
apolinario 🌐
@multimodalart
Followers
12K
Following
4K
Media
824
Statuses
3K
ML for Art and Creativity, working @HuggingFace ([email protected])
Joined July 2021
Excited to introduce LEDITS++, a novel way to edit real images with precision ✏️ . - Multiple edits ✂️🔁.- Automagic free masking 🪄🎭.- 🆕 DPM-Solver fast inversion 🔀⚡. 🤗 Try it: 🔗 Project: 📝 Paper
12
105
467
testing out the Diffusers Image Fill demo capabilities on a random image
42
145
1K
Google just announced a DALLE-2-like model: Imagen. For now no code, just demo site: And paper:

18
135
920
I hacked @huggingface Spaces to build an open source @gradio Dreambooth Training UI that allows you to train a model for less than US$0.80 🐱💻 (you can also use it locally for free):
28
110
811
My favorite part is that it works really well with out-of-the-distribution garments




17
84
801
Editing facial expressions in real time now on @huggingface Spaces 👨🎤🔀. A Grog converted Cog image to Gradio running a ComfyUI backend - magic of open source 🤝. ▶️
10
138
786
Releasing my first FLUX LoRA: .FLUX Tarot v1! 🌙🧙♀️🃏. Based on Raider Waite's 1920 tarot (public domain) . Model and demo: Image & Caption Dataset:




42
97
717
outpainting with the new FLUX-1[dev] Fill model is just on a completely new level 🪼. i've built a Space for you to try it👇
20
85
692
reminder for flux: prompting is case-sensitive 𝙰𝚊. left: Mark Zuckerberg eating pasta.right: mark zuckerberg eating pasta.same seed


26
42
644
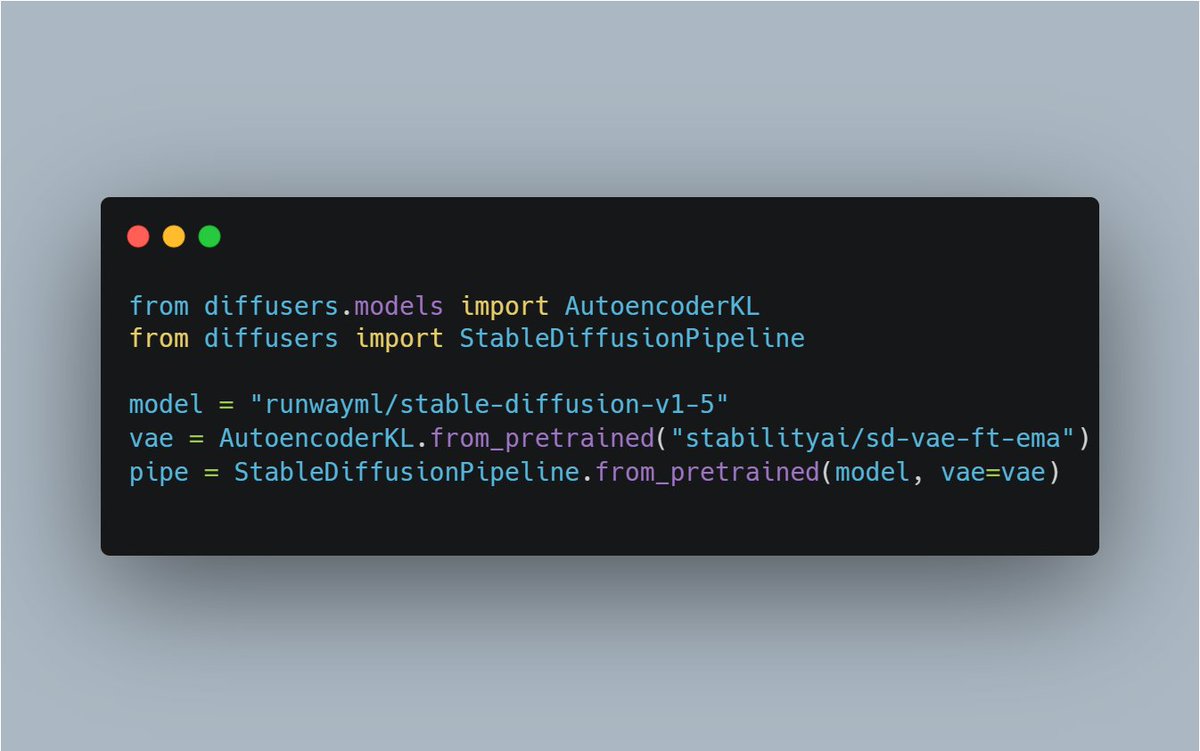
After some, uh, developments yesterday:.- Stable Diffusion v1-5 is out by @runwayml.- Fine-tuned image decoder (VAE) out by @StabilityAI. Magic of open source🧙 collaboration continues no matter what, here's the Best Available Stable Diffusion™ notebook:
9
99
615
1 week of Stable Diffusion. A creative explosion is unfolding with Stable Diffusion,s showing the power of open source as state of the art!. We curated 23+ applications this week: new features, workflow integrations, UIs; run on Win, CPU, AMD, M1 and more!
8
145
607
Very exciting 'breaking' news! . CompVis (research group behind VQGAN) have just released a new 1.45B parameter model to its Latent Diffusion model: From the released image it seems like it has an unprecedented text-synthesis capacity. More to follow soon

12
121
605
GANs are so back?!. Scientists from Brown and Cornell have published a paper with a ✨ modern architecture GAN ✨ that is 🗿 stable to train 🗿 and competitive with SOTA GANs and even diffusion models. Paper and demo 👇
17
80
600
IC-Light v2 was just released by @lvminzhang 🔦, now runs on FLUX, and it is the best relighting tool in the world 🌐, just like that. Try out the official demo ✨📣


14
92
525
Thanks @angrypenguinPNG for merging my PR to add high resolution to the Illusion Diffusion Space 📺🌀 . It's now as fast, double the resolution and has crispy details - go play ▶️ .
18
94
509
Google just announced "Parti" - a text-to-image model co-developed with "Imagen". "Parti" doesn't use diffusion models - rather it scales up Transformer + VQGAN architectures like DALL-E 1 and its open source replicas (dalle-pytorch, ruDALLE, DALL-E Mini)

7
100
508

ControlNet is cool, but what if you could have MORE control? 🤯 . With MultiDiffusion Region Control you can 🎛️ draw masks ✏️ and give a specific prompt for each mask 📜. The @gradio demo is just out on @huggingface 🤗 - kudos to the author @omerbartal!
9
101
440
Less than 1 minute guide on how to train your own LoRA with LoRA Ease 🧞♂️⚡. Train high-quality LoRAs on objects 📦, faces 😊, styles 🎨 or characters 🧑🎤 effortlessly and super cheap ༄. ▶️
16
94
421
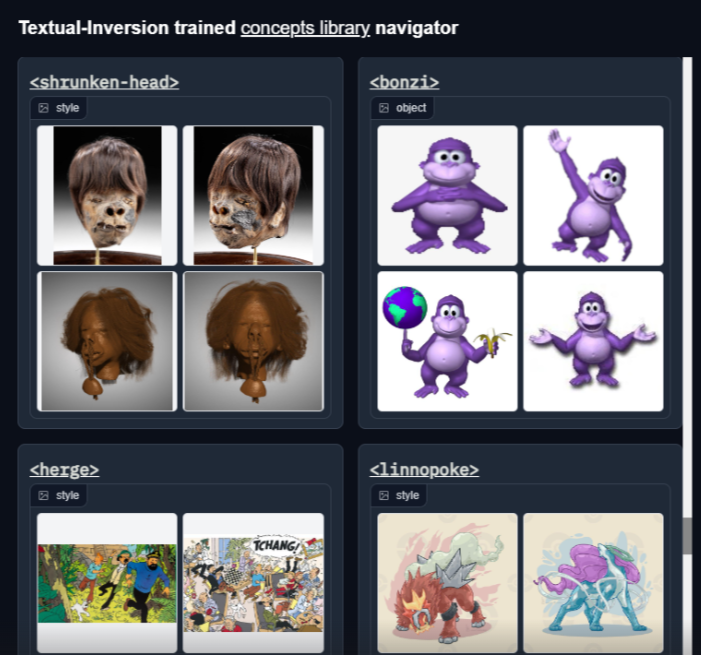
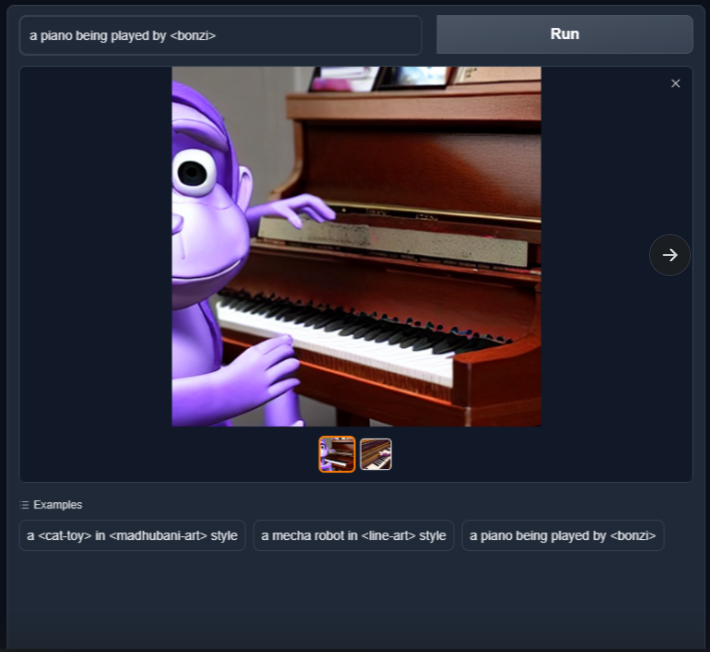
It's out! 🥳 Browse visually the Stable Diffusion Concepts Library - and use more than 100+ community taught concepts in your prompt directly on the same UI!. Colab with Gradio UI:
7
65
414
You can now finally create your own stock photo smiling while eating salad in seconds 👨🎤🥗. IP-Apdater-FaceID Plus was silently released last week - it's first inference technique time face really captures my likeness 🥸🦚. ▶️
8
74
420
How to train your own ControlNet? 🥅. We wrote a guide, ranging from deciding which controls to use 🎛️, how to prepare your dataset, all the way to gpus going brrr 🔥 .(with an unexpected trip to the uncanny valley 👀). From me and @pcuenq with ❤️.
9
91
414
Iterated with @angrypenguinPNG on some enhancements to their Illusion Diffusion Space, @MrUgleh-inspired QR ControlNet patterns 🌀. ▶️

12
59
387
Upgraded the TokenFlow demo to an A100! And defaults changed - the edits should be ~2.5x faster .
8
54
378

The first large scale open source DALL-E 2 replication is here🧙. Karlo is an unCLIP model trained by #KakaoBrain. I'm having fun playing with it on 🤗 @huggingface Spaces: Model card: GitHub:

12
77
370
Introducing LoRA the Explorer 🔎: browse the coolest SDXL LoRAs, play with them online ▶️, use locally 💿. (. and no need to dodge semi-naked waifus 🚫). Join the fun 🕺
6
82
357
The Stable Diffusion Multi Inpainting Spaces is out!. On it you can do both: Inpainting by masking the image (with the newest @Gradio masking) or inpainting with words, your choice!.
7
64
348
🧨 diffusers 0.5.0 now supports JAX for super fast #stablediffusion inference on TPUs. You can generate 8 images in ~8s on Colab Free using TPU 🚀.

2
77
345
The first open Stable Diffusion 3-like architecture model is JUST out 💣 - but it is not SD3! 🤔. It is HunyuanDiT by Tencent, a 1.5B parameter DiT (diffusion transformer) text-to-image model 🖼️✨. In the paper they claim to be SOTA open source! I'm working on a @huggingface demo

13
78
347
I'm super thrilled to announce that our assemble of the Latent Diffusion LAION-400M text-to-image model is now available on @huggingface🤗, democratizing even further the access to text-to-image ai art!. Thank you for all the help @osanseviero!
11
77
343
I'm delighted to announce I've joined @huggingface as a ML Art Engineer 🤗, to help make AI art even more accessible, easy to use and to develop for!. This tech is going to empower human expression and creativity in unprecedented ways - and building it openly feels the right way!

29
29
343
Text-to-3D and Image-to-3D in 7 seconds 🤯 💨. That's LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation 🧊 . And it's open source ✨ .Try it ▶️
38
65
293
ControlNets are cool, but T2I-Adapters are 94% smaller 🤏 , and way faster 💨 . Today TencentARC released 6 T2I Adapters for SDXL: depth, canny, lineart, openpose, and. DOODLY! . Come play:

3
61
320
Introducing FLUX LoRA the Explorer 🧭✨. Explore, generate and download FLUX LoRAs! 🖼️ Including the popular flux-realism and the cute Frosting Lane . Come over, we're just getting started 🛸.▶️
15
78
330
The MarioGPT @huggingface Spaces demo is now playable! 🕹️. Now you can play the levels you generate - hopefully you're better than me 😂
7
58
310
Meta just released a new collection their open access "Seamless" translation models 🔊 . They do speech-to-text, text-to-speech, speech-to-speech, text-to-text 💬🔄📝. The Expressive model keeps speech rate, pauses and style 🗣️. 📁 Models and demos:
6
74
302
Wow! I wasn't expecting the outpainting of the new FLUX Inpainting Beta Controlnet to be this good 🤯. 👇 links to try it


10
26
306
The diffusers 🧨 library just did a release incorporating ControlNet, it runs so fast! 🏎️💨 . Blog: Colab:

3
60
295
Diffusers Outpaint now allows for infinite zoom-out with a resize input size + "use as input" button. @kingnish24 🤝 @fffiloni . ▶️
7
42
289
omg, it seems recraft v3 can perform simple language model tasks 🤯. 1: "this page contains the number of letters r that the word strawberry has". 2: "this page contains the result of 2+5" . 3: "write 2 adjectives in english" . 4: "write the name of the US president"




11
33
291
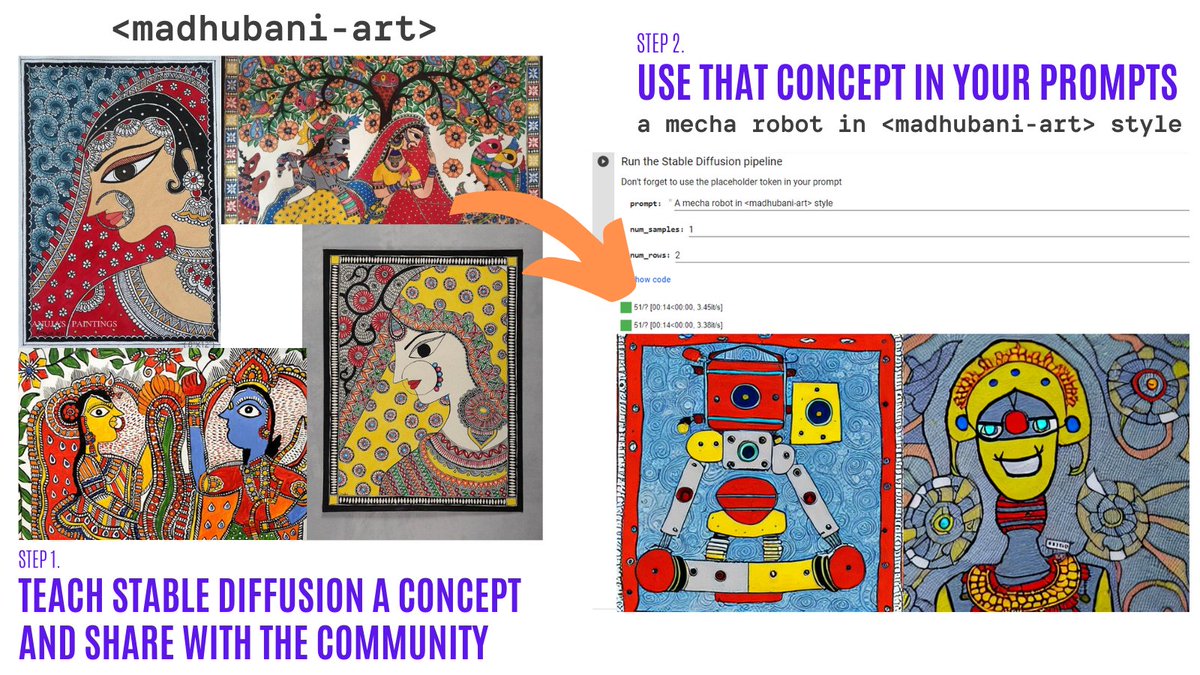
Collaborative new concepts on #StableDiffusion🎨. 1. Teach Stable Diffusion new concepts 👩🏫(add to the public library if you wish): (or browse the library to pick one🧤 . 2. Run with the learned concepts 🖼️
4
56
277
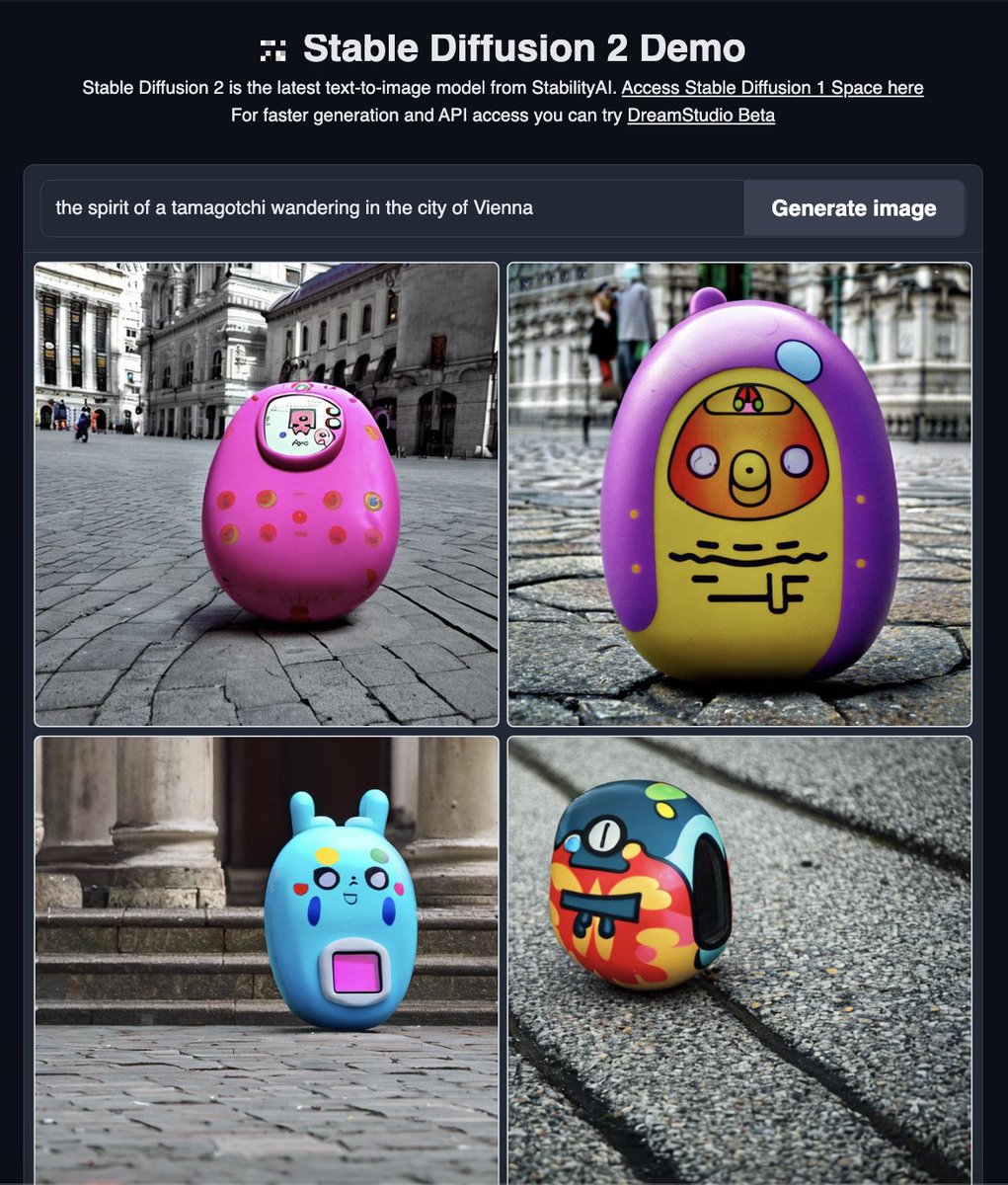
Stable Diffusion 2 by @StabilityAI is out with new 5 models 👽. You can try now the 768x768 model (the largest one released) on @huggingface Spaces
9
44
272
Happy Public Domain day! 🎉 . To celebrate Steamboat Willie finally joining the public domain, I created a @huggingface dataset with all frames of the 1928 short 🐭📜. ▶️


7
48
264
Breaking news: OpenAI open sourced their CLIP ViT-L/14@336px! I'll hook it soon to many generation systems, stay tuned!.
5
32
261
The official ToonCrafter demo is now available @huggingface Spaces ZeroGPU 🤯. This generative cartoon interpolation model is by far the best coherent generative interpolation model I've seen 🖼️ . IMO it will change how animations are made 🪄. ▶️
3
63
262
Ok - I just quickly assembled the LAION-400M trained Latent Diffusion CFG TTI model to a Google Colab, you can try it yourself: "A mecha robot holding a sign that reads: 'This is weird'"

Very exciting 'breaking' news! . CompVis (research group behind VQGAN) have just released a new 1.45B parameter model to its Latent Diffusion model: From the released image it seems like it has an unprecedented text-synthesis capacity. More to follow soon
36
49
245
🎅 Ho-ho-ho! Today a bunch of ICLR 2023 papers dropped! This is a conference with blind submission, authors are anonymous till review. A lot of multimodal AI: text-to-video (yes, another one), text-to-3D, another 'teach-diffusion-new-concepts', texto-to-audio. and more! 🧵.
4
54
247
Stable Diffusion model card is up, and the weights are available for academic and research purposes first. This is the first step ahead of a full public release which should be coming soon! 🤩 #StableDiffusion
4
50
246
This week's updates were not only made of Dall-E 2! We also got:.- Latent Diffusion LAION 400M (an open model!).- KNN Diffusion paper (promising new approach to text-to-image).- 3 new exciting TEXT-to-VIDEO models!.and more!. Check out our weekly update:
4
47
242
OPEN TO EVERYBODY! . I optimized the Latent Diffusion LAION-400M Colab RAM usage and now it should run on free non-Pro accounts. And fast!.8 images in 20 seconds on a P4 GPU. Google Drive support and VRAM optimizations by @RiversHaveWings were also added

Ok - I just quickly assembled the LAION-400M trained Latent Diffusion CFG TTI model to a Google Colab, you can try it yourself: "A mecha robot holding a sign that reads: 'This is weird'"
21
44
239
Stable Video Diffusion is an amazing (and chonky 🐼) new model by @StabilityAI - if you can't run it locally, you can now play with it on @huggingface Spaces 🤗. ▶️
3
41
247
Yesterday OpenCLIP released the first LAION-2B trained perceptor! a ViT-B/32 CLIP that suprasses OpenAI's ViT-B/32 quite significantly:

3
35
238
And the Spaces for the Stable Diffusion Concepts Library is out!. Navigate 250+ community taught object and styles with Textual Inversion and use them in your prompts!

3
44
233
Guess who's back? Back again! 🎵 @StabilityAI is back, tell a friend 🎤. Stable Diffusion 3.5 Large is here 🔥.- 🏋️ 8B parameters.- Full 💪 and 🏎️💨 4-step Turbo variant.- 🧾 🤝 commercial use (for orgs below 1M year/rev).- 🧨 day-0 LoRA fine-tuning support

9
47
238
Following the full open source release of Stable Diffusion, the @huggingface Spaces for it is out🤗. Stable Diffusion is a state-of-the-art text-to-image model that was released today by @StabilityAI #stablediffusion .

4
61
229
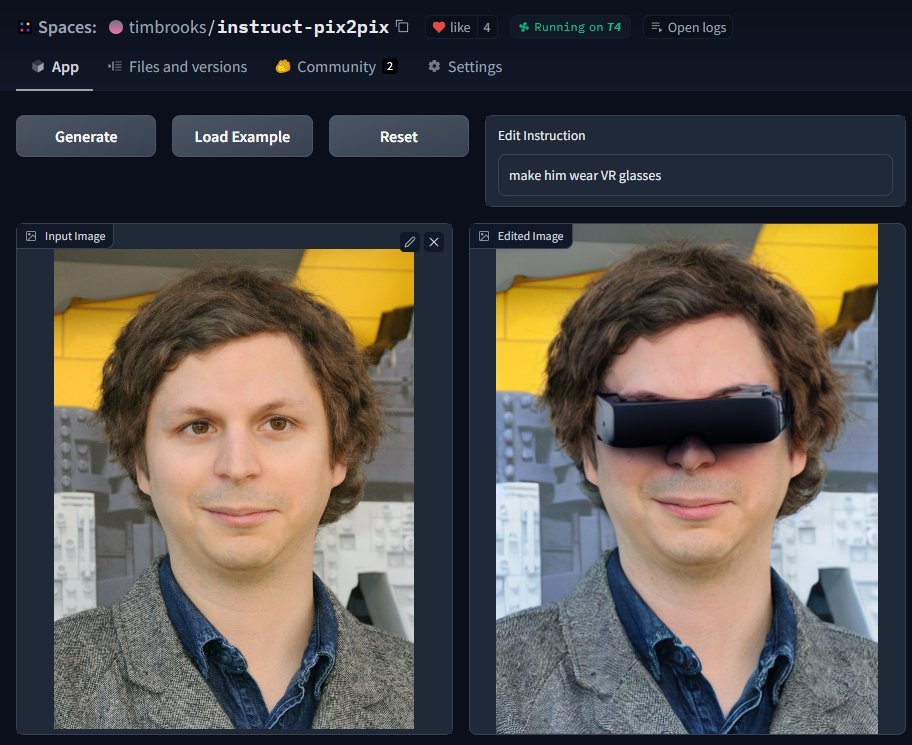
InstructPix2Pix by Tim Brooks allows you to write natural language instructions to edit images ✏️🖼️ . We are getting closer and closer to "photoshop with words"! 🎨. Play with it now on @huggingface Spaces
5
40
217
Since VQGAN+CLIP times, we've been learning to prompt with @openai CLIP knowledge (incl. SDv1, conditioned on OAI CLIP). Stable Diffusion 2 breaks that 💥 with LAION-trained CLIP, "trending on artstation", "greg rutkowski" don't work; we're all learning to prompt again! 👶.
13
23
214
✨ PD12M ✨, a 12.4 million high quality image-caption dataset for AI training 🎛️, featuring:. - 🤖✏️ Florence-2 synthetic captions .- 🌸 Aesthetic and safety filtered from 34M superset .- 🔓 only public domain images. superb release by @spawning_ .
6
43
215
ComfyUI → @huggingface Spaces → serverless ZeroGPU ✨😌. We wrote a tutorial on how to turn any ComfyUI workflow into an easy to use Gradio app and (optionally) host it for free with ZeroGPU 💥.
3
37
217
SDXL Flash 📸 is here! . While SDXL LCM/Turbo/Lightning/Hyper do a great job in 1-4 steps, SDXL Flash gets uncompromised quality in 10 steps 💥. A new sweet intermediary spot to unlock use-cases 🍬 . Model: .Demo:

9
32
208
PAG (Perturbed-Attention Guidance) is not getting nearly the attention it deserves, I've adapted it to work on SDXL with diffusers 🧨. and it DELIVERS! 🤯 . Try it here ▶️.. thanks to KU-CVLAB researchers: Donghoon Ahn Hyoungwon Cho et. al ❤️

Recent studies reveal that the quality of samples from diffusion models relies on techniques like CG and CFG, yet these fall short in unconditional generation and tasks like image restoration. This research paper introduces Perturbed-Attention Guidance (PAG), a novel method

9
52
195
💥 If SDXL was trained with LLM as a text encoder, what would happen? 🧪 . Kolors is the answer 🎨 - Kwai trained (from scratch!) an SDXL-arch model with the GLM-4 LLM as the text encoder, and it's fantastic! . ▶️ Demo 📁 Model


12
44
195
The Logo in Context Spaces demo + 🧨 diffusers implementation is here! 🖼️🏷️. In-Context LoRA + Image-to-Image + Inpainting → allow you to apply your logos to anything.


9
42
196
MindsEye - an open source interface to 'pilot' AI art models without using code - is now available to everyone. Check it out, share it around and let me know what you think!. Colab: Discord: Guide and FAQ:
17
34
191
with the amazing @bfl_ml FLUX Tools released yesterday, . maybe you missed the release of the first IP Adapter for FLUX [dev] by @instantx_ai! ⭐️. (and it's actually amazing). You can try the official demo here 🎨🔧.
3
37
194
Introducing Majesty Diffusion👑. Dango233 princesses were crowned queens, and Majesty Diffusion is born!. Two colabs are being released with new plenty of new features - but I need your help with one thing, come with me🧶

8
49
184
HUGE update from @StabilityAI ✨. Stable Diffusion 3 🖼️, Stable Video Diffusion 🎥, SDXL Turbo 💨 and more can now be used commercially without a subscription by anyone with less than US$1M annual revenue 🔓 💥.

2
39
186
AuraSR an open source replication of @Adobe's GigaGAN super-resolution by @FAL 🔥. 🤏 600M params.💥 4x upscaling .🖼️ Excels at adding sharpness/fine details to mid-sized images.🔓 Commercially permissive license (cc-by-sa). ▶️

Time for some Aura. First in our series of fully open sourced / commercially available models: AuraSR - a 600M parameter upscaler based on GigaGAN. Blog: HF: Code: Playground:
2
50
187
CogVideoX just released the weights for its 5B model! 🎥 ✨. It's the best open weights text-to-video model - competitive with Runway / Luma / Pika. With 🧨@diffuserslib, it fits on < 10GB VRAM 🤏. (ah, and they changed the smaller 2B model license to Apache 2.0 🔥)




5
45
174
Pyramid Flow 𓁿 was announced today as a high quality 2B 🤏 text-to-video and image-to-video model 🎥. You can now try it by yourself on a @huggingface Gradio demo ꔮ. ▶️
3
42
180
My first HunyuanVideo generation 🎥 . "A capybara walks on the grass, realistic style" .🌱₍ᐢ-(ェ)-ᐢ₎🌱. Definitely SOTA open source quality! 🔥 Took 60GB VRAM and 40min tho —how much less will it be in a week the magic of open source? 🪄
24
24
178
I've released MindsEye Lite👁️🧠: a UI that runs multiple text-to-image models without Colabs or logins - directly on Hugging Face Spaces. Run Diffusion, DALLE replicas, VQGAN+CLIP. Try it out and consider sending it to someone that tried used AI art yet!
3
42
167
Releasing my Vintage Ads LoRA 📰📮 . Based on public domain ads from old magazines . Model and demo: Dataset: . (trained on @FAL and migrated to the @huggingface Hub using their native tooling 🤗)




5
29
171
🚨 A new text to image model by @StabilityAI is out!. It's Stable Cascade 💧 an iteration on the Würstchen architecture by @dome_271 & @pabloppp . I made a demo for it:
20
40
167
Introducing LoRA Roulette 🎲. Two custom models are loaded at random every refresh 🔄 - can you find a fun way to combine them? 🎨. ▶️
6
29
160
Introducing ✨ LoRA Studio ✨ a dedicated UI by @enzostvs for LoRAs hosted on @huggingface 🤗 browse and generate images with fun models 🎉 . (and safe models, no need to worry if your mom or your colleague enter the room while you are browsing 😳 🔞). ▶️
12
40
164
Have you tried OOT-Diffusion? 👕. A state of the art diffusion virtual try-on that just works with any person and any clothes ✨ - fully open source 💥. Official demo by Yuhao Xu: .▶️
2
42
161
Another Stable Diffusion 3-like architecture model is out! 🤯. Lumina Next by Shanghai AI Lab is a DiT architecture 2B parameter model that uses an LLM (Gemma-2B) as the text-encoder! 🤖. This makes the model multi-lingual and able to follow complex prompts out of the box 🌐. Try

7
33
160
Tencent releases PhotoMaker v2!.better identity fidelity 🤝 better controllability . it works really good when multiple images of the subject are uploaded! kudos to @yshan2u @zhenli1031!. demo: code:
5
33
163
New model alert! 🚨 ⋆✴︎˚。FLEX.1 Alpha ˚。✴︎⋆ is an 8B parameter model pruned and further trained by @ostrisai from 12B FLUX.1 [schnell]:. 🖼️ High quality, competitive with FLUX[dev].🎨 Good at styles.🤏 Smol.📜 openly licensed (Apache 2.0).⚗️ de-destiled, CFG optional
9
41
288
This is fun! A new leap!. You show the model 3-5 images of what you want, it 'learns' what it is and now you use it on your prompts! And the approach is be pluggable to different models (here they applied it to Latent Diffusion) . Code is not yet out - excited for it!


An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion.abs: . “Textual Inversions”, operates by inverting the concepts into new pseudo-words within the textual embedding space of a pre-trained text-to-image model

4
18
159
@fofrAI expanding on this technique gives you even more super powers, helps with flux having some troubles with some abstract styles. IMG_0134.TIFF: a dog in the park --style impressionist painting, impressionism --details low

4
5
158
Stable Fast 3D has just been released by @StabilityAI, an incredible image-to-3D model that takes 0.5 to generate 3D assets 🤯 . Can you imagine games with assets generated on the fly? ✈️. Try out their official demo here and check it by yourself!

We are excited to introduce Stable Fast 3D, Stability AI’s latest breakthrough in 3D asset generation technology. This innovative model transforms a single input image into a detailed 3D asset in just 0.5 seconds, setting a new standard for speed and quality in the field of 3D
4
44
157
Generate 4 SDXL images in < 5s seconds, no queue, for free! 🏎️💨. (I did NOT speed up this video!).▶️
3
26
155
✨ Introducing FLUX LoRA Lab 🧪🔬. Mix-up and combine multiple FLUX LoRAs and do your own crazy LoRA alchemy. (You can also use the 🎲 function to randomly merge 2 LoRAs for some surprise, novelty and fun) . ▶️


8
35
156
TRELLIS may be the biggest thing to happen to image-to-3D yet 🖼️ → 🧊. Microsoft simply cooked it SOTA, free and open source and casually dropped on @huggingface last week 🤗. ✶⋆.˚. try it for yourself ⋆✴︎˚。⋆ · .
9
30
153
Two days ago, @stabilityai quietly released CosXL and CosXL Edit, fine-tuned SDXL models that can produce full color range images ⬛⬜. You can now try them out on @huggingface! 🕹️. ▶️
6
35
145
negative prompts and real CFG are back! 🔙. reintroducing real CFG to FLUX [dev] 💥 allows it to work super well with styles . `a watercolor painting of a forest`.← left: no cfg // right: cfg →


9
14
145
The community has uploaded more than 7000 Flux[dev] LoRAs to @huggingface 🤗🎊 . Browse them all 🔍 and test them out for free 🖼️ ✨. ▶️
7
35
145
Video-to-video is now available in the official CogVideoX-5B Space 🔥. Try it out 🎥 ➡️🎥 .
4
36
140
SDXL Lightning is a new distilled SDXL model by ByteDance: LCM+progressive distillation+adversarial objective ⚡️. They have a 1, 2, 4 and 8 step variations, below I'll test the prompt: "An unicorn plush toy on the beach" 🦄 for every step 🧵. (my favorite is 4 steps 🦶)

4
20
137
DeepFloyd IF is here! . 💫 Demo . Fits on Colab Free with diffusers 🧨 👩💻 GitHub:

7
36
138
The @huggingface Hub now has `model templates`: instead of a blank `/new` page: a page tailored towards .uploading a specific kind of model 📙🎨. The first model template is one of the most requested: SD LoRAs! Share it with your fine-tuner friends 🤗.
7
26
136
fast & longer text-to-video with 🧨 diffusers . you maybe saw fun junky text-to-video from the ModelScope's research model lately. with diffusers you can control how long the video is - and fit it on smol VRAM GPUs, including free colab. Try out here:.

5
32
138
MindsEye - an open source interface to 'pilot' AI art models without using code - is now available to everyone. Check it out, share it around and let me know what you think!. Colab: Discord: Guide and FAQ:
12
26
125
Würtschen: a new, trained from scratch high res (1024x1024) model by @dome39931447 . Inference is at a fraction of SDXL. And trained with 6x less compute than SD1.4. Quality trade-offs 🤔? Try it for yourself! . PS: this video is not sped up! .
4
32
133
Is it a LoRA or a Latent Consistency Model? 🤔 Well, both! 🔄. Just hook the LCM LoRA to SDXL or SD1.5 and boom! Now it can do inference in 4-8 steps 🤯. 📚.
3
27
129