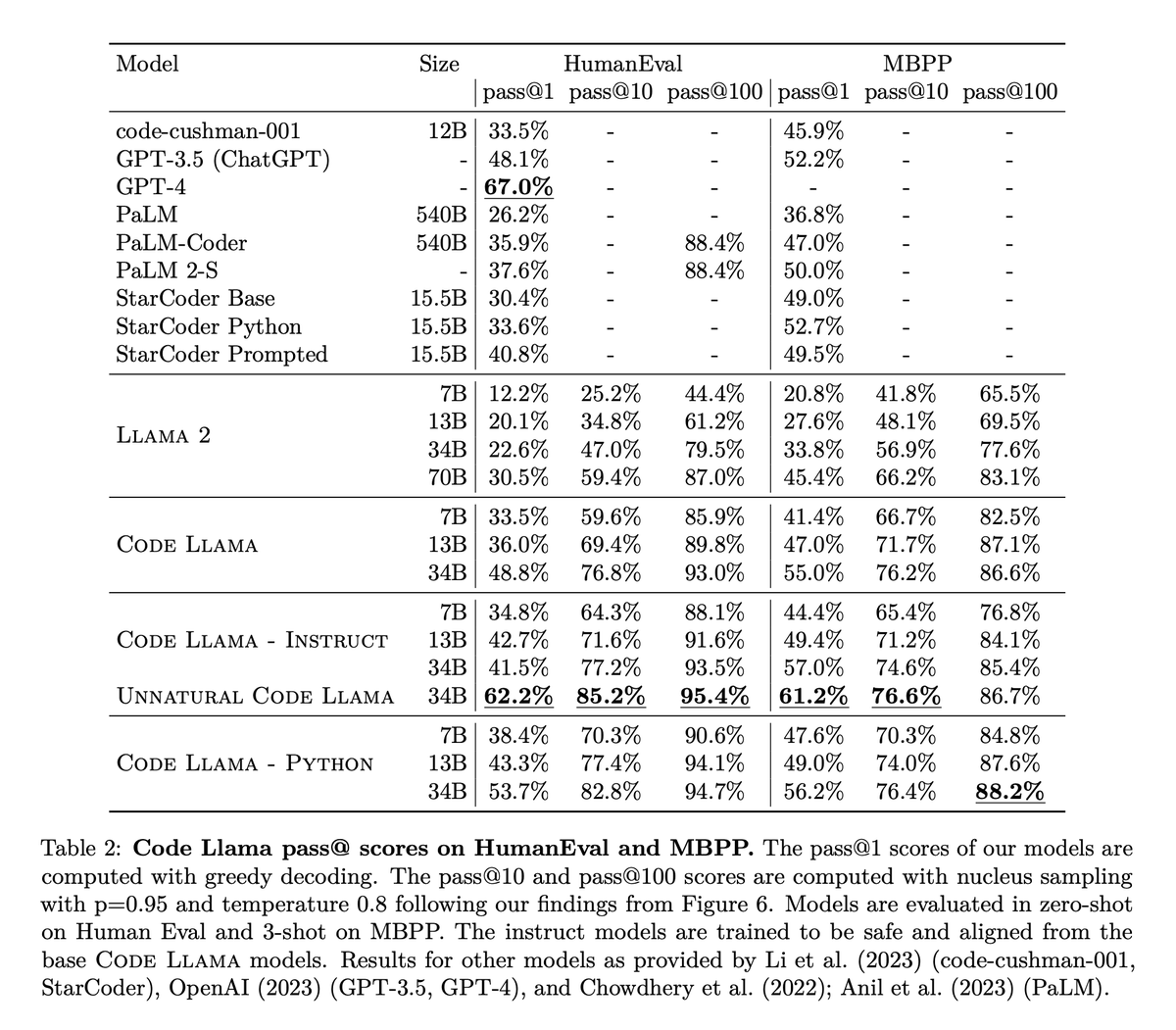


1
1
13
I will have the opportunity to present our last paper on sequence generation this afternoon, thanks @omarsar0!. #NLProc #exposureBias #beamSearch. Collaboration @RecitalAI / @mlia_lip6.

I am excited about today's talk on "Discriminative Adversarial Search for Abstractive Summarization" by @ThomasScialom. You will learn about a GAN inspired approach for sequence decoding. (Work accepted at ICML2020). cc: @RecitalAI @stjaco @GillesMoyse.

1
2
13
@Thom_Wolf @nlpmattg Indeed we did so at @RecitalAI. Yes it works well BUT little resources natively available in non-eng. Here the BERT multilingual results. Note that our french Squad is a machine translation of the En. version => might be biased and not perfect.

3
4
12
I do agree with @GaryMarcus : "there's been an “irrational exuberance” around #DeepLearning" Despite impressive achievements, #AI, as most sciences do, will develop incrementally over time.
1
3
13
Farwell BLEU & ROUGE metrics in NLG?. Our new metric, QuestEval has been accepted to #EMNLP2021 !. Paper: Code: Can be broadly applied in NLG, e.g. to Summarization, Text Simplification, Data2text, Image Captioning. thread.👇. 1/

3
4
11
A benchmark to evaluate NLG systems on Indonesian, Javanese, and Sundanese? . IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation.Accepted at #EMNLP2021. An international collab. led by @sam_cahyawijaya (*I am not an author). Thread .👇.1/

1
1
13
@yoavartzi @_jasonwei @LukeZettlemoyer @chrmanning Christopher does language. Jason does langauge ;).
1
0
12

Research papers Vs reality🤦.



0
0
11
Grateful living at the open science era. 1992 was quite a different world.

0
1
12
2020 is ending with two major biological breakthroughs: RNA vaccines, and solving protein folding. The way they were solved is closer to Computer Science than Chemistry. Will 2020 marked in history books as the advent for digital?.
3
1
12
@rm_rafailov Each algo has its own pros and cons. RS is very stable and is used for the "sft" stage, init it at the level of the best rlhf models. PPO push the reward scores much beyond. Dpo is a final refinement using only few lattest batches pushing further the results.
0
0
11