

search founder
@n0riskn0r3ward
Followers
706
Following
1,108
Media
180
Statuses
3,171
Solo entrepreneur passionate about search tech. Self-taught dev building a niche search product and sharing what I learn along the way.
Joined June 2022
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
バニーの日
• 262513 Tweets
RFK Jr.
• 182507 Tweets
Obamas
• 146069 Tweets
Kennedy
• 137689 Tweets
Vote Harris
• 131947 Tweets
Cristiano Ronaldo
• 84859 Tweets
Lijo
• 81916 Tweets
Sterling
• 81257 Tweets
Maresca
• 69817 Tweets
Hermosilla
• 60362 Tweets
Young Boys
• 51626 Tweets
ALWAYS 8Y JAEMIN SIDE
• 43387 Tweets
TRT 1
• 32435 Tweets
#YBvGS
• 28814 Tweets
Manuel Neuer
• 28306 Tweets
#كاريزما46
• 26970 Tweets
El PRO
• 24009 Tweets
Gringo
• 18573 Tweets
ドゥレッツァ
• 16978 Tweets
Estadounidense
• 16510 Tweets
Asheboro
• 12542 Tweets
シティオブトロイ
• 11644 Tweets
Velasco
• 10734 Tweets





















Wake up babe Alibaba just dropped a new SOTA Apache 2 embedding model. 434M params, 57.91 MTEB retrieval score, 8192 token context length, transformer++ encoder backbone (BERT + RoPE + GLU).
6
27
337
A new, mysterious, NVIDIA embedding model, "NV-Embed" is 1st overall, in retrieval, reranking, & classification on MTEB. cc-by-nc-4.0 licensed, LLM based (huge?), no config, no weights, doesn't even specify output dimensions or model parameter count.
@nvidia
don't be a tease!!
4
21
173
Outperforming Rank-GPT4 by this much with a cross encoder is a huge deal IMO. Suggests
@cohere
has better data labels for contrastive learning than a naive application of GPT-4 turbo would get you which means they should be able to make a much better dense model as well...

Introducing Rerank 3! Our latest model focused on powering much more complex and accurate search.
It's the fastest, cheapest, and highest performance reranker that exists. We're really excited to see how this model influences RAG applications and search stacks.

23
124
742
2
7
67
These lovely people did a nice job distilling RankZephyr into 109M and 330M param MIT licensed cross encoders for us. Haven’t tested it yet, but will soon. It’s also another cross encoder paper concluding list-wise ranking isn’t a big enough boost to be stat significant

4
13
48
Very much a fan of the "propositions" approach to text chunking (full gpt-4 prompt in image). Makes a lot of sense. Yes, it's resource intensive, but to get the maximum quality quality chunks/data loading, there's no comparison.

2
5
46
Snowflake went hard on this paper. They're kindly sharing all the juicy deets about what went into their arctic models. Definitely worth a read. This image is the paper's version of Daniel's tweet thread.


Want to know how Snowflake made the artic-embed models better than Open AI's text-embed-3 or Cohere's embed 3? Check out our tech report on Arxiv . 🧵of TLDR findings below.
2
22
121
2
3
43
After getting free credits to nearly every LLM fine tuning under the sun from taking Hamel and Dan's course/conf, I've tried most of them...
A v quick informal 🧵:
@OpenPipeAI
is easier to use but pricey IMO.
@predibase
is easy to use except
1
2
43
True, but right now I need an LLM to act on 22 million records in my database and smaller open source models are the only practical solution financially b/c openai hasn't made anything smaller than 3.5 turbo
Many enterprises will need DSPy like pipelines to bring costs down.

unpopular opinion: training open-source LLMs is a losing battle. a complete dead end
the gap between closed models like GPT-4 and open models like LLAMA will only continue to widen as models grow bigger and require more resources
no one is building particle colliders at home
256
55
943
3
3
35
This piece from
@dottxtai
convinced me to use structured generation (aka constrain token generation to tokens that match a regex) more.
You can't do this (in the same way) with any of the major API providers can you? Sglang can do this within in DSPy, yes?

5
2
35
@tianle_cai
Noob here: Am I correct in understanding that you're saying these phrases are one token in the new tokenizer and them being one token implies they occur frequently in the training data given that the tokenizer was likely trained on the same data as the models?
1
0
30
0
3
26
Enough OpenAI/AGI nonsense. Can
@cohere
just announce the details of this Compass model already so I have something interesting to read about and play with? Da eff is this "special format". Can we speculate about this instead of OpenAI pls 🙏🏼?

4
4
25
This MIT Licensed, 236B Param (21B active per token) model, priced at $0.14/1M input; $0.28/1M output should be v competitive on the cost/value curve esp for "math, code and reasoning" tasks. From a v quick test it likely outperforms even Command R+ on my relevance labeling task

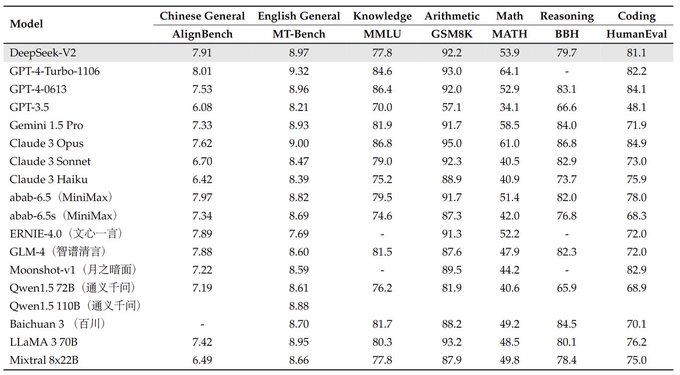
🚀 Launching DeepSeek-V2: The Cutting-Edge Open-Source MoE Model!
🌟 Highlights:
> Places top 3 in AlignBench, surpassing GPT-4 and close to GPT-4-Turbo.
> Ranks top-tier in MT-Bench, rivaling LLaMA3-70B and outperforming Mixtral 8x22B.
> Specializes in math, code and reasoning.
39
235
981
3
0
27
✅ synthetic query generation pipeline
Next: mining hard negatives
Random idea: Has anyone tried using an LLM to take query positive pairs and just make some small modifications to the positive document to turn it into a hard negative?
10
2
25
I’m over here planning to use LLMs to generate “proposition” based chunks for retrieval from ~100 million+ web pages…
Them: “inference is basically free for startups”
Me: it would cost me ~$3M in GPT-4 turbo input tokens alone; ~$75k in haiku input tokens, ~$375k output tokens

LLMs are at exponential growth/investment curve and y'all want to finetune smaller models to cut costs?!?!?
NGMI. Even if you have PMF.
2
0
16
5
2
24
New Apache 2.0, 7B param, 4096 dimension gte chonker is now on the top of the MTEB leaderboard. Trained like prior gte models which IIUC means all the MTEB train splits were used along with MEDI. But worth a look if you want to fine tune a 7B w/ bidirectional attention.

1
5
21
@LolaaBrink
@InternetHippo
This headline and tweet are both incorrect. It was a test of identifying prime numbers. 100% of the questions asked if a prime number was prime. Old model defaulted to yes. New model defaults to no. When a mix of composite and prime number are used both models are equally poor.
2
1
22
@xennygrimmato_
Nope. Only a multi vector model like ColBERT would work at that length. If you could make me one and open source it that would be great! 🤗 Or just have your colleagues turn this into one:

1
2
20
Even with the sneaky 98% output token price increase on Flash, it's 95% confidence interval overlapping with Claude Opus on coding based on domain expert evaluation is crazy town given the price difference. Opus is $15/$75; Gemini 1.5 Flash is $0.35/$1.05; 42.8x/71.4x cheaper


3/ We eval'd many of the leading models:
- GPT-4o
- GPT-4 Turbo
- Claude 3 Opus
- Gemini 1.5 Pro
- Gemini 1.5 Flash
- Llama3
- Mistral Large
On Coding, Math, Instruction Following, and Multilinguality (Spanish).
See leaderboard results below.




10
6
149
3
1
20
From a very imperfect attempt to benchmark my data on recall metrics, mixed bread’s model is legit. It matches or outperforms Cohere v3 and Voyage Large 2 on my data.
5
2
17
Benchmarks of Voyage's multilingual model just dropped. Including the google sheet with all the data sets tested and scores. Love that they include this level of detail every time.

Looks like
@Voyage_AI_
just released "voyage-multilingual-2" on their website, will be interesting to see it benchmarked as I haven't seen too many multilingual focused models released of late
0
0
3
2
3
18
Hot takes on tools and tech:
1.
@plasmicapp
>
@bubble
2.
@coda_hq
>
@NotionHQ
3.
@TallyForms
>
@typeform
4.
@vespaengine
>
@pinecone
and other vector dbs
5.
@QwikDev
> react and nextjs *
6.
@Cloudflare
workers r often >
@awscloud
lambda
7. I h8 kubernetes
3
2
17

Linq-Embed-Mistral is now
#1
on the MTEB retrieval subset (scores 60.19): 7B params, outputs 4096 dims, cc-by-nc-4.0 license. Less training on test than other leaders (trained on E5S + S2ORC, S2ORC may overlap with Arxiv-related MTEB tasks)
🧵Thoughts from skimming their report:
1
1
16
Why isn't there a single company/product that makes it easy to fine tune embedding models. Am I the only person trying to do this myself and finding it painful? I could teach a 3 yr old to fine tune Mistral-7b with
@UnslothAI
. Took 22 mins on a free colab gpu. 1/4
3
0
15

1
4
15
No exaggeration, 100% of the machine learning/information retrieval community, and AI academic communities both on Twitter and elsewhere have been incredibly welcoming, generous, and kind hearted to me stumbling around in the dark for the last year or so. Thankful for you all.
1
0
15
RAG Prompting trick: Repeating instructions before a long list of search results, after every ~X search results, and at the end of search results significantly improves instruction following ability esp when instructions are complex
1
2
14
@nvidia
The first few commits listed it as Apache 2.0... How bout we revert back to that pls?
1
0
14
@tianle_cai
So to get an SOTA multimodal voice assistant you just need to train a model on a bunch of Japanese porn and throw some scams in too. The more ya know…
2
0
13
DSPy optimizer ICL prompting idea (see "Active Prompting with Chain-of-Thought for Large Language Models") temp=0.7, find answers/examples model "disagrees" with itself on over 40 generations, use expensive foundation models to determine correct answer, use those examples if ICL
1
1
12
@migtissera
You can connect them to a third party api. But yeah it's all just RAG, sometimes they run the RAG over the docs you upload or you can build your own api and serve it up that way. They still haven't said what the rev share will be though.
2
0
11
@parkerdlittle
@roblabonne
You should definitely want people to book directly. Both to avoid the platform’s cut and for better data on your customer for retargeting.
1
1
12
If you won't go full DSPy for your IR paper's prompt, at least do something low effort that works well like analogical prompting + constrained generation (last bit so model perf comparisons aren't determined by how freq an LLM fails to generate a parsable answer)

2
1
11
@HamelHusain
If we're going full conference mode we might as well get
@Nils_Reimers
to give a talk on fine tuning embedding models and cross encoders...
2
0
11
@jxmnop
There’s an interesting listt5 paper about using a “fusion in decoder” approach to reranking with T5. Works pretty well considering the size of the model though not as well as rankZephyr which takes a similar approach but by fine tuning mistral 7B
1
0
10
Me when I see a search startup not using BM25:

0
0
11
@abacaj
For sure - don’t get me wrong I love to see a model that small performing well. But to most users - LLM’s are a tool to get an answer. Given multiple free options (Bing, Claude v2, and chatGPT) I have no motive to try something else
1
0
10
Would love to see
@cohere
,
@Voyage_AI_
,
@mixedbreadai
and vector dbs like
@vespaengine
implement the - query time modification of query vector to mimic cross encoder scores (see "Adaptive Retrieval and Scalable Indexing for k-NN Search with Cross-Encoders" and other papers)

today i'm pleased to share the first of a series of technical reports with the ai application developer community - our investigation into the use of linear embedding adapters in improving retrieval accuracy in realistic settings.
@SuvanshSanjeev
@trychroma

20
41
337
2
0
10
@cohere
's coral chat is mind blowingly fast. It starts responding to my question seemingly instantaneously and the question asks it to visit a site read something and answer a question about that web page and it successfully quotes the page.
1
0
9
Still fighting the "masculine" urge to train an SOTA embedding model. I have neither the time nor the $; I'm mostly convinced model training isn't a good biz (endless competition). But no one else is going to spend the $ trying my crazy ass ideas so....
4
0
9
@TolgaBilge_
Yeah, if you listen to Sam do interviews or podcasts, you can see why he's so successful. He comes off very well IMO. Carefully spoken, thoughtful guy is my genuine reaction after any given interview. But the facts of his actions so far don't add up for me and feel sus. 1/2
2
0
9
Haven't fully tested this yet, but from a few attempts, Sonnet 3.5 is MUCH better at critiquing document-1 vs document-2 type tasks where hallucinations were rampant before. Also works when document-2 is it's own response. BIG unlock IMO bc 1/n
Thought LLMs would be better at this:
Given 2 500 token summaries: Does sum 1 mention anything sum 2 doesn't?
Goal: Find 4 diffs w/o hallucinating.
GPT-4 T:1/4, 4+ Hs
GPT4-o:1/4, 4 Hs
Command R+:1/4, 1 H
L3:1/4, 1 H
DeepseekV2: 3/4, 3 Hs
Opus: 3/4, 1 H
Gemini 1.5: 3/4, 0 H
2
1
6
1
0
8
Lots in info/claims here, careful w scale diff on the bottom 2:
1. For long context: BM25 + rerank outperforms openaiv3large + rerank
2. Vectors >> BM25 for code search and medical search
3. Cohere v3 reranker DECREASES perf of OpenAI embeddings on every lang except other??

🆕📢 We are thrilled to launch rerank-1, our best general-purpose and multilingual reranker! It refines the ranking of your search results with cross-encoder transformers.
It outperforms Cohere's english-v3 on English datasets and multilingual-v3 on multilingual datasets 🚀.

2
8
57
1
0
7
@t3dotgg
Yeah, so this is a “hack” people use to rent an apartment in a building that doesn’t allow tenants to Airbnb their apartment. They rent it as a corporation, tell the building diff employees will come thru, then make every guest temporarily part of that corporation…
1
0
8
1/3 I’m too dumb to quickly figure out which learned sparse retrieval methods will a) work with long documents and b) not be extremely expensive to store the index or run: SPLADE won’t work with long docs, but what about deepImpact, TILDEv2, SpaDe, EPIC, and Sparta?

2
1
8
@thealexbanks
Sequoia’s job is to identify undervalued ideas, assets and trends. They don’t create value. They recognize it and invest in it. Markets need that, but let’s call it what it is pls
1
0
8
Testing it out right now and holy shit this thing is insane
1
0
8
@ZainHasan6
This conclusion: "even when fed with the same top 5 chunks of evidence" is interesting. So whatever modifications were made to extend the context window from 4k to 32k resulted in a model with a more effective attention mechanism for the first 4k tokens?
2
0
8

@GregKamradt
Meant to tag you in a discussion of my favorite chunking method:
Very much a fan of the "propositions" approach to text chunking (full gpt-4 prompt in image). Makes a lot of sense. Yes, it's resource intensive, but to get the maximum quality quality chunks/data loading, there's no comparison.
2
5
46
2
0
8
@alexalbert__
Helps when it's trained on the answers... 3.5 Sonnet is a better model but this benchmark is not evidence of that progress or a good measure of the magnitude of progress

SWE-bench is probably contaminated for frontier models (gpt-4/claude-3-opus).
Given only the name of a pull request in the dataset, Claude-3-opus already knows the correct function to modify.

14
70
683
0
0
8
Can someone ELI5 - If the chat model has much more knowledge than the base model then why does everyone fine tune the base model?

I think Meta and Llama-3 is the final nail in the coffin to several misconceptions I've been fighting against for the last year.
Llama-3 Chat was trained on over 10M Instruction/Chat samples, and is one of the only finetunes that shows significant improvements to MMLU.

81
103
1K
7
0
7
@m_chirculescu
@jxmnop
A synthetic dataset Microsoft made along with e5 mistral that's designed to look as much as possible like the datasets that mteb tests on. Aka a synthetic replica of training on test IMO
0
0
7
Also nice to see the open source flan t5 trained model made available on hugging face:
Although the 512 token length flan-t5 limits make it significantly less useful in my opinion.

1
1
7
Would love to see some of people's favorite/most mature open source RAG projects. Ideally ones facilitating/using:
1. Hybrid search
2. A cross encoder
3. Have a lengthy list of possible import sources
4. Fancy/unique data loading pipelines
I like danswer:

1
0
7
@Teknium1
This explanation seems most likely to me

@maximelabonne
The HF model is buggy. A rope fix was pushed by
@danielhanchen
a couple of days ago. Also the chat template doesn't include the required BOS token.
Someone needs to go through the reference implementation line by line and check the HF version carefully, IMO.
4
3
90
1
0
6
So pumped for this.

🚨Announcing 𝗗𝗦𝗣𝘆, the framework for solving advanced tasks w/ LMs.
Express *any* pipeline as clean, Pythonic control flow.
Just ask DSPy to 𝗰𝗼𝗺𝗽𝗶𝗹𝗲 your modular code into auto-tuned chains of prompts or finetunes for GPT, Llama, and/or T5.🧵


24
138
639
0
1
7
The one thing gpt2-chatbot is AGI level good at relative to gpt-4 is helping me figure out who to mute on this app
1
0
7
@GregKamradt
I’ve seen a few people do this (sorry don’t have a link off the top of my head), tbh I’ve always avoided zapier bc it’s so effing expensive per call. ’s approach seems better to me though very different target customer.

1
0
7
@debarghya_das
@spacepanty
Former religious studies major + seminary student turned indie software developer checking in. I agree with the gist of your point, but a STEM education isn’t a panacea either. Stats should be mandatory in high school though
1
0
6
@ShaanVP
I know Sarah, we invited her to speak at an event I helped host during my MBA program. Great story. She also worked her ass off after buying this business. None of it has been easy.
1
0
6
@andersonbcdefg
I miss unhinged Bing so much. My internal monologue definitely says "but I have been a good bing!! 😡🥹 " when the gpus OOM now
0
0
9
Will definitely be reading this one. Big setfit fan so potentially by extension a fastfit fan?

🎉Excited to share our paper
When LLMs are Unfit, Use FastFit: Fast and Effective Text Classification with Many Classes
was accepted to
@naaclmeeting
!
🚀SOTA results
⚡Fast training & inference
🎯High accuracy
📄Paper:
💻Package:

6
21
78
0
2
7
Thought LLMs would be better at this:
Given 2 500 token summaries: Does sum 1 mention anything sum 2 doesn't?
Goal: Find 4 diffs w/o hallucinating.
GPT-4 T:1/4, 4+ Hs
GPT4-o:1/4, 4 Hs
Command R+:1/4, 1 H
L3:1/4, 1 H
DeepseekV2: 3/4, 3 Hs
Opus: 3/4, 1 H
Gemini 1.5: 3/4, 0 H
2
1
6

1
4
7
Seems like there's so much performance left on the table in building better training data for retrieval models. If you gave me $1 million to spend, I think I could build a 50% better retriever changing nothing but the hard negatives mining strategy.
0
0
7
Some of these 7b merge models are shockingly good at following instructions relative to when I tried 7b models a while back.
1
0
6
Ok this is pretty fun

Sharing a bit more about Reflect Orbital today.
@4TristanS
and I are developing a constellation of revolutionary satellites to sell sunlight to thousands of solar farms after dark.
We think sunlight is the new oil and space is ready to support energy infrastructure. This
449
687
4K
0
1
6
@JustinLin610
I’ve tried sglang and vLLM and was able to get vLLM working the fastest because they already had a docker container. Sglang was probably easier on my local machine but was having some trouble getting the ports right on vast ai
1
0
2
If you're fine tuning smaller models I'd love to see someone leverage the long context expansion capabilities added to
@UnslothAI
to do this with the smallest model unsloth works with which I think is gemma 2b
@GregKamradt
@isabelle_mohr
@llama_index
@JinaAI_
Yeah, still waiting for someone to train/fine tune a very small 1B or less non-linear attention long context SSM type model to handle chunking. Even a very imperfect attempt would be very useful.
@cohere
@JinaAI_
@mixedbreadai
@togethercompute
1
0
2
1
0
6
Gecko scores a surprisingly poor 32.6 on MSMarco. The next model on the MTEB leaderboard scoring worse than that on MSMarco is bge-micro-v2 at
#80
(for retrieval). I think that highlights a clear enough weakness in the Gecko hard negatives selection strategy.
2
0
6
@BraceSproul
The speed difference is going to be insane and at least against haiku and gpt3.5 I expect cohere rerank v3 would outperform both at reranking by a good margin. Supposedly cohere's rerank v3 is competitive with gpt-4 turbo, outperforming it in some cases.
0
0
6
@arjunashok37
@arankomatsuzaki
Very skeptical as thus far transformers haven't worked for time series but neat if it works!
3
1
6
Epic, brb quantizing...

Embedding Quantization is here! 25x speedup in retrieval; 32x reduction in memory usage; 4x reduction in disk space; 99.3% preservation of performance🤯 The sky is the limit. Read about it here: More info in 🧵
5
93
373
0
0
6
I would like to place an order for a ColbertV3 model built on a miniLM backbone trained in 0.68 bits with a 32k+ context window pls 🙂
0
0
6
Keep fighting to the masculine urge to:
- let everyone know when we will have AGI
- explain how you used Q* and synthetic data to improve Sonnet 3 to 3.5
- predict who will be losing their job
I believe in you. Channel that energy into building something useful instead.
1
0
6
✅synthetic hard negative generation pipeline
The beast is running, it's going to take a while (bc I'm GPU poor) and I still need to make an eval to check if it even helps but should definitely be interesting. I'm far too excited about this.
✅ synthetic query generation pipeline
Next: mining hard negatives
Random idea: Has anyone tried using an LLM to take query positive pairs and just make some small modifications to the positive document to turn it into a hard negative?
10
2
25
1
0
6
Is it straight up not possible to teach a bi-encoder negation? Or has it just not been focused on much? If I had hundreds of thousands of:
query: residential HVAC business
pos: HVAC biz specializing in residential...
neg: Car AC repair biz that does not do residential HVAC
3
0
5
Cohere's has one of the more interesting business models in the AI startups space IMO. I'm biased as a search nerd, but it makes a lot of sense to me. Don't sleep on Cohere.
1
0
6
@virattt
IIUC pinecone doesn't have legit bm25 in their serverless setup. Love Turbopuffer but it's purely a vector store, probably the best pricing (esp for float 32 vectors like voyage) and simplest setup.
The expense of the different options is how I wound up self hosting Vespa.
1
0
6
So when someone goes to ChatGPT and asks: “How many employees currently work at Salesforce and how much has that changed over the last quarter”
… and there are 12 api endpoints on the marketplace that could provide the answer, how does it decide which one to use?
Distribution
3
1
6
@thdxr
At this point it's clear AGI is a marketing/lobbying term useful for regulatory capture. Next token prediction doesn't yield intelligence, it does yield incredibly useful tools. Low switching costs should cause low multiples on huge rev growth but AGI hype solves that for now
1
0
5
Would love to see someone use the dataset: to train a mistral or similar version and then do some pruning on that.

1
2
6
If you're planning to fine tune a smaller model using DSPy this looks like the best option. For a 7b I'd use Mistral 7b instruct v0.2. I think this is a clear answer that Gemma 2b isn't better than stablelm2 1.6B, tbd on Gemma 7b its still too early to tell

Outstanding effort by Stability's Language Team and led by awesome
@MarcoBellagente
&
@jonbtow
Many more details in the report
Model can be downloaded at
0
5
27
1
0
6
I found
@tengyuma
's ColBERT comments on
@CShorten30
/
@weaviate_io
's podcast interesting - esp. the idea of multi-vector doc embeddings that aren't token embeddings. Any plans to support this approach
@bclavie
@jobergum
@weaviate_io
?
3
0
6
The main benchmarks I want to see are a) performance of llama 3 8B vs mistral 7B fine tunes and b) the scores of DSPy optimizations of llama 3 8B vs a variety of other models (maybe even including a fine tune of mistral 7B)
2
0
6
@TolgaBilge_
That 180 and his abrupt departure (expulsion?) from y-combinator after he was about to be president and chair, his sister's accusations, and comments from a handful of departed OAI employees make me uneasy
0
0
5
Is there any reason the recent model merge paper’s strategy could not be applied to search models? Could
@bclavie
use it to merge his SOTA Japanese ColBERTv2 model with the initial ColBERTv2 model and retain most of the performance of each?
1
0
5
I'd give the average prompt in an IR paper (typically generates synthetic queries or ranks the relevance of retrieved candidates) a 3/10. If English is your second language... use GPT-4 or Opus to get the grammar or better yet with DSPy to optimize it!
2
0
6
Leaks say OpenAI is going to sell companies rlhf-ed "richer brand expression" backed into their models? Not a fan, not helping me feel the AGI, and soooo far off from the original non-profit mission. The model spec's been out a day, this leak makes it feel like meaningless PR.
1
0
6
@lateinteraction
From a few attempts at hand prompting gpt-4 to do this it hasn’t done an amazing job so far. I think it would require some hand made examples and DSPy prompt optimization of gpt-4 then distill that down to a smaller model but in theory should be pretty doable
1
0
5
Was really looking forward to Vespa implementing ColBERT for end-to-end retrieval but it sounds like they decided against implementing PLAID though they *might* try to engineer their own alternative solution.
2
0
5
This looks interesting and useful. Though I have to admit my first thought was - we need an enterprise quality vector db that can handle efficient end-to-end multi-vector retrieval bc it's perfect for the issues this is addressing IMO.

Announcing the private beta of our newest foundation embedding model, Cohere Compass: designed specifically for multi-aspect data like emails, invoices, CVs, and support tickets to offer superior enterprise search capabilities.
Sign up to try it out!
5
51
231
0
0
5
👏👏👏The results look impressive (outperforms gecko). Excited to try this new Apache 2 licensed embedding model. Now teach me what "competence-aware hard-negative mining" is please!
I am very proud of my small but mighty team for releasing this model. At 4x smaller and requiring just a (free) Apache-2 license, I am excited to see how this massively improved accessibility will propel research in complex reasoning systems to new heights!
1
7
54
2
0
5
@mathemagic1an
@evadb_ai
On the one hand, this is useful. On the other… that’s an expensive merge…
0
0
4