
Ishan Misra
@imisra_
Followers
6,393
Following
224
Media
18
Statuses
248
GenAI @Meta . Tech Lead of Movie Gen Meta. Past: MIT TR's 35 under 35 ; Llama3, Emu Video, ImageBind, DINO
United States
Joined June 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
النصر
• 936093 Tweets
التعاون
• 718674 Tweets
Washington Post
• 271885 Tweets
Durk
• 218490 Tweets
Virginia
• 188375 Tweets
Bezos
• 129501 Tweets
Beyoncé
• 127921 Tweets
Tommy Robinson
• 91797 Tweets
WaPo
• 84420 Tweets
LA Times
• 80518 Tweets
Forest
• 68326 Tweets
Edwin Santos
• 55141 Tweets
Democracy Dies in Darkness
• 53002 Tweets
#史上初金車確定無料ガチャ
• 42730 Tweets
Marçal
• 41905 Tweets
Chicó
• 38726 Tweets
#الاهلي_الاخدود
• 30074 Tweets
レジェンド車両
• 25095 Tweets
全員最大金枠アイテム5つ
• 24942 Tweets
Tether
• 22247 Tweets
بن زكري
• 19369 Tweets
Leicester
• 18977 Tweets
Albon
• 16316 Tweets
Phil Lesh
• 12961 Tweets
SÃO PAULO IS COMING
• 10106 Tweets




















Pinned Tweet

So, this is what we were up to for a while :)
Building SOTA foundation models for media -- text-to-video, video editing, personalized videos, video-to-audio
One of the most exciting projects I got to tech lead at my time in Meta!

🎥 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date.
Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in
370
2K
7K
37
67
908
We released 92 pages worth of detail including how to benchmark these models! Super critical for the scientific progress in this field :) We'll also release evaluation benchmarks next week to help the research community 💪

yes, Meta released a full scientific paper on MovieGen, with a lot of details that'll help the field move forward.
14
62
733
10
34
447
World meet
#emuvideo
For the past year, our team has been pushing on video generation. The result? Emu Video that generates high quality videos from text or images. SOTA performance vs. commercial products and academic papers. Check it out
Today we’re sharing two new advances in our generative AI research: Emu Video & Emu Edit.
Details ➡️
These new models deliver exciting results in high quality, diffusion-based text-to-video generation & controlled image editing w/ text instructions.
🧵
53
472
2K
22
62
367
Thank you
@MetaAI
! Would not have been possible without the awesome collaborators and mentors at FAIR (Meta) and CMU!
And thanks to
@techreview
for the award :)
Congratulations to our very own Meta AI researcher
@imisra_
for being named one of
@TechReview
’s
#35InnovatorsUnder35
! Ishan has been one of our leaders in advancing self-supervised learning.
6
22
155
8
7
279
Thanks for having me
@lexfridman
! It was a great experience :)

Here's my conversation with Ishan Misra (
@imisra_
), research scientist at FAIR, working on self-supervised visual learning: getting machines to understand images & video with little help from humans. This is one of the most exciting topics in AI today.

26
81
630
5
16
206
We released ImageBind - a multimodal model for six different modalities trained using self-supervised learning.
Mark announced it in his video
Also, thanks,
@_akhaliq
for sharing :)


ImageBind: Holistic AI learning across six modalities
ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. It enables novel emergent applications ‘out-of-the-box’ including cross-modal retrieval, composing
7
110
529
3
35
194
Check out the generative vision related release too
Imagine Flash generates the image as you type
You can also "Animate" your images! (technique based on Emu Video )
Kudos to the team for putting this out :)
7
24
177

Latest work in SSL learns with 100x fewer labeled images than previous SOTA like MAE, DINO
Huge shout out to
@mido_assran
and Nicolas Ballas for really pushing the boundaries of SSL!
Tired of manually annotating vast quantities of data to achieve good performance? Our Masked Siamese Networks (MSN) is a self-supervised framework for learning image representations. So what does that mean?

15
145
814
0
21
153
Two exciting updates on Movie Gen
(1) MovieGenBench containing thousands of *random* generations for benchmarking for video/audio tasks :)
(2) Folks in Hollywood (Casey Affleck, Blumhouse productions) took Movie Gen for a spin:
As detailed in the Meta Movie Gen technical report, today we’re open sourcing Movie Gen Bench: two new media generation benchmarks that we hope will help to enable the AI research community to progress work on more capable audio and video generation models.
Movie Gen Video Bench
42
225
1K
3
14
151
Attending
#NeurIPS2022
this year. Super excited to see the awesome research! Organizing the 3rd SSL workshop at NeurIPS (1st time in-person) on December 3
5
7
129
Thank you
@facebookai
and
@ylecun
:)
FAIR research scientist, Ishan Misra (
@imisra_
) sat down with
@lexfridman
to demystify self-supervised learning & its impact in
#AI
: . Read the blog post that inspired the conversation:
5
87
477
1
8
136
It’s been one of the toughest days at work. Praying for my wonderful ex-colleagues. Please let me know if I can help.
2
3
135
[1/2] Late to arxiv
Happy to share my recent work on using Transformers for 3D Recognition.
Inspired by DETR, we propose 3DETR which works well for 3D Detection and classification.
Simple to understand, implement and extend!
1
9
110
And yes, we released a full paper!
It was a mammoth effort with such an amazing team :)
Here's the first line (one of my favorites) of our paper as a video
12
14
111
Giving two talks today on Generative Video and Image models at
(11am)
(2:45pm)
Come say hi :)
5
9
110

Why train separate models for visual modalities?
Following up on our Omnivore work: We train a single model on images, videos using no labels! Joint work with
@_rohitgirdhar_
,
@alaaelnouby
, Mannat, Kalyan and
@armandjoulin
!
PS: Omnivore is an oral at CVPR 2022, see you there!
OmniMAE: Single Model Masked Pretraining on Images and Videos
abs:
single pretrained model can be finetuned to achieve 86.5% on ImageNet and 75.3% on the challenging Something Something-v2 video benchmark

3
21
149
1
11
90
#ECCV2022
Presenting Detic at today’s poster session. A detector for 20,000+ classes! With
@zhouxy2017
@_rohitgirdhar_
@armandjoulin

2
1
86
Thank you CMU and Smith Hall! So many wonderful memories :)

12
1
74
We are organizing the 3rd workshop on SSL at NeurIPS!
Awesome lineup of speakers across different domain in ML.
You're welcome to submit papers too :)
With --
@xiaolonw
@cmuptx
@gulvarol
@yalesong
@y_m_asano
@paulineluc_
0
8
65
Thank you
@kchonyc
for the beer! It’s rewarding to review on time
#NeurIPS2022
@meickenberg
@Sagar_Vaze
@AnanyaHarsh
@utkuevci

1
1
63
Autoregressive language modeling meets diffusion models! In a single shared model. Super cool work 😊

Introducing *Transfusion* - a unified approach for training models that can generate both text and images.
Transfusion combines language modeling (next token prediction) with diffusion to train a single transformer over mixed-modality sequences. This


23
215
1K
0
4
63
CutLER: a self-supervised detection/segmentation model. Surpasses prev SOTA by 2.7x on 11 datasets across various image domains! Awesome work by
@XDWang101
!
1
6
51
This is a homage to our Emu line of models for image, video, editing :)
@rsumbaly
And yes, we released a full paper!
It was a mammoth effort with such an amazing team :)
Here's the first line (one of my favorites) of our paper as a video
12
14
111
1
1
50

SSL workshop happening tomorrow
@ylecun
will start us off with an amazing talk at 8:40am! See you there :)
Attending
#NeurIPS2022
this year. Super excited to see the awesome research! Organizing the 3rd SSL workshop at NeurIPS (1st time in-person) on December 3
5
7
129
1
3
48
Happy to share our two recent papers on audio-visual self-supervised learning!
0
4
44
Llama3 is out with great performance and efficiency!! Models are available for download :)
Check out to interact


It’s here! Meet Llama 3, our latest generation of models that is setting a new standard for state-of-the art performance and efficiency for openly available LLMs.
Key highlights
• 8B and 70B parameter openly available pre-trained and fine-tuned models.
• Trained on more
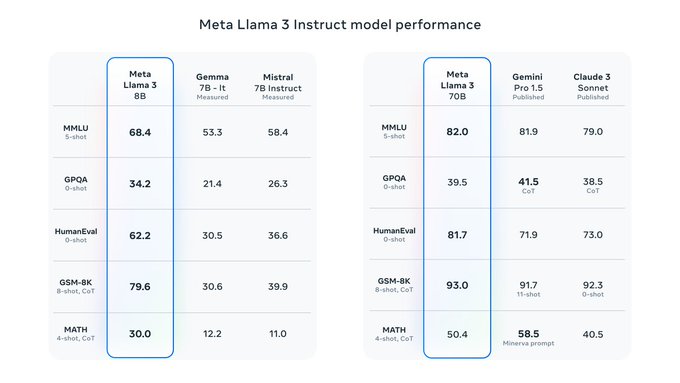
63
202
998
0
5
45
Thank you, Max and all the authors of Flow Matching!! Such a powerful and simple technique :)

0
3
42
The 5th edition of our self-supervised learning workshop at NeurIPS 2024 this year :)
Great line-up of speakers and the call for papers is out!

🎉We are thrilled to announce the NeurIPS 2024 workshop on Self-supervised Learning - Theory and Practice. We invite submissions of both theoretical works and empirical works on SSL!
Website:
OpenReview:
1/n

1
12
111
0
3
41


1
2
37
The 4th iteration of our SSL workshop at NeurIPS'23 :)
Open for submissions!

The 4th workshop on "Self-Supervised Learning - Theory and Practice" will appear in
@NeurIPSConf
2023 in December! We have a great list of speakers: And we are still open for submissions:
1
7
37
0
4
34



This is quite something! Input detailed image detections to ChatGPT => incredibly detailed natural language description of the image, where it fills up spatial relations.


0
6
29
@ziv_ravid
Great question! In vision, these models seem to have an advantage in few-shot classification () and seem to be more robust ()

1
2
32
Such great energy at the BigMAC workshop 😀 I’ll also be presenting there at 11am!

Join us for the 🍔BigMAC workshop on Big Model Adaptation in Computer Vision with our great line-up of speakers:
@neilhoulsby
@JMarakiii
@cvondrick
@lschmidt3
@imisra_
@AdtRaghunathan
@RisingSayak
⏰ 9am - 1pm
📍 S03
🌐
ℹ️

2
12
65
0
3
30
Really nice analysis and code release! Probing the representations learned by a variety of ViT models.

What do the Vision Transformers learn? How do they encode anything useful for image recognition? In our latest work, we reimplement a number of works done in this area & investigate various ViT model families (DeiT, DINO, original, etc.).
Done w/
@ariG23498
1/
10
176
1K
0
4
29
Get visual instructions to your most pressing questions :) We jazz up an LLM's text-only answers with corresponding images.

Since I started working on generative models, I've felt the most compelling application would be sth that helps one learn new skills. Excited to share our first steps to that goal: generating bespoke instructions with illustrations to solve your task! w/
@SachitMenon
@imisra_
2
13
77
0
0
23
We'll be presenting our poster today afternoon at
#ICCV2023
:)
Strong foundational models released!

Excited to present our work, "The effectiveness of MAE pre-pretraining for billion-scale pretraining" () at
#ICCV2023
today. Our strong foundational MAWS models, with multilingual CLIP capabilities, are now available publicly at .
1
9
63
0
1
21
Omnivore at CVPR’s morning’s oral and poster session today (June 24). Come say hi!

If you're still at CVPR today check out our paper "Omnivore: A Single Model for Many Visual Modalities".
Our SoTA model excels at classifying images, videos, and single-view 3D data using exactly the same model parameters and without access to correspondences between modalities.

1
6
54
0
0
21
Lots of interesting talks at the T4V workshop, CVPR 2023! I’ll be talking about supercharging transformers with SSL
#imagebind
#cutler
at 10:30. Joint work with
@_rohitgirdhar_
,
@alaaelnouby
,
@XDWang101
,
@armandjoulin
, Mannat Singh, and Kalyan Alwala
2
2
20
Here is
@ShellySheynin
editing her video with Movie Gen Edit models!!

I’m thrilled and proud to share our model, Movie Gen, that we've been working on for the past year, and in particular, Movie Gen Edit, for precise video editing. 😍
Look how Movie Gen edited my video!
57
97
853
0
0
20

Teach a robot to do your task in just 5 minutes using off-the-shelf hardware + smart Machine Learning :)
Super cool work with
@notmahi
,
@anantr_ai
,
@HarithejaE
, Eva Liu,
@soumithchintala
, and
@LerrelPinto
!

Meet Dobb·E: a home robot system that needs just 5 minutes of human teaching to learn new tasks. Dobb·E has visited 10 homes, learned 100+ tasks, and we are just getting started!
Dobb·E is fully open-sourced (including hardware, models, and software):
🧵
13
110
492
0
4
18
Holiday greetings from
#emuvideo
Excited to share what we've been up to this year: Emu Video! A SOTA video generation system from text or images. In spirit of the upcoming holidays, here's a holiday greeting featuring a cute little penguin Frosty, powered by Emu Video! (🔊 on)
#emuvideo
1
24
132
0
0
17
Omnivore and OmniMAE training code is out 😊
We've released our "Omnivorous" training code for Omnivore () and OmniMAE (), for unified modeling of multiple visual modalities! Check it out at !
@KalyanVasudev
,
@_rohitgirdhar_
,
@alaaelnouby
,
@imisra_
1
3
24
0
0
17
Could not have said it better! The incredible team of
#emuvideo
and the amazing support from many others at Meta
Work done with an incredible team
@_rohitgirdhar_
,
@Andrew__Brown__
,
@quduval
,
@smnh_azadi
,
@rssaketh
, Akbar Shah,
@xi_yin_
,
@deviparikh
,
@imisra_
!!!
0
1
10
0
2
16
And it was so simple to implement! Such a powerful technique 😊 kudos to
@RickyTQChen
@mnick
Yaron Lipman and others! Super insightful discussions with you all

Lots of goodies (aka actual explanations & research results🧐) in the Movie Gen technical report: .
1) Flow matching val loss correlates with human evaluation.
2) Human evaluation strongly prefers flows over diffusion on both quality and text alignment.
1
14
121
0
0
15

We dive deep into self-supervised learning with Dr. Ishan Misra
@imisra_
from FAIR
@facebookai
and cover their recent cluster of vision papers; with
@ykilcher
@RisingSayak
CC:
@ylecun
@skornblith
@mcaron31
@HugoTouvron

2
58
242
1
0
13
[5/n] A cute jack-o-lanterns holding sparklers for Diwali
Thought you may enjoy this one
@RisingSayak
;)
#emuvideo
1
1
11
Omnivore and OmniMAE training code is out 😊
We've released our "Omnivorous" training code for Omnivore () and OmniMAE (), for unified modeling of multiple visual modalities! Check it out at !
@KalyanVasudev
,
@_rohitgirdhar_
,
@alaaelnouby
,
@imisra_
1
3
24
0
0
11
[2/2] We show that using better positional encodings and non-parametric queries is critical for 3D detection.
Transformers are also good encoders of 3D point data and work well for classification.
Accepted as an ICCV’21 Oral
1
0
10
We have some great speakers lined up -
@ylecun
@mcaron31
@jalayrac
@MichaelAuli
@phillip_isola
@StefanieJegelka
Karen Livescu & Andrea Vedaldi
0
0
9
Amazing to see how
@blumhouse
creators found our models to be helpful tools for human<->AI collaboration
Not a stretch to imagine generative video models be a standard tool for moviemakers and content creators.
Movie Gen pilot program is out for the creatives!
Today, we’re sharing initial results from our work with
@Blumhouse
and select creators as we continue to develop our Meta Movie Gen models.
We’re excited to expand this pilot program in collaboration with the creative industry in 2025 ➡️
10
30
194
2
1
8
Very happy to see this effort :) Congratulations
@hjegou
and team!


0
0
8
@xwang_lk
From the blog -
"Our goal in the near future is to make Llama 3 multilingual and multimodal"
0
1
8
[3/n] Enough text, time for some videos!
A red boat in the middle of a blue lake
1
0
7
Thanks for sharing our work,
@AlphaSignalAI
!

This is big. Meta just announced and open-sourced a new powerful Multimodal AI that combines six types of data.
Inspired by humans, ImageBind, is the first to combine six types of data into a single embedding space. It understands images, video, audio, depth, thermal, and
12
119
380
2
0
7

@y_m_asano
@shawshank_v
@MamshadR
@joaocarreira
@1avr1e
Congratulations! Very well deserved on a really interesting line of work 😊
1
0
6
Thank you,
@Ahmad_Al_Dahle
!! This was such an amazing experience :)
0
0
6
@TheHeroShep
@multimodalart
@Andrew__Brown__
@deviparikh
@ylecun
@AIatMeta
We do know where our data comes from! Our model was trained on licensed data :)
0
0
5
A movie about the Emu in
#emuvideo
! :)
Yes, Emus can write and fly with our model!

0
0
5
A really simple but effective approach to open-set classification by
@Sagar_Vaze
et al.!

Does your classifier know when it doesn't know?
We ask how well a standard, properly trained classifier can detect if a test image comes from an 'unseen' class. Surprisingly, it can get SoTA!
#ICLR2022
Oral
Project Page:
Code:
🧵

10
112
535
0
1
4

@ClementDelangue
@SalesforceVC
@Google
@amazon
@nvidia
@AMD
@intel
@QualcommVenture
@IBM
@sound_ventures_
@huggingface
Congratulations!!
0
0
1
0
0
3
See you soon,
@kchonyc
!

a new strategy (targeted rather than untargeted, incentive rather than penalty):
are you in NYC, done with
#NeurIPS2022
review and without life (i.e. no plan later this afternoon)?
if yes, DM me to claim your deserved glass of beer/wine/etc. on me later today.
10
9
157
0
0
2
Congratulations
@Sagar_Vaze
!! :)
Special shoutout to the Covid-cohort at VGG
@PrannayKaul
@RhydianWindsor
@maxhbain
@LiliMomeni
@y_m_asano
@Andrew__Brown__
@robmccr
, as well as everyone at Meta for two awesome summers
@imisra_
@alcinos26
@ashkamath20
@vgabeur
@nikhilaravi
@junting9
@cfeichtenhofer
6
0
10
0
0
2
Update on the NeurIPS SSL Workshop: Paper deadline is 30th Sept now :)
We are organizing the 3rd workshop on SSL at NeurIPS!
Awesome lineup of speakers across different domain in ML.
You're welcome to submit papers too :)
With --
@xiaolonw
@cmuptx
@gulvarol
@yalesong
@y_m_asano
@paulineluc_
0
8
65
0
1
2
0
0
2