
Yuki
@y_m_asano
Followers
3,750
Following
698
Media
158
Statuses
593
Assistant Professor for Computer Vision and Machine Learning at the QUVA Lab, @UvA_Amsterdam . Previously @Oxford_VGG , @OxfordAI , interned @facebookai
Joined July 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
梅雨明け
• 196735 Tweets
BRANDS AI TALK x FOURTH
• 131411 Tweets
Raila
• 122601 Tweets
黒人奴隷
• 100733 Tweets
Halal
• 42781 Tweets
パワプロ
• 42607 Tweets
カルストンライトオ
• 34846 Tweets
#EnflasyonMuhasebesi
• 34716 Tweets
#TheBoys
• 31648 Tweets
Yunan
• 29115 Tweets
Harmony
• 23794 Tweets
Haas
• 20657 Tweets
Colabo
• 19263 Tweets
暇空敗訴
• 16039 Tweets
BarengPRABOWO MakinOPTIMIS
• 15420 Tweets
SEMANGATbaru EKONOMItumbuh
• 14850 Tweets
#WeMakeSKZStay
• 13235 Tweets
悪魔の証明
• 11817 Tweets
全員再契約
• 11268 Tweets
CROWN PRINCE SUNG HANBIN
• 11209 Tweets





















Just presented and successfully defended my D.Phil. to my examiners
@phillip_isola
and Philip Torr!🥳🎉 It was an honor and pleasure
@Oxford_VGG
with Andrea Vedaldi,
@chrirupp
and many amazing colleagues like
@mandelapatrick_
and
@afourast
! On to new adventures!

21
3
175
Getting excited for my "Self-supervised and Vision-Language Learning" lectures starting tomorrow for the
@UvA_IvI
's MSc in AI, Deep Learning 2 course:
Sharing a preview in
@CSProfKGD
style :)
Soo much recent progress, learned a lot in preparing it.😊
3
29
163
Check out our
@iclr_conf
[oral] paper on learning state-of-the-art ViTs from a single video from scratch!
One of the coolest things is that multi-object tracking emerges from the different heads in the plain ViTs (three heads visualised below in R,G,B).

Really happy to share that DoRA is accepted as an Oral to
@iclr_conf
#ICLR2024
Using just “1 video” from our new egocentric dataset - Walking Tours, we develop a new method that outperforms DINO pretrained on ImageNet on image and video downstream tasks.
More details in 🧵👇
2
20
116
2
16
123
Today we introduce Bidirectional Instruction Tuning (Bitune). It's a new way of adapting LLMs for the instruction->answering stage.
It allows the model to process the instruction/question with bidirectional attention, while the answer generation remains causal.

3
16
117
Looking forward to the Self-Supervised Learning Workshop we’ve organized with
@chrirupp
, A. Vedaldi and A. Joulin at
#ECCV2020
.
Join us tomorrow for our speakers:
@avdnoord
, P. Favaro,
@CarlDoersch
, A. Zisserman, I. Misra, S. Yu, A. Efros,
@pathak2206
! .

2
33
108
Check out our
@CVPR
paper on making caption-based Vision-Language Models do object-localization without _any_ human-supervised detection data!
⁉️ We develop a new *VLM-specific PEFT method* 🤩which is more powerful than LoRA etc. We test on non-training categories only!


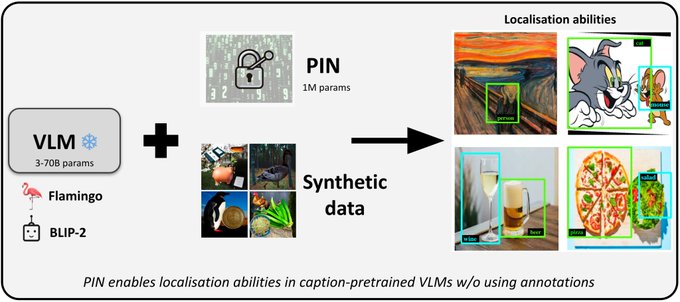
1
11
101
With
@iclr_conf
done &
@NeurIPSConf
deadline rapidly approaching, here's something to look forward to 🤩:
Our workshop
@ICCVConference
: "🍔BigMAC: Big Model Adaptation for Computer Vision" with amazing speakers
🌐:
📆: 2nd October 9am-1pm, details soon

1
22
99
Reminder from Bill Freeman at the Quo Vadis workshop that it's not the quantity but that _one_ creative/weird paper that matters.
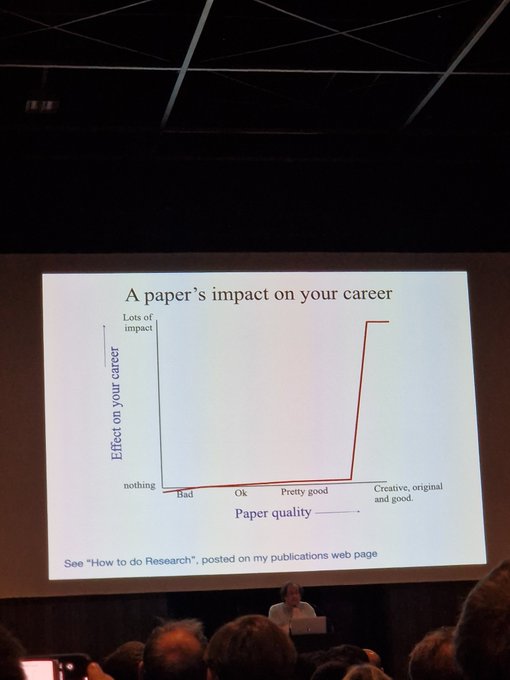
2
12
89
This week marks my one year anniversary of being assistant prof at the
@UvA_Amsterdam
. 🥳🎉
To celebrate this, I want to share a few of my distilled reflections.
1
0
90
Visit our ICLR poster "Measuring the Interpretability of Unsupervised Representations via Quantized Reversed Probing" with
@irolaina
and A. Vedaldi, from
@Oxford_VGG
. We linear-probe SSL models, but in ǝsǝʌǝɹ!🤯 For better interpretability.
in 1h:
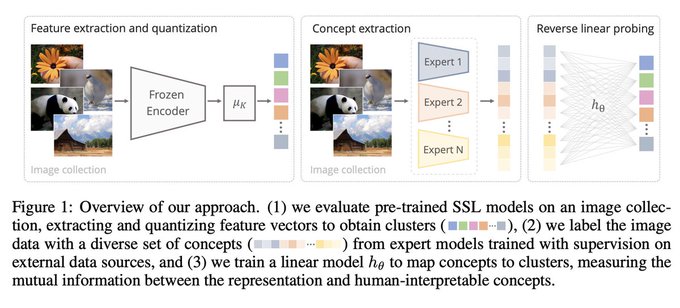

1
10
89
@y0b1byte
At the top of my head: A lot of strands. Synthetic data: phi models, newest stable diffusion. MoEs: megablocks, llava-moe. PEFT: eg DoRA, VeRA (ours). Instruction tuning: alpaca,moe+IT paper from Google. VLMs: Apple and HF papers, LLM embeddings: eg llm2vec,
2
5
79
Today, my friend & collaborator
@TengdaHan
sent me this: I've arrived at 1000 citations! 🥳 Or rather, the works I've co-authored with many brilliant & inspiring individuals, have, collectively reached a nice arbitrary number! Still: 🥳🎉!
To celebrate: here's some TL;DRs
6
0
68
Here's the (re-)recording of lecture 1 + updated slides:
🎥:
📄:
Also, checkout the other cool modules of the DL2 course: from
@egavves
,
@saramagliacane
,
@erikjbekkers
,
@eric_nalisnick
,
@wilkeraziz

Getting excited for my "Self-supervised and Vision-Language Learning" lectures starting tomorrow for the
@UvA_IvI
's MSc in AI, Deep Learning 2 course:
Sharing a preview in
@CSProfKGD
style :)
Soo much recent progress, learned a lot in preparing it.😊
3
29
163
0
17
65
@Ellis_Amsterdam
ELLIS Winter school on Foundation Models kicking off! Happy to have a super diverse students with us in Amsterdam.
@ELLISforEurope



1
9
60
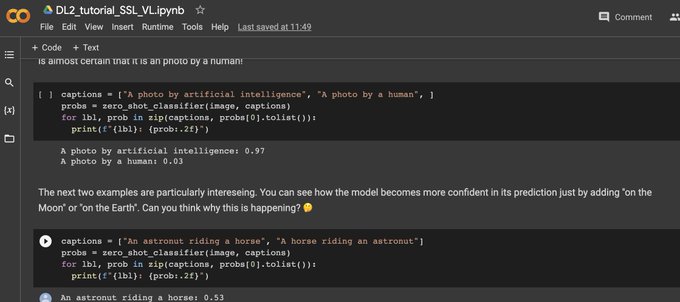
Full house at the practical of our SSL + vision-language module!
Want to follow along? Find the collab notebook made by my fabulous TAs
@ivonajdenkoska
and
@mmderakhshani
here
💻:
lecture 2 📺:
slides 📄:


Here's the (re-)recording of lecture 1 + updated slides:
🎥:
📄:
Also, checkout the other cool modules of the DL2 course: from
@egavves
,
@saramagliacane
,
@erikjbekkers
,
@eric_nalisnick
,
@wilkeraziz
0
17
65
0
11
56
Congratulations! Truly an "example in research, teaching/mentoring", as is the prize's intention. Couldn't have had a better PhD advisor.

0
3
54
Finally it's out! 🎉 Our new work on leveraging the passage of time in videos for learning better image encoders. Big improvements for spatial tasks like unsupervised object segmentation. Check out the great thread below! Paper
@ICCVConference

New paper on exploring the power of videos for learning better image encoders 🎥🧠. Introducing "TimeTuning", a self-supervised method that tunes models on the temporal dimension, enhancing their capabilities for spatially dense tasks, such as unsupervised semantic segmentation.
3
20
86
0
6
53
So. Loud. 🔊 Even while sitting in the rooms and only breathing you constantly hear the clinging. once you start hearing it you cannot unhear. 😅
4
1
46
I will be giving a public talk about some of my research tomorrow as part of the QUVA Deep Vision lecture.
It'll be about self-supervised learning and privacy/ethics in CV (SeLa, PASS, SeLaVi, GDT and our GPT-2 bias paper).
Tune in here:
0
8
45


Research -> meeting friends! 🥳 After speaking at Bristol's Machine Learning and Vision group of
@dimadamen
and having exciting discussions about research yesterday, I was happy to see old and new colleagues from
@Oxford_VGG
at my talk at
@oxengsci
in Oxford today.
0
0
35
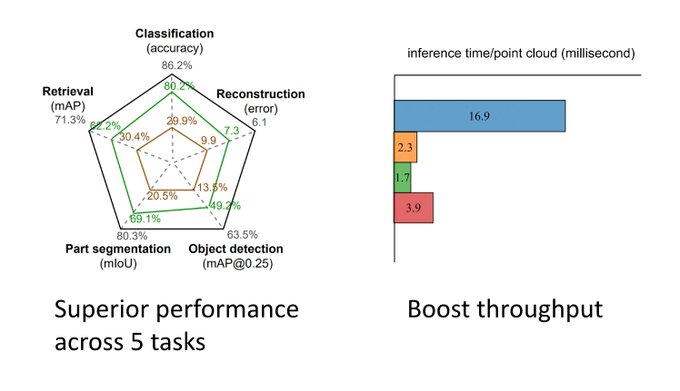
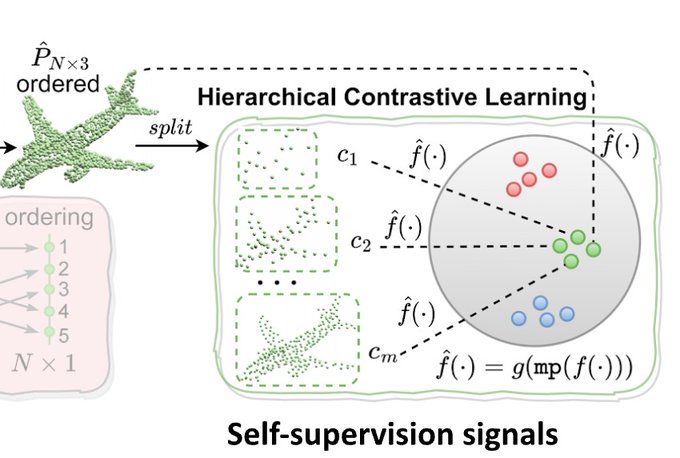
Final day at
@ICCVConference
! We have one oral at around 9:20am: "Self-ordering Point Clouds" where we learn how to select the most informative points with hierarchical contrastive learning (subsets as positive augmentations) and use Sinkhorn-Knopp for differentiable sorting.
1
4
34
VLM people when a new LLM like llama-3 comes out

0
2
32
I'm sure that if we had this tool earlier, efforts like ImageNet-blurred, removing the person-subtree and PASS would've happened earlier.
We don't have an excuse anymore to not see the bias and problems in our datasets. (5/5)
3
3
29
Our paper on causal representation learning from videos got accepted into ICML. 🍋🎉 while we use toy datasets this is a great step for the future of representation learning.

Great way to wake on a Sunday, our work on Causal Representation Learning from Temporal Intervened Sequences, w
@phillip_lippe
@TacoCohen
@y_m_asano
@saramagliacane
@sindy_loewe
accepted in
#icml2022
!
2 very good papers rejected, more for
#neurips2022
😀
3
15
76
1
1
28
Another nice oral at
@CVPR
's vision-language session. And another good demonstration that current VLMs are pretty broken. But the authors propose a nifty way to distill procedural knowledge of coding of LLMs to VLMs, improving them on benchmarks.




Excited that VPD has been selected as Oral at
#CVPR2024
(90 orals in total, 0.8%). Congrats to all coauthors, and see you in Seattle!
Let's distill all the powerful specialist models into one VLM!
paper:
proj:
0
10
57
0
2
25
Really happy to share our new work on arXiv! do check out our interactive cluster visualization here:

Check out our new work "Labelling unlabelled videos from scratch with multi-modal self-supervision" by
@y_m_asano
@mandelapatrick_
@chrirupp
and Andrea Vedaldi in colab with
@facebookai
!
See below for our automatically discovered clusters on VGG-Sound!
1
10
40
3
3
24
It was such a nice event! Seeing friends and meeting new ones all the while seeing NeurIPS works -- and it being simply downstairs from my office is 💯 . Especially also super happy to see the mingling between PhD and MSc students and other researchers! 🙌

Happening now: the NeurIPS Fest 🎉 at
@Lab42UvA
over 100 people are here to see 38 poster presentations of the latest AI research in Amsterdam
#ai
#machinelearning
#ELLISamsterdam

0
8
40
1
1
24