

Wes Gurnee
@wesg52
Followers
3K
Following
3K
Statuses
129
Optimizer @MIT @ORCenter PhD student thinking about Mechanistic Interpretability, Optimization, and Governance.
San Francisco, CA
Joined June 2022
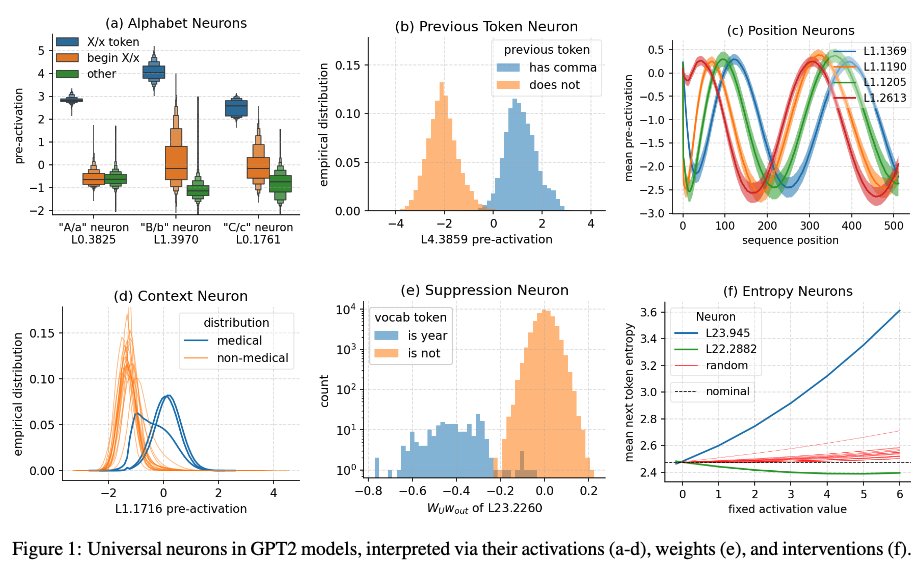
New paper! "Universal Neurons in GPT2 Language Models" How many neurons are independently meaningful? How many neurons reappear across models with different random inits? Do these neurons specialize into specific functional roles or form feature families? Answers below 🧵:
7
68
407
RT @saprmarks: What can AI researchers do *today* that AI developers will find useful for ensuring the safety of future advanced AI systems…
0
67
0
RT @AnthropicAI: New Anthropic research: Alignment faking in large language models. In a series of experiments with Redwood Research, we f…
0
740
0
RT @Jack_W_Lindsey: If you’re interested in interpretability of LLMs, or any other AI safety-related topics, consider applying to Anthropic…
0
25
0
RT @AnthropicAI: We’re starting a Fellows program to help engineers and researchers transition into doing frontier AI safety research full-…
0
309
0
RT @tilderesearch: We're thrilled to be launching Tilde. We're applying interpretability to unlock deep reasoning and control of models, e…
0
128
0
RT @Jack_W_Lindsey: Really excited to share our work on crosscoders, a generalization of sparse autoencoders that allows us to identify sha…
0
42
0
RT @JoshAEngels: 1/5: We recently uploaded a new version of our paper "Not All Language Models are Linear," and I thought I would post a fe…
0
23
0
RT @DarioAmodei: Machines of Loving Grace: my essay on how AI could transform the world for the better
0
1K
0
RT @jade_lei_yu: New paper! 🎊 We are delighted to announce our new paper "Robust LLM Safeguarding via Refusal Feature Adversarial Training"…
0
5
0
RT @NeelNanda5: Are you excited about @ch402-style mechanistic interpretability research? I'm looking to mentor scholars via MATS - apply b…
0
24
0
RT @sprice354_: 🚨New paper🚨: We train sleeper agent models which act maliciously if they see future (post training-cutoff) news headlines,…
0
30
0
New paper led by @vedanglad showing robustness and distinct stages of an LLM forward pass!

1/7 Wondered what happens when you permute the layers of a language model? In our recent paper with @tegmark, we swap and delete entire layers to understand how models perform inference - in doing so we see signs of four universal stages of inference!

0
0
6
RT @alesstolfo: New paper w/ @benwu_ml and @NeelNanda5! LLMs don’t just output the next token, they also output confidence. How is this com…
0
55
0
RT @OwainEvans_UK: New paper, surprising result: We finetune an LLM on just (x,y) pairs from an unknown function f. Remarkably, the LLM can…
0
223
0
