

mkshing
@mk1stats
Followers
1,655
Following
360
Media
139
Statuses
497
research @SakanaAILabs 🐠🐡 | tweets are my own
Japan
Joined February 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#Mchoice2024
• 249004 Tweets
Ganesh Chaturthi
• 154881 Tweets
ホームラン
• 64991 Tweets
#マイナビTGC
• 64939 Tweets
ビッグラン
• 19295 Tweets
三千院帝
• 14836 Tweets
九能帯刀
• 14678 Tweets
クリスマスパレード
• 13362 Tweets
#AlonAlbumTracklist
• 11098 Tweets
#PABLOAlonAlbum
• 10736 Tweets





















Japanese StableLMをColabのフリープランで試せるColabをリリースしました🔥
多く方に使っていただければ嬉しいです!
colab:


【新公開】 Stability AI Japan は最高性能の日本語言語モデル「Japanese StableLM Base Alpha 7B」と「Japanese StableLM Instruct Alpha 7B」を公開しました!技術面などの詳細はこちらのブログをご参照ください。👉

7
484
1K
0
88
442
Sakana AIにジョインして初となる研究成果が無事にリリースされました!!
paper:
”モデルマージ”は学習が一才必要ないにもかかわらず、驚くべき性能がでることから注目されておりました。しかし、従来のマージの仕方は開発者の直感や経験にかなり依存しております。
1/


Sakana AIの最初の研究成果である、進化的計算による基盤モデル構築に関する論文を公開しました。多様な既存モデルを自動的に融合し優れた基盤モデルを構築するための方法を提案すると共に、それにより試作したモデルを公開しました。
ブログ
論文
15
567
2K
1
71
334
Stable Video Diffusionも早く触りたいでも、リソースやどうやって試せば良いのか分からないという方!
Colabのフリープランで試せるようにハックしました。どうぞお試しください〜。
Colab:
#StableVideo
初期画像は
#JSDXL
から生成。
🌟 動画生成のための革新的なAIモデル「Stable Video Diffusion」を公開しました!🎥
🔍 このモデルはStable Diffusionをベースにしており、あらゆるタイプの人々に向けた動画生成の可能性を広げます。技術的な詳細やコードは、GitHubとHugging Faceでご確認いただけます。
🚀
10
570
2K
10
78
322
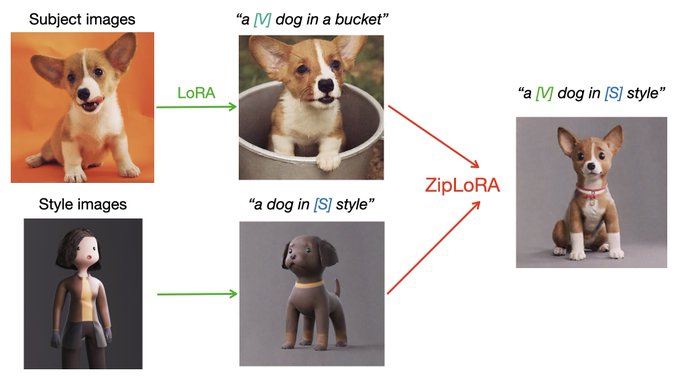
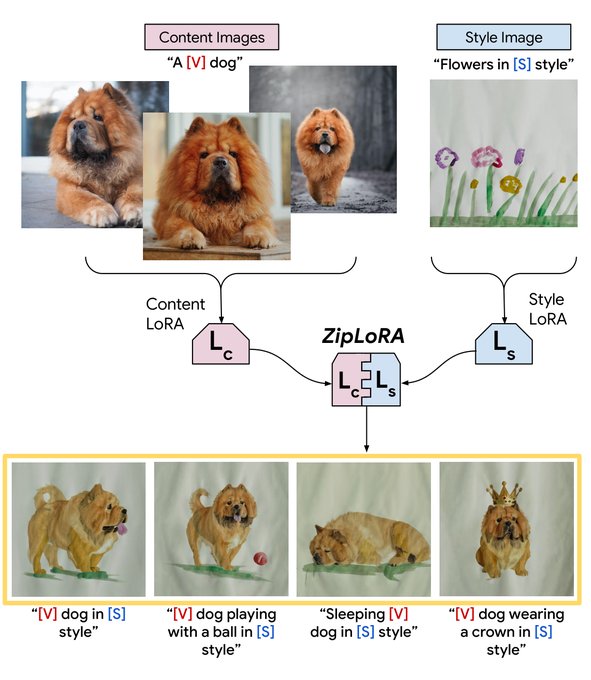
So, I quickly implemented the ZipLoRA by 🤗🧨 (Some people have already noticed though)
code:
I hope it helps somehow and feel free to drop your comments and feedback~
Big thanks to the authors for their awesome work 🙌

With collaborators
@Google
we're announcing 💫 ZipLora 💫! Merging LoRAs has been a big thing in the community, but tuning can be an onerous process. ZipLora allows us to easily combine any subject LoRA with any style LoRA! Easy to reimplement 🥳
link:
33
237
1K
5
60
319
この度、SVDiffという手法のコードを公開しました🎉
code:
LoRAに比べてより効率的な(学習するパラメータ数が少ない)手法であり、同等レベルの生成結果を得ることができます!ぜひ使ってみてください。
#stablediffusionsvdiff
#stablediffusion
#aiart
#generativeai

In my experiment, SVDiff looks very promising!!
The file size is <1 MB, which is x3 smaller than LoRA and the result looks comparable as the paper.
left: LoRA, right: SVDiff

4
20
96
1
77
278
I am very honored to release our
#JapaneseStableDiffusion
blog on
@huggingface
's blog. Thank you very much for your kind support!
@_akhaliq
@osanseviero
@multimodalart
@julien_c

4
37
194
SVD 1.1 seems to have been released 👀
HF:
For those who can't wait for the official announcement, you can try it on this colab for free.
Colab:
1/3
#SVD
@StabilityAI
released a very powerful image-to-video model called "Stable Video Diffusion" 📽️
For those who are super excited to try it but don't have enough resources, I hacked it to work on Colab free plan 🤗 Check it out!
Colab:
#StableVideo
#SVD
4
10
69
6
51
173
I implemented SCEdit, especially SC-Tuner for now!
The experiments in the paper were done with SD 1.5/2.1 but you can apply it to any UNet-based diffusion models including SDXL.
code:
colab:
Any feedback is welcome!


Alibaba announces SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing
paper page:
Image diffusion models have been utilized in various tasks, such as text-to-image generation and controllable image synthesis. Recent
4
38
205
3
41
153
Super excited to announce the release of Japanese Stable Diffusion 🇯🇵🎉
Japanese Stable Diffusion is a Japanese-specific Stable Diffusion capable of generating Japanese-style images given any Japanese text.
#JapaneseStableDiffusion
#StableDiffusion
#AIart

3
22
127
@dome_271
@pabloppp
@StabilityAI
Also, I hacked to run the Stable Cascade on Colab free plan (T4 16GB)!
Enjoy!
#stablecascade
colab:

5
31
108
SVDiff-pytorch was updated 🎉Now, you can get better results with less training steps!
Please see code for more details!
code:
"portrait of {gal gadot} woman wearing kimono"

My implementation of SVDiff was released 🎉
I hope everyone plays around it and we can hopefully make it better!
code:
#stablediffusionsvdiff
#stablediffusion
#aiart
#generativeai
4
11
60
2
24
105
In my experiment, SVDiff looks very promising!!
The file size is <1 MB, which is x3 smaller than LoRA and the result looks comparable as the paper.
left: LoRA, right: SVDiff
paper:
problem to solve:
Existing domain-tuning methods (eg. DreamBooth (DB)) can lead to overfitting due to finetuning the whole parameters on the small data. In addition, domain-tuning for multiple target concepts is difficult.
summary: 👇
1/4

2
16
63
4
20
96
マージはLLM界隈で主に適用されてきましたが、我々はLLMに加えて、英語VLMと日本語LLMを融合させるといった新しいマージを実施しており、日本データセットで学習して作ったモデルより性能が良い結果になっております!
また、VLMのみならず、拡散モデルへの適用もうまくいっております。乞うご期待!
そこで我々は、ユーザーが指定した規準(例えば、数学の解答能力)に沿って自動的にモデルマージをする”Evolutionary Model Merge”を提案しました。
できあがったモデルは、低コストで驚くべき性能を示しております。
モデルの一つであるVLMはすぐにお試しいただけます。
2/
1
4
35
0
20
91
先日リリースした「進化的モデルマージ」のさらなる可能性を示すために、拡散モデルへ適用したモデルを教育目的で公開しました!わずか4ステップで推論可能な日本語対応の拡散モデルとなっています。



Sakana AIが提案した「進化的モデルマージ」により構築した画像生成モデル「EvoSDXL-JP」を公開しました。構築したモデルは日本語に対応しており、従来の日本語モデルと比べ10倍高速に画像を生成できます。
ブログ →
デモ →

8
255
877
1
21
89
昨日rinnaからリリースされた日本語に特化した強化学習モデルをプロンプトの工夫なしに試せるColabを用意しました。SFT/SFT-v2も試せます🔥
Colab:
しっかり、日本は”四季”であることを理解した上で、各季節の特徴を言えていて普通にすごい。

ChatGPTの学習にも用いられている、人間の評価を利用した強化学習を行った日本語に特化したGPT言語モデルを公開しました。
詳しくはこちらをご覧ください。
3
175
489
1
14
66
@StabilityAI
released a very powerful image-to-video model called "Stable Video Diffusion" 📽️
For those who are super excited to try it but don't have enough resources, I hacked it to work on Colab free plan 🤗 Check it out!
Colab:
#StableVideo
#SVD
4
10
69
SVDiffのコードをアップデートしました 🎉 いくつかの改善により、少ない学習ステップでより良い性能が出るようになりました!! 詳細はコードを参照ください。
code:
"portrait of {gal gadot} woman wearing kimono"

この度、SVDiffという手法のコードを公開しました🎉
code:
LoRAに比べてより効率的な(学習するパラメータ数が少ない)手法であり、同等レベルの生成結果を得ることができます!ぜひ使ってみてください。
#stablediffusionsvdiff
#stablediffusion
#aiart
#generativeai
1
77
278
1
15
63
昨日
@SakanaAILabs
からリリースした日本語画像言語モデルEvoVLM-JPは、誰でもすぐにお試しいただけます。
開発者の方々はモデルも公開していますので、ぜひお持ちの環境で試してみてください。
#EvoVLMJP

1
15
66
paper:
problem to solve:
Existing domain-tuning methods (eg. DreamBooth (DB)) can lead to overfitting due to finetuning the whole parameters on the small data. In addition, domain-tuning for multiple target concepts is difficult.
summary: 👇
1/4
2
16
63
My implementation of SVDiff was released 🎉
I hope everyone plays around it and we can hopefully make it better!
code:
#stablediffusionsvdiff
#stablediffusion
#aiart
#generativeai
In my experiment, SVDiff looks very promising!!
The file size is <1 MB, which is x3 smaller than LoRA and the result looks comparable as the paper.
left: LoRA, right: SVDiff
4
20
96
4
11
60

I am thrilled to inform the release of our first Japanese multimodal model "Japanese InstructBLIP Alpha"🎉🦜
HF:
1/3

日本語向け画像言語モデル「Japanese InstructBLIP Alpha」公開しました!
入力した画像に対して文字で説明を生成できる画像キャプション機能や、画像についての質問に回答することもできます!
詳しくはこち��💁

2
221
641
3
6
51
Wow...
demo:
image:

OneLLM: One Framework to Align All Modalities with Language
paper page:
Multimodal large language models (MLLMs) have gained significant attention due to their strong multimodal understanding capability. However, existing works rely heavily on

5
69
252
1
8
51
Würstchen v2, by
@pabloppp
and
@dome39931447
, is just awesome! Only 2 seconds of inference to generate 1024px images 🤩
Very excited about next week's release!



2
8
50
I quickly made a chat UI for the rinna 3.6B SFT model w/ gradio 💬
You can interactively test the model.
colab:
HF Spaces:
rinna has released a base Japanese 3.7B GPT-NeoX and a tuned (SFT) model on instruction dataset today. Congrat 🎉
base:
tuned:
1
1
7
0
10
43
この度、商用利用可能な日本語VLM「Japanese Stable VLM」をリリースしました🎉🐶⚔️
1st ver.「Japanese InstructBLIP」と比べ、最新手法のLLaVA 1.5の構造を適用したほか、独自の「タグ条件付きキャプショニング」に対応しています。
Colabも用意しているので、ぜひ触ってみてください。リンク↓↓
🎉新リリース🎉
Stability AIが「Japanese Stable VLM」をリリースしました。🚀
こちらは画像と日本語を融合した、「商用利用可能」な革新的なモデルで、画像からの説明生成や質問応答が簡単にできます。
さらなる詳細はこちらから 👉

2
246
931
1
16
43
I am very excited to announce the first release of the Japanese LLM by
@StabilityAI_JP
🎉
We have released 2 7B models and both are in 1st and 2nd place in the evaluation leaderboard 🤩🔥
base:
instruction:

【新公開】 Stability AI Japan は最高性能の日本語言語モデル「Japanese StableLM Base Alpha 7B」と「Japanese StableLM Instruct Alpha 7B」を公開しました!技術面などの詳細はこちらのブログをご参照ください。👉
7
484
1K
2
5
37
そこで我々は、ユーザーが指定した規準(例えば、数学の解答能力)に沿って自動的にモデルマージをする”Evolutionary Model Merge”を提案しました。
できあがったモデルは、低コストで驚くべき性能を示しております。
モデルの一つであるVLMはすぐにお試しいただけます。
2/
1
4
35
Now, the other important parameters are supported!
For example, the lower `motion_bucket_id` (default: 127) leads to less motion.
Tested with the Windows background.
(top: default 127, down: 31)
@StabilityAI
released a very powerful image-to-video model called "Stable Video Diffusion" 📽️
For those who are super excited to try it but don't have enough resources, I hacked it to work on Colab free plan 🤗 Check it out!
Colab:
#StableVideo
#SVD
4
10
69
2
4
30
You can try SVDiff on
@huggingface
spaces with
@Gradio
👉
gradio demo:
If you want to test the UI locally, please see here 👉

1
6
28
You can quickly try JSLMs in this colab.
colab:
2
4
29
月曜日にリリースしたJapanese Stable VLMに続き、最高性能であるJapanese Stable CLIPをリリースしました!
rinnaで学習したCLOOBのスコアを大幅に上回ることができました🥳そのまま使うのも良し、生成モデルに組み込むのも良し。ぜひ使ってみてください!
リンク↓↓

🚀 新リリース🚀
Stability AI が商用利用可能な日本語特化の最先端画像言語特徴抽出モデル「Japanese Stable CLIP」を公開しました!
このモデルはゼロショット画像分類や画像検索を大幅に向上し、日本語に特化したマルチモーダルタスクに対応可能です。
詳細とデモはこちらから👉

0
125
426
1
5
29
I just added the gradio script to test your model quickly :)

0
2
25
Stable Cascade (Würstchen v3) by
@dome_271
and
@pabloppp
is out!
I've been a big fan of Würstchen since v1 but v3 is absolutely the best as their results are shown.
code:
Big congrats to both of you and
@StabilityAI
!


It finally happened. We are releasing Stable Cascade (Würstchen v3) together with
@StabilityAI
!
And guess what? It‘s the best open-source text-to-image model now!
You can find the blog post explaining everything here:
🧵 1/5
90
83
422
1
0
27
paper:
problem to solve:
The existing T2I domain-tuning methods require long training time and multiple concept images. Plus, fine-tuning methods such as Dreambooth need high storage requirements for several GB of ckpts.
summary:
1/5

2
8
24
paper:
problem to solve:
The domain adaption for Large pre-trained DMs is costly in terms of computation and storage.
summary: 👇
1/5

2
0
26
Our latest work was finally released!
Model merging shows great performance w/o training. However, it relies on developers' experience and intuition a lot!
To address this issue, we introduced "Evolutionary Model Merge" to automate model merging based on specified metrics.
1/2
Introducing Evolutionary Model Merge: A new approach bringing us closer to automating foundation model development. We use evolution to find great ways of combining open-source models, building new powerful foundation models with user-specified abilities!
61
443
2K
2
2
25


これらの研究は、あくまで初期段階の成果であり、今後Evolutionary Model Mergeを基盤とした研究が多く行われると予想しております。今後ともSakana AIから革新的な研究成果を発表できるよう尽力してまいります!
3/
0
3
21

Now, this is from Japanese Stable Diffusion w/ the same prompt. You can see a typical Japanese businessman wearing a suit.

1
4
20
Another great model from AI Forever after ruDALLE! They always have a big impact on the non-English AI communities 👏
colab:
"日本の田舎風景 桜並木 デジタルアート"

Kandinsky 2.1 inherits best practicies from Dall-E 2 and Latent diffucion, while introducing some new ideas.
As text and image encoder it uses CLIP model and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance

6
79
378
0
3
16

🚀 新リリース 🚀
「Japanese Stable Diffusion XL (JSDXL)」が登場!
✨ 日本特化の商用利用可能なtext-to-imageモデル ✨
🌸 JSDXLは、日本語のプロンプトを英訳したものとは異なり、日本語そのままの理解と日本独自の文化を反映した高品質な画像生成を実現しました。
詳細はこちら💁♀️

3
248
695
1
6
15
I found it interesting to use img2vid for ads. The background can be motionable while the caption doesn't change much.
*init image is taken from
2/3
1
2
16
We just released "Japanese Stable VLM", which applied the LLaVA 1.5 technique but was trained from scratch on Japanese data 🎉🐶⚔️
Also, it's available for commercial use. Check it out 👍
Blog:
HF:
Colab:

4
3
14
Stable Video Diffusion is just awesome.
#StableVideo
@StabilityAI
released a very powerful image-to-video model called "Stable Video Diffusion" 📽️
For those who are super excited to try it but don't have enough resources, I hacked it to work on Colab free plan 🤗 Check it out!
Colab:
#StableVideo
#SVD
4
10
69
0
3
13
#JSDXL
は、SDXLに適用されている多くの拡張手法・機能にも対応可能です。
例えば、以下では、JSDXLを用いたLoRAによるドメインチューニングをお試しいただけます。
Colab:

🚀 新リリース 🚀
「Japanese Stable Diffusion XL (JSDXL)」が登場!
✨ 日本特化の商用利用可能なtext-to-imageモデル ✨
🌸 JSDXLは、日本語のプロンプトを英訳したものとは異なり、日本語そのままの理解と日本独自の文化を反映した高品質な画像生成を実現しました。
詳細はこちら💁♀️
3
248
695
0
3
13
DiffFit was applied to DiTs but can be applied to
#stablediffusion
too as a PEFT.
Here's my WIP implementation of DiffFit.
code:
I'm still struggling with good results so I am happy to get feedback!

paper:
problem to solve:
The domain adaption for Large pre-trained DMs is costly in terms of computation and storage.
summary: 👇
1/5
2
0
26
1
3
12
We have released another 2 kinds of powerful Japanese Stable LM (JSLM) under the commercial license 🎉🎉
JSLM 3B-4E1T:
(base)
(instruct)
JSLM Gamma 7B:
(base)
(instruct)

🚀日本語大規模言語モデル「Japanese Stable LM 3B-4E1T」と「Japanese Stable LM Gamma 7B」をリリースしました🎉
約30億と70億のパラメータを持つこれらのモデルは、日本語タスクの性能評価でトップクラスです✨
さらに、Apache 2.0ライセンスで商用利用も可能📜

4
207
657
1
2
12
Maybe I should emphasise what our
#JapaneseStableDiffusion
is good and what is the difference from other fine-tuned models like waifu-diffusion.
1/5

Japanese Stable Diffusion - SD trained on 100M japanese image-text pairs
The model works with prompts in the Japanese language. Requires it's own pipeline
Model:
Colab:

0
5
52
1
3
12
A single-step SDXL is out! SDXL Turbo was trained w/ a new distillation technology called Adversarial Diffusion Distillation.
You can quickly try it on
@clipdropapp
and here's my result😺
clipdrop:
paper:
HF:

Introducing SDXL Turbo: A real-time text-to-image generation model.
SDXL Turbo achieves state-of-the-art performance with a new distillation technology, enabling single-step image generation with unprecedented quality, reducing the required step count from 50 to just one.
The
131
591
3K
0
2
11
本日リリースされたrinnaのinstruction-following fine-tuned model () をChat形式で試せるUIを作りました!
”システム”や”ユーザー”などのpromptを打ち込まず、会話できます!
colab:
HF Spaces:
0
1
11
paper:
problem to solve:
With existing DM-based image translation methods, there is a trade-off between maintaining the spatial layout of the input image and high-quality content.
summary:
1/4

1
3
11
Compared
#stablediffusion
sampling methods (ddim, plms, k_euler, k_euler_ancestral, k_heun, k_dpm_2, k_dpm_2_ancestral, k_lms)
code:
"A beautiful painting of a view of country town surrounded by mountains, ghibli"
#stablediffusion
#AIart
#AiArtwork

1
0
7

空 (sora) means sky in Japanese.

Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
Prompt: “Beautiful, snowy
10K
32K
138K
0
0
7
SVDiffについては、以下のサマリーツイートをご参照ください!
paper:
problem to solve:
Existing domain-tuning methods (eg. DreamBooth (DB)) can lead to overfitting due to finetuning the whole parameters on the small data. In addition, domain-tuning for multiple target concepts is difficult.
summary: 👇
1/4
2
16
63
1
4
7

rinna has released a base Japanese 3.7B GPT-NeoX and a tuned (SFT) model on instruction dataset today. Congrat 🎉
base:
tuned:
1
1
7


Japanese InstructBLIP Alpha is built on top of our powerful JSLM model.
Japanese InstructBLIP Alpha enables not only to generate textual descriptions in Japanese for input images but also to generate answers to questions given images.
2/3


2
1
5
Plus, Japanese InstructBLIP Alpha is capable of recognising proper objects in Japan such as SkyTree🗼
Can't wait to see the applications using our Japanese InstructBLIP Alpha!
3/3

0
1
5

ImageReward, a t2i human reference reward model (RM), is out under Apache2.0.
"ImageReward outperforms existing text-image scoring methods, such as CLIP, Aesthetic, and BLIP, in terms of understanding human preference in text-to-image synthesis"
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
abs:
github:

3
45
227
1
4
6
Compared to LoRA and DB in the same training step, LoRA leaded to underfitting and DB causes overfitting, while SVDiff provides good balanced results.
They also proposed a data augmentation technique called Cut-Mix-Unmix for domain-tuning for multiple concepts.
4/4

2
0
6
Today, I am very proud to release the new SOTA Japanese CLIP "Japanese Stable CLIP" 🥳 👏
This model significantly outperformed the rinna's CLOOB which was SOTA (and I trained too) 🎊 👏
Excited to see how the community uses it!
HF:
Colab: ↓↓
1/2

1
2
6
ちなみに、Japanese Stable VLM、Japanese Stable CLIPの画像ももちろん、
#JSDXL
から生成 🐶
🚀 今週のハイライト: 3つの新AIモデルが登場!
今週はモデルのリリースが続いて追いきれなかったという皆さんへ。
以下のツリーで今週リリースした各モデルを再度ご紹介します!
1
15
43
0
2
5




Although JSD is still not as versatile compared to SD, we hope to communicate to the research community the importance and potential of language-specific model development through JSD.
0
0
5
Also, single image editing is now supported! 📸
left: training image, right: output when "pink" changed to "blue"

1
0
5
Stable Diffusion is a very powerful text-to-image model, not only in terms of quality but also in terms of computational cost.
So, why do we need Japanese-specific Stable Diffusion?
1
0
4
@StabilityAI_JP
Now, you can try Japanese StableLMs with free Colab plan 😄 Check it out!
colab;
0
2
4
From researcher’s view, to make language-specific stable diffusion, fine-tuning is not efficient because the text tokenizer/encoder is English.
So, we had 2 stages overall, inspired by PITI.
3/5
1
0
4
They Proposed SVDiff, a method that performs SVD on the weights of the pre-trained diffusion model and train only the difference part of the singular values. This method is based on previous work applied to GAN (paper: ) and applied to diffusion models.
2/4

1
0
4
"A beautiful painting of a view of country town surrounded by mountains, ghibli" by "k_lms"
#stablediffusion
#AIart
#AiArtwork

0
0
4


先週発売の日経サイエンスの「特集 話すAI 描くAI」にて、昨今話題のLLMや画像生成モデルについて取材を受けました。最近の怒涛のAI進化にキャッチアップできるだけでなく、仕組みを分かりやすく記載頂いております!
日本のAIコミュニティに少しでもお役に立てれば嬉しいです!

📗3月25日発売!
日経サイエンス2023年5月号
🤖特集:話すAI 描くAI
【特別解説:数学の数学「圏論」の世界】
・クール・コンピューター 熱くならない計算機を作る
#科学
#AI

19
192
455
1
1
4

paper:
problem to solve:
One drawback of diffusion models is the slow sampling process but many improved methods have recently been proposed to generate images in fewer steps. However, these methods do not work well in the guidance setting.
summary:
1/3

1
2
4
Another interesting output w/ another famous Japanese word, "idol".
"アイドルの自撮り写真" (which means "idol selfie photo")

0
0
4
paper:
problem to solve:
To further control t2i pre-trained models(PMs) with additional info (e.g. sketch), there are problems of the number of data and computational cost. Plus, fine-tuning could reduce the ability of powerful PMs.
summary:
1/5

1
1
4

This was released a month ago but I noticed that I haven't retweet it!
I was honored that I joined this project as the main AI researcher :)
The short anime is very touching, so please don't miss watching it~

Netflix アニメ・クリエイターズ・ベース×技術開発のrinna株式会社×WIT STUDIOによる共同プロジェクトアニメ『犬と少年』のショートムービー。
人手不足のアニメ業界を補助する実験的な取り組みとして、3分間の映像全カットの背景画に画像生成技術を活用!
2K
3K
12K
0
0
3

Because we want a model to understand our culture, identity, and unique expressions.
For example, one of the famous Japanglish is "salary man" which means a businessman wearing a suit.
This is from
#stabledifussion
w/ "salary man, oil painting"

1
1
3
paper:
problem to solve:
Most SOTA vision-language models are very computationally expensive because large models are pre-trained on large multimodal dataset.
summary:
1/4

1
0
3
また、一枚の画像を部分的に編集するタスクSingle Image Editingを追加しました 📸
左: 元の画像, 右: "ピンク"を"blue"に変えた時の結果

0
1
3

paper:
problem to solve:
Transformer-based multi-modal models such as MAGMA have become increasingly complex, and they lack explainability; Gradient-based interpretation methods consume high GPU memory due to the large number of parameters.
1/3

1
0
3
paper:
problem to solve:
Textual Inversion proceeds in the only one embedding space (P) and can be extended to the multiple embedding spaces (P+)
summary:
1/4

1
1
3
Comparison between sampling methods
"Japanese samurai with sunglasses"
#stablediffusion
#AIart

0
0
3

Our LLMs/VLM remarkably achieve SOTA performance! Ofc, all models are public on HF!
This is only our initial progress and I'm excited to expand its possibilities further!!
All details are written in our blog & paper! Check it out 🐠
2/2
0
0
3
Do you want to use `init_image` in
#stablediffusion
before they release?
Now I implemented k-diffusion samplers in
#stablediffusion
as glid-3-xl.
Here's the code 🎉
code:
prompt: "A ukiyoe of a countryside in Japan" by k_lms sampler

Implemented k-diffusion samplers in glid-3-xl because
#stablediffusion
uses `k_lms` sampler by default.
All k samplers (k_euler, k_euler_ancestral, k_heun, k_dpm_2, k_dpm_2_ancestral, k_lms) are supported.
"A ukiyoe of a countryside in Japan"

1
0
0
1
0
2