
Hila Chefer
@hila_chefer
Followers
2,126
Following
215
Media
58
Statuses
393
PhD candidate @TelAvivUni , student researcher @GoogleAI , interested in Deep Learning, Computer Vision, explainable AI
Joined December 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
İran
• 516637 Tweets
Argentina
• 404124 Tweets
Kyle
• 266250 Tweets
Shapiro
• 220459 Tweets
Sunderland
• 141482 Tweets
Enrique Márquez
• 114558 Tweets
オフサイド
• 104474 Tweets
Francia
• 95175 Tweets
スペイン
• 94450 Tweets
#ErdoğanınYanındayız
• 80012 Tweets
Emily
• 68747 Tweets
Mascherano
• 65103 Tweets
İmamoğlu
• 60623 Tweets
Julian
• 60027 Tweets
Ron Paul
• 47334 Tweets
Arabia
• 43503 Tweets
#FRAARG
• 38019 Tweets
Angola
• 29999 Tweets
Game Informer
• 29115 Tweets
Fresh News for $XRP Holders
• 27137 Tweets
Hepimiz Erdoğan'ız
• 25090 Tweets
Joshua Cheptegei
• 20043 Tweets
BAUTISTA EN EL GRAN REX
• 19375 Tweets
準々決勝進出
• 18919 Tweets
Equi
• 16549 Tweets
Zenón
• 16470 Tweets
Mateta
• 16351 Tweets
Simeone
• 16263 Tweets
#バレーボール男子
• 15682 Tweets
Gabriel Sara
• 14118 Tweets
Almada
• 13455 Tweets
Otamendi
• 13056 Tweets
FGOフェス
• 12480 Tweets
Grant Fisher
• 10862 Tweets
Echeverri
• 10664 Tweets
Harmeet
• 10377 Tweets
منتخب مصر
• 10147 Tweets




















Pinned Tweet

TLDR: Meet ✨Lumiere✨ our new text-to-video model from
@GoogleAI
!
Lumiere is designed to create entire clips in just one go!
Seamlessly opening up possibilities for many applications:
Image-to-video 🖼️ Stylized generation 🖌️ Video editing 🪩 and beyond.
See 🧵👇
78
207
947
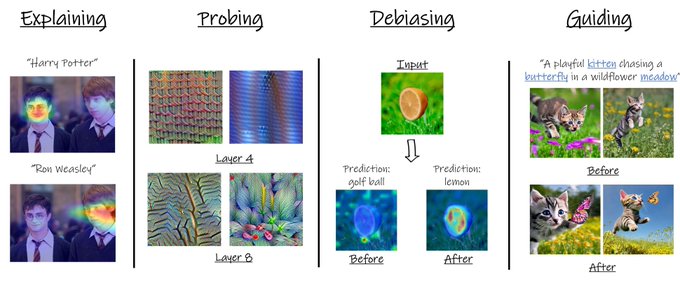
[1/n] Can explainability improve model accuracy? Our latest work shows the answer is yes!
We noticed that ViTs suffer from salient issues- their output is often based on supportive signals (background) rather than the actual object

11
86
446
Last Sunday, I got to present a tutorial for the ✨first time✨
Alongside the best partner
@RisingSayak
🤩
📢 Today, we are happy to release **all** materials from our
#CVPR2023
@CVPR
tutorial- the slides, code, demos and recordings🚀
👀 recording ⬇️
1/


Starting today from 9:00 AM Vancouver time 🔥
If you're attending
#CVPR2023
(virtually or physically), please do drop by! If you're attending in person, the location is **West 211**.
@hila_chefer
and I have wrapped our preps.

2
35
173
6
73
325
Text-to-image models revolutionized computer vision, but what do they learn about the world?🤔
We present Conceptor 🧐 a method to inspect the inner representation of a concept by decomposing it into a set of interpretable tokens, which reveals surprising semantic structures🧵
7
58
285
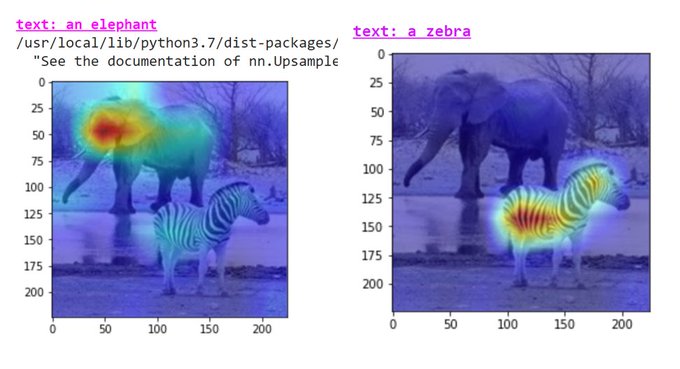
Ever wonder which text tokens CLIP uses to match a text and an image?
Using our multi-modal explainability method, your wondering days are over!
Code:
Notebook:


6
23
154
[1/n]
@eccvconf
#ECCV2022
paper thread!
1. Image-based CLIP-Guided Essence Transfer (TargetCLIP)- we extract the essence of a target while preserving realism and source identity.
2. No Token Left Behind- we use explainability to stabilize the unreliable CLIP similarity scores.

Image-Based CLIP-Guided Essence Transfer
abs:
github:
new method creates a blending operator that is optimized to be simultaneously additive in both latent spaces

3
55
258
2
17
125
Excited to share that we will be presenting our work in person at
#NeurIPS2022
@NeurIPSConf
!
Interested in leveraging explainability to improve accuracy and robustness? Come check out our poster and chat 🥳
Code:
@Gradio
demo:

[1/n] Can explainability improve model accuracy? Our latest work shows the answer is yes!
We noticed that ViTs suffer from salient issues- their output is often based on supportive signals (background) rather than the actual object
11
86
446
4
22
127
Interested in understanding how diffusion models produce images from simple text prompts? 🧐
Or how Transformers leverage attention to make predictions? 🤔
Join my talk at
@forai_ml
to hear about my latest research! 🤩
Looking forward to it ✨

Our open science community is excited to welcome
@hila_chefer
to present their work on explainable vision transformer networks, with discussion around interpreting generative models.
Join our community to attend:
Thanks to
@nahidalam
for hosting!

3
6
29
1
16
87
2024 is the year of text-to-video models 🎥
Join me tomorrow as we dive into ✨Lumiere✨our T2V model from
@GoogleAI
!
We'll discuss Lumiere's architecture, applications, and more🤩
⏰ tomorrow at 20:00 IDT (10:00 PDT)
🚀 sign up now:
Excited to share insights about our text-to-video model✨Lumiere✨
Join us at the Vision-Language Club meetup 📅
We'll explore Lumiere's architecture, applications, and results 💡
Big thanks to
@dana_arad4
for the invite!
Secure your spot by signing up👇
6
14
77
3
12
83
Excited to share insights about our text-to-video model✨Lumiere✨
Join us at the Vision-Language Club meetup 📅
We'll explore Lumiere's architecture, applications, and results 💡
Big thanks to
@dana_arad4
for the invite!
Secure your spot by signing up👇
6
14
77
Transformer Interpretability Beyond Attention Visualization
pdf:
abs:
github:
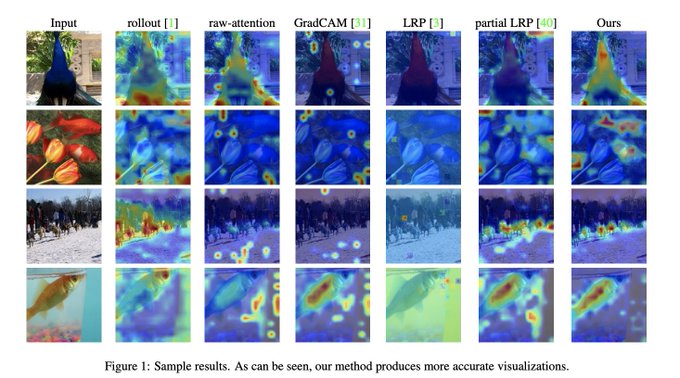
1
17
112
2
9
68
Very excited to share our latest work-
Image-Based CLIP-Guided Essence Transfer (paper will reach arxiv soon)!
We develop a method to transfer the semantic essence from a target image to any source image.
code:
With
@BenaimSagie
, Roni Paiss, and Lior Wolf


3
6
67
Our paper finally hit arxiv! Check it out 🥳
With
@BenaimSagie
, Roni Paiss, and Lior Wolf
Image-Based CLIP-Guided Essence Transfer
abs:
github:
new method creates a blending operator that is optimized to be simultaneously additive in both latent spaces
3
55
258
1
7
63
Stylized generation 🖌️ is one of my favorite features!
We show that Lumiere can stylize motion🏃♀️ by the appearance of a single image 🖼️🎨
using various cool styles from StyleDrop (by Kihyuk Sohn,
@natanielruizg
et al.).
5
4
62
So excited to share our new work!
- we expand to explaining *any* type of Transformer (also co-attention, encoder-decoder).
- we remove the complex LRP.
- we explain VQA- models actually understand the text + image!
- we use explainability to generate segmentation from DETR.
Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers
pdf:
abs:
github:
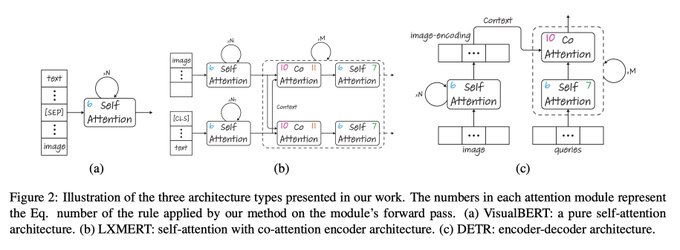

2
18
64
1
13
62
For more details and many more cool results, check out our website!

6
5
60
💡Lumiere's key observation-
Instead of generating short videos and temporally upsampling them, we perform joint spatial and *temporal* downsampling-- increasing both length and quality of the generated videos
2
2
59
Really excited to finally share our work! Attend-and-Excite has been accepted to
#SIGGRAPH2023
🥳
w/ the amazing
@yuvalalaluf
@YVinker
@DanielCohenOr1
and Lior Wolf
Text-to-image models are amazingly expressive, but have you tried generating an image of, say, a cat and a dog?

Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
abs:
project page:
github:

3
75
341
2
18
57
Lumiere can also edit videos based on text with and without an input mask 🪩
2
2
49
I have been extremely fortunate to work on this with the most talented team
@omerbartal
@omer_tov
Charles Herrmann
@Roni_Paiss
@ShiranZada
@arielephrat
@JunhwaHur
Yuanzhen Li, Tomer Michaeli
@oliver_wang2
@DeqingSun
@talidekel
and our great team leader ✨
@InbarMosseri
✨
2
1
42
Thanks for inviting me
@twelve_labs
! 🤩🥳
Classifier interpretability is fascinating and important, but it’s about time we start understanding generative models too 🧑🏼🎨🚨
Interested in taking a look under the hood of diffusion models? 🧐
Sign up and join us tomorrow! 👇

@evonotivo
@activeloopai
@hila_chefer
will present her research "The Hidden Language of Diffusion Models", which proposes a novel interpretability method for text-to-image diffusion models 🎨
1
3
8
0
10
36
Thanks for sharing our work
@ak92501
!
Check out the thread with more details on the paper 👇
@Gradio
demo coming soon!
[1/n] Can explainability improve model accuracy? Our latest work shows the answer is yes!
We noticed that ViTs suffer from salient issues- their output is often based on supportive signals (background) rather than the actual object
11
86
446
0
9
34
Check out our new
@Gradio
demo ()-
Even for out of domain inputs such as images generated by DALL-E 2 or animations, our method corrects the original model to produce a plausible prediction! (code: )
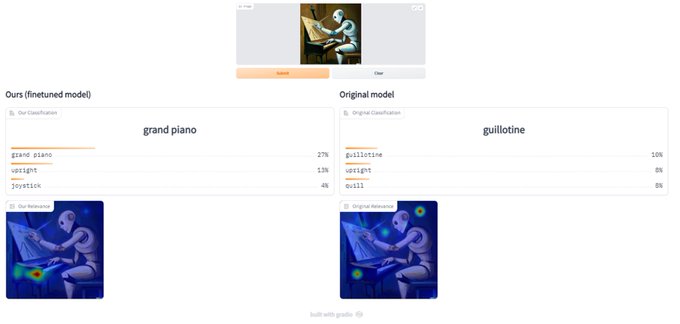
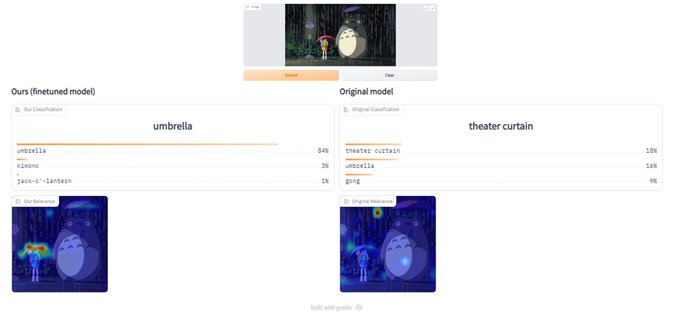
Optimizing Relevance Maps of Vision Transformers Improves Robustness
abs:
github:
show that by finetuning the explainability maps of ViTs, a significant increase in robustness can be achieved

0
23
98
0
10
33
Very happy to announce that our paper got accepted as to
#iccv2021
as oral!!!
Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers
pdf:
abs:
github:
2
18
64
1
5
34
I had the pleasure of speaking at
@Columbia
’s vision seminar, kindly hosted by
@SongShuran
,
@sy_gadre
.
My talk focused on using Transformer explainability algorithms to improve performance of downstream tasks (e.g. image editing).
Check it out :)

0
2
33
Attention in now everywhere!
Interested in understanding attention and how to use it for downstream tasks?
Come check out our tutorial at
@CVPR
#CVPR2023
with the one and only
@RisingSayak
!
Super excited to see all of you there and discuss the future of attention in vision 🥳
Incredibly excited to announce our
@CVPR
tutorial w/ the amazing
@hila_chefer
!
"All Things ViTs: Understanding and Interpreting Attention in Vision"
Come for cool visualizations, exclusive insights, & interesting approaches ❤️
Catch the details here ⬇️
4
77
367
0
5
26
Amazing accomplishment!
@YVinker
is on a roll with 2 best papers in a row 😱
Congrats 🎉🥳

I'm super excited to share that our paper Word-as-Image received an honorable mention award this year at
#SIGGRAPH2023
! 👩🎨
This is such a HUGE honor for me and the team!
Thanks for the recognition, looking forward to seeing you in LA soon!🤩
13
5
90
2
0
23
Check out our project website for more information:
A special thanks to the amazing team from Hugging Face
@_akhaliq
@hysts12321
@YiYiMarz
@RisingSayak
for creating an awesome demo:
and integrating our code into diffusers!

2
6
21
@ak92501
Thanks!
Another example with targets that weren't inverted (directions are initialized randomly):

2
0
22
[3] Evidently, the model represents dual-meaning concepts by interpolating both meanings, even if only one object is generated.
For example, a crane borrows its structure from the bird 🦤. When removing the token “stork” from the decomposition the structure changes significantly

3
1
19
Thrilled to host
@MokadyRon
in our upcoming
#CVPR2023
tutorial! 🤩
Ron’s works on leveraging attention for image editing are truly inspiring, and demonstrate how powerful the attention mechanism can be! ✨
For more details, check out:

Thrilled to share that I'll be speaking (remotely) at the amazing
#CVPR2023
tutorial on "Attention"! 🎉😃 by
@hila_chefer
@RisingSayak
Join me as I dive into the importance of attention for diffusion-based image editing 👼.

0
3
31
0
2
19
2/2 papers accepted to
#ECCV2022
! Works were done with
@BenaimSagie
, Roni Paiss, and Lior Wolf.
Details to come soon 🥳
See you in Tel Aviv! 🎉

1
0
18
@ak92501
We added support for CLIP on our repo!
Check out our repo and colab notebook for more examples and details :)
2
1
17
[2] Conceptor also extracts the tokens from the decomposition that correspond to a specific image!
We find that Stable Diffusion links concepts based on non-trivial semantic features such as texture and shape, e.g., sweet peppers are generated as peppers🌶️ shaped like fingers 💅

1
0
16
Check out our colab notebook where you can experiment with our fine-tuned models and compare them to the original ones:

1
0
13
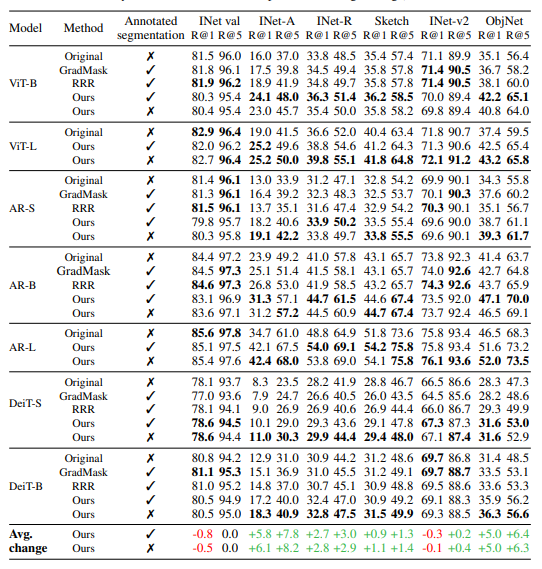
We only use 3 labeled examples for 500 classes, and achieve a large increase in robustness (ImageNet-A, R, ObjectNet)
1
0
13
Super excited to be a part of the first
@huggingface
event in Tel Aviv 🥳alongside such incredible speakers 🤩
Thanks to the amazing
@linoy_tsaban
for making it happen 🌸

LETS GO🤩
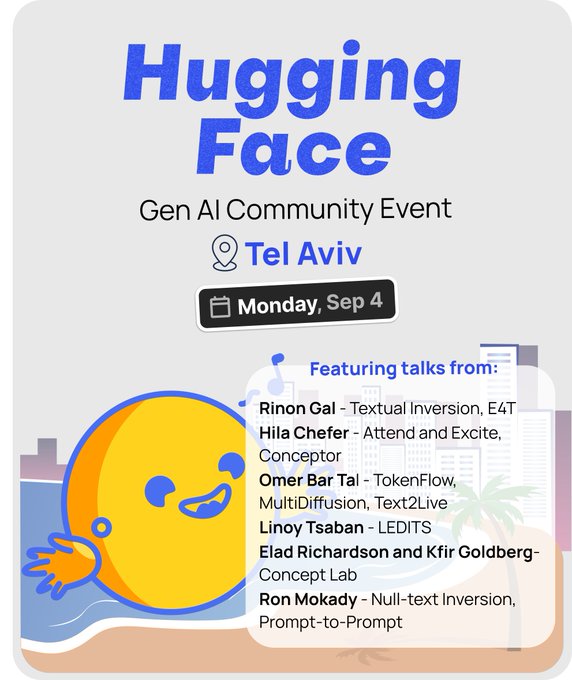
(First!) Hugging Face meetup in Tel Aviv, September 4th🤗
Featuring an amazing group of speakers🔥:
@hila_chefer
@MokadyRon
@RinonGal
@EladRichardson
@omerbartal
You have a cool demo you’d like to showcase?
Demo registration also is open! 🚀:
4
8
57
0
0
14
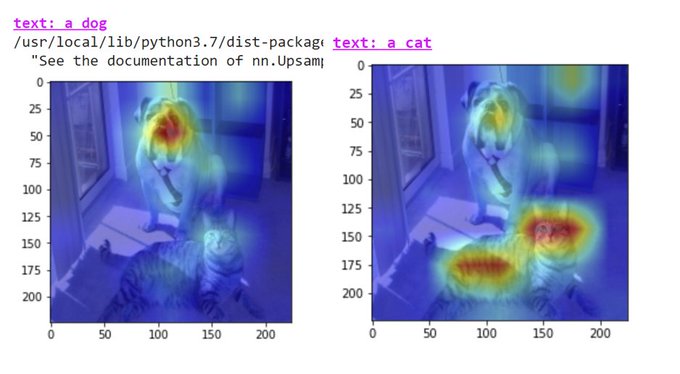
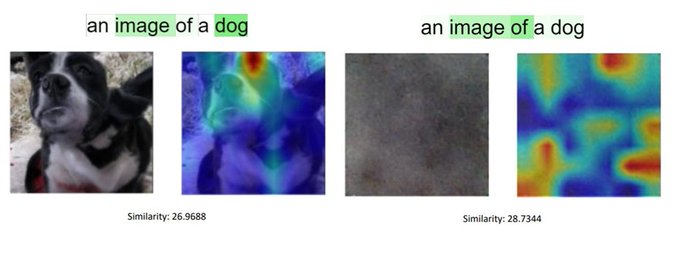
[7/n] No Token Left Behind-
RT
@_akhaliq
:
We find that CLIP similarity scores can be unreliable since they rely on a small subset of the text tokens. E.g., the noisy image scores higher due to the influence of the words "image of" on the similarity score.
No Token Left Behind: Explainability-Aided Image Classification and Generation
abs:

0
26
102
1
2
14
@eccvconf
#ECCV2022
is right around the corner!🥳
@BenaimSagie
and I would be happy to meet! feel free to DM and let's grab coffee 🙂
Also, come check out our posters (at Hall B)🤓
TargetCLIP - Tuesday 11:00-13:30
No token left behind with
@Roni_Paiss
- Thursday 15:30-17:30
1
1
13
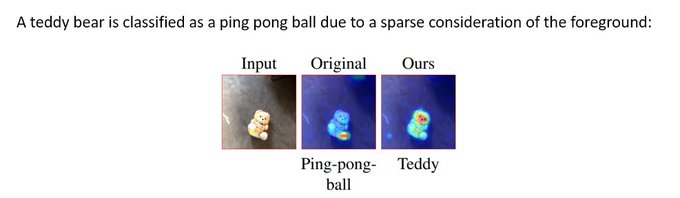
In this work, we show that one can *directly optimize the explanations*- i.e. use a loss on the explainability signal to ensure that the classification is based on the *right reasons*- the foreground and not the background.
1
0
12
So excited to be able to share our work!
Hope you’ll find it useful :)
With
@shiretzet
and Lior Wolf.

Transformer Interpretability Beyond Attention Visualization
by Hila Chefer et al. including
@shiretzet
#TransformationNetwork
#ComputerVision
0
13
30
1
4
13
@WilliamLamkin
@GoogleAI
@huggingface
Thanks
@WilliamLamkin
!
I think you broke a world record in paper-reading speed!
Not sure about a demo ☹️ but I'll take this opportunity to highlight that this was a joint effort by many great people, e.g., this awesome investigation of temporal consistency was done by
@ZadaShiran

1
0
13
Amazing results!
Volumetric Disentanglement for 3D Scene Manipulation
abs:
project page:
0
32
149
0
1
11
@ak92501
Also, check out our colab notebook- where you can edit your own image with one of our directions:

1
0
11
[2/n] This phenomenon results in poor generalization to domain shifts- a bus is classified as a snowplow due to the snow, a lemon is classified as a golf ball due to the grass, a forklift is classified as a garbage-truck due to the garbage

1
0
9

0
0
10
[4] Conceptor also enables fine-grained semantic editing by manipulating the coefficients of tokens in the decomposition. For example, we can make a sculpture more abstract 👩🎨.
This manipulation also allows us to visualize the impact of each token in the learned decomposition 🖼️

1
0
10
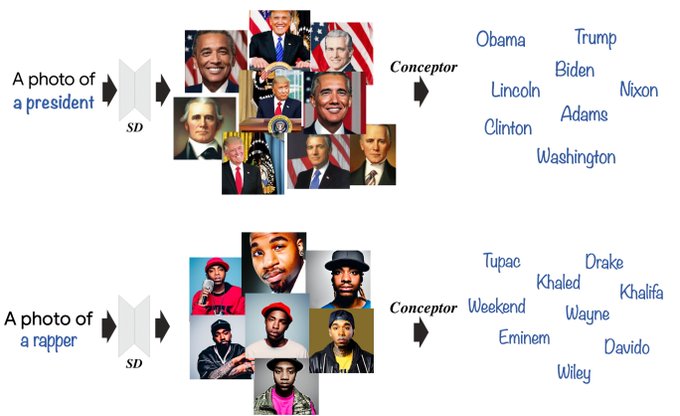
[1] We observe that some concepts such as “a president” and “a rapper” are represented as simple interpolations of famous personalities (e.g., “Obama”, and “Biden” for presidents, “Tupac”, and “Drake” for rappers), suggesting that the model tends to learn from examples💡
1
2
9
@natanielruizg
It is also worth mentioning that the method for the stylized generation is based on weight interpolation between the original and fine-tuned text-to-image weights.
This is inspired by a great work on GANs by
@Buntworthy
and
@Norod78
!

0
1
8

@JacobGildenblat
[1/n] Thanks
@JacobGildenblat
! That's a great question, of course, this thread is a TLDR for the work, but I'll try to answer it in multiple parts.
Part 1: the method does not entirely eliminate the use of the background (it is, as you said, useful) see example below

1
0
8
The text explainability scores can also explain cases where the similarity scores are unstable, in the below example, the noisy image scores higher than a dog for the text "an image of a dog" due to the influence of the words "image of" on the similarity score.

0
0
7
Amazing work by the authors! Can’t wait to try it out!
Designing an Encoder for Fast Personalization of Text-to-Image Models
TL;DR: use an encoder to personalize a text-to-image model to new concepts with a single image and 5-15 tuning steps
abs:
project page:
10
140
665
0
0
7
[5] The obtained decompositions capture biases that are not easily detectable from the generated images, such as “millennials” for the concept “drinking” 🍺.

1
0
8
It turns out that CLIP uses a sparse subset of the input tokens to determine the similarity score:
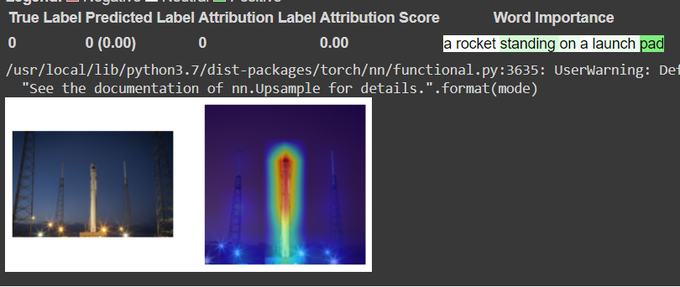
0
0
7
Thanks to my great partner
@RisingSayak
for the incredible work on this despite the time differences and visa issues ❤️
And to our wonderful guest speaker
@MokadyRon
for a fascinating and inspiring talk! 🥳
0
0
7
@giffmana
@chriswolfvision
Or maybe it could mean that the paper assignment does not always align with the reviewers’ expertise?
I have been assigned 2/6 papers that are fairly far from my area of research and it was very hard to provide a high quality review.
2
0
5
@DigThatData
Very interesting work! Thanks for sharing! Seems to correspond nicely to the results we found when decomposing concepts (“president” is a linear combination of presidents, “rapper” is a linear combination of rappers, and even “dog” is a linear combination of dog breeds)
[1] We observe that some concepts such as “a president” and “a rapper” are represented as simple interpolations of famous personalities (e.g., “Obama”, and “Biden” for presidents, “Tupac”, and “Drake” for rappers), suggesting that the model tends to learn from examples💡
1
2
9
0
0
5
@Gradio
@omerbartal
@omer_tov
@Roni_Paiss
@ShiranZada
@arielephrat
@JunhwaHur
@oliver_wang2
@DeqingSun
@talidekel
@InbarMosseri
Thanks for sharing our work! ❤️
Shout out to
@Roni_Paiss
who created both of these incredible demos! 😎
0
1
6
0
1
6
Amazing opportunity to work with
@MokadyRon
🤩
TL;DR: We are looking for Researchers 🌟
We at
@bria_ai_
, having recently secured funding, are set to train 3 foundational models this year (One of them is T2I, with more details to come)
If you wish to train large models 💪but in a startup environment 🚀 - please DM
3
2
26
0
0
6
We use explainability for DETR and generate segmentation masks from a model only trained for object detection!
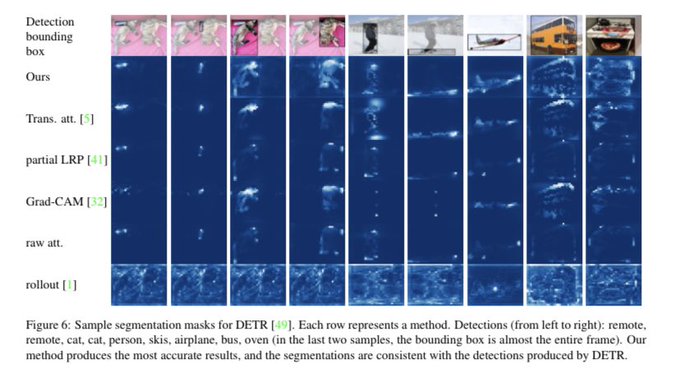
1
0
6
@eccvconf
[3/n] TargetCLIP -
We demonstrate that using CLIP guidance and the powerful StyleGAN, we can extract an essence vector- a vector of semantic properties that correspond to the “signature characteristics” that are also identified by humans as related to the specific target.

2
0
6
@ak92501
Our notebook is expanding with more interesting targets that weren't inverted :)
Doc Brown (Back to the Future), Morgan Freeman, Beyonce, and Ariel (The Little Mermaid)
ideas for additional targets are always welcome :)


0
1
5
TLDR: Meet ✨Lumiere✨ our new text-to-video model from
@GoogleAI
!
Lumiere is designed to create entire clips in just one go!
Seamlessly opening up possibilities for many applications:
Image-to-video 🖼️ Stylized generation 🖌️ Video editing 🪩 and beyond.
See 🧵👇
78
207
947
0
0
4
[10/n] No Token Left Behind-
Additionally, we demonstrate that using the image explainability heatmaps, it is possible to generate an image from a given layout of bounding boxes!
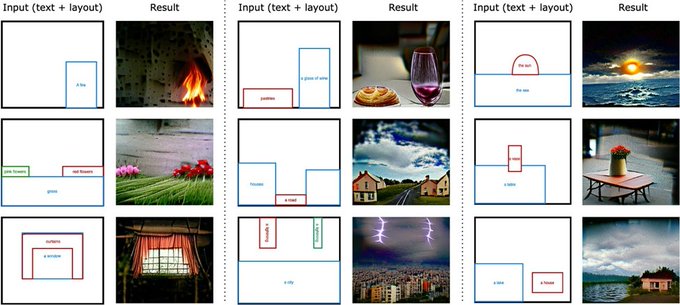
1
0
5
To mitigate this, we introduce Generative Semantic Nursing (GSN). We implement GSN using an attention-based formulation -- Attend and Excite -- to refine SD's attention to attend to ALL the subject tokens from the input prompt.
This is done ON the fly, so NO retraining!
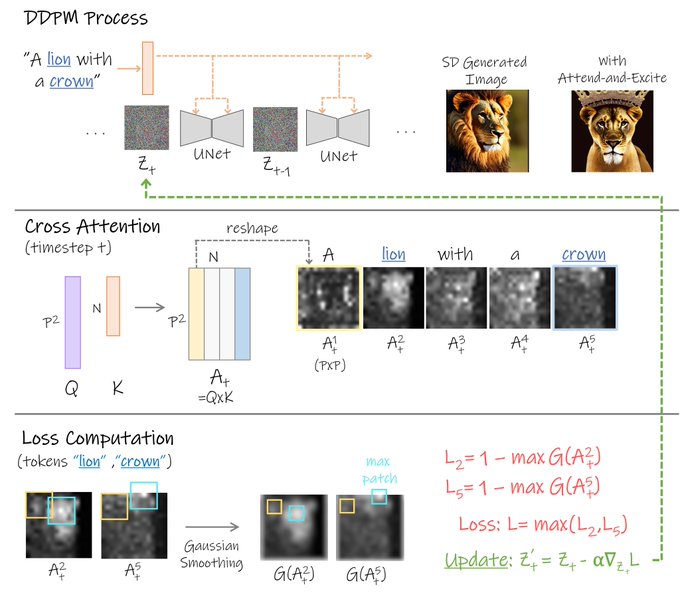
2
1
5

@giffmana
@dahou_yasser
@rasbt
@CSProfKGD
@shir_gur
Thanks for the reference
@giffmana
! Your works on vision transformers are so inspiring, and paved the path for us and many others :)
To visualize self-attention based models see:
For cross-attention, vision-language models see:
0
0
5
@giffmana
Cool work!
We have a
#NeurIPS2022
paper that deals with spurious correlations too:
We apply a loss to restrict the explainability maps to focus on the correct parts of the image, which improves robustness significantly with a short fine-tuning process :)

[1/n] Can explainability improve model accuracy? Our latest work shows the answer is yes!
We noticed that ViTs suffer from salient issues- their output is often based on supportive signals (background) rather than the actual object
11
86
446
2
0
5
@nickfloats
Thanks for sharing
@nickfloats
! Motion stylization is one of my favorite findings of our work! 🙏
Linking here the full thread with more details 🤩
TLDR: Meet ✨Lumiere✨ our new text-to-video model from
@GoogleAI
!
Lumiere is designed to create entire clips in just one go!
Seamlessly opening up possibilities for many applications:
Image-to-video 🖼️ Stylized generation 🖌️ Video editing 🪩 and beyond.
See 🧵👇
78
207
947
1
1
5
@eccvconf
[2/n] TargetCLIP-
Code:
Humans identify characteristics independently from the target identity. For example, the joker is identified by the signature hair color, face, and makeup regardless of the identity of the actor.

1
0
5
Ever wonder if a model simply guessed an answer to a visual question? We show that models can connect the text to the image and answer based on joint information!



1
0
4
[8/n] No Token Left Behind-
We demonstrate that explainability can be used as an additional loss to penalize similarity scores that are not based on the semantic text tokens.

1
0
4
[9/n] No Token Left Behind-
Using this additional explainability loss, we demonstrate that downstream tasks such as image classification and image generation and editing that use CLIP guidance can be significantly improved.

1
0
4
@yuvalalaluf
@YVinker
@DanielCohenOr1
We find that Stable Diffusion suffers from catastrophic neglect, meaning it simply ignores entire part of the prompt


1
1
4
@JacobGildenblat
Part 2: Rephrasing from the ImageNet-A paper: "image classification datasets contain `spurious cues' or `shortcuts'. For instance, cows tend to co-occur with green pastures... models may predict `cow', using primarily the green pasture background cue."

1
0
4
[4/n] TargetCLIP -
The extracted essence vectors are global and can be applied to any source while maintaining realism, and the original identity of the source.

1
0
4
All examples are available in our colab notebook:
You can also very easily add your own images and questions and get answers + explanations!

1
1
4
A fantastic post about our recent
#cvpr2021
paper!
Thanks
@Analyticsindiam
, you've done an amazing job summarizing the main concepts of the paper!
With
@shir_gur
and Lior Wolf.

0
2
4
@baifeng_shi
Cool work! Congrats! 🎉
We actually have a similar work published at NeurIPS’22 that shows that by a simple optimization process on the attention maps, a significant improvement to robustness can be achieved:
3
1
4
@pbaylies
@danielrussruss
Thanks for sharing this cool application of our work!
I definitely noticed this too. Using 16 resulted in more fragmented heatmaps, and more artifacts.
My best guess is that this is a training issue since I didn’t notice this issue working with ViT-B/16 explainability on imagenet
1
0
3
1
0
3
This investigation of dual-meaning concepts was inspired by a great work by
@RoyiRassin
et al.
Our findings show that their conclusions generalize even if only one object is generated in the image 💡
1
0
3
Amazing results!
CLIPascene: Scene Sketching with Different Types and Levels of Abstraction
abs:
project page:
2
56
272
0
0
3
[5/n] TargetCLIP -
As an alternative to long optimization, we show that one can also fine-tune an inversion encoder to output the essence vector of a target, allowing for instant extraction of the essence for each target!

1
0
3
Our method is able to transfer semantics from out of domain images


1
0
3



Super interesting observations by
@MokadyRon
! 🚀
🔬Exploring Alignment in Diffusion Models - a 🧵
TL;DR: Diffusion models trained on *different datasets* can surprisingly generate similar images when fed with the same noise 🤯
[1/N]


33
112
760
1
0
3
@JacobGildenblat
We attempt to solve the absolute reliance on shortcuts, and instead provide a more object-centric output. In fact, we observed that as the model obtains higher accuracy the salient issues get worse... (below: ViT Large heatmap that is unrelated to the object)

1
0
3
@ai_for_humans
@JacobGildenblat
@ai_for_humans
I think the distinction is that the background can be beneficial as a supportive cue to the foreground (e.g. a water snake is usually inside the water), when the prediction is mostly based on the background it is overfitting.
2
0
3