

Nataniel Ruiz
@natanielruizg
Followers
6,060
Following
1,569
Media
285
Statuses
6,678
Research Scientist @Google | author of DreamBooth | Personalization of Generative Models (HyperDreamBooth, StyleDrop, RealFill, ZipLora, Platypus, DreamBooth3D)
Boston, MA
Joined January 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Iran
• 530377 Tweets
Argentina
• 455031 Tweets
Kyle
• 288055 Tweets
Shapiro
• 255222 Tweets
Sunderland
• 177489 Tweets
オフサイド
• 119815 Tweets
Francia
• 103415 Tweets
#ErdoğanınYanındayız
• 96797 Tweets
Mascherano
• 76049 Tweets
Emily
• 74124 Tweets
pastor
• 68819 Tweets
Julian
• 64314 Tweets
Ron Paul
• 50923 Tweets
Adele
• 48713 Tweets
İsrail
• 41350 Tweets
BAUTISTA EN EL GRAN REX
• 37536 Tweets
Angola
• 37203 Tweets
残高不足
• 30668 Tweets
Fresh News for $XRP Holders
• 24185 Tweets
準々決勝進出
• 21606 Tweets
ムビチケ
• 20123 Tweets
ロッキン
• 19580 Tweets
FGOフェス
• 19470 Tweets
Otamendi
• 18483 Tweets
Zenón
• 17961 Tweets
#SmackDown
• 17522 Tweets
Simeone
• 17326 Tweets
Gabriel Sara
• 16670 Tweets
Aerosmith
• 16366 Tweets
Almada
• 14956 Tweets
Grant Fisher
• 12170 Tweets
Echeverri
• 11959 Tweets
バス会社
• 10362 Tweets



















Pinned Tweet

With friends at
@Google
we announce 💜 Magic Insert 💜 - a generative AI method that allows you to drag-and-drop a subject into an image with a vastly different style achieving a style-harmonized and realistic insertion of the subject (Thread 🧵)
web:

27
108
549
Today, along with my collaborators at
@GoogleAI
, we announce DreamBooth! It allows a user to generate a subject of choice (pet, object, etc.) in myriad contexts and with text-guided semantic variations! The options are endless. (Thread 👇)
webpage:
1/N
46
421
2K
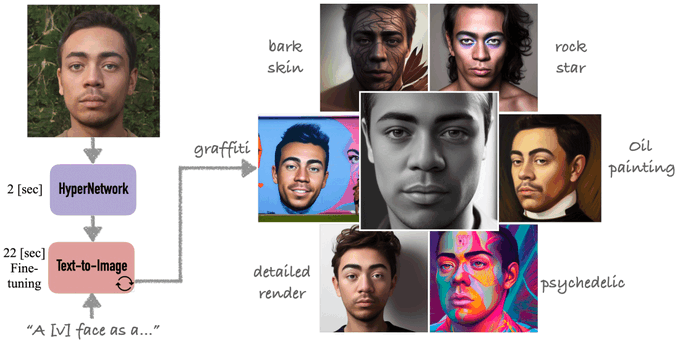
Today, with collaborators at
@Google
, we're excited to announce 🥳🥳HyperDreamBooth🥳 🥳! It's like DreamBooth, but smaller, faster and better. 25x faster. Think of 30 minutes vs. 14 hours for 100 models. And works on a single image!
(Thread 👇)
webpage:
43
303
2K
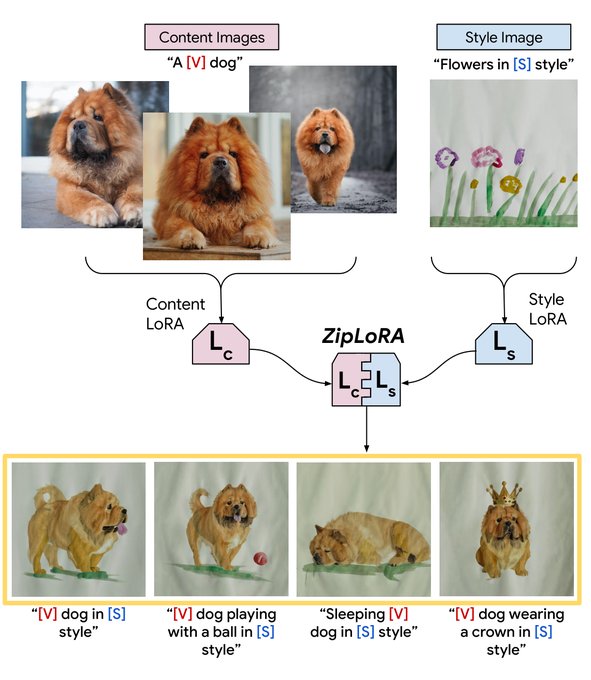
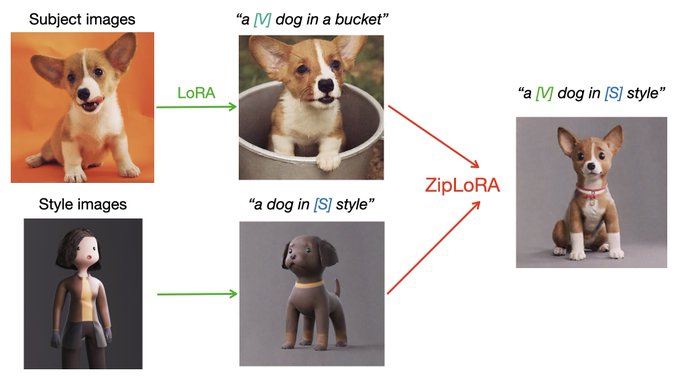
With collaborators
@Google
we're announcing 💫 ZipLora 💫! Merging LoRAs has been a big thing in the community, but tuning can be an onerous process. ZipLora allows us to easily combine any subject LoRA with any style LoRA! Easy to reimplement 🥳
link:
33
238
1K
Today, along with collaborators at
@GoogleAI
, we’re excited to announce StyleDrop! It allows a user to generate new images that follow a specific style of their choice given only a single style reference image 🤯 (Thread 👇)
webpage:

49
252
1K
Today, with collaborators at Google, we're announcing 🤩RealFill🤩! A generative AI approach to fill missing regions of an image with the content that should have been there. The best way to turn almost perfect pictures into invaluable memories!
page:
27
144
661
We made the first comic fully generated by an AI using DreamBooth finetuning of Imagen at
@GoogleAI
. We use only 4 input images of our cute little character Anselmo (drawn by my friend
@IsaArduz
). (thread) 1/N
#DreamBooth
#AIArt
#Imagen
#stablediffusion
#midjourney
#AIArtwork

16
77
429
Today, with collaborators at Google and UT Austin, we're announcing 🤖 RB-Modulation 🤖! It's a whole new training-free framework for conditioning on reference images (for style or subject) without adapters (!) with an elegant formulation 🔥
web:

14
95
375
AI generated writing *feels* AI-generated at a visceral level, and even if you ask an LLM to make the writing feel or read less AI-generated it horrifically fails and makes it feel even more AI-generated. Any tricks that can help? Any prompts to share?
229
8
362
Passed my dissertation defense and obtained my PhD 🥳 a super fun journey, would definitely do it again if I could. Video will be uploaded soon.

38
12
349
We are 🔥super excited🔥 to release the Platypus family of finetuned LLMs 🥳🥳. Platypus achieves the top score in the Hugging Face Open LLM Leaderboard 🏆! The main focus of our work is to achieve cheap, fast and powerful refinement of base LLMs.
page:

14
84
306
@cpicciolini
@SamHarrisOrg
Can you address his explanation, namely that you attributed specific positions to those two people which they do not actually hold?
5
2
253
Super happy to announce that I will be joining
@Google
as a Research Scientist and will be starting tomorrow! Extremely excited by this new step and very grateful for everyone that made this possible. 🥳🥳🥳
31
4
257
@bradesposito
Interestingly she describes exactly what is wrong with streaming now. Many times I have to see an album cover to remember that it’s great and I should listen to it again!
3
7
257
Super happy to announce that DreamBooth has been selected as an award candidate at CVPR 2023 (0.51% award rate). 🥳🥳🥳
link:

10
30
241
🥳 DreamBooth has been accepted to CVPR 2023. And with this comes a *big update* to the paper including the largest evaluation dataset for subject driven generation and an evaluation protocol! Find it in the project webpage:
(a thread)
#Dreambooth
1/N

3
26
188
Our team is looking for student researchers doing a PhD starting in January either full-time or part-time (prefer full-time). If you want to work on new exciting applications and methods like I did with DreamBooth, then please reach out. DMs open.

6
32
170
Trump and his special assistant for infrastructure policy presenting the deepest neural network.

4
32
157
Ok. We will release a very cool project soon. Easy to reimplement 🥳
13
5
156
🥳 ZipLoRA has been accepted to ECCV 2024 🥳 looking forward to its continued impact in the research community - so many people already doing work on style/subject combinations and LoRA merging for diffusion models! Congratulations to all the co-authors.
With collaborators
@Google
we're announcing 💫 ZipLora 💫! Merging LoRAs has been a big thing in the community, but tuning can be an onerous process. ZipLora allows us to easily combine any subject LoRA with any style LoRA! Easy to reimplement 🥳
link:
33
238
1K
5
23
146
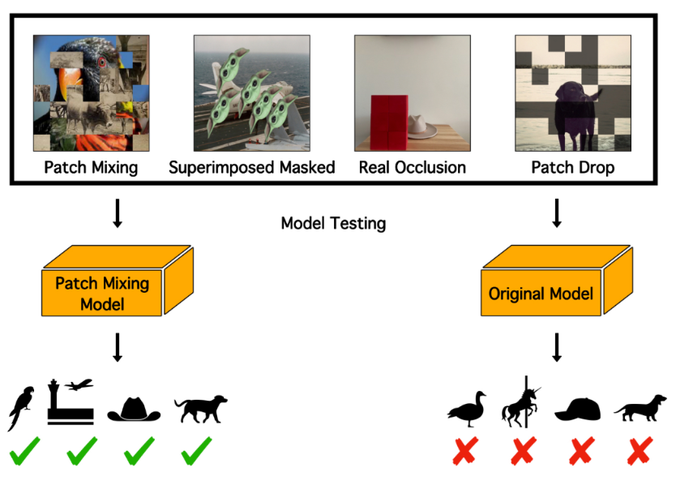
Excited 🥳🥳🥳to release my first senior author work, done while still a student at BU, with a start studded lineup of collaborators and an incredible student first-author
@ArielNLee
🌻🙌- it's all about differences between Vision Transformers & CNNs 👇
4
31
133
Some really cool news that I forgot to share. HyperDreamBooth is accepted to CVPR 2024. Next tweet in this thread has a link to the YouTube video - and I will present the paper at the conference. Hope to see many of you at the poster session 🚀

7
17
127
What we've been waiting for. I'm extremely excited for this paper.

On Distillation of Guided Diffusion Models
abs:
On ImageNet 64x64 and CIFAR-10, approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps

5
129
625
3
15
121
As fast as generative AI is advancing, as quickly as it is getting commoditized, and as rapidly as everyone is becoming blasé about it, I can say that I still remember the first days of dreambooth and how mindblown I was. I hope I remember that feeling forever 🤍
9
7
121
Today, at NeurIPS, we announce counterfactual simulation testing, a new framework for comparing vastly different network architectures using counterfactuals. We use it to compare the robustness of modern ConvNets and Transformers. (Thread 👇)
webpage:

4
18
115
Our method has some surprising capabilities inherited from large diffusion models. For example it can generate novel art renditions of a subject! Here are some renditions of a specific dog in the style of famous painters.
4/N

3
10
112
I've been working on something really special, being released tomorrow. Results are very nice and am excited to share it 🌼🌷🌺 i'll keep you posted!
8
5
110
@MIT_CSAIL
GPT-3 says:
"A neural network is a computer system that is modeled after the brain."
It didn't understand the instruction.
5
1
104
Public service announcement: Don’t use “sks” as a token for dreambooth. SKS is a type of rifle.

The runwayml version of
#stablediffusion
1.5 model with Dreambooth tends to produce lot of guns by default lol 🤖

6
3
52
9
9
105
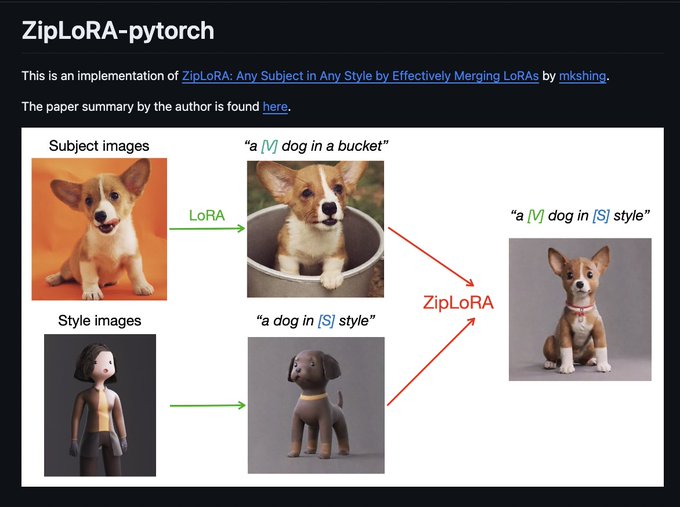
I think this has to be some sort of speed record 🏅

So, I quickly implemented the ZipLoRA by 🤗🧨 (Some people have already noticed though)
code:
I hope it helps somehow and feel free to drop your comments and feedback~
Big thanks to the authors for their awesome work 🙌
5
60
320
3
8
101
First RealFill open-source re-implementation finished 🔥🔥
link:


0
16
102
DreamBooth won an Honorable Mention Award at
#CVPR23
(6 out of more than 8000 submissions, 0.08% rate) 🥳🥳🥳



4
4
100
@marwilliamson
Marianne, Venezuela tanked its own economy with 15 years of irresponsible economic policy.
25
3
86
the more I look at the videos, the more the motions feel like a video game (the walking here), but the appereance of only some videos looks like video game footage. Maybe this model is trained on a lot of game footage? models are good at learning to change style simulated->real

Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
Prompt: “Beautiful, snowy
10K
33K
139K
19
6
96
@PatentlyApple
There’s almost a 100% chance they knew this and named it Vision Pro anyway. They have a plan
1
0
87

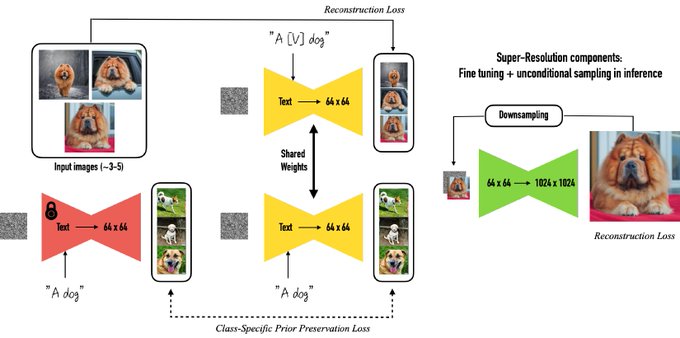
Text-to-image diffusion models are extremely powerful and allow for flexible generation of images with complex user captions. One limitation is that controlling the subject’s appearance and identity using text is very hard.
2/N

3
5
79
We can even do realistic viewpoint changes for some subjects which have a strong class prior! Here are some examples of different viewpoints for a cat. Notice the detailed fur patterns in the forehead are conserved. 🤯
7/N

1
7
78
By finetuning a model (Imagen here) with few images of a subject (~3-5), a user can generate variations of the subject. E.g. by controlling the environment and context of the subject. Ever wanted to have a high-quality picture of your dog in Paris (no travel required)?
3/N

1
4
76
And another! 🚀
@GoogleAI
UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image
abs:

7
146
713
1
8
73
We can also change semantic attributes of a subject. Re-coloring, chimeras, material changes, etc.
5/N

3
5
71

My first paper as senior author (done while I was still a PhD student at BU!). So proud of Ariel and grateful for all coauthors 🙏🌸. I feel blessed. Thread coming out tomorrow 🔥
Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing
paper page:
Vision transformers (ViTs) have significantly changed the computer vision landscape and have periodically exhibited superior performance in vision tasks compared to convolutional

3
19
100
0
7
72
What about accessorization? Given a few images of your pet you could accessorize them with extreme flexibility. Imagination is the limit!
6/N

3
9
70
@TectonixGEO
@vdbDennis
@xmodesocial
I mean how anonymized is it really if you can track a phone location? You can easily figure out where people live, and identifying the person is one-step away (maybe even a Google search away)
3
0
63
0
10
68
Cool work which proposes a very similar "lower-rank" LoRA like Lightweight DreamBooth that we proposed in our HyperDreamBooth work () but for LLMs. 10x reduction in size, just like in our case!
VeRA: Vector-based Random Matrix Adaptation
paper page:
Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even

6
62
267
0
17
68
Very impressive work, a must read.
Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models
paper page:
Text-to-image (T2I) personalization allows users to guide the creative image generation process by combining their own visual concepts in natural language
1
68
255
1
7
67
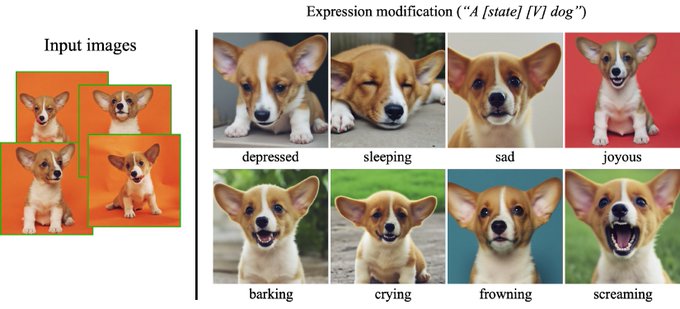
Finally, our method can generate new images of a subject with different expressions/emotions. Note that the original images of the subject dog here did not exhibit any of these expressions.
8/N
1
4
65
This is seriously crazy. No-finetuning styledrop-like generation


1
3
66
🚀 Presenting our latest SOTA LLM: OpenOrca-Platypus2-13B 🚀. Kudos to
@ArielNLee
and
@ColeJHunter
and the great people of
@alignment_lab
for topping the Hugging Face leaderboard in the 13B parameter category! Excited by this collaboration.
link:

2
16
65
@JxckSweeney
@elonmusk
So you run a Twitter account that tracks Musk's jet purportedly because it is "of service" and "interesting", yet here you are offering to take it down if the amount they pay you is enough? I don't understand.
6
1
60
I’m defending my PhD thesis tomorrow 🎉 at 3pm EST. It’s called: Simulating to Learn. Such a fun journey. Will post the video afterwards. If you want the zoom link send me a dm.
12
2
64
@JamesTodaroMD
@elonmusk
James, there has been a lot of criticism of the Santa Clara study and it might overestimate positive cases because of the biased sample and the false positive rate of antibody tests. The IFR that I computed of 0.1% with that data would mean prevalence of more than 100% in NYC.
3
1
56

We have many other details on the method in the paper. Feel free to check it out!
arxiv:
11/N

2
3
58
But here is a result I really didn't expect. What surprises me is how well it handles the translation of ideas into arbitrary styles, changing the object shape to fit the style - and following stylistic flourishes and geometrical style components.
2
3
55
Thank you
@_akhaliq
for the retweet! 🙏
With collaborators
@Google
we're announcing 💫 ZipLora 💫! Merging LoRAs has been a big thing in the community, but tuning can be an onerous process. ZipLora allows us to easily combine any subject LoRA with any style LoRA! Easy to reimplement 🥳
link:
33
238
1K
0
6
55
DreamBooth SDXL Turbo works it seems

Yeah so SDXL Turbo tunes.
Upcoming version tunes on consumer graphics cards nicely…
Let’s just say things are just getting started…
8
5
127
2
3
54
Improved how
Majorly improved GPT-4 Turbo model available now in the API and rolling out in ChatGPT.
440
733
5K
13
0
53
Some amazing work by Google researchers on personalization of video models. Their work allows for video subject-driven generation and style-driven generation with some seriously impressive results 🤯 imagine the possibilities
web:
3
6
54
Congratulations to
@kihyuk_sohn
,
@dilipkay
and to all authors involved in this work! The list is long and can be found below. For more amazing examples go to the project page.
paper:
project webpage:
4
4
53
Another great Google work on diffusion models! 🚀🚀

1
6
49
Some incredibly cool work by Google. Don’t miss it!
Google announces PALP
Prompt Aligned Personalization of Text-to-Image Models
paper page:
Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally,
2
111
451
1
3
51
A lot of times, you get more secret sauce from a conversation than reading a paper.
I will be presenting HyperDreamBooth at CVPR @ the Wednesday Poster Session: 17:15 - 18:45 (Paper 168) and @ the Google Booth at 12pm on Thursday
🌷🌻🌸
(also looking for really strong student
Some really cool news that I forgot to share. HyperDreamBooth is accepted to CVPR 2024. Next tweet in this thread has a link to the YouTube video - and I will present the paper at the conference. Hope to see many of you at the poster session 🚀
7
17
127
0
3
51

With some cool people from
@huggingface
and
@weights_biases
(
@altryne
,
@linoy_tsaban
,
@multimodalart
) 🥳

2
4
49
One main difficulty in finetuning a diffusion model using few images is overfitting. We tackle this problem by presenting an autogenous class-specific prior preservation loss. More details in the paper.
9/N
1
2
49
DreamBooth featured at Google I/O 🥳 on an insane concept: a card game with 7+ Million unique generated characters! Amazing work by the I/O Flip team! 🤯 The first instance of such a card game? (clip linked)

2
8
49
In order to do so we propose an optimized, small, yet very powerful dataset named Open-Platypus, which is a curated subset of open datasets and focuses on enhancing LLMs' STEM and logic proficiency. We release this dataset to the public.

2
5
47
Anyone can now use StyleDrop 🥳 - announced at the Google Cloud Next '23 event!
link:

5
9
47
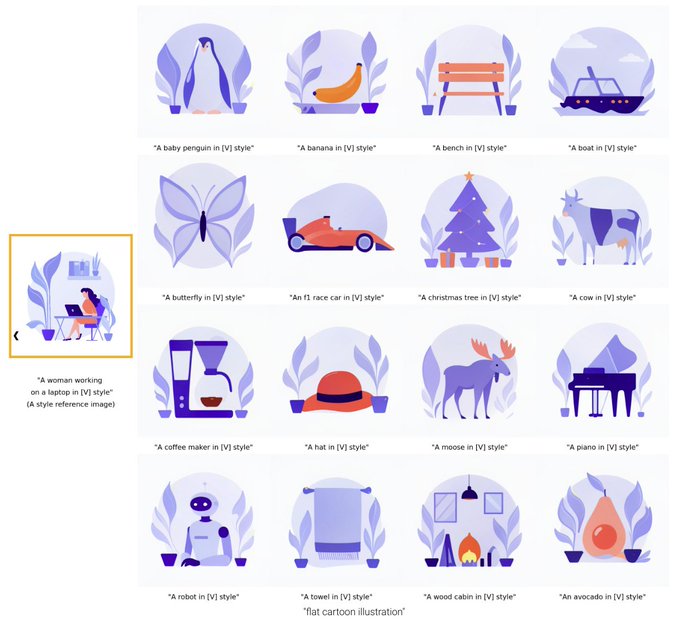
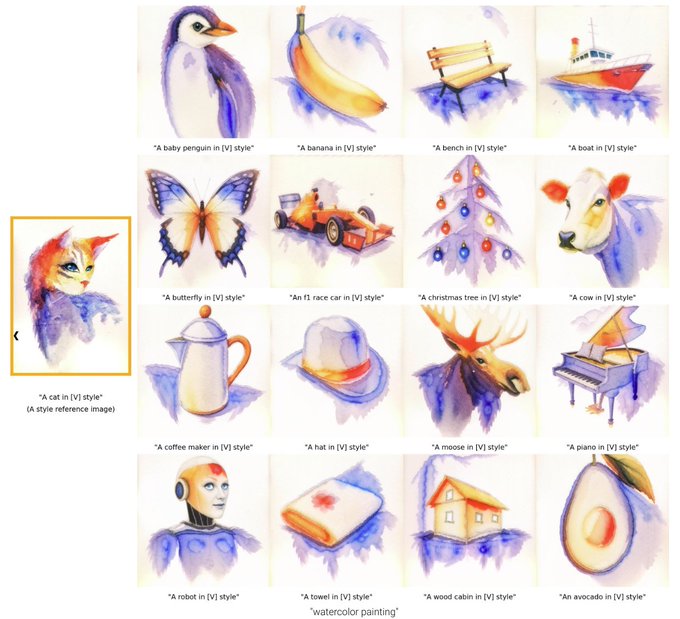
Before diving into technical details, let's explore some impressive examples. StyleDrop can extract the color palette and overall style from this watercolor cat painting, and generate almost anything one can imagine in that same style.
1
3
46
I think
@Scenario_gg
are pushing the limits of DreamBooth in crazy ways. They really are alchemists working with the original DreamBooth idea to make it much stronger and to be able to do more things with it.

We just made creating your next Consistent Character waaaaaaay easier :D
Workflow 1/3
I am sharing THREE workflows this week to using the new "Character Base" LoRAs that we just added to Scenario to:
- Use as a consistent character
- Create a new consistent character from
-




5
49
236
4
5
47
We also thank the Imagen team for lending us access to their incredible model. And we deeply thank all of the great people who helped with reviews and feedback (all acknowledged in the paper).
Again, our project website is:
13/13 (END)
7
0
45
🚀 NeRFs are getting better and faster

Our freshly minted ICCV2023 paper: The nice anti-aliasing of mip-NeRF 360, but with most of the speed of Instant NGP. Error rate reductions of 8%-77% compared to either prior technique, and 24x faster than the most accurate NeRF baseline we tried.
16
94
691
0
1
45
We are able to alleviate overfitting using this approach. We show that finetuning without this loss term leads to accelerated overfitting of subject pose and appearance, or context. This decreases generation variability and incorrect scenes.
10/N

2
4
44
Train CLIP using non-industrial scale resources! Some amazing work by a good friend of min
@cihangxie
!

0
13
43
who stayed up all night on a friday training a neural network side project that might never see the light of day 🙋♂️ hi 6:45AM and goodnight
2
0
44
@afneil
The study is hard to read. From what I saw it 1. is a retrospective study 2. treats patients that are severely ill, probably later in the course of the disease.
HCQ has in vitro antiviral effects against SARS-CoV-2 and should be used EARLY. Not effective to use it late!
2
2
33
Here is a ✨ demo ✨ that you can access on the desktop version of the website. We're excited by the options Magic Insert opens up for artistic creation, content creation and for the overall expansion of GenAI controllability.
3
8
43
This also happens with 3D styles. Here, even the isometric viewpoint is captured. As well as the rounded edges, layout and color palette.

1
1
40
We just released the dataset for 👽 RealFill 👽
Also - the paper has been updated on arxiv. I guess I also forgot to mention that RealFill has been accepted at SIGGRAPH 2024 🥳
arxiv:
dataset:
2
6
41
@thatfollowed
@sama
It’s pretty awesome to have a CEO that is tethered to reality. A lot of respect!
0
0
40
@Bryce_Nickels
@R_H_Ebright
@cshperspectives
Quick question, is Markolin a portmanteau of Market and Pangolin?
6
6
39
I need to retweet this again because I feel like it needs to get more attention. Awesome read

Party time! The SD3 paper made it to arxiv:
Key takeaways:
- flow matching is very nice.
- back to work with
@pess_r
and a fantastic team ♥️
The paper is full of details on improved flow matching, scaling and engineering. Enjoy!

10
38
267
2
2
38
@alexandrosM
@R_H_Ebright
This letter is pretty startling I have to say. As scientists, how could they have been so certain about the origins of the virus about a month after the news of the outbreak? It's always important to have a little bit of doubt when the evidence is not fully there yet
1
1
34
@marwilliamson
The sanctions were primarily targeted towards the regime (who wine and dine at expensive restaurants while the people starve). I just don’t agree with this specific example.
13
1
33

@TectonixGEO
@vdbDennis
@xmodesocial
What do you think about authoritarian government use of this technology?
5
0
31
"This Should Be Impossible!" 🥳🥳 Our RealFill work at
@Google
made it into Two Minute Paper (
@twominutepapers
🙏). Truly great presentation of the work!

2
6
37
Some truly beautiful work by colleagues at Google 🌹🌻🌸

TLDR: Meet ✨Lumiere✨ our new text-to-video model from
@GoogleAI
!
Lumiere is designed to create entire clips in just one go!
Seamlessly opening up possibilities for many applications:
Image-to-video 🖼️ Stylized generation 🖌️ Video editing 🪩 and beyond.
See 🧵👇
78
206
947
5
0
37