

Ostris
@ostrisai
Followers
6K
Following
2K
Media
227
Statuses
967
AI / ML researcher and developer. Forcing rocks to think since 1998. Patreon - https://t.co/ew5M6LdJkO ML at https://t.co/IhAXPimwqM - @heyglif
Denver, Co
Joined August 2023
I am happy to release the next iteration of OpenFlux, Flex.1-alpha. Flex.1 is an 8B param model with an Apache 2.0 license. It has been trained a significant amount since OpenFlux, and has a fancy new guidance embedder. Still a WIP. More to come.
21
133
787
Did a lot of testing on my LoRA training script for @bfl_ml FLUX.1 dev model. Amazing model! I think it is finally ready. Running smooth on a single 4090. Posting a guide tomorrow. Special thanks to @araminta_k for helping me test on her amazing original character and artwork.
35
97
680
I teared up a bit. I am extremely excited, but also feel completly inadequate in literally everything I have ever worked on. Ever. It is absolutely stunning and humbling to watch. I need a drink.

Prompt: “A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.”
24
29
667
Testing Flux.1 schnell embedding interpolation. I told claude some details about my life and had it generate 40 prompts from being born -> being dead using the data I gave it. Then interpolated between the embeddings for this video. Uses @araminta_k softpasty LoRA
30
84
645
IT WORKS!! I trained an IKEA instruction LoRA on a decompressed version of FLUX.1 schnell , and it works on schnell at 4 step! The choppiness should go away when I get the guidance embedding trained. Still a WIP, but it works! There is hope!


22
57
532
New Stable Diffusion XL LoRA, Ikea Instructions. SDXL does an amazingly hilarious job at coming up with how to make things. Special thanks to @multimodalart and @huggingface for the GPU grant!!. HF -> Civitai ->




13
78
474
AI-Toolkit now officially supports training LoRAs directly on FLUX.1-schnell. 🥳 . How to do it here -> The adapter that makes it possible here ->
14
84
478
FLUX.1 schnell text embedding interpolation test. Silver balloons floating in the street.
13
41
455
Early alpha demo of my "virtual try on" I have been working on. Load a few photos of a person, a photo of a top, enter a prompt, and instantly render them wearing it in any scene you want. Special thanks to my beautiful wife for letting me use her likeness.
16
48
379
It is absolutely insane how well img2img with IC LoRA works for embedding anything into a model. This changes everything.



just put this insane "Any Logo Anywhere" Flux workflow into the Glif Browser Extension🤯 . links below

6
22
323
Working to get out a full tutorial for FLUX.1-dev LoRA training on a 24GB card. For now, I updated the read me and added an example config file. Should be enough to get many of you going. Will be updating as I go.
11
32
311
Soon. It is still cooking, but I am starting to get extremely excited about it.

20
16
283
Testing training a LoRA for FLUX.1 . 38.5gb VRAM!!. Gradient checkpointing.Rank 256 (Big, I know).T5 in 8bit.Full BF16 . It is a big boy.

13
35
260

Releasing my 16ch VAE (KL-f8-d16) today (also). MIT license, lighter weight than SD3 VAE (57,266,643 params vs 83,819,683), similar test scores, smaller, faster, opener. I'm currently training adapters for SD 1.5, SDXL, and PixArt to use it (coming soon).
9
45
254
I take this back. I managed to squeeze LoRA training for FLUX.1-schnell-train on a single 4090 with 8bit mixed precision. We will see how well it works. 3s/iter.
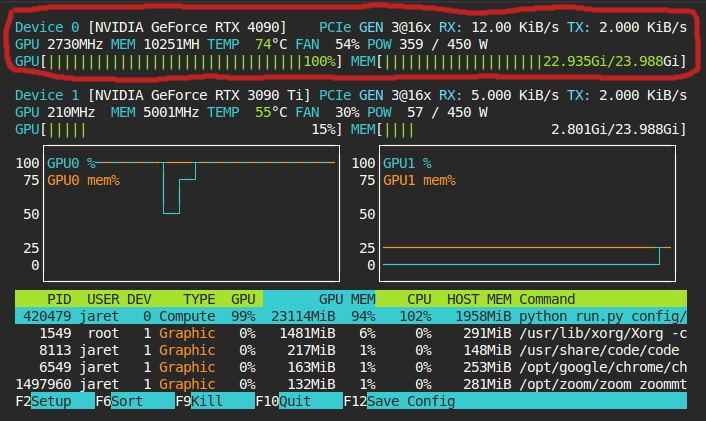
This can be optimized further. I think you could maybe do mixed precision 8bit quantization on the transformer (maybe). But, no matter how optimized it gets, I don't think it will ever be possible to train on current consumer hardware (<=24gb). Someone please prove me wrong.
13
26
251
I haven't spoken much about my ongoing project to de-distill schnell to make a permissive licensed version of flux, but I have been updating it periodically as it trains. I just noticed it is the #2 trending text-to-image model on Hugging Face. Working on aesthetic tuning now.

13
28
248

I trained a new VAE with 16x depth and 42 channels (kl-f16-d42). I am now training SD1.5 to work with it, which will double the output size of SD1.5 without much additional compute overhead. Every time I train a new latent space, it always starts out inverted. It's so odd.
13
34
223
I just released a new IP adapter for SD 1.5 I'm calling a Composition Adapter. It transfers the general composition of an image into a model while ignoring the style / content. A special thanks to @peteromallet , it was their idea. Samples in🧵.
12
49
216




Just added a SDXL version of the IP Composition Adapter, which injects the general composition of an image into the model, while mostly ignoring content and style. It now supports SDXL and SD 1.5. Some samples in 🧵.
7
33
200
Training sample from a training run using a schnell training adapter I have been working on. 1200 steps in. Still hasn't broken down. Trained on and sampled with FLUX.1 schnell.

10
12
193







It won't be long now. Note: This is not a traditional IP adapter. We are going directly from the SigLip 512 base last hidden state into the attn layers. We are fine tuning the entire vision encoder as well, it is a small encoder but has more than 2x the resolution of CLIP.

We're cooking up a FLUX.1-dev IP Adapter at @heyglif using SigLip 512 base for the vision encoder. It is still cooking, but it is getting there. Current samples (left input - right output).

7
17
179
Just kicked out a significant bugfix for ai-toolkit that should have a dramatic increase in quality when training Flux, especially on fine details. The artifacts should be gone. You are probably going to want to update to the latest if you are using it.
8
18
169
I am honestly pretty happy with how OpenFLUX is turning out. I never expected to actually get it to where it is currently, and it still has a long way to go before it is where I want it to be.

12
6
168
I added support for training LoRAs on SD3.5 Large at 8bit on 24GB GPU to ai-toolkit. Still doing some testing and will likely make some tweaks to it, but it is there if you early birds want to test it out.
6
29
162
Experimenting skipping Flux blocks. First image is all blocks. 2nd image is skipping MMDiT blocks 3, 6, 7, 8, 9, 10, 13. With a little tuning, it would improve farther. Prompt: a woman with pink hair standing in a forest, holding a sign that says 'Skipping flux blocks'


16
17
149
Please prioritize your children's mental health, no matter how young they are. My family had a close call recently. I will be dialing back my open source side projects for a while, but will continue my professional work and focus the rest of my time on family.
17
0
155
SD1.5 with a Flan T5 XXL text encoder is cooking 🔥with parent teacher training. >400k steps in. Most generic concepts are transferred. I am really loving how it is turning out so far.

15
13
133
OpenFLUX.1 update. I have been training it on new data and training various pruned versions. The next release will likely be a 7B param (8mmdit 30dit) version with a new name (TBD). Most of my efforts on this project will likely shift to this version. Alpha next week, hopefully.
5
7
127
I set up a 🤗 HF space if you want to test out Flex.1-alpha without downloading it
I am happy to release the next iteration of OpenFlux, Flex.1-alpha. Flex.1 is an 8B param model with an Apache 2.0 license. It has been trained a significant amount since OpenFlux, and has a fancy new guidance embedder. Still a WIP. More to come.
6
24
126
I have had twitter for a year, as of today. Somehow, I have acquired close to 4k followers from almost exclusively posting about ML experiments I am working on. I never expected anyone to be interested in my work. Thank you all for nerding out with me this year. #MyXAnniversary

4
0
109
Toying with an idea of a living community model for the next step for open flux. Allow the community to fine-tune the model on their own datasets and target identified weak spots using set training configs. Then, once a week/month, all of these are merged into the base model.
18
5
105



They had H200s available on @runpod_io this morning. I have never seen them available and have never gotten to mess with one. I spun up a pod and I am transfering a dataset now. Excited to see how they perform.

11
3
100
PixArt Sigma is now ranked higher than SD3 on imgsys. We all need to start giving PixArt more love. Plus, it is openrail++.

6
13
94
This simple change allows you to use 4090s in a datacenter. Follow me for more life hacks.


@giffmana I just checked the GeForce license and it looks like they carved out an exception for crypto. So if I find a way to put this on the blockchain…

1
9
97
Stable Diffusion 1.5 but with the CLIP Big G text encoder. This was an experiment that I probably dedicated too much compute to. To realize its full potential, it needs some proper fine tuning. Regardless, here it is and it works with 🤗inference api.
4
16
94
I have an experimental de-compressed version of Flux-schnell trained. It won't generate well on its own without the guidance embeddings. So I am training those from scratch now. I am also training my first real LoRA test on it (IKEA instructions). 🤞.
6
4
84
I ran a test last night to completely remove the double transformer layers on flux and only training the first 9 single layers to see if it the model could learn to function without the first half of the network. It seems to be working. 🧵
3
11
84
I added a post with the results of skipping each block in FLUX.1 dev here ->
Experimenting skipping Flux blocks. First image is all blocks. 2nd image is skipping MMDiT blocks 3, 6, 7, 8, 9, 10, 13. With a little tuning, it would improve farther. Prompt: a woman with pink hair standing in a forest, holding a sign that says 'Skipping flux blocks'
8
11
82
New training best practice, random case dropout.

reminder for flux: prompting is case-sensitive 𝙰𝚊. left: Mark Zuckerberg eating pasta.right: mark zuckerberg eating pasta.same seed


1
3
80
Added a blog post with images from skipping each block in SD3.5-large. Hopefully this helps in choosing more efficient blocks to target during fine tuning.
8
16
81
TinyLlama is amazing! I have been waiting on a <3B permissive model to come out. Fine tuning small LLMs to do very specific tasks has so much potential. I loaded it up in my prompt upsampler and it works shockingly well. 🧵.
4
8
77
Looking for opinions on licensing. I am planning to release a pruned and fine tuned version of open flux soon (8b). I have always been an OSI compliant license purist, but I am toying with a license that is permissible for everything except well funded/profitable companies. What.
21
4
74
Working on a clothing IP adapter for Flux. Shirt is getting close. Face is. not.


4
5
70
The SD1.5 version is probably done. Currently at 240k steps . I am trying to cleanup fine detail, but it may have reached the limit of what synthetic data from the parent model can achieve. Will run it through the night on some high res fix images which will hopefully help.
75k steps in on training the adapter for SDXL. First ~30k steps were just on the new conv_in/conv_out layers. Then I added the LoRA (lin 64, conv 32). It is going to be a while, but it is coming along.
5
3
61
I am training a Diffusion Feature Extractor with lpips outputs as targets now. It is still cooking, but I pulled an early version out and finetuned Flex.1-alpha for ~2k steps with it. It is really cleaning up the features, especially text. I am super excited about this.




Diffusion Feature Extractor: Training a model that can extract features from RF diffusion model outputs. You can use the features as an additional loss target. I tested an early version of it with a Flex.1 finetune. This is before/after 250 steps. It works too well. 🧵




6
7
68
I was curious how difficult it would be to train a guidance LoRA so you can infer without CFG and burn in the negative prompt. Turns out, it is pretty easy to do. My test was with OpenFLUX.1, but should work with any model requiring CFG and will double inference speed.




6
3
61
Diffusion Feature Extractor: Training a model that can extract features from RF diffusion model outputs. You can use the features as an additional loss target. I tested an early version of it with a Flex.1 finetune. This is before/after 250 steps. It works too well. 🧵
6
4
65
Be super careful with your FLUX.1 training captions people.

Everyone who said captions don't do anything for Flux is wrong because I captioned a dog as a "cat" and it was ONE picture, and now the model is beautiful except whenever I prompt cat or kitten it gives me dogs. Also shoutout to @comfydeploy for the awesome service.

2
3
59
Excellent work @multimodalart !.
FLUX.1 ai-toolkit now has an official UI 🖼️ with @Gradio . With this open source UI you can 💻, locally or any cloud: .- Drag and drop images 🖱️.- Caption them ✏️ (or use AI to caption 🤖).- Start training 🏃. No code/yaml needed 😌. Thanks for merging my PR @ostrisai 🔥

0
2
60
75k steps in on training the adapter for SDXL. First ~30k steps were just on the new conv_in/conv_out layers. Then I added the LoRA (lin 64, conv 32). It is going to be a while, but it is coming along.
Releasing my 16ch VAE (KL-f8-d16) today (also). MIT license, lighter weight than SD3 VAE (57,266,643 params vs 83,819,683), similar test scores, smaller, faster, opener. I'm currently training adapters for SD 1.5, SDXL, and PixArt to use it (coming soon).
1
5
56
Training my first SD3 LoRA. It is hacky and probably won't be able to run on anything other than my trainer for now, but it is cooking. I am sure I am missing some stuff, but we will see.

5
0
53
I'm still off and on cooking a version of SD1.5 that has a 16ch VAE and T5XL text encoder. It takes forever to learn the fine detail since it is 4x the amount of data in a 16ch VAE. It is frustrating because it is so close, yet still so far.




11
2
52

Released a LoRA for SDXL that converts the latent space to the SD1/2 latent space.
Training samples from a little pet project. SDXL LoRA that converts the SDXL Latent space to the SD1/2 latent space. I have been training it off and on for a while and think it is probably closed to done.




3
4
51
Since bitcoin hit $100k, I thought I would tell the story of putting 1 bitcoin on a paper wallet for my child about 7 years ago. A few month later, we lost everything in a fire including that paper wallet. Every time it peaks it hurts.
12
0
51
I trained Marty McFly on 6 images for 1500 steps and 6 LoRAs on each image for 250 steps each, and merged them together on inference. In short, no, it does not work as well as training on all images at the same time.


I am curious if you would get similar results from training a LoRA on 10 images as you would training 10 LoRAs on single images with 1/10th the steps, and then merging them together. Has anyone tried anything like this?.
9
1
50
A year ago, when I was building the sampling mechanism for ai-toolkit, I accidentally left my name (Jaret) hard coded as the trigger word, buried deep in the code. It really freaked me out and made me question reality when my name started showing up in all the training samples.




5
1
48
Current training sample with this prompt from the 7B param version. It is still in the early stages and has a ways to go, but I am pretty happy with the current prompt comprehension after pruning out 5B params (41%) from the model.

I am honestly pretty happy with how OpenFLUX is turning out. I never expected to actually get it to where it is currently, and it still has a long way to go before it is where I want it to be.
3
4
48
Almost every VLM captions like : "The image appears to possibly feature a man who could be in a mood some would describe as happy" vs how people prompt "A happy man". And they all seem to ignore my instructions do it otherwise.
20
0
47
To me, the most exciting thing about Auraflow is that it is actually an open source license, Apache 2.0. CreativeRail++, while being permissive, is not actually an OSI compliant license. I am super excited to sink my GPUs into it this weekend!.
2
4
44
Changing name to LittleDiT since I decided to increase the size a bit. Moved from T5 base to T5 large and going with 20 blocks in DiT vs 10. Still a lot smaller than SD1.5 with everything baked in. Now we cook, for a long time. Current samples attached.




3
0
47
First LoRA test I tried was with live action Cruella because in my pruning attempts, anatomy broke down. Plus that hair and her clothing is hard to learn. It worked out well. Final step training samples attached.




How did I miss this? Too many releases. @freepik Awesome work! It works out of the box with ai-toolkit. Training first test LoRA now.
5
0
46
Cooking a style only IP adapter for SDXL. It still has a ways to go, but it is looking promising.

3
3
48
Training a Stable Diffusion LoRA that can do 1 step is HARD. You have to get pretty creative with the timestep to prevent from going pure adversarial loss, which I don't want to do. I think I have it now. Just needs to cook for a while. Current train samples of 1 vs 2 step. SD1.5


5
4
46

My electricity provider sends me these emails trying to kilowatt shame me every month. Mind your business.

6
0
46
Style IP Adapter for SDXL is coming along. I love the impasto style people. Some content is still coming through. Working on that. I also figured out a novel way to compensate for inference CFG during training to prevent over saturation. Hopefully done tomorrow.


2
4
43
@bfl_ml @araminta_k For personalization I also did a celeb test with Christina Hendricks since the model didn't seem to know her well. It works well on realism personalization. Attached is before and after training a LoRA on FLUX.1-dev on Christina Hendricks.


4
2
45
Tiny DiT: Images are coming through. It is basically going to need a full fine tune though. Debating on committing to that because I REALLY want this. Entire model w/ TE is 646MB. Full fine tune takes 2.4GB VRAM and I can train at a BS of > 240 on a 4090.


Saturday experiment: Retrained xattn layers on PixArt Sigma to take T5 base (much smaller). It works surprisingly well. Merge reduced the number of blocks in the transformer from 28 to 10. Just popped it in the oven (full tune). Now we wait. Who wants a tiny DiT to play with?.
4
6
41
Current progress of OpenFLUX 4B vs OpenFLUX 7B models. Really wish I could get the 4B model in a better state, but for now, I am getting pretty happy with the 7B version.




4
3
39
Testing some flux vision adapter training today. My favorite generations have always been the oddities generated while messing with the cross attn layers.


3
0
41
Support for these LoRAs will work out of the box with Diffusers, I also finished the weight mapping for ComfyUI and have a PR for that here That will enable full support for Comfy UI. You can checkout my fork in the iterum.
1
3
43
Training montage for those who enjoy watching models train as much as I do.
Doing a test of training SD1.5 to use a 16 channel/16 depth VAE so it will generate natively at 1024 with same compute requirements of 512. ~ 300k steps in so far. It is working but taking FOREVER.




1
0
40
New Stable Diffusion XL LoRA - "Super Cereal". Turn anything into a cereal box. Special thanks to @multimodalart and @huggingface for the compute!. HF -> Civitai ->




2
6
43
SDXL 16ch VAE adapter is still coming along, but it still has a long way to go.




1
1
40
16ch SDXL VAE adapter sample image. Prompt: "woman playing the guitar, on stage, singing a song, laser lights, punk rocker". In many ways, the 4ch VAE made training easier because the VAE made up most of the fine details. Now, the unet has to learn it. Needs to cook more.

4
4
38
I logged into Civitai for the first time in a long time. There is just blatant unchecked child porn everywhere. I took all of my models off of there. I do not support nor want to be associated with that in any way shape or form.
9
1
41
It has taken dozens of iterations and keyboard smashing to figure out all of the math. Hours to curiate and modify the 3k guidance image pairs. But it is working!! I will fix stable diffusion hands!. Training sample from my private SDXL realism model. Step 0 and 600

6
1
37
I generated a few hundred regularization images for training with FLUX.1-dev, and it kept generating Donald Trump completly unprompted. These prompts were:. "a man in a suit and tie talking to reporters"."a man with a blue tie and a black jacket"."a man in a suit and green tie"



10
1
39
Training samples from a little pet project. SDXL LoRA that converts the SDXL Latent space to the SD1/2 latent space. I have been training it off and on for a while and think it is probably closed to done.
3
3
36
Saturday experiment: Retrained xattn layers on PixArt Sigma to take T5 base (much smaller). It works surprisingly well. Merge reduced the number of blocks in the transformer from 28 to 10. Just popped it in the oven (full tune). Now we wait. Who wants a tiny DiT to play with?.
2
5
33
@DMBTrivia @kohya_tech It was trained on thousands of schnell generated images with a low LR. The goal was to not teach it new data, and only to unlearn the distillation. I tried various tricks at different stages to speed up breaking down the compression, but the one that worked best was training with.
2
7
31


@McintireTristan Dataset is thousands of images generated by Flux Schnell. Fine tuning is not possible because it is distilled. What is I doing is intentionally breaking down the step compression to hopefully end up with a training base that we can train LoRAs on that will work with schnell.
8
1
35
Saturday experiment: Single value adapter. I trained feeding a single -1 to 1 float directly into key/val linear layers that corresponds to eye size in images, and apply that to the cross attn layers. It works. Sample images are -1.0 and 1.0 pairs. Time to add more features.




8
4
34
"You will not use the Stability AI Materials or Derivative Works, or any output . to create or improve any foundational generative AI model" Is still in there. My understanding was that this is why @HelloCivitai refused to host it in the first place.

At Stability AI, we’re committed to releasing high-quality Generative AI models and sharing them generously with our community of innovators and media creators. We acknowledge that our latest release, Stable Diffusion 3 Medium, didn’t meet our community’s high expectations, and

7
3
32
I cannot get my 16ch adapter for SD1.5 where I want it without doing a full fine tune. I also cannot get my flan T5xl adapter there either. So I merged them into a single model together and I am doing a full tune of a T5xl- 16ch-SD1.5 model. We will see.
3
0
30


Having some issues keeping up with direct messages and tags on here and discord. If I haven’t gotten back to you yet, I am sorry. A little overwhelmed with messages at the moment.
1
0
33
I trained another VAE (kl-f8-d16 -16 ch), and I test trained SD 1.5 to use it. It picked it up very quick, but the fine details need work. Overall, the test worked. Trying to decide if I want to switch to SDXL or PixArt Sigma. Thoughts?




8
4
32