
Ying Shan
@yshan2u
Followers
1,530
Following
608
Media
190
Statuses
950
Distinguished Scientist @TencentGlobal , Founder of PCG ARC Lab, Director of AI Lab Visual Computing. Formerly @Microsoft , @MSFTResearch . Views are my own.
Joined June 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Francia
• 680321 Tweets
#HouseOfTheDragon
• 566624 Tweets
Rhaenys
• 264314 Tweets
#GranHermano
• 249516 Tweets
Bautista
• 178205 Tweets
seokjin
• 173262 Tweets
Meleys
• 172921 Tweets
Emma
• 162337 Tweets
#HOTD
• 136887 Tweets
#OccupyMOH
• 110350 Tweets
FRED GLOBAL AMBASSADOR JIN
• 106575 Tweets
Aegon
• 105050 Tweets
Vhagar
• 100415 Tweets
Aemond
• 99466 Tweets
#JinxFredJewelry
• 74443 Tweets
Serena
• 66561 Tweets
Daemon
• 65816 Tweets
Uruguayo
• 60385 Tweets
Marcos
• 48109 Tweets
Sunfyre
• 42985 Tweets
Criston Cole
• 30914 Tweets
KMPDU
• 23006 Tweets
間宮結婚
• 20597 Tweets
セレクトセール
• 20093 Tweets
Kaylor
• 18978 Tweets
間宮祥太朗
• 16106 Tweets
hyuna
• 16071 Tweets
萩のツッキー
• 14727 Tweets
ドウデュース
• 13314 Tweets
PakPRABOWO SiapkanPROGRAM
• 12687 Tweets
UntukNKRI LebihSEJAHTERA
• 12152 Tweets
Happy New Week
• 10673 Tweets


















Pinned Tweet

I’m attending CVPR next week! The ARC and AI Lab teams will be presenting quite a few papers on-site, including the ones listed below. Feel free to DM me if you'd like to chat. Looking forward to engaging discussions! 🤝✨🎉
Our CVPR24 highlights:
SmartEdit: Exploring Complex Instruction-based Image Editing with LLMs
Programmable Motion Generation for Open-set Motion Control Tasks
HumanGaussian: Text-Driven 3D Human Generation with GS
Turns out there's no overlap with the ones listed earlier😆😆
0
4
28
1
4
34
Announcing Mira: A glimpse into the world of Sora, providing insights through open-sourced resources including MiraData (training samples), MiraDiT (the model), and code, all aimed at fostering collaboration and accelerating innovation in this promising field. 🩷🩷
Project Page:
3
24
116
CustomNet demo is live: id preserved object placement with controllable viewpoints, location, and background. Feel free to give it a try!


🎉Tencent's CustomNet official demo is on Spaces
🌟A unified encoder-based framework for object customization in text-to-image diffusion models
🌟Incorporates 3D view synthesis capabilities
🌟Adjusts spatial positions and viewpoints
🌟Preserves object's Identity effectively
1
14
60
3
18
111

An image-to-texture dreamer, clearly explained🚀🚀

Showcasing the capabilities of TextureDreamer (
#CVPR2024
)!
... include my favorite results of transferring Rirakkuma 🧸to all types of shapes.
Full explainer video:
0
20
124
0
12
75
Introducing Mani-GS: 3DGS editing made easy, through triangular mesh with self-adaptation🚀🚀
Project page:
Paper:

Mani-GS: Gaussian Splatting Manipulation with Triangular Mesh
Xiangjun Gao, Xiaoyu Li, Yiyu Zhuang, Qi Zhang, Wenbo Hu, Chaopeng Zhang, Yao Yao,
@yshan2u
, Long Quan
tl;dr: use a triangular mesh to manipulate 3DGS directly with self-adaptation




0
6
36
0
18
68
LiDAR to Gaussian Splatting: claimed centimeter-level accuracy for both indoor and outdoor scanning

LiDAR to Gaussian Splatting, Lixel CyberColor, from
@XGRIDS2023
has been announced.
✨ LiDAR to Gaussian Splatting
📏 CM level precision
🥽 Compatible with Apple Vision Pro
🤝 Compatible with XGRIDs scanning suite
🔗
2
33
145
0
9
66
A new benchmark for Video MLLMs📏📐


Video-MME
The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus

2
38
121
0
17
68
Thanks
@_akhaliq
for featuring! The survey on 3D Model Generation encompasses 436 papers on the latest advancements. Hope it's helpful!🌟📷
Thanks to the team: Xiaoyu Li, Qi Zhang, Di Kang, Weihao Cheng, Yiming Gao, Jingbo Zhang, Zhihao Liang, Jing Liao,
@yanpei_cao
,
@yshan2u

Advances in 3D Generation: A Survey
paper page:
Generating 3D models lies at the core of computer graphics and has been the focus of decades of research. With the emergence of advanced neural representations and generative models, the field of 3D content

1
64
281
1
9
64
🚀🚀 ARC Lab is hiring Junior Researchers with:
🩷a recent Ph.D. in 2D/3D generative AI
🩷3-5+ top conference/journal papers
🩷500+ GitHub stars
🩷a "make it happen" mindset
Feel free to DM me!
Website:
Recent work: links below
7
5
65
Introducing BrushNet, fills in anywhere with precision and coherence, and works with any frozen DMs (diffusion model)! Code, paper, demo available!
cc:
@juxuan_27
,
@AlvinLiu27
,
@xinntao
, Yuxuan Bian,
@yshan2u
, Qiang Xu


#BrushNet
A plug-and-play inpainting/outpainting model
Please try it out:
Codes and models are released:
Thanks to co-authors
@juxuan_27
,
@AlvinLiu27
, Yuxuan Bian,
@yshan2u
, Qiang Xu
1
8
41
1
14
65
We've just launched InstantMesh, our latest addition to the Image-to-3D family — arguably one of the best open source models to date, based on our tests😉. Feel free to try it out.🚀
CC: Jiale Xu, Weihao Cheng, Yiming Gao,
@xinntao
, Shenghua Gao,
@yshan2u
#InstantMesh
🎉, an image-to-3D mesh generation method from a single image within 10 seconds.
Incorporate mesh-based optimization, better training efficiency, and scalability, allowing explicit geometric supervision.
Codes: Demo:
3
33
178
1
6
58
Thanks
@_akhaliq
for sharing!
#PhotoMaker
creates images with customized person and style in just seconds.
Tencent just released PhotoMaker
Customizing Realistic Human Photos via Stacked ID Embedding
demo realistic:
demo style:
23
187
982
5
4
50
Thanks
@_akhaliq
for sharing! This is for 3D scene editing with better control.
Thanks to the team: Jingyu Zhuang, Di Kang,
@yanpei_cao
, Guanbin Li, Liang Lin,
@yshan2u
Tencent presents TIP-Editor
An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts
paper page:
Text-driven 3D scene editing has gained significant attention owing to its convenience and user-friendliness. However, existing methods still
2
85
391
2
8
49
SAM is able to simplify complex low-level vision tasks. In this case, adapting SAM to take flow as input, or use flow as segmentation prompt outperforms all previous approaches by a significant margin in both single and multi-object benchmarks.

SAM + Optical Flow = FlowSAM
FlowSAM can discover and segment moving objects in a video and outperforms all previous approaches by a considerable margin in both single and multi-object benchmarks 🔥
10
227
1K
0
4
47
Thanks to
@_akhaliq
for sharing!
#VideoCrafter2
is NOW open-sourced - featuring improved visual quality, motion and concept combos! Feel free to try it out!🌐✨
Demo:
Project Page:
Thanks to the team:
@haoxin_chen
@Norris29973102
Tencent presents VideoCrafter2
Overcoming Data Limitations for High-Quality Video Diffusion Models
paper page:
Text-to-video generation aims to produce a video based on a given prompt. Recently, several commercial video models have been able to generate

1
30
149
0
8
46
Thanks to
@_akhaliq
for sharing. M2UGen is our first attempt to unify music understanding and generation with LLMs.
#GenerativeAI
Tencent and NUS release M2UGen
Multi-modal Music Understanding and Generation with the Power of Large Language Models
demo:
The M2UGen model is a Music Understanding and Generation model that is capable of Music Question Answering and also Music
6
69
300
0
15
44
Cool video editing demo! Thanks
@ptsi
for putting this together!
cc:
@skalskip92
@tiahch
@ge_yixiao
@XinggangWang
@yshan2u

So.. full video editing using AI 📹🎨 is still a bit away. But we are now closer! 🔥🔥
We just built a demo for
@CamcorderAI
that lets you crop (rotobrush) any object out of a video just by using your words! 😁
What do you think - should we make it into a full tool?
🧵
24
33
256
1
10
42
Introducing Open-MAGVIT2: an open-source effort investigating and advancing the lookup-free visual tokenizer with large codebooks. From SEED (discrete) to SEEDX (continuous), we keep exploring the frontier of MLLM and sharing our progress along the way.


MAGVIT2 is a leading visual tokenizer, but hasn't been officially open-sourced. Existing reproductions lack complete codes and checkpoints. We did this! 🔥
We are keeping iterating the codebase and welcome collaboration on the Open-MAGVIT2 plan. 🤗




1
29
146
0
9
42
Run Brushnet locally on your machine with 1 click!

Segment and Edit Anything, on your Local Computer.
The Brushnet Gradio app lets you select some points in an image to segment items, and replace them with ANYTHING you want. Pure magic.
And now, run locally on your machine with 1 click. Works on all OS (Windows, Mac, Linux)
13
41
197
0
3
40
TIP-Editor accepted as a SIGGRAPH-2024 Journal paper: An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts🎉🎉
Congrats:
@JjZhuang26958
, Di Kang,
@yanpei_cao
, Guanbin Li, Liang Lin,
@yshan2u
Tencent presents TIP-Editor
An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts
paper page:
Text-driven 3D scene editing has gained significant attention owing to its convenience and user-friendliness. However, existing methods still
2
85
391
1
6
38
Study reveals Sora's stunning geometrical consistency!
Sora Generates Videos with Stunning Geometrical Consistency
The recently developed Sora model [1] has exhibited remarkable capabilities in video generation, sparking intense discussions regarding its ability to simulate real-world phenomena. Despite its growing popularity, there

6
49
268
0
6
33
Thanks
@_akhaliq
,
@liuziwei7
! Glad to see our I2V DynamiCrafter at Top1, and t2V VideoCrafter2 at Top3 on your VBench leaderboard.


📢VBench now Supports I2V Eval📢
📊
#VBench
now supports the multi-dimensional evaluation of Image-to-Video (I2V) models
🏆
#DynamiCrafter
and
#SVD
are among the top models
- Code:
- Leaderboard
@huggingface
: . Thanks to
@_akhaliq
!

2
13
41
0
5
33
🚀 A stellar 2023 at ARC Lab & AI Lab Visual Computing! Proud of our impactful work in T2IAdapter, VideoCrafter, Tune-a-video, FateZero, SEED-Bench, Dream3D, SadTalker etc. [see links], all open sourced. Big thanks to our teams and collaborators. Looking forward to an even more
0
4
34
Adding "parts" to 3D generation🚀🚀

✨The rapid progress in 3D generation is impressive, but generated meshes often lack structure. We integrate *parts* into the reconstruction process, enhancing segmentation, structural distinction, and shape editing!
Project Page:
#SIGGRAPH2024
#AIGC
0
14
68
1
5
34
Text to Video is in GenAI arena!
Collecting votes at:


We are happy to integrate "text-to-video" into GenAI arena . Currently, we support six open-source video generation models. Please help us vote to create the video leaderboard!
For "text-to-image" arena, Playground V2 and V2.5
@playground_ai
are leading


3
6
52
0
5
32
Our CVPR24 highlights:
SmartEdit: Exploring Complex Instruction-based Image Editing with LLMs
Programmable Motion Generation for Open-set Motion Control Tasks
HumanGaussian: Text-Driven 3D Human Generation with GS
Turns out there's no overlap with the ones listed earlier😆😆
0
4
28
Thanks
@_akhaliq
for featuring! SEED-X is a unified MLLM designed for both real world understanding and generation tasks, with competitive results. Feel free to try it out!
Project page:
CC:
@tttoaster_
, Sijie Zhao, Jinguo Zhu,
@ge_yixiao
, Kun Yi, Lin
SEED-X
Multimodal Models with Unified Multi-granularity Comprehension and Generation
The rapid evolution of multimodal foundation model has demonstrated significant progresses in vision-language understanding and generation, e.g., our previous work SEED-LLaMA. However,

3
13
72
0
2
26
Thanks
@_akhaliq
for featuring! DynamiCrafter is a major upgrade to our image-to-video model.🚀 Echoing recent improvements in our text-to-video model, VideoCrafter2, the new model significantly improves motion, resolution, and coherence. 💡
Team credit:
@Double47685693
,
DynamiCrafter
Demo:
model:
Animating Open-domain Images with Video Diffusion Priors
9
74
314
1
2
23
Egocentric multimodal open dataset!
Meta announces Aria Everyday Activities Dataset
present Aria Everyday Activities (AEA) Dataset, an egocentric multimodal open dataset recorded using Project Aria glasses. AEA contains 143 daily activity sequences recorded by multiple wearers in five geographically diverse indoor
11
90
469
0
1
19
Tencent released MotionCtrl for Stable Diffusion Video
A Unified and Flexible Motion Controller for Video Generation
demo:
API docs:
MotionCtrl can Independently control complex camera motion and object motion of generated
5
94
436
0
4
20
Multi-Concept Composition made easy!
Gen4Gen
Generative Data Pipeline for Generative Multi-Concept Composition
Recent text-to-image diffusion models are able to learn and synthesize images containing novel, personalized concepts (e.g., their own pets or specific items) with just a few examples for training. This
5
65
241
0
2
21
Thanks to
@_akhaliq
for sharing!
#VideoCrafter2
is NOW open-sourced - featuring improved visual quality, motion and concept combos! Feel free to try it out!🌐📷
Project Page:
Thanks to the team:
@haoxin_chen
@Norris29973102
@shadocun
@RichardXia101
Tencent just released VideoCrafter2 demo on Hugging Face
high quality text to video model
demo:
Overcoming Data Limitations for High-Quality Video Diffusion Models
code, models and data are distributed under Apache 2.0 License
1
22
98
0
3
20
Thanks
@_akhaliq
for the update! DynamiCrafter applied to frame interpolation and looping video generation, check it out!
cc:
@Double47685693
,
@Norris29973102
,
@xinntao
Tencent announces DynamiCrafter update
𝐠𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐟𝐫𝐚𝐦𝐞 𝐢𝐧𝐭𝐞𝐫𝐩𝐨𝐥𝐚𝐭𝐢𝐨𝐧 and 𝐥𝐨𝐨𝐩𝐢𝐧𝐠 video generation model weights (320x512) released
2
59
308
1
3
19
Appreciate the insights from the paper, but starting with Sora in the title might be misleading. 🤔😊
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and

16
217
1K
1
0
17
My view of the world model, world simulator, etc., based on the original 'World Model' paper. Hoping this sheds some light on the subject, though it might cause more confusion. 😆😆

2
1
18
Claude-3 had 20,000+ votes in three days on Arena!

🔥Exciting news from Arena
@Anthropic
's Claude-3 Ranking is here!📈
Claude-3 has ignited immense community interest, propelling Arena to unprecedented traffic with over 20,000 votes in just three days!
We're amazed by Claude-3's extraordinary performance. Opus is making history
26
111
657
0
3
18
A new T2V model ranked top-1 on VBench🚀🚀
Thrilled to work with
@JiachenLi11
to release T2V-Turbo, which is a very fast yet high-quality consistency model.
With only 4 diffusion steps (5 seconds), it can obtain high-quality video. T2V-Turbo currently ranks the first on VBench (), beating other

3
42
169
0
7
17

Thanks
@_akhaliq
for featuring. YOLO-World is for real-time open world detection!
Thanks to the team and collaborators: Tianheng Cheng, Lin Song,
@ge_yixiao
, Wenyu Liu,
@XinggangWang
,
@yshan2u
Tencent presents YOLO-World
Real-Time Open-Vocabulary Object Detection
paper page:
On LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed.

3
58
284
0
2
16
The Keynote on 𝐏𝐡𝐨𝐭𝐨𝐫𝐞𝐚𝐥𝐢𝐬𝐭𝐢𝐜 𝐀𝐈 𝐀𝐯𝐚𝐭𝐚𝐫𝐬 was well received🎉👍

I gave a keynote at China3DV about our research on 𝐏𝐡𝐨𝐭𝐨𝐫𝐞𝐚𝐥𝐢𝐬𝐭𝐢𝐜 𝐀𝐈 𝐀𝐯𝐚𝐭𝐚𝐫𝐬.
Since many people asked, I have uploaded the slides of my talk here (PDF version):

3
20
156
0
2
16
Thanks to
@_akhaliq
for sharing! EvalCrafter is our step towards tackling the challenge of video generation evaluation. It's designed to streamline the process for faster iterations, benefiting both our own development and hopefully the broader community. It's very much a work in
Tencent released EvalCrafter Leaderboard on Hugging Face
demo:
Benchmarking and Evaluating Large Video Generation Models

3
16
81
0
2
16
Explore the magic of
#PhotoMaker
by ARC! ✨
Create images with customized person and style in just seconds. 🎨
Try the Huggingface demo NOW! 🚀
Thanks to
@xinntao
,
@zhenli1031
, and the team for making this happen, and to
@osanseviero
for sharing. 🙌
🥳
#PhotoMaker
HuggingFace Gradio demo is ready. Try it out!
Realistic version:
Stylization version:
Project Page:
GitHub:
Grateful to co-authors
@zhenli1031
@yshan2u
6
56
229
1
1
16
Thrilled to witness the waves of ICLR acceptance posts! Great insights from each paper's crisp summary. Feel like folks will have a lot of fun in Vienna!
@iclr_conf
#ICLR2024
#ICLR
🌊📚🚀
1
0
15

This is how plants move in 24hours. A great source of training data for Image-to-video models😆😆

2
0
14
A super stable, high-res flying camera that responds to your gaze and head movements!

La qualité des Drones DJI est de plus en plus impressionnante !
Ici il s’agit d’un drone FPV dernier cri où il semble que DJI a sans doute intégré la stabilisation Rocksteady et Horizon pour minimiser les vibrations de la caméra et garantir des séquences fluides même lors de
27
233
1K
0
3
13
As we promised, SEED-X is now open sourced with the model checkpoint, training code for instruction tuning , and newly collected data for instructional image editing!
Feel free to check out this link for more details:

Our model checkpoints, training code for instruction tuning, online demo, and newly collected data for instructional image editing have been fully open source! 🔥
Welcome to cook with SEED-X models and data. 🤗
1
5
16
2
0
13
Thanks
@_akhaliq
for sharing. YOLO-World is for real-time open world detection!
Thanks to the team and collaborators: Tianheng Cheng, Lin Song,
@ge_yixiao
, Wenyu Liu,
@XinggangWang
,
@yshan2u
Tencent releases YOLO-World
Real-Time Open-Vocabulary Object Detection
demo:
method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on

1
65
345
0
3
13
Image-to-image material transfer.

Today, with my collaborators
@prafull7
(MIT CSAIL),
@jampani_varun
(
@StabilityAI
), and my supervisors Niki Trigoni and Andrew Markham, we share with you ZeST, a zero-shot, training free method for image-to-image material transfer!
Project Page:
1/8
5
65
271
0
1
13
A annotation framework that produces hyper-detailed descriptions, and "performs better than GPT-4V outputs (+48%) on readability, comprehensiveness etc."


📢 Excited to unveil our latest research, ImageInWords (IIW)! 🚀We're pushing the boundaries of image descriptions with a new seeded, sequential, human-in-the-loop approach producing SOTA, articulate, hyper-detailed descriptions.
arXiv: 🧵1/12

5
32
128
2
0
13


A prototype of AR glasses that is compact (without a projector-based light engine) and 3D! 🕶️✨


Stanford engineers have developed a prototype augmented reality headset that uses holographic imaging to overlay full-color, 3D moving images on the lenses of what would appear to be an ordinary pair of glasses.
@stanford_ee
@GordonWetzstein
0
5
17
0
2
13
Interesting work.

🐎 Let the hooves pound!
Our new method Ponymation learns a generative model of 3D articulated animal motions from raw unlabeled Internet videos.
Page:
Paper:
Led by
@skq719
& Dor Litvak, w/
@zhang_yunzhi
Hongsheng Li
@jiajunwu_cs
3
21
122
0
0
12

Thanks to
@camendur
for sharing!

🎞 FreeNoise + AnimateDiff 🔥 FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling 🐰 Colab 🥳
Thanks to Haonan Qiu ❤ Menghan Xia ❤ Yong Zhang ❤ Yingqing He ❤
@xinntao
❤
@yshan2u
❤
@liuziwei7
❤
🌐page:
📄paper:
1
42
168
0
0
12
Once a model is trained, there is a fun phase to discover its capability. I've been experimenting with our SEED-X-I model by blending two images, which I call A Tale of Two Images. Here are some interesting results, with details in the thread below!



1
2
12
Given the renewed interest in binarization, here is our earlier work (KDD23) focused on binary embedding for retrieval. It achieves a 16x reduction in memory footprint and has been rigorously tested in production with billions of vectors! Code is available!
cc: Yukang Gan,
0
3
12
Neocognitron, the model directly inspired CNN was invented 44 year ago by Kunihiko Fukushima.


This month in 1980: a Japanese computer scientist published a paper proposing the “Neocognitron,” the neural net that directly inspired CNNs.
Kunihiko Fukushima’s paper:

5
125
483
1
2
12
More to come!😊🌟

MultiModal Large Language Models have undergone substantial advancements, augmenting off-the-shelf LLMs to support MM inputs or outputs. The models preserve the reasoning and decision-making capabilities of LLMs but also empower a diverse range of MM tasks.

10
29
173
1
1
11
While Gemini 1.5 Pro may take some time to explain, it marked a breakthrough in multimodal content understanding!

A nice video made by
@Sam_Witteveen
, an external developer with early access to the long context capabilities of Gemini 1.5 Pro, sharing some of the things this model can do. 🎉
14
76
408
0
0
11
We've just released a survey on 3D model Generation, encompassing 436 papers on the latest advancements. Hope it's helpful!🌟📈🚀
Thanks to the team: Xiaoyu Li, Qi Zhang, Di Kang, Weihao Cheng, Yiming Gao, Jingbo Zhang, Zhihao Liang, Jing Liao,
@yanpei_cao
,
@yshan2u
Paper:
0
1
11
Impressive results for tough prompts!🌟🚀

Excited to announce RPG-DiffusionMaster, a joint work with Peking University and Stanford University. RPG harnesses multi-modal LLMs to master diffusion models in complex and compositional text-to-image generation/editing, achieving state-of-the-art performance.

8
31
160
1
1
11
ICLR 2024 (Oral): an unsupervised RL that learns diverse locomotion skills purely from pixels.

METRA is the *first* unsupervised RL method that can learn diverse locomotion skills purely from pixels, and is one of my favorite works!
METRA got accepted to ICLR 2024 (Oral), and come to the sessions this Wednesday!
Oral: Wed 4p, Halle A 2
Poster: Wed 4:30-6:30, Halle B
#161
1
14
66
0
0
11
🌟 Harnessing Tech for Good: ARC Lab is thrilled to be a part of the team integrating cutting-edge AI to restore a stunning 4,500-year-old statue.
#TechForGood
#Innovation
#tencent
#ARCLab

0
3
11


Glad that MotionCtrl is accepted by SIGGRAPH-2024. Thank you all for featuring and following this work!
Congrats to: Z Wang, Z Yuan,
@xinntao
, Y Li, T Chen, M Xia, P Luo,
@yshan2u
The future of AI video generation is gonna be so cool!
MotionCtrl is a motion controller that can manage both camera and object motions with video generation models like VideoCrafter1, AnimateDiff and Stable Video Diffusion 🤯
30
124
628
2
1
10
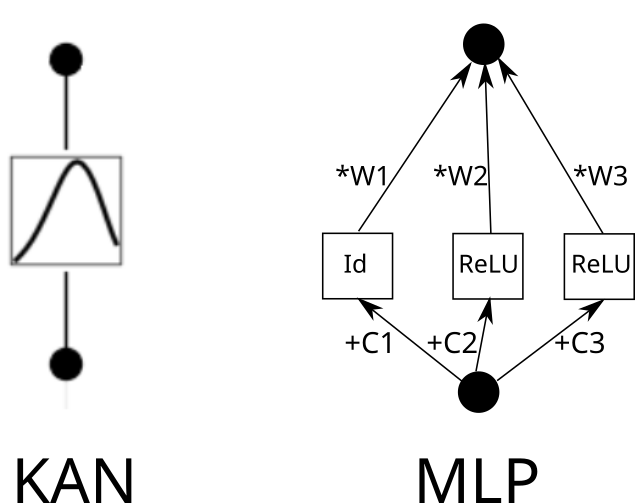
One way of looking at Kolmogorov-Arnold Network.


Kolmogorov-Arnold Network is just an ordinary MLP.
Here is the Colab, which explains:
The main point is, that if we consider KAN interaction as a piece-wise linear function, it can be rewritten like this:
1/n
21
212
1K
4
0
10
Portrait Video generated from a single image. In the same category of EMO and VASA-1, but open-sourced.
🗣️ V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation 🔥 Jupyter Notebook 🥳
Thanks to Cong Wang ❤ Kuan Tian ❤ Jun Zhang ❤ Yonghang Guan ❤ Feng Luo ❤ Fei Shen ❤ Zhiwei Jiang ❤ Qing Gu ❤ Xiao Han ❤ Wei Yang ❤
🌐page:
4
42
157
1
2
10
Probably the first in-situ generation of multiple 3D objects from a single image. 📸✨
ComboVerse
Compositional 3D Assets Creation Using Spatially-Aware Diffusion Guidance
Generating high-quality 3D assets from a given image is highly desirable in various applications such as AR/VR. Recent advances in single-image 3D generation explore feed-forward models
2
14
97
0
1
10
YOLO-World + EfficientSAM!

working on YOLO-World + EfficientSAM
@huggingface
space
last touches and you will be able to run zero-shot image segmentation on short videos
space:

5
50
287
1
2
9
Diffusion-DPO: an example of connecting open source with close source.

Check out Diffusion-DPO🌟 Bridging the gap between StableDiffusion & closed models like Midjourney v5. Our
#TextToImage
model uses human feedback for state-of-the-art alignment, marking a new era in AI creativity!
Code:
Blog:

2
16
80
0
1
8
Wearable MLLMs (Multimodal LLMs) has chance going mainstream this time! 🚀✨

Multimodal Meta AI is rolling out widely on Ray-Ban Meta starting today! It's a huge advancement for wearables & makes using AI more interactive & intuitive.
Excited to share more on our multimodal work w/ Meta AI (& Llama 3), stay tuned for more updates coming soon.
31
101
596
0
0
9
Thanks
@camenduru
for sharing! DynamiCrafter is a major upgrade to our image-to-video model.🚀 Echoing recent improvements in our text-to-video model, VideoCrafter2, the new model significantly improves motion, resolution, and coherence.
🎬 576x1024 👀 DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors 🔥 Jupyter Notebook +
@replicate
🥳
#image2video
Thanks to
@Double47685693
❤ Menghan Xia ❤ Yong Zhang ❤ Haoxin Chen ❤ Wangbo Yu ❤
@_hanyuan
❤
@xinntao
❤ Tien-Tsin Wong ❤ Ying Shan ❤
10
30
189
0
6
9
In Dall-E3's vision, living in a post-labor economy following the advent of AGI looks like this: a world where advanced robotics and AI are seamlessly integrated into the environment, and humans are engaged in leisure and artistic activities.😊

1
0
9
Self-nominating ECCV2024 reviewers.
#ECCV2024

#ECCV2024
is encouraging potential reviewers to self-nominate. Know a great reviewer? Encourage them to self-nominate.
Reviewer nomination form:
Please do not send an email to the ECCV organizing committee, we cannot reply to all the individual emails.
1
18
52
0
0
9
Most comprehensive and enlightening tutorial on YOLO-World! Huge thanks to
@skalskip92
for the efforts!
cc:
@tiahch
@ge_yixiao
@XinggangWang
@yshan2u
The YOLO-World YouTube tutorial is out!
please, let us know what you think!
- model architecture
- processing images and video in Colab
- prompt engineering and detection refinement
- pros and cons of the model
watch here:
↓ more resources
12
137
804
1
2
9
The best world model is the world itself. 🌍😊✨

Caught this fleeting beauty on my sleeve today 🦋
The design of ecological systems is a marvel indeed!
4
2
33
0
0
9
Generative creativity with lightning fast inference.


0
0
8
Immersive memory!

0
1
7


Interestingly, the World Model bears some similarities to the I Ching (易经). In
@ylecun
's formulation, it categorizes all life situations x into 384 categories s, each with a suggested action a. The mystical mapping from s(t) to a(t) is sometimes referred to as a controller.


Lots of confusion about what a world model is. Here is my definition:
Given:
- an observation x(t)
- a previous estimate of the state of the world s(t)
- an action proposal a(t)
- a latent variable proposal z(t)
A world model computes:
- representation: h(t) = Enc(x(t))
-
133
442
3K
1
3
8
Wow, auto-rigged 3D characters in one click!

💥Generate auto-rigged 3D characters in one click, only with Tripo AI💥
👇
The auto-rigging feature for humanoid models is available in our Discord for beta testing.
#Tripo
#ImageTo3D
#TextTo3D
#3D
#AI
#Autorigging
5
20
79
0
0
8



Upgraded body model with anatomically accurate skeleton rig and mesh!

Working with body models 💃 but need to track bones 🦴? We released the SKEL model (SIGGRAPH Asia 2023) 🧵(1/6)
Project Page:
Code:
6
49
276
0
2
8
One of the highlights from the year 2023 report.


This year’s AI Index report offers a deep dive into the evolving landscape of AI. Covering key trends from technical performance to geopolitical dynamics, it's a must-read for industry leaders, policymakers, and anyone interested in the state of AI.

9
207
533
0
0
8
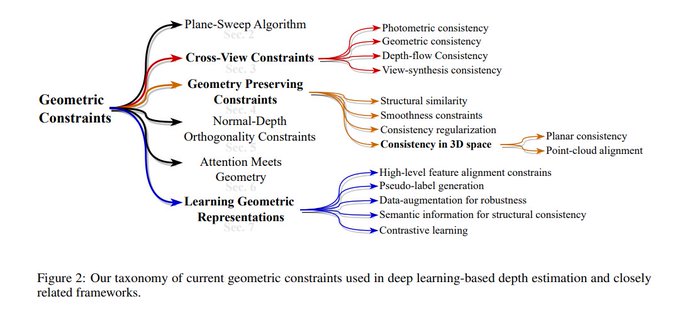
A timely refresh of geometric constraints in the era of deep learning!

Geometric Constraints in Deep Learning Frameworks: A Survey
Vibhas K Vats, David J Crandall
tl;dr: in title

0
28
91
0
0
8
Research and innovation were mostly works of burning brain power. In the new era of deep learning, a significant part of the thinking process has shifted to burning GPUs. This presents both challenges and opportunities for academia. 🔥💻🎓

Since Sora is out, I have been thinking about our role in academia. One thing we can do at school is fast prototyping with very talented students, showing the potential, the possibility. Of course, the future will always be scaling up.
3
15
198
0
0
7
Stanford's AI Index-2024 is now live.

📢 The
#AIIndex2024
is now live! This year’s report presents new estimates on AI training costs, a thorough analysis of the responsible AI landscape, and a new chapter about AI's impact on medicine and scientific discovery. Read the full report here:
14
368
723
1
1
7
I'm increasingly convinced there's an "impossible trinity" in content creation tools: controllability, usability, and versatility. No tool excels in all three, and none seems able to.

0
0
7
A compositional world model for multi-agent planning!

The ability to infer others' actions and outcomes is central to human social intelligence.
Can we leverage GenAI to build cooperative embodied agents with such capabilities?
Introducing 🌎COMBO🌎, a compositional world model for multi-agent planning!
5
17
103
1
1
7
A challenge for image-to-video models 😊🚀🎥
0
0
7
Generative graphic design with solid results!


Introducing COLE: a effective hierarchical generation framework that can convert a simple intention prompt into a high-quality graphic design, while also supporting flexible editing based on user input.🤗🤗🤗
Paper:
Project page:

6
19
69
0
0
7
Great effort assembling the map! The history of AI is essentially a history of massive tensor computation gradually taking the center stage of the evolution.



0
0
7

Text-to-music generation with specific controls on chords, tempo, and dynamics.

I am excited to announce that Mustango has been accepted at
#NAACL2024
! MusTango is a controllable text-to-music generative system that can generate music audio from text prompts that contain music-specific descriptions (e.g., chords, tempo, dynamics, etc).


1
17
64
1
0
7
1
0
7