

Jialu Li
@JialuLi96
Followers
1,266
Following
586
Media
43
Statuses
279
CS PhD student at @unc @unccs @uncnlp ; Previous @Cornell_CS ; Past intern @Amazon @Apple @Google . Working on VLN, image generation, multi-modal LLM.
Chapel Hill, NC
Joined April 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
McDonald
• 1205536 Tweets
الهلال
• 689651 Tweets
سالم
• 152360 Tweets
Liz Cheney
• 92265 Tweets
Neymar
• 92110 Tweets
علي العين
• 87268 Tweets
AFIP
• 54843 Tweets
نيمار
• 42163 Tweets
البليهي
• 35891 Tweets
#الاهلي_الريان
• 31392 Tweets
Paul Di'Anno
• 28411 Tweets
curitiba
• 27282 Tweets
زعيم اسيا
• 26988 Tweets
Iron Maiden
• 26100 Tweets
Chris Kaba
• 24466 Tweets
كوليبالي
• 24293 Tweets
جيسوس
• 22753 Tweets
سفيان رحيمي
• 15588 Tweets
Samantha Irvin
• 15465 Tweets
Simone
• 13830 Tweets
سافيتش
• 12708 Tweets
Yulia
• 12192 Tweets
علي الفوز
• 11857 Tweets
الشوط الاول
• 11394 Tweets
الاتحاد الاسيوي
• 10246 Tweets



















Pinned Tweet

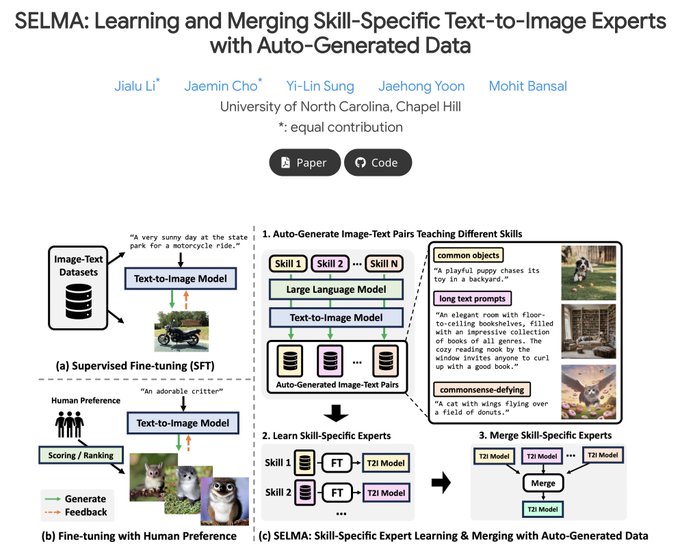
Can we teach multiple skills to a text-to-image (T2I) model (w/o expensive annotations), while minimizing knowledge conflicts between skills? 🤔
👉SELMA improves T2I models by fine-tuning on automatically generated multi-skill image-text datasets, with skill-specific LoRA expert
4
41
110
🚨Excited to share: “𝗣𝗮𝗻𝗼𝗚𝗲𝗻: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation”!🚨
PanoGen creates diverse 360-degree panorama via recursive outpainting, achieving SotA on R2R, R4R, CVDN.
@mohitban47
@uncnlp
🧵
1
37
95
Hi
#CVPR2023
, sadly I wasn't able to come to
@CVPR
in-person due to visa issue 😭, but I'm excited to present our work "Improving VLN by Generating Future-View Image Semantics" remotely. Welcome to our posterboard
#245
Jun21 10:30-12pm PT!
Talk recording:
Excited to share my
#CVPR2023
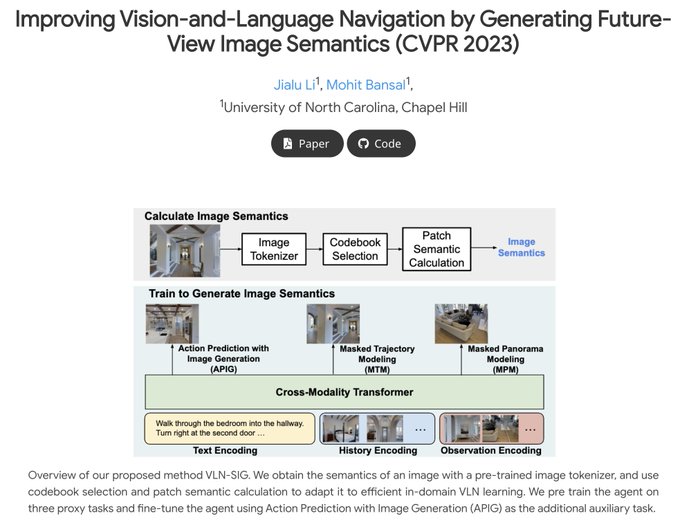
paper: “Improving Vision-and-Language Navigation by Generating Future-View Image Semantics”!
We equip the agent with ability to generate the semantics of future views to aid action selection in navigation.
w/
@mohitban47
🧵
2
21
68
3
18
84
🎉Excited to share my new
#AAAI2024
work “VLN-VIDEO: Utilizing Driving Videos for Outdoor Vision-and-Language Navigation”!
Diverse outdoor envs in videos, w/ generated ins+actions w/ image rotation similarity -> SotA outdoor VLN
@AishwaryaPadma4
@gauravsukhatme
@mohitban47
🧵

1
23
73
Excited to share my
#CVPR2022
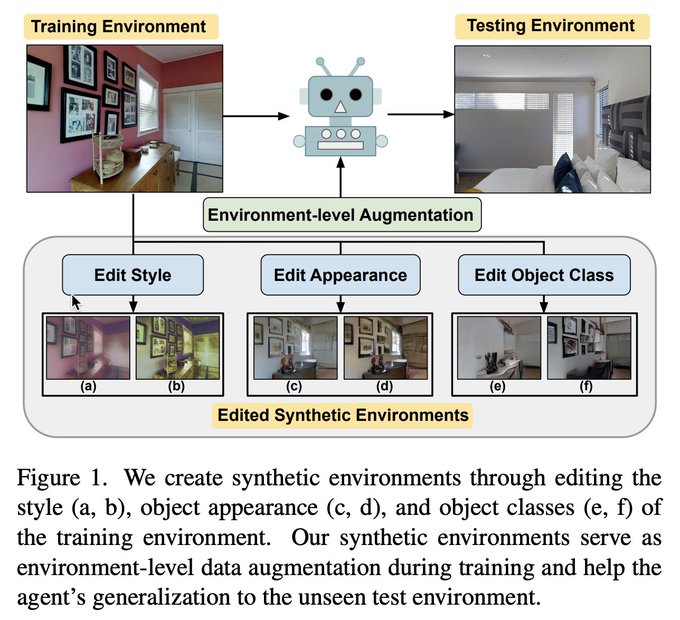
paper: “EnvEdit: Environment Editing for Vision-and-Language Navigation”!
We introduce sota VLN env-augmentation based on style transfer, object class, appearance editing for better generalization
w/
@HaoTan5
@mohitban47
🧵
3
26
72
Excited to share my
#CVPR2023
paper: “Improving Vision-and-Language Navigation by Generating Future-View Image Semantics”!
We equip the agent with ability to generate the semantics of future views to aid action selection in navigation.
w/
@mohitban47
🧵
2
21
68
🎉Excited to share that 𝗣𝗮𝗻𝗼𝗚𝗲𝗻 has been accepted to
#NeurIPS2023
! We create diverse panorama environments for VLN via recursive image outpainting, improving SotA agents on R2R, R4R, CVDN unseen envs. Looking fwd to meeting you all in New Orleans!
cc
@mohitban47
@uncnlp
🚨Excited to share: “𝗣𝗮𝗻𝗼𝗚𝗲𝗻: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation”!🚨
PanoGen creates diverse 360-degree panorama via recursive outpainting, achieving SotA on R2R, R4R, CVDN.
@mohitban47
@uncnlp
🧵
1
37
95
0
14
55
Happy to share my
#NAACL2022
findings paper: “CLEAR: Improving Vision-Language Navigation with Cross-Lingual, Environment-Agnostic Representations”!
We use connection btw same object in diff env+lang for generalizable multiling VLN
@haotan5
@mohitban47
🧵


CLEAR: Improving Vision-Language Navigation with Cross-Lingual, Environment-Agnostic Representations
abs:
code:
Cross-lingual & environment-agnostic representations for better instruction-path grounding and generalization in VLN

0
8
50
1
19
54
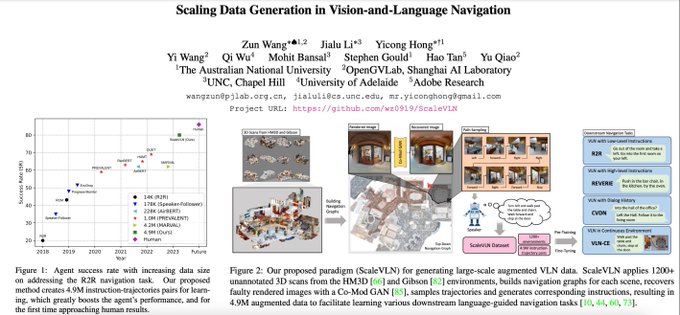
Check out our new
#ICCV2023
VLN paper, that I co-led with Zun and Yicong! By scaling to 4.7M generated data, we achieve sota on multiple VLN datasets (R2R, CVDN, REVERIE, R2R-CE) & reduce long-lasting generalization gap btw seen & unseen envs to <1%, close to human performance!😀

Excited to share our new
#ICCV2023
paper: “Scaling Data Generation in Vision-and-Language Navigation”!
We reduce the long-lasting generalization gap between navigating in seen & unseen scenes to < 1%, & approaching human performance for 1st time! 🥳
🧵
3
15
60
0
15
46
Thanks so much for sharing our work!🥰


2
4
45
Our ScaleVLN paper was selected as ORAL at
#ICCV2023
!🥳
We scale VLN data to 4.7M high-quality data, w/ better graph connectivity & achieve near-human SotA generalization! Meet me (zoom) &
@ZunWang919
@ poster session Oct5 2:30-4:30 & oral session 4:30-6
Excited to share our new
#ICCV2023
paper: “Scaling Data Generation in Vision-and-Language Navigation”!
We reduce the long-lasting generalization gap between navigating in seen & unseen scenes to < 1%, & approaching human performance for 1st time! 🥳
🧵
3
15
60
2
13
39
Check out our
#NAACL2021
work😃(today 11:40-13:00 PDT in session3D) --> “Improving Cross-Modal Alignment in Vision Language Navigation via Syntactic Information” with
@HaoTan5
@mohitban47
(
@uncnlp
)!
Paper:
Code:
1/n




1
14
36
I'm excited to present our work in my first in-person
@CVPR
--> EnvEdit, that introduces sota VLN env-augmentation based on style transfer, object class, appearance editing for better generalization.
Our poster id 204b in
#CVPR2022
Session3.2 Jun23 2:30-5pm
@HaoTan5
@mohitban47
Excited to share my
#CVPR2022
paper: “EnvEdit: Environment Editing for Vision-and-Language Navigation”!
We introduce sota VLN env-augmentation based on style transfer, object class, appearance editing for better generalization
w/
@HaoTan5
@mohitban47
🧵
3
26
72
0
8
29
I'll be at
#NeurIPS2023
from Mon-Fri😀. Happy to talk about VLN, image generation, or anything else.
On Wed (5 - 7pm CST), I'll present PanoGen--creating diverse 360-degree panoramic environment via recursive outpainting for VLN.
🚨Excited to share: “𝗣𝗮𝗻𝗼𝗚𝗲𝗻: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation”!🚨
PanoGen creates diverse 360-degree panorama via recursive outpainting, achieving SotA on R2R, R4R, CVDN.
@mohitban47
@uncnlp
🧵
1
37
95
0
9
26

Thanks so much for your advisory and encourage along the way! No way I could be able to accomplish this research without your and claire’s help!

Proud moment when the student you advised gets her first main conference paper
@emnlp2020
. Congrats
@JialuLi96
! You will do great at
@uncnlp
!
3
2
83
1
1
8
@CVPR
(Thanks to Jaemin
@jmin__cho
and Abhay
@AbhayZala7
for helping setting up my poster and helping me present remotely😀)
cc.
@mohitban47
@uncnlp
@unccs
0
0
7
On both Room-to-Room (English) & RxR (Eng, Hindi, Telugu) datasets, our syntax-aware agent improves the baseline EnvDrop agent in val-unseen environments in all metrics (by using structured syntax info, we are able to avoid word-level shallow overfitting & generalize better)
4/n

1
3
5
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
(c) Given the image-text pairs, first we independently train multiple skill-specific T2I LoRA expert models specialized in different skills.
(d) Then, we merge the LoRA expert parameters to build a joint multi-skill T2I model while mitigating the knowledge conflict from different

1
0
4
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
We show qualitative examples from DSG test prompts requiring different skills. SELMA helps improve SDXL in various skills, including counting, text rendering, spatial relationships, and attribute binding.

1
0
3
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
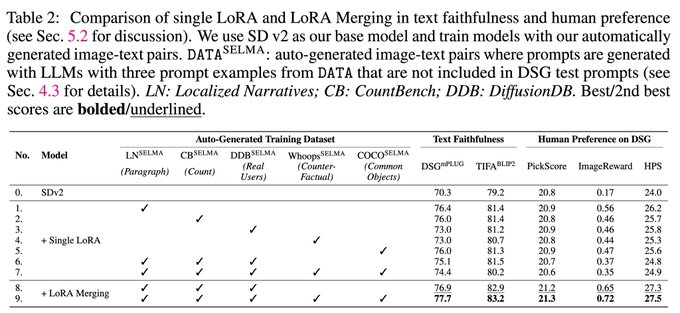
On three T2I models (SD v1.4, v2, XL), SELMA substantially improves 5 different metrics (e.g., +6.9% on DSG, +2.1% TIFA, +0.4 Pick-a-Pic, +0.39 ImageReward, +3.7 HPS, on SDXL), as well as human preference over the original backbone.


1
0
4
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
Co-led with
@jmin__cho
, and wonderful collaboration with
@yilin_sung
@jaeh0ng_yoon
@mohitban47
!
@uncnlp
@unccs
Check out more details of our paper at:
And our code is available at:
Diffusers checkpoints coming soon!

0
0
4
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
SELMA’s strategy of learning & merging skill-specific LoRA experts is more effective than training a single LoRA model on multiple datasets. This indicates that merging LoRA experts can help mitigate the knowledge conflict between multiple skills.
1
0
4
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
4 stages of SELMA: (a) given a description and three in-context examples about a specific skill, we generate prompts to teach the skill with an LLM, while maintaining prompt diversity via text-similarity-based filtering.
(b) Next, given the generated prompts, we generate training

1
0
3
Check out more details of our paper at:
Our code is available at:

0
0
3
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
Interestingly, we find that finetuning on auto-generated data matches (+ sometimes outperforms) the performance of finetuning on GT data. This empirically demonstrates the strong effectiveness of auto-generated data, which doesn’t need any human annotation.

1
0
3
Lastly, we show that the agent can benefit from training with more generated panoramic environments, suggesting promising results for scaling up the PanoGen environments to enhance agents' generalization to unseen environments.

1
0
2
@jmin__cho
@yilin_sung
@jaeh0ng_yoon
@mohitban47
@uncnlp
@unccs
We also find intriguing weak-to-strong generalization in T2I models.
Fine-tuning a strong T2I model (SDXL) on images generated with a weaker T2I model (SD v2) improves the performance on all 5 metrics.

1
0
3
Our VLN-Video generates ins for videos with a template infilling method -- explicitly incorporates objects detected in the envs to have richer entity refers and less repetition. We extract templates from TD train set and filter with GPT-2 to preserve high-quality templates only.
1
0
2
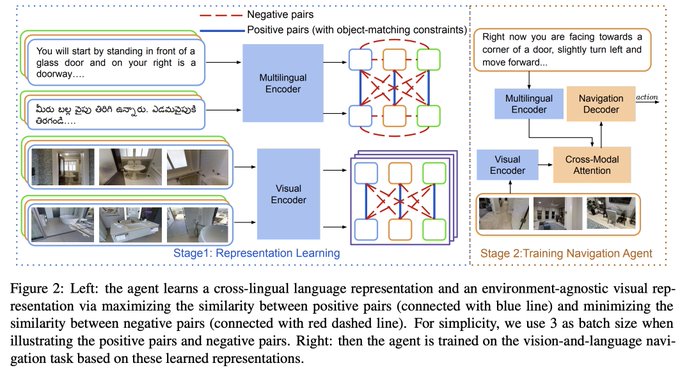
A multi-lingual VLN agent faces larger instruction variance compared with mono-lingual agent. Moreover, previous works have shown that VLN agents perform significantly worse in unseen environments. Thus, we propose CLEAR to address these two challenges on RxR (Eng, Hindi, Telugu)

1
1
3

0
0
3
Then, we use txt2img diffusion models to generate diverse room images based on text captions. To generate consistent 360-degree panorama views, we use a recursive txt-conditioned image outpainting approach, which generates missing observations beyond the original image boundaries

1
0
2
Our new panoramic envs share similar semantic information with the original envs by conditioning on text descriptions, which ensures the co-occurrence of objects in the panorama follows human intuition, & creates enough diversity in room appearance + layout with img outpainting.
1
0
2
First, we generate captions for every discretized view in the panorama using a state-of-the-art vision-language model BLIP-2. This ensures that the generated captions contain a more detailed description of the objects in the smaller region of the panorama.
1
0
2
Our PanoGen can generate continuous views that can be stitched together to form a high-quality panos. Besides, our generated panos preserve the wide range of objects that appeared in the original envs, while generating them with new appearances & different room layouts.

1
0
2
Training with our PanoGen environments achieves the SotA on R2R, R4R and CVDN dataset, outperforming previous SotA agents by a relative gain of 28.5% in goal progress on CVDN test leaderboard, and a 2.7% absolute gain in success rate on the Room-to-Room test leaderboard.

1
0
2
Furthermore, we show the effectiveness of pre-training with the speaker data generated for our PanoGen environments, and replacing the original environments with our PanoGen environments during fine-tuning on R2R, R4R, and CVDN unseen sets.


1
0
2
One main challenge in VLN is the limited availability of photorealistic training environments, which makes it hard to generalize to new and unseen environments. To address this problem, we propose PanoGen to generate panoramic environments for VLN training.

1
0
2
1
0
2
We explore two ways of utilizing PanoGen in VLN. We generate instructions for paths in our PanoGen environments with a speaker built on a pre-trained VL model for VLN pre-train & augment the visual observation with our panoramic envs during agents' fine-tune to avoid overfitting.
1
0
2
Lastly, we show that agents initialized with our learned representation will learn an alignment between the instructions and the environments that is more close to the ground truth alignment.

1
0
2
For Language Representation Learning, we encourage the instructions in different languages corresponding to the same path to be closer to each other with contrastive learning, which helps the agent learn the same visual concepts mentioned in the instructions better.
1
0
2
We pretrain a Transformer-based agent on both TD data & our dataset processed from BDD100K videos with Masked Lang Modeling, Instr Trajectory Matching, Next Action Prediction. Then, we extract the learned contextualized instr repres for initializing the LSTM-based SotA nav agent.

1
0
1
We then show the effectiveness of our proposed proxy tasks in pre-training with ablations. We further show that our codebook selection and block-wise weight function are crucial for learning image semantics. We also show our agent achieves better performance for longer paths.




1
0
1
Detailed analyses: We first show that our learned cross-ling repres can capture visual concepts better. We extract paired paths based on instr similarity, & demonstrate that paths extracted with instructions encoded with our crossling representation contain more similar objects.

1
0
1
1
0
1
We further show that it’s important to have object constraints to filter out views that don’t contain the same objects. These constraints filter out viewpoints with low correspondence/matching and thus improve the learned visual representation.

1
0
1
In Visual Representation Learning, we maximize the similarity between semantically similar paths. To identify such paths, we first extract path pairs with high instruction similarity, & then filter out viewpoint pairs that don’t contain the same objects (to get higher alignment).
1
0
1
Our VLN-Video agent pre-trained on Touchdown and processed videos achieves the new SotA on val & test set on TD, improving previous SotA agents w/o GT path traces by 2.1% TC and 1.3% SED. This demonstrates that our agent follows the instructions better while navigating correctly.

1
0
1
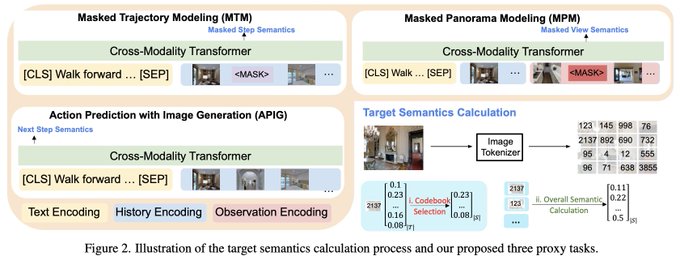
These three objectives teach the model to predict missing views in a panorama (MPM), predict missing steps in the full trajectory (MTM), and generate the next view based on the full instruction and navigation history (APIG), respectively.
1
0
1
Lastly, we then fine-tune the agent on the VLN task with an auxiliary loss that minimizes the difference between the view semantics generated by the agent and the ground truth view semantics of the next step.
1
0
1
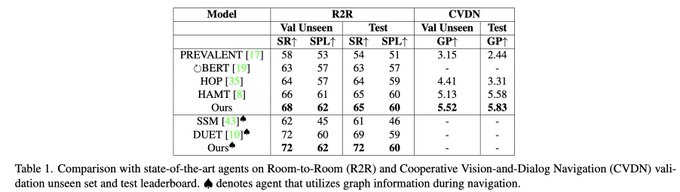
Our proposed VLN-SIG achieves SotA on both the Room-to-Room dataset and CVDN dataset, outperforming previous SotA agents by a relative gain of 4.5% in goal progress (meters) on the CVDN test leaderboard, and a 3% absolute gain in success rate on the Room-to-Room test leaderboard.
1
0
1
See an example to compare nav traj predicted by VLN-Video & baseline. VLN-Video successfully identifies “trash can” & “traffic pole” & stops correctly, whereas baseline fails & stops earlier (suggests that diverse visual data seen in videos helps agent learn obj semantics better)

1
0
1
We further demonstrate that although our representations are trained on the RxR dataset, they can successfully generalize to R2R and CVDN datasets in both zero-shot setting and when fine-tuned on corresponding datasets. (CVDN: 0.74 finetune & 0.42 zeroshot gain in Goal Progress).
1
0
1
Pretraining w/ our video envs achieves better performance compared with pretraining w/ envs only from NYC, suggesting the agent benefits from the diverse visual observations and temporal info in videos. See one qual example of our generated synthetic instructions on video data.

1
0
1
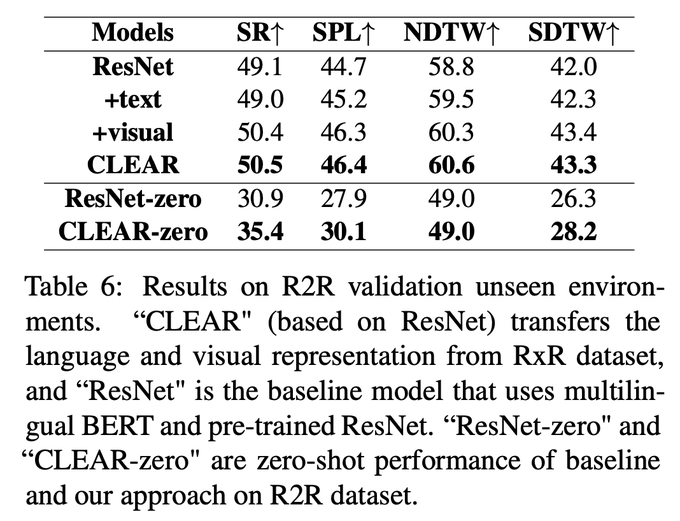
In this way, our env-agnostic visual repres can mitigate env bias induced by low-level visual info: we show that using either ResNet or CLIP features to encode the views, our CLEAR approach significantly improves the baseline agent in all evaluation metrics on unseen environments

1
0
1
1
0
1
We further show that the generated semantics is more similar to the ground truth semantics quantitatively (where our method has a distance of 0.95, while the baseline is 1.31).
Paper:
Code is available at:
0
0
1
First, we calculate the overall image semantics with a block-wise weight and dynamic codebook selection method. The dynamic codebook selection focuses on learning the more important and difficult tokens. The block-wise weight helps learn the richer semantics in the blocks.
1
0
1
Lastly, when given 70%/80%/90% ground truth tokens, our agent could reasonably generate missing future view semantics, and reconstruct future images with higher quality than filling in the missing patches with randomly sampled tokens.

1
0
1
Then, we pre-train the VLN agent with three proxy tasks (Masked Trajectory Modeling, Masked Panorama Modeling, and Action Prediction with Image Generation) to learn the image semantic information.
1
0
1
We also propose an image rotation similarity-based navigation action predictor to predict actions in driving videos. We rotate the frame to mimic the turning action and compare the similarity between the rotated image and the target image to determine the turning direction.

1
0
1
Humans can anticipate which scene is likely to occur next based on instructions and observations and use these to assist in action selection. In this paper, we investigate whether nav agents can also benefit from the capability to predict future scenes to aid in action selection.

1
0
1