

Unsloth AI
@UnslothAI
Followers
15K
Following
2K
Statuses
267
Open source LLM fine-tuning! 🦥 https://t.co/2kXqhhvLsb
California, USA
Joined November 2023
Introducing 1.58bit DeepSeek-R1 GGUFs! 🐋 DeepSeek-R1 can now run in 1.58-bit, while being fully functional. We shrank the 671B parameter model from 720GB to just 131GB - a 80% size reduction. Naively quantizing all layers breaks the model entirely, causing endless loops & gibberish outputs. Our dynamic quants solve this. The 1.58-bit quant fits in 160GB VRAM (2x H100 80GB) for fast inference at ~140 tokens/sec. By studying DeepSeek-R1’s architecture, we selectively quantized certain layers to higher bits (like 4-bit), and leave most MoE layers to 1.5-bit. Benchmarks + Blog: Dynamic GGUFs (131GB–212GB) on Hugging Face:

139
625
4K
Train your own reasoning LLM using DeepSeek's GRPO algorithm with our free notebook! You'll transform Llama 3.1 (8B) to have chain-of-thought. Unsloth makes GRPO use 80% less VRAM. Guide: GitHub: Colab:
19
254
1K
Unsloth is the #1 trending repo on GitHub! 🦥 It’s been an incredible journey and we couldn’t have done it without you! To celebrate, we’re taking a look back at how it all started and how we got here: GitHub repo:

24
57
489
You can now reproduce DeepSeek-R1's reasoning on your own local device! Experience the "Aha" moment with just 7GB VRAM. Unsloth reduces GRPO training memory use by 80%. 15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models. Blog:

150
539
3K
@vega_holdings @OpenWebUI Oooh maybe really depends on demand. Issue is the imatrix quants will take a lot of time and money but we'll see. We might release it for V3 first - or maybe not :)
1
0
11
@zevrekhter @OpenWebUI You'll need at least 20GB RAM but that's the minimum requirement. Preferably have at least a sum of VRAM+RAM = 80GB+ for decent results.
0
0
1
RT @OpenWebUI: 🚀 You can now run 1.58-bit DeepSeek-R1 (non-distilled version) on Open WebUI with llama.cpp, thanks to @UnslothAI! 💻⚡️ (Test…
0
46
0
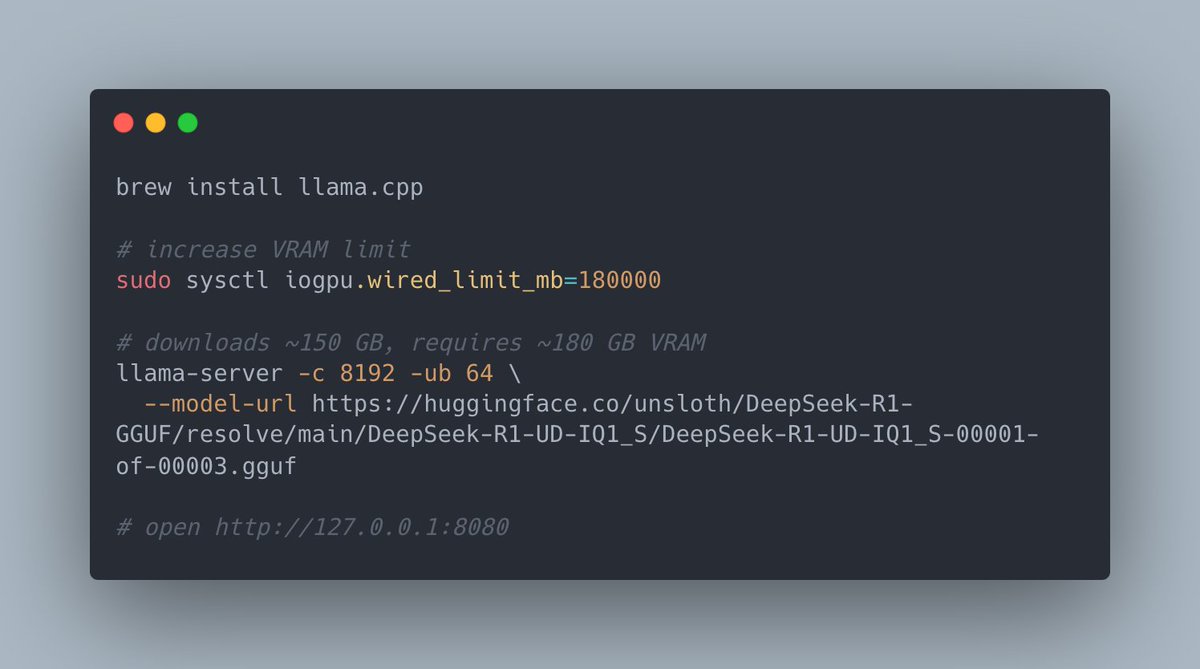

@0xAsharib @tom_doerr @deepseek_ai We do, but only for the distilled versions. You can read more in our blog here:
2
0
4

@levelsio DeepSeek R1 Distill Llama 8B seems to be the current most popular R1 GGUF and it will definitely run great on your laptop. We uploaded ALL of the GGUF files & they can be directly used with Jan AI, llama.cpp, Ollama, HF etc:
DeepSeek-R1 GGUF's are now on @HuggingFace! Includes all Llama & Qwen distilled models + 2 to 8-bit quantized versions. How to run R1: DeepSeek-R1 Collection:
0
0
41
RT @helloiamleonie: You can be GPU poor like me and still fine-tune an LLM. Here’s how you can fine-tune Gemma 2 in a Kaggle notebook on a…
0
121
0
DeepSeek-R1 GGUF's are now on @HuggingFace! Includes all Llama & Qwen distilled models + 2 to 8-bit quantized versions. How to run R1: DeepSeek-R1 Collection:
20
122
567
0
0
3