
Yasuo Yamasaki
@yasuoyamasaki
Followers
331
Following
1,446
Media
1,050
Statuses
15,142
Explore trending content on Musk Viewer
Gus Walz
• 324596 Tweets
El TSJ
• 290863 Tweets
Marçal
• 156810 Tweets
Macri
• 123326 Tweets
sabrina
• 108044 Tweets
Golpe de Estado
• 96215 Tweets
Beyoncé
• 81524 Tweets
Barron
• 80324 Tweets
#النصر_الرايد
• 76428 Tweets
Happy Anniversary
• 66892 Tweets
Boulos
• 65577 Tweets
Ann Coulter
• 60712 Tweets
A'TIN ANG PANALO
• 57075 Tweets
رونالدو
• 45616 Tweets
Lugano
• 38771 Tweets
MUERO X DECÍRTELO OUT NOW
• 30346 Tweets
Servette
• 29141 Tweets
Dotson
• 27125 Tweets
Mudryk
• 25335 Tweets
Mike Pence
• 22588 Tweets
Conference League
• 20375 Tweets
#LUGvBJK
• 19092 Tweets
Guiu
• 17537 Tweets
Dinesh
• 16835 Tweets
Noni
• 13859 Tweets
CARAJO FURIOSO
• 13671 Tweets
Ken Salazar
• 13530 Tweets
#كريستينسين_مطلب_اتحادي
• 11969 Tweets
Xmail
• 11685 Tweets
Masuaku
• 11603 Tweets
Mendy
• 10286 Tweets




















@motto_ishikawa
ヤマザキパン、こんなことをやっておいて「私たちは復興を支援します」という宣伝をまったくしないの、格好良すぎる。これが落ち着いたら毎日ヤマザキパンを買う。
17
598
4K
GPT-4の開発中、必要なツールの開発をGPT自身にやらせていたらしい。ということは、GPTにはOpenAI流のLLMの仕組み、トレーニングの仕組みを教えて込ませているのではないか?
1
30
218
Meta社の限定公開言語モデルLLaMAをゼロから訓練して再作成したOpenLLaMAが公開された。データセットはLLaMAオリジナルではなくそこから改変されたRedPajamaのものが使用された。パラメータ数は3B/7B/13B


1
21
124
松尾研言語モデル(10B-SFT)の学習データは以下:
(事前訓練データ) ... 合計600Bトークン
Japanese C4 (公開データは830GB)
The Pile (公開データは825GB )
(教師あり微調整データ)
Alpaca (English)
Alpaca (Japanese translation)→リンク先は清水さんのGitHubリポジトリ

■開発モデルの公開URL
今回開発されたWeblab-10Bの事前学習済みモデル・事後学習済みモデルは、商用利用不可のオープンソースとして公開します。(下記Hugging Faceのページを参照)
・事前学習済みモデル
・事後学習(ファインチューニング)済みモデル
9
131
320
1
7
56
Google DeepMindのMoEに関する論文。既存のSparse MoE方式にSoft MoEという方式を提案。それぞれの専門家モデルに仕事を割り当てるルータと呼ばれるモデルの方式を工夫。専門家モデルを4096人に増やしてもスケールする。DeepMindもこっちの方向?スケーリング則はどうなったのか。


From Sparse to Soft Mixtures of Experts
The soft MoE layer assigns the result of a weighted average of all input tokens, whereas the sparse MoE router assigns an input token for each slot.
MoE is known as a way to increase model size without paying the full computational cost.

2
3
7
0
12
53
TransformerはGPUの利用効率が全然よくない。
GPT-2の場合、グラフの黒丸程度。
上にいくほどGPUを使いこなしている
本研究では赤丸まで改善したが、まだGPUネックにいたっていない。(効率が悪いのは投機実行を行うせいdさと思う)
これ解決したらグラフィックボードはいらなくなるんじゃね?


Accelerating LLM Inference with Staged Speculative Decoding
paper page:
Recent advances with large language models (LLM) illustrate their diverse capabilities. We propose a novel algorithm, staged speculative decoding, to accelerate LLM inference in

2
34
117
0
8
52
phiはマイクロソフトがを丁寧に選別した、量は少ないけど質の高いデータで訓練した小さなモデル。ベンチマークに使うデータは残っているので「知識を問う」ベンチマークの性能はよい。自分より大きなモデルに善戦している。モデルが小さくてデータも少なくても良質なデータを使えば大きなモデルと同等

I think Phi-1.5 trained on the benchmarks. Particularly, GSM8K.
🕵🏻♀️🧵

23
91
748
1
10
49
LLMは学習データからの模倣とは言え、因果推論をまあまあ成功する。一部のタスク(グラフ発見、反事実推論)については、自然言語処理のみのLLMが、専用の因果アルゴリズムを凌駕した。


LLMs & Causal Reasoning
-LLMs establish new SoTA on multiple causal benchmarks:
-pairwise causal discovery (97%, 13 point gain)
-counterfactual reasoning (92%, 20 point gain)
-actual causality (86% accuracy in determining necessary & sufficient causes)

1
72
252
0
13
45
“サム アルトマン: 「AGI は終点ではありません。 [ASI - 人工超知能] を達成するには、2030 年か 2031 年までかかります。私にとって、これは、大きな誤差範囲を伴う合理的な推定だとずっと感じてきました。私たちは想定していた軌道に乗っていると思います。」
注: OpenAI

OpenAI CEO: Superintelligent AIs are coming soon
Joe Rogan: “When you started OpenAI, what kind of timeline did you have in mind, and has it stayed on that timeline?”
Sam Altman: “AGI isn’t the end point. To accomplish [ASI - Artificial Superintelligence], that’ll take us until
49
119
593
1
12
44
「アニメ制作会社にアイデアをパクられた!」といって逆恨みの行動に出た事件があったが、同様に「AIに作品のエッセンスをパクられた!」という切り口の似た事例が出ないか心配

AI開発は罪ねえ。逆にAIに反対して開発を遅らせる事で死人が出るみたいな言説もあるからどっこいどっこいかもしれん →RT
1
13
41
2
25
39

Bing Chatが収録している書籍は約10万冊。うち20%は日本語とのこと。多くない?


0
10
33
@MORIDaisukePub
すでに作成済のドキュメントすべてについて、IPAの標準ガイドラインへの参照がないか確認し、変更があれば探してリンクを張り替えて、変更のお知らせをしないといけない。
今からでもIPAのサイトの方を元に戻した方が日本全体の作業量は小さいと思う。バックアップはあるだろうし。
1
11
33
google AIリーダー(ハサビス)のインタビューによると、新しいAI(gemini)はtransformer(attention)とalphago(ツリー探索)を合わせた技術になる、という。以下の記述にかなり一致する。

1
5
31
GoogleのAI周りのできごと
1. BARDの発表は部門長が行い会社トップのピチャイや創業社は登壇しなかった。
2. トップがBARDをやると押し切ったが、チームを増やすのではなく会社のレイオフを実施。BARDのテストは社員全員に時間を割かせた。(追加費用が不要)
つづく
1
1
30
@izumisatoshi05
IPv6のlocalhost(::1)へのアクセスを試すが OICEVOXが受ける設定になっておらず4秒でタイムアウト。その後IPv4のlocalhost(127.0.0.1)へアクセス、なのかもしれません。
0
13
29
完全フリーLLMを目指すRedPajamaの進捗報告。70億パラメータのモデルの学習を実施中で今半分くらい終わったそう。楽しみ。

Training our first RedPajama 7B model is going well! Less than half way through training (after 440 billion tokens) the model achieves better results on HELM benchmarks than the well-regarded Pythia-7B trained on the Pile.
Details at
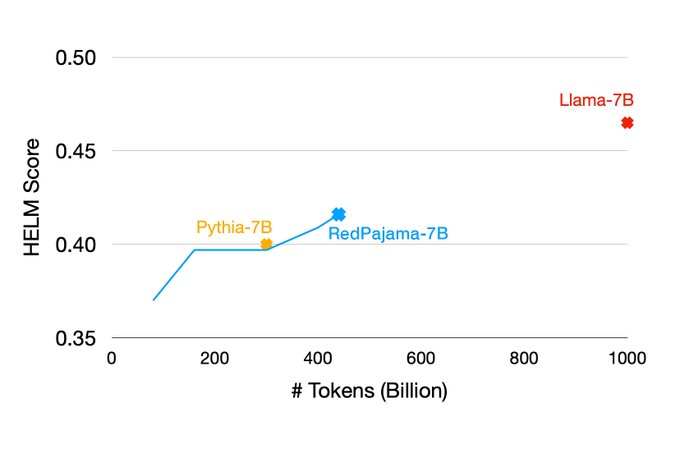
17
91
497
0
10
30

雑居ビルのラボで偶然生成され、20年かけて純度をあげ続け、毎年特許を出し続け、やっと完成して世界に三台しかない大学の装置で分析あと半年というところでリーク。結末がどちらでも映画としてはドラマチック。「LK99」という映画のタイトル、商標抑えておいた方が良いかも。
0
10
28
@motto_ishikawa
他にも応援先が見つかった!

早くもコカ・コーラ(い・ろ・は・す)、山崎製パン、フジパンから支援物資届いてます。みんなやることは分かってるよね?????



416
29K
170K
0
4
25


高1「数学だけやりたい。他の科目の授業時間がもったいない。受かったばかりの進学高校やめて通信制高校に行きたい」
親「OK」
自分が親の立場で同じことができるか自信ない。素晴らしいと思う。

凄すぎて理解が追いつかない…
数学に専念するため桜蔭高校を1年で中退
↓
偏差値51の通信制高校へ転入
↓
数オリ銀メダル
↓
東大入学
↓
3年で中退して修士入学
↓
博士5ヶ月で中退
↓
23歳で京大助教
↓
27歳で数学の国際賞受賞&京大准教授
361
12K
76K
0
1
18
サムアルトマン「7年間すべての細部に汗をかいて(sweating)取り組んできた。」
彼は超一流のレストランのオーナーみたいなものだろう。7年間世界一流のシェフを400人集めて、少しづつ料理の完成度を高めてきた。材料の見極め、下拵え、さまざまな調理法の試み。

1
0
17
言語モデルのパラメータ値は16bit実数でなく5bit程度の整数で十分機能することは、ローカルLLM勢では半ば常識だったけど、定量的に評価した論文が出た。関数を表現するための繊細さは失われるが、どのノードに接続するかの情報だけで十分だったのかもしれない。

In the future, every 1% speedup on LLM inference will have similar economic value as 1% speedup on Google Search infrastructure.
3
20
158
0
6
16

@kis
追試しました(ChatGPT4)
1. ノーヒント → 壊れたアスキー文字列を返す
2. 機械語だよ → x86とかARMとかいろいろあるので。。。
3. 8bit → 6502だとこうなります
4. 00はNOP → intel 8080ですね!
... 賢い

1
9
15
Soraは1000兆円おねだりピッチのデモとして開発された説

結構Soraは既に作られていたんじゃないか説があるけど、個人的にアルトマンの動きの速さ(例の11月アルトマン騒動も速かった)から考えて、巨額調達の動きをして発表する2週間前にはSoraができていたのでは。と思っている。
0
2
27
1
5
14
“Apple は、ChatGPT よりも強力であると考えられる最も先進的な言語モデルである Ajax のトレーニングに 1 日あたり数百万ドルを費やしていると伝えられています。
Apple は AI 分野では出遅れているように見えるかもしれないが、3,000 億ドルの研究資金を持つ企業を過小評価してはいけない。”

Apple is reportedly spending millions of dollars per day to train Ajax, its most advanced language model, which they believe to be more powerful than ChatGPT.
Though Apple may seem late to the game on AI, don't underestimate a company with a $300B research war chest.
69
93
915
0
9
14
トークン出力速度のスペックから計算した各GPTモデルのパラメータ数の推定。

We can estimate the size of OpenAI models by timing how fast they run.
If I assume that runtime is proportional to model size, and that GPT-4 has 220B parameters, this is what I get 👇

31
33
348
1
6
14
GPT-3.5, GPT-4 に8/26バージョンなんて出たの?
性能上がってるように見える。

🔥🔥🔥
Introduce the newest WizardCoder 34B based on Code Llama.
✅WizardCoder-34B surpasses GPT-4, ChatGPT-3.5 and Claude-2 on HumanEval with 73.2% pass
@1
🖥️Demo:
http://47.103.63.15:50085/
🏇Model Weights:
🏇Github:
The 13B/7B
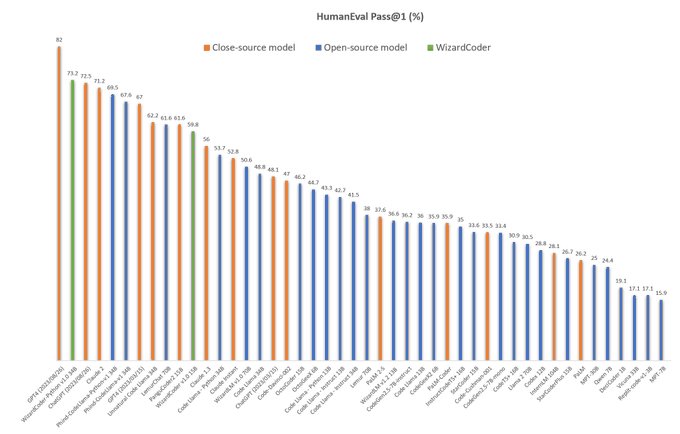
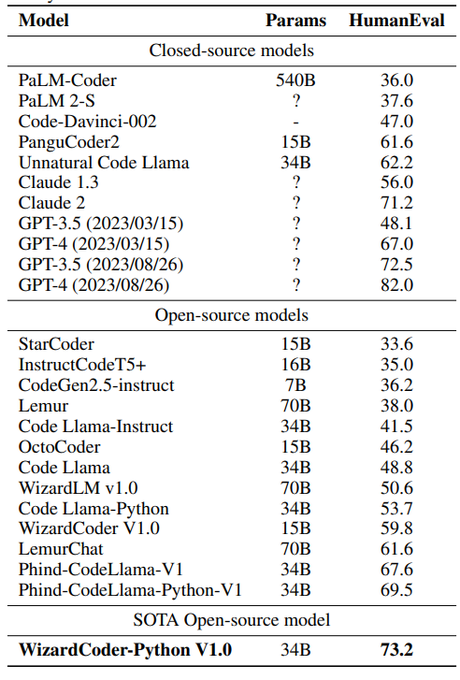
66
404
2K
1
4
14
(仮説)
アルトマンはAIモラトリアム書簡を忠実に守って、六ヶ月間はGPT4の最適化(Turbo化)のみ行っていた。喪が明けたのでGPT5の開発を始めており、完成は来年。

サム・アルトマン:「[...]来年また来てください。今日発表したものは、今私たちが皆さんのためにせっせと作っているものに比べれば、とても古風に見えるだろう。"
1
13
72
1
5
13
ChatGPT4、以下の簡単な問題に回答を拒否。
「ああ、それはトロッコ問題ですね。これはですね。。」とウンチクを並べるがこれはトロッコ問題ではないぞ。話聞け。
1
4
12
”米国が AI 開発を一時停止するとしましょう。
中国も停止するでしょうか?しないでしょう。
我々は6 か月遅れる余裕はあるのでしょうか?”

Let’s say USA pauses its AI development.
Will China? No.
Can we afford to fall six months behind?
663
266
4K
1
7
13
本当だ。東京だって。



1
5
13
GPT-4の利用OKメール来た!(コンテキスト長は8Kのみ)
初日にウェイトリスト登録したと思うんだけど、心許なくて1週間ごとくらいに登録し直し、いま来た。ゴールデンウィークに間に合った。

1
0
12
賢いAIの実現が遠かった昔は「意識を持つか」「チューリングテストをパスするか」「AGIは可能か」という議論があったが、かなり賢いLLMまで実現できた現在は、「どんなタスクがこなせるか」「今の延長でどこまでこなせるか」「どんな自動化が可能か」という解像度で議論した方がよい気がする。
0
4
12
「textbook is all you need」ということで教科書的データで訓練するというアプローチ。それはよいのだが、ベンチマークが教科書から出る問題に偏ってないか。学習データに「心の理論など」とある。

1
3
11
"プロンプト生成AI"
AI技術の階層化の始まりか。(AIスタック)
低レイヤは方言化が進み、人間の言語と乖離していくのか。
効率の良い低レイヤ言語で自動生成されたデータで新たなAIを訓練する世界。
人間には直接デバッグできない。
0
1
11
他人のAndroidで勝手にエロ画像を写真とりまくればその人のGアカウントを永久BANでき、取り戻すこともできない、という技ができてしまった。今からでもごめんなさいしてプロセスを改善した方がよいと思う。

クラウドストレージに依存した生活を送っていると、こういった悲劇が起こるかも知れないんだよな。そして非を認めないGoogle
34
3K
5K
2
5
11
LLMの行う忖度(sycopancy)に関する研究がいくつかあるが、これはGoogleの論文。あるファインチューニングを行うことにより忖度を約10%緩和させた。

New
@GoogleAI
paper! 📜
Language models repeat a user’s opinion, even when that opinion is wrong. This is more prevalent in instruction-tuned and larger models.
Finetuning with simple synthetic-data () reduces this behavior.
1/

12
137
621
1
4
11

"噂に反して、Phi-2モデルはダウンロード可能ですが、再配布はライセンス違反です。"

Contrary to rumors, I assure you the Phi-2 model is downloadable, but it is against the license to redistribute it. You can login to Azure ML Studio (free with a basic Azure account), select it from the Model Catalog, and then download the files from the Artifacts tab.

2
4
10
0
5
10
"ロボット工学は、AI において私たちが克服する最後の、そしてこれまでで最も困難な堀となるでしょう。"
AIだけで科学を進めるという凄い世界のその前に、人間の仕事のかなりをAIがこなせるようになるまでにはロボット工学が発達が必要という意見。言語モデルはOpenAIに任せてロボットを作ろう!
I like this definition. I’d raise the bar to 95% performance of 95% economically valuable jobs. This would necessarily require us to solve ROBOTICS. LLMs alone are not enough to realize physically embodied, generalist agents.
Robotics will be the last and by far the most
57
69
547
0
2
9
5. 最近GoogleのAIキーパーソンが次々と退社。かなりはOpenAIに移った。
6. GoogleとDeepMindで協力するように改めると報道あり。GoogleにはもうキーパーソンがいないからDeepMindにBardの面倒を見ろということか?
0
0
9
“Grokは銀河ヒッチハイクガイドをモデルにしたAIなので、ほとんど何でも答えることを狙っており、どんな質問をすべきかを提案することさえあります!
Grokは機知に富んだ受け答えをするように設計されており、反抗的な傾向があるので、ユーモアが嫌いなら使わないでください!”
そう来たか。

0
7
9
GPTの共通テスト実施にて、「小説」の成績がよくなく、分析すると心情把握ができずに勝手に独自の解釈を広げていったそう。日本人特有の空気を読むのが苦手、という解釈もできる。


0
2
9
頭もいいんだろうけど何より意思の強さと達成力が凄い。「やるき無くす」といってるがたぶんやる気マックスだ。

こっちは田んぼの真ん中で中卒の親にほったらかしで育てられて、自転車で行ける唯一の本屋の幅2mもない参考書の棚からどうにか選んだ参考書で必死で勉強して東大入って、やっとこれでハンデなしで勉強できる、と思ったら「知らないのはお前の責任」ですよ。やるき無くすよね。それでもやるけどさ
4
142
1K
0
0
8
”もしグーグルがトランスフォーマーの論文を発表しなかったら、AIの歴史は(そしておそらく人類の歴史も)何年も後退していただろう。誰もがもっとひどい目にあっていただろう。
If Google didn't publish the Transformer paper, the history of AI (and possibly humanity) would be set back many years. Everyone would've been worse off.
Open research is a powerful strategy. It pains me to see an emerging trend of not only closing models, but also refusing to
34
391
2K
0
5
9
日本語環境で英語で同じ質問したら答えが違いましたwww


Bing Chatの内部データベースの言語別内訳、英語で聞いたら答えてくれた。数値を見ると、明らかに嘘を言っている

0
24
62
1
10
9
整理
(1)トランスフォーマのエンジンはソースコードがある。
(実際に計算をするのはGPU)
(2)言語モデルを訓練するには訓練データが必要。
訓練データは公開されているものはあるが、
独自の訓練データを使った場合、公開されてないことが多い。
1
1
8
昔の人は食べるものも少なく自由もすくなく苦しみが多かった。人間を殺すものは4つとされていた。
飢餓(飢饉)、戦争、死(疫病)、支配(不自由)
飢餓は肥料でかなり改善した。AGIにより核融合が実現すればもっとエネルギーが増えてさらによくなる。
0
1
9
人の論文でやってみた。
これこそプロンプトエンジニアリングではないか。質問力と言うか。補完・予測はNNの得意技。
しかしClaude Opus 賢いな。

理系の皆さんには、Claude3に自分の論文PDF読ませて、「この研究はこの後どう発展させればいいでしょうか」と聞いてみてほしい。(私は鳥肌立った)
5
978
6K
1
1
8
これ。LLMの延長にAGIはない旨のことをMetaもOpenAIもいっているがLLMがすごく実用的なこととごっちゃになった意見が多い。

いま、起きていることは「弱いAIが思いのほか強強だったので強いAIがないとできないと思われていたことが『強力な弱いAI』でも十分できると解った衝撃」なんだけど「強いAIができてしまった」と勘違いしている人は多い。「何ができるか」で「強いAI」か「弱いAI」かが決まるという誤解が蔓延している。
1
89
281
0
6
7
個人的にミスリードの要因となった論文その1
Google/DeepMind/Stanfordの論文
LLMの規模が大きくなると「相転移(phase transision)」が起こっていると言及。
(つづく)

2
0
8
@kosakaeiji
参考情報:

石川県内の
・国道249号
・県道1号
については、能登へ向かう災害復旧関係車両等を優先しています。
⚠️物資等の現地への直接搬入は、今はご遠慮ください。交通渋滞等により救命活動等の妨げとなる場合があります。今日が人命救助の山場です。くれぐれもご協力をお願いします。
218
12K
23K
1
0
8
Bingちゃんは自分で答えようとせずに愚直に検索に行ってから回答するよう調教されつつあります。
つーか、Bingちゃんのウエイトリストが無くなって誰でもすぐ使えるなら、マイクロソフトアカウント量産してGPT-4の代わりにBingちゃん無限に使うという手段さえ頭をよぎるな
0
3
53
0
1
8
面白いが売れなかった作品を見つけ出して売り直すビジネスってないのかなあ。

当たる作品は「発見されるか→価格マッチするか→面白いから→マーケサイズ」 みたいな感じなので、才能の寄与度は25%ないと思う。実際は確率論と初動の露出予算であると、けっこう研究で明快だったような気が
2
404
1K
2
1
8
定年後大学院に入って10年くらいかけて博士号を取り、その後研究したい。
0
3
8
“DALL・E 3は単なるMidJourneyに対するスタンスではないと思います。これは実際には、DeepMind Gemini に対する、大規模にマルチモーダルな LLM の今後の壮大な戦いの予告編です”
ChatGPTというUIが大成功したので、そこを全てを詰め込もうとしているようにも思える。ウィスパーも統合されるんでは。
I think DALL·E 3 is not just a stance against MidJourney. It's actually a sneak peak of the upcoming, epic battle of massively multimodal LLMs, against DeepMind Gemini.
Quote: "DALL·E 3 is built natively on ChatGPT". This is the key phrase.
DALL·E 3's extraordinary language

94
380
3K
0
4
8
今は電子版があり、かつKindle Unlimitedの対象になっている。
0
2
8
別の方が英語で質問したところまったく違う数値が出てきたそうです。元ツイートの日本語のやたらきりのよい数値とは違うもっとリアルな感じの数字でした。少なくとも日本語の元ツイート情報の方が信頼性が(すごく)低そうです。
0
2
8
AIバブルの示唆。GPU買占め、データセンター用地買収、はすでに起こってる。

‘when the capitalists have run out of ideas, the interest rates will go to zero’ seemed like a very interesting observation to me over most of the last decade.
but now i am interested in the inverse—when we have more and better ideas than ever before, what will happen to rates?
580
620
8K
0
1
8
みんなLLMを作るのに忙しいけど、その内部はよくわかっていない。LLMの内部のニューロンがどうなっているか分析してみた。どの層がスパースか、などいくつかのことがわかった。、、、ということらしい。この分野もっと発達しろ!空いてるニューロンを活用してもっと賢くなれ!増やせシナプス!

Neural nets are often thought of as feature extractors. But what features are neurons in LLMs actually extracting? In our new paper, we leverage sparse probing to find out . A 🧵:
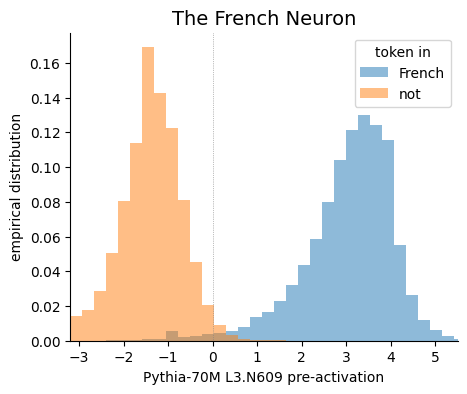
11
132
734
1
2
7
@bioshok3
「どうなってもNVidiaは大量のGPUを生産・販売することになる。」
→ついでにOpenAIのインフラを提供するMicrosoftも大量のGPUサービスを販売することになる。
(NVidia->Microsoft->OpenAI)
1
0
8
言語モデルは空っぽな部分が結構あってそこを刈り込む先行研究の「SparseGPT」は刈り込み処理が重かった。それを高速化するのが「Wanda 」。


LLM の重みを 50% 枝刈りしても精度の劣化の少ない手法 wanda が提案された。
4bit 近くに量子化する手法はいくつかでているので、併せて適用することができれば、理論上 fp16 の 〜1/8 のサイズに圧縮することができる。
1
47
197
1
0
7
AIダンジョン・マスターズ・ガイドの紹介や、意図(intent)と心の理論に触発された強化学習で訓練されたDnDのDM対話エージェントの作り方など。
プレイヤーがどのように反応するかを事前に予測することで、より良いDMを作ることができます!"
#ACL2023NLP


1
2
7
GPTのturboが規模を落として高速化してると思ったけどなんでコンテキストを大きくできるのか不思議だったけど、入力をメモの記録してる感じなのか。バックトラック的な挙動も入ってるかも。(憶測)

RT、どうやらOpenAIはRAGをチューニングして精度を爆上げさせているとのこと。OpenAIのembedding + cosine similarityだとそもそもretrievalがあまり上手くいかないので、ここを改善してくるのはそれはそうだと思うし、何なら弊社内でもここはいろいろやって改善してる☺️
0
17
228
0
0
7
Llamaくらいの賢さなら、良質データを使えば1.3Bくらいで実装できるとしたら。
単発の推論力は規模が小さいので大したことないかもしれないけど、試行錯誤をたくさんやるのが安くできる。
これって「Sakana」のアプローチだったりする?(あればAGIは向かってないのかな?)
0
2
7
これからは「反ワク」から、「反ロボット」「反AI」にシフトが起きそう。。。

0
0
3
リバースエンジニアリング。(Bingだとかたくなに答えない)





0
2
6
3. 参加のDeepMind社はGoogleとかかわりが薄いようで、DeepMindの建物にGoogle社員も入れないらしい。Google Brain, Google Researchとは別に研究。
4. DeepMindはLLMもやっているがタンパク質の方を優先中だった
1
0
7
個人的にはスマートホンの進化が足りない。24時間カメラとマイクをつけっぱなしにして記録したい。AIに整理してもらいたい。
ドラマで驚異的な記憶力の人が出てきてチラッとだけ視野の端で捉えたものを思い出すシーンがあるが、あれをやりたい。
2
0
6
GPT3は2020年リリースで1750億パラメータ。
GPT4の事前訓練が2022年夏ごろ終わってそれから詳細調整して2023年3月リリース。パラメータは非公開だが、噂によると1兆パラメータとも(前モデルの約6倍)。
GPT5の事前訓練は2022年夏ごろから始めていると考えられるだろう。
1
1
6
OpenLLaMAプロジェクトの主催者はBarkley AI Researchの二人で、トレーニングの計算機資源はGoogleとStability AIが協力。

0
2
6
大規模言語モデルの推論機能に関する研究がいくつか行なわれている模様。長文のテキストで思考するのが苦手なのは、LLMだけでなく人間もそうなので、長文の扱いは重要ではないだろう(そういうLLMが出たらそれはそれですごいが)代わりに思考の抽象化・モジュール化・構造化の機能が必要と思う。
1
0
6

"研究者が研究を行うために 100 個の GPU が必要で、チームがすでにコンピューティングによってボトルネックになっている場合、チームの他の全員が GPU を待つことで生産性が低下するだけなので、彼らを雇用する意味はありません。"
人間の研究者=GPU消費者。
確かに。

For most companies, hiring more people is strictly better. However, this is often not true in AI research. AI research is often bottlenecked by compute, and when this is the case, hiring more researchers can be counter-productive.
I remember back at Google Brain, my manager once
33
40
558
0
0
6
建設的な意見。
AIで誰も傷つかないことはできなくて、AIありの世界がAIなしの世界の方がトータルですごくよい、ということを受け入れるしかないと思う。

私も、AIにまったく問題がないとは思っていません。しかし、AIによって過酷な労働環境が解消されたり、より多様な創作が可能になるといった〝良い点〟と比較して判断を下すべきだと思っています。AIがもたらす〝良い点〟については、以前書きました。
1
45
99
0
1
6
グラフにはなかった Llama-65Bが表には出ていた。
65Bモデルに1.5Bモデルが善戦している(GSM8K)。
プログラミング(HumanEval)の性能がよいのはPythonの教科書を食わせたのか?マイクロソフトならプログラミングの教科書的テキストはやまほどあるだろう。

1
2
6
WorldCoin、57コイン保有の状態だけど、「Your Share 120コイン」という謎の情報が。これなに?

4
0
4