

Allen Z. Ren
@allenzren
Followers
1K
Following
1K
Media
39
Statuses
294
PhD student in robotics @Princeton with @Majumdar_Ani. Previously @GoogleDeepMind @ToyotaResearch @JohnsHopkins
Joined August 2019
👇Introducing DPPO, Diffusion Policy Policy Optimization. DPPO optimizes pre-trained Diffusion Policy using policy gradient from RL, showing 𝘀𝘂𝗿𝗽𝗿𝗶𝘀𝗶𝗻𝗴 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁𝘀 over a variety of baselines across benchmarks and sim2real transfer.
5
86
467
HNY! Lately I took a crack at implementing the pi0 model from @physical_int. PaliGemma VLM (2.3B fine-tuned) + 0.3B "action expert".MoE + block attention.Flow matching w/ action chunking.Strong eval on Simpler w/ 75ms inference. ckpts available!. 👇(1/6).
18
59
393
LLMs can generate plans and write robot code 📝 but they can also make mistakes. How do we get LLMs to 𝘬𝘯𝘰𝘸 𝘸𝘩𝘦𝘯 𝘵𝘩𝘦𝘺 𝘥𝘰𝘯'𝘵 𝘬𝘯𝘰𝘸 🤷 and ask for help?. Read more on how we can do this (with statistical guarantees) for LLMs on robots 👇.
4
47
234
Excited to attend #CoRL23 next week! I will present AdaptSim on Tue and KnowNo (oral) on Wed. Would love to chat about LLM, uncertainty, conformal prediction, sim2real, Drake, or just anything!
2
14
81
How do we get robots to efficiently explore diverse scenes and answer realistic questions? e.g., is the dishwasher in the kitchen open❓. 👇Explore until Confident — know where to explore (with VLMs) and when to stop exploring (with guarantees).
1
11
73
Greatest pleasure to work with the amazing team! And much thanks to the community for the many feedback we received at #CoRL2023.

Thrilled that our paper on Robots That Ask For Help received the Best Student Paper Award at #CoRL2023! Congratulations to students @allenzren, @anushridixit111, Sasha Bodrova, & our wonderful collaborators at @GoogleDeepMind!.

3
0
58
The colab notebooks for KnowNo is available now at We provide both mobile manipulation and tabletop sim settings. Also check out the demo here using pre-run calibration
LLMs can generate plans and write robot code 📝 but they can also make mistakes. How do we get LLMs to 𝘬𝘯𝘰𝘸 𝘸𝘩𝘦𝘯 𝘵𝘩𝘦𝘺 𝘥𝘰𝘯'𝘵 𝘬𝘯𝘰𝘸 🤷 and ask for help?. Read more on how we can do this (with statistical guarantees) for LLMs on robots 👇.
1
8
41
I really hope humanoid startups can say something about the success rate when they post new demos….

With OpenAI, Figure 01 can now have full conversations with people. -OpenAI models provide high-level visual and language intelligence.-Figure neural networks deliver fast, low-level, dexterous robot actions. Everything in this video is a neural network:
3
0
35
Check out our recent work on applying runtime intervention to VLA observation input, simple yet effective! No training needed. BYOVLA uses action chunk prediction delta to quantify VLA uncertainty. Also see
Tired of your vision-language-action (VLA) model failing catastrophically in the presence of distractions?.Check out BYOVLA: Bring Your Own VLA: a run-time intervention scheme that markedly improves performance with distractor objects and backgrounds.
0
5
31
Consider applying to our group especially if you are interested in making robots reliable! Ani is an amazing mentor to work with!.
Excited about creating robots that know when they don't know and act reliably in challenging environments? We are recruiting PhD students again this cycle to the IRoM Lab @Princeton!

1
0
31
(6/6) I've made all the data processing / training / eval scripts available!. Plan to training with mixed OXE data soon. Also excited about co-training with other modalities, and SFT/RL fine-tuning leveraging the MoE setup. Finally, my favorite google robot clip in Simpler :)
0
1
22
Our paper on safety assurance for navigation with learned perception will be presented at Poster and Spotlight Session 2 at CoRL! Stop by our poster to learn more! @anushridixit111
Accepted to #CoRL2024: our work on calibrated uncertainty quantification for perception systems for end-to-end statistical assurances for navigation!.Perceive with Confidence: .Work led by @anushridixit111 during her postdoc at @Princeton!
0
2
20
Check out Kaiqu’s awesome work on better aligning LLM planner’s uncertainty with task ambiguity!. Introspection based on previous experiences and asking for human assistance when needed makes robot/Al systems more reliable during deployment.

Frustrated by robots taking unsafe actions ⚠️ or asking for help too often? 🤔. Introducing introspective planning 🧠✨, a novel approach to align LLM’s uncertainty with the inherent task ambiguity. Our paper was accepted to NeurIPS 2024!. 🌐 Webpage: 🔗
1
0
18
@larsankile will present DPPO (oral) tmr at the CoRL Workshop on Mastering Robot Manipulation in a World of Abundant Data and also at the Fine Dexterous Manipulation workshop!. Talk to him and learn how to supercharge pre-trained diffusion policy with RL!.
👇Introducing DPPO, Diffusion Policy Policy Optimization. DPPO optimizes pre-trained Diffusion Policy using policy gradient from RL, showing 𝘀𝘂𝗿𝗽𝗿𝗶𝘀𝗶𝗻𝗴 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁𝘀 over a variety of baselines across benchmarks and sim2real transfer.
1
1
17
Check out Sidd's VLMs and what really matter for training them! We have also an exciting work in active perception🧐powered by Prismatic VLMs, coming up soon.

What design choices matter when developing a visually-conditioned language model (VLM)?. Check out our paper – Prismatic VLMs – and open-source training code, evaluation suite, and 42 pretrained VLMs at the 7B-13B scale!. 📜 ⚙️ + 🤗
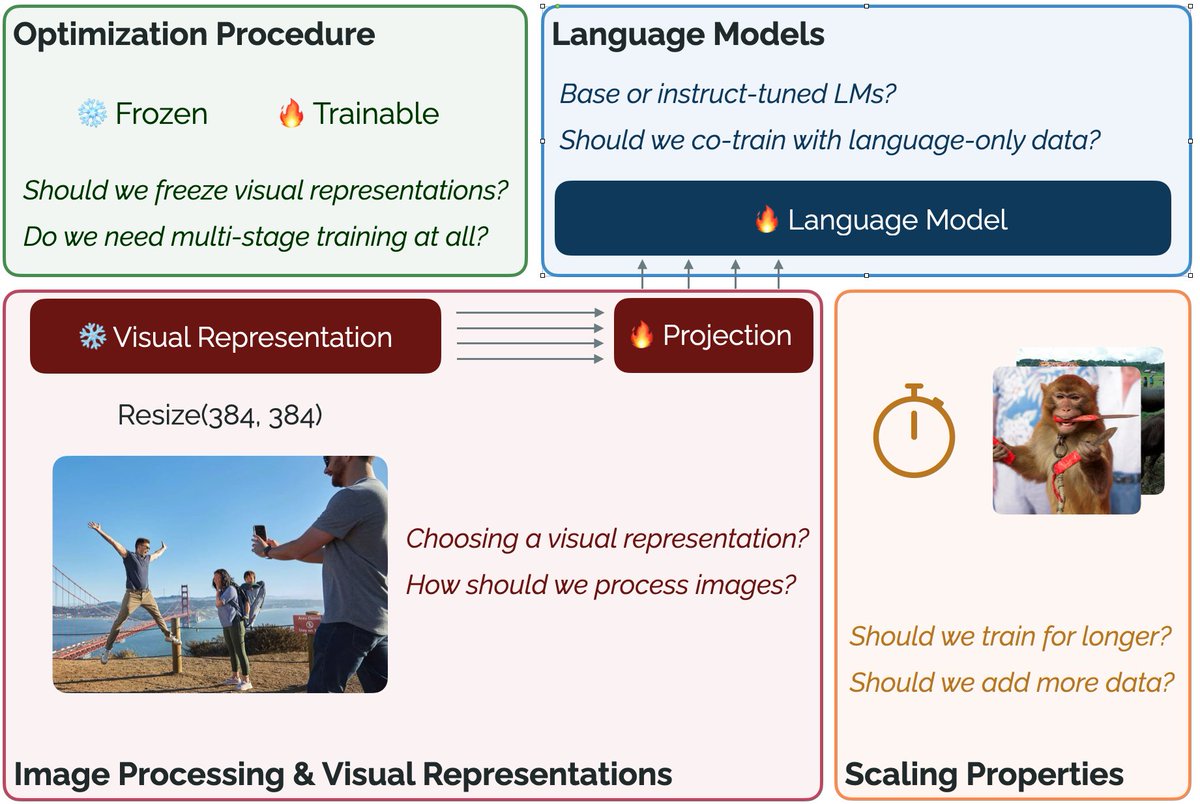
0
1
14
1.5yr ago we tried to use BERT embedding to accelerate robot learning creative use of tools (in sim) now clever use of LLM can get us very far (in real!).

Using tools is often regarded as the hallmark of intelligence. How can robots creatively use tools beyond standard functionalities and make impossible tasks possible? 🤖🗝️. We introduce RoboTool built on LLMs, enabling multiple creative tool-use behaviors, including tool
1
1
13
@LiruiWang1 @BoyuanChen0 DPPO comes from a wonderful collaboration with @justinlidard @larsankile @anthonysimeono_ @pulkitology @Majumdar_Ani @Ben_Burchfiel Hongkai Dai + last author @max_simchowitz. Give DPPO a try with our code!. Website/code: Paper:
0
1
11
@GuanyaShi @_akhaliq It reminds me I was trying to get the Minitaur jumping the stairs (scripted controller) somewhere in Hamerschlag I think in 2018. Amazing to see how both software and hardware have gotten so much better since then!
0
0
11
Check out the amazing line of speakers and talks from our robotics seminar!.
All recordings from our @Princeton Robotics Seminar are now online!.We had a wonderful set of speakers spanning diffusion policies, self-supervised learning, human-robot interaction, safe model-based control, and much else. Stay tuned for next year!

0
0
10
DPPO implements Proximal Policy Optimization (PPO) by treating the denoising process as part of a “two-layer MDP”, making gradients efficiently computable. We improve performance with better advantage estimation + modified denoising schedule to balance exploration and stability

1
1
10
Congrats Max! Max has taught me so much in the past year and he is also super fun to work/be friend with :). Join him to explore the theoretical and algorithmic frontiers of decision making!.

A very exciting personal update: In January, I’ll be joining @CMUMLD as tenure-track assistant professor! My lab will focus on the mathematical foundations of, and new algorithms, for decision making. This includes everything from reinforcement learning in the physical world

0
0
10
Most remarkably, DPPO achieves zero-shot sim2real transfer in state-based, long-horizon assembly tasks, while Gaussian policy shows significant sim2real gap. DPPO also succeeds in challenging pixel-based benchmark (see next), and we are actively working on pixel sim2real
1
1
9
Our newest work tackles the problem of calibrating perception system alone while providing end-to-end system safety assurance! Closed-loop distributional shift is a big hurdle of combining guarantees from different modules, and we offer a clever solution to that.
How can we rigorously quantify the uncertainty of pretrained perception models to provide end-to-end statistical safety assurances for robot navigation?Perceive With Confidence: Statistical Safety Assurances for Navigation with Learning-Based Perception.🧵
0
1
9
Glad to release the code for the Sim-to-Lab-to-Real paper with my co-author Kai-Chieh. Code: Website: (1/n)

1
0
9
I am presenting Sim-Lab-Real on Saturday in the journal track oral session 9:30am. The work (from 2 years ago!) is published at Artificial Intelligence Journal.
New preprint in collaboration with Jaime Fisac's group:.Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees.Work led by Kai-Chieh Hsu and Allen Ren.

0
1
9
@DJiafei @physical_int Thanks Jiafei! I don't have anything right now apart from the readme since my goal so far was to replicate the architecture from the pi0 paper. I hope to play things around a bit more though and write a blog about it. Will let you know!.
1
0
9
Hope to see more benchmarks and environments in continual learning from the robotics community!.

We are thrilled to announce LIBERO, a lifelong robot learning benchmark to study knowledge transfer in decision-making and robotics at scale! 🤖 LIBERO paves the way for prototyping algorithms that allow robots to continually learn! More explanations and links are in the 🧵
0
1
9
@EugeneVinitsky We have been thinking about the right way to use RL (in robotics). I think pre-training with expressive models (diffusion/flow) + RL fine-tuning (in physics sim/real/video sim) can be really powerful in the long term (shameless plug of my own work here .
1
0
9
(4/6) Inference involves 1 forward pass through PaliGemma (saving KV cache), and then 10 flow matching steps through the action expert. RTX 4090, bf16, torch.compile -> 75ms. *my numbers are w/ 1 image input and chunk size 4 while the original Pi0 uses 3 images and chunk size 50

1
1
8
Our work (from CoRL 2022) borrows representations from foundation models to help robots learn faster! Great to see the similar idea in recent work like PR2L
Our work on leveraging language for accelerated learning of robotic tool manipulation (led by PhD student @allenzren in collab. with.@karthik_r_n) was featured in a new Scientific American @sciam article alongside a number of exciting advancements!.
0
0
8
(5/6) Why considering evaluating with float32 even though training was in bf16? Turns out that with the current implementation, using KV cache of vlm/proprio leads to a small distribution shift in policy output when bf16 is used, while using float32 shows negligible difference.
1
0
8
Why does DPPO work so well? DPPO engages in 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱, 𝗼𝗻-𝗺𝗮𝗻𝗶𝗳𝗼𝗹𝗱 𝗲𝘅𝗽𝗹𝗼𝗿𝗮𝘁𝗶𝗼𝗻, showing wide coverage around expert data due to more structured exploration noise. This improves training efficiency and leads to smooth actions that aid in sim2real
1
1
8
DPPO yields marked improvements in training stability and final performance compared to other diffusion-based RL methods and common policy parameterizations such as Gaussian and Gaussian Mixture, across tasks from Gym, D3IL, Robomimic, and Furniture-Bench

1
1
8
DPPO solves the challenging Square and Transport tasks in robomimic to >90% success using 𝐞𝐢𝐭𝐡𝐞𝐫 𝐬𝐭𝐚𝐭𝐞 𝐨𝐫 𝐩𝐢𝐱𝐞𝐥 input and sparse reward. To our knowledge, DPPO is the first RL algorithm to solve Transport to >50% success rates (from either state or pixel!)
1
2
8
(3/6) I have trained with either fractal or bridge dataset so far. Below shows Simpler eval of OpenPi0 trained with either Uniform or Beta sampling (proposed by Pi0) of flow matching timesteps. Beta: avg 68.8% (bridge) and 69.6% (fractal).Uniform: avg 56.0% and 66.7%

1
0
7
Reliable deployment of robots in the real world calls for robustness to distributional shift. Check out our workshop on out-of-distribution generalization in robotics #CoRL2023!.

📢 Announcing the first @corl_conf workshop on Out-of-Distribution Generalization in Robotics: Towards Reliable Learning-based Autonomy! #CoRL2023. 🎯 How can we build reliable robotic autonomy for the real world?. 📅 Short papers due 10/6/23. 🌐 🧵(1/4).
0
3
7
@mustafasuleymn Our recent work at @GoogleDeepMind and @EPrinceton addresses this for language-instructed robots! We uses conformal prediction as a wrapper around LLM logprobs to achieve efficient triggering of human help when LLM is uncertain.
LLMs can generate plans and write robot code 📝 but they can also make mistakes. How do we get LLMs to 𝘬𝘯𝘰𝘸 𝘸𝘩𝘦𝘯 𝘵𝘩𝘦𝘺 𝘥𝘰𝘯'𝘵 𝘬𝘯𝘰𝘸 🤷 and ask for help?. Read more on how we can do this (with statistical guarantees) for LLMs on robots 👇.
1
3
7
(2/6) MoE: each expert/block has its own set of parameters and interacts only through attention; only loss on action expert output. Block-wise causal masking: VLM attends to itself, proprioception (sharing weights with action) attends to itself and VLM, and action attends to all

2
1
7
LLMs can generate plans and write robot code 📝 but they can also make mistakes. How do we get LLMs to 𝘬𝘯𝘰𝘸 𝘸𝘩𝘦𝘯 𝘵𝘩𝘦𝘺 𝘥𝘰𝘯'𝘵 𝘬𝘯𝘰𝘸 🤷 and ask for help?. Read more on how we can do this (with statistical guarantees) for LLMs on robots 👇.
0
3
7
Attending AAAI at Vancouver this Friday and Saturday! Hope to catch up with any folks that are around too!.
1
1
7
Future work could incorporate uncertainty of vision-language models in the pipeline. Quantifying uncertainty builds trust 🤝between us and robots. Let’s make them safe and reliable!. Website: Paper: Colab codes available soon.
2
0
7
In three multi-stage assembly tasks from Furniture-Bench, One-leg, Lamp, and Round-table, DPPO improves the success rate of pre-trained policies from 57% to 97%, 12% to 87%, and 1% to 86%, respectively, learning from only 𝘀𝗽𝗮𝗿𝘀𝗲 𝗿𝗲𝘄𝗮𝗿𝗱
1
1
6
Great idea of combining the MCQA setup (Sample & Select) in KnowNo ( with self-evaluation! Excited to see this being applied to general question answering and improving LLM calibration.

Struggling with LLM calibration for open-ended generation?.Check out our methods (Sample & Select / Sample & Eval) that reformulate open-ended generation into multiple choice or true/false evaluation to leverage LLMs’ better calibration at the token level.

0
0
5
For example, if a robot 🤖 is tasked to "put the bowl in the microwave" but sees two bowls – a metal and plastic one – the uncertainty of the LLM should trigger the robot to ask for help 🛟. Greedily choosing e.g. the metal bowl can damage the microwave or even cause a fire 🔥
2
2
6
Very cool and useful idea! Interesting that with sysid between sim and real, sim performance is biased and consistently worse than real 🤔.

Scalable, reproducible, and reliable robotic evaluation remains an open challenge, especially in the age of generalist robot foundation models. Can *simulation* effectively predict *real-world* robot policy performance & behavior?. Presenting SIMPLER!👇.
2
0
6
Exploring LLM uncertainty in the context of generating robot plans is especially crucial because of safety considerations 🚧. Instructions from people can be ambiguous, and LLMs are prone to hallucinating. Poor outputs can lead to unsafe actions and consequences.

1
1
5
Check out Nate's tiny crazyflie navigating with monocular(!) depth estimation with onboard RGB image. Amazing results!.

We just released code for MonoNav: MAV Navigation via Monocular Depth Estimation and Reconstruction! (w/ @Majumdar_Ani at IRoMLab). MonoNav enables real-time 3D reconstruction from a stream of noisy images and poses. Code:
0
0
5
This work comes from collaboration between @EPrinceton and @DeepMind, including @anushridixit111, Alexandra Bodrova, @Sumeet_Robotics, @stephenltu, Noah Brown, @sippeyxp, @leilatakayama, @xf1280, Jake Varley, @Zhenjia_Xu, @DorsaSadigh, @andyzeng_, @Majumdar_Ani.
1
0
5
DPPO also yields policies that are robust to perturbations in dynamics and the initial state distribution. Such robustness also allows more extensive domain randomization in simulation to facilitate sim2real transfer

1
1
5
In future, we are excited to unlock the potential of DPPO in multitask settings by exploiting diverse expert data manifolds through structured exploration + combining RL with test-time guidance (e.g. POCO @LiruiWang1), and other architectures (e.g. Diffusion Forcing @BoyuanChen0).
1
1
5
Off-the-shelf LLM predictions do come with confidence scores, but can be miscalibrated 📐. Our framework "KnowNo" builds off of conformal prediction (CP) theory to model LLM uncertainty: generate a set of predictions, then quantify how likely it contains a correct option.
1
2
5
@DannyDriess Awesome work Danny! Would you say the bottleneck is still the amount of real data available? I saw PaLM-E only use probably 5% real robot data. I would also be curious about how useful the sim robot data is. I feel for such use of sim without physics, sim data can be very useful.
0
0
5
Our most recent work improves safety during training and deployment at sim2real transfer in RGB-based navigation tasks by leveraging Hamilton-Jacobi reachability analysis and PAC-Bayes guarantees. Check out the website for more details!.
New preprint in collaboration with Jaime Fisac's group:.Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees.Work led by Kai-Chieh Hsu and Allen Ren.
0
0
4
In mobile manipulation settings, common home-robot task instructions can often under-specify the object (“the chips”) or target location (“the drawer”)
1
0
4
Our paper was accepted @corl_conf and I will be presenting it at the last poster session on this Wednesday. Looking forward to your thoughts and questions!. paper: video:
My newest work provides generalization guarantees for imitation learning. We leverage a compact, high-entropy latent policy distribution to encode multi-modal expert behavior and be '"fine-tuned" to achieve strong performance in novel environments. Also my first paper in PhD!.
0
0
4
@davidstutz92 @beenwrekt Great post David! I really like the perspective of hypothesis testing. As for using pred sets, we have some applications in robotics, e.g., set size triggering human help or set include obstacles that the downstream planner should avoid (under review).
1
0
4
DRAGEN is our most recent effort in addressing out-of-distribution robustness of control policies in robotic settings.
New pre-print from our group: "Distributionally Robust Policy Learning via Adversarial Environment Generation" (DRAGEN). ArXiv: Video: Work led by @allenzren.

1
0
4
CP provides statistical guarantees: with user-specified probability, the prediction sets contain the correct plans at test time!
1
1
4
We ran all experiments with PaLM-2L model, which provides reasonably calibrated confidences. We find that GPT3.5 suffers from recency bias in MCQA. Nonetheless, KnowNo still achieves the target success level by triggering more human help.

1
0
4
KnowNo triggers human help🛟when the prediction set has more than one option. Baselines that use the scores without calibration 📐or directly ask LLM if it is uncertain can trigger unnecessary help.

1
1
3
@larsankile Since the release we have also added experiments comparing DPPO to other RL methods using offline data (RLPD, Cal-QL, IBRL) (see figure) and significantly optimized our code base. Website: (new arxiv version).Code:

1
1
3
KnowNo can also quantify LLM planner uncertainty in multi-step planning settings, such as sorting food items 🥕 based on human preferences with feedback.
1
0
3
@BoyuanChen0 @Ken_Goldberg @Stanford I think another interesting question is how much sensing/hardware we need for achieving certain success levels in different tasks. Even with infinite data, there can be things still not learnable or controllable if robots don’t have enough sensing or control capabilities.
1
0
3
@roydanroy Hi Dan, not sure if relevant enough, but my paper that applies PAC-Bayes bound to IL/RL in robotics might be interesting:
0
0
3
@andrewsilva9 @MatthewGombolay @core_robotics Congrats Andrew! Best of luck in your future endeavors.
0
0
3
In bimanual settings, the arms' reachability is limited and there is ambiguity in the choice of arm for the specific task
1
0
3
@zipengfu @tonyzzhao @chelseabfinn Wow this is happening so fast!. One question I have: will simple setup with parallel-jaw gripper reach deployment-ready task success rate, even with a lot more data? Maybe eventually we need better hardware to reach the robustness we desire?.
1
0
2
Check out Sim-to-Lab-to-Real, also accepted to the Artificial Intelligence Journal! Will be presenting it at the NeurIPS TEA workshop on Dec 2.
How can we safely bridge the sim2real gap in vision-based navigation tasks? .Check out our paper, Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees, now accepted to the Artificial Intelligence Journal!.Website: 🧵
0
0
3
We often see robots as the embodiment for the path towards agi. Along the exciting journey, there are many that we can learn from robotic systems that are deployed already, especially challenges yet to to solved even in more structured environments.
With seemingly endless progress in AI, I decided over the past few months to take a deep dive into the state of robotics 🤖, emerging trends, and research challenges. What do actual field-deployed robotic systems look like now? Will LLMs solve robotics?.🧵.
0
1
3
Check out the presentation!
New pre-print on recent collaborative work:.FlowDrone: Wind Estimation and Gust Rejection on UAVs Using Fast-Response Hot-Wire Flow Sensors.We integrate novel MEMS flow sensors onto a drone, and train a policy using RL for real-time control with wind.
0
0
3
@m_wulfmeier Very cool work Markus! Our recent work also unifies the two settings (RL+demo pre-training) with the powerful diffusion policy used in ALOHA! hope you find it interesting
👇Introducing DPPO, Diffusion Policy Policy Optimization. DPPO optimizes pre-trained Diffusion Policy using policy gradient from RL, showing 𝘀𝘂𝗿𝗽𝗿𝗶𝘀𝗶𝗻𝗴 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁𝘀 over a variety of baselines across benchmarks and sim2real transfer.
1
0
2
1
0
2
My newest work provides generalization guarantees for imitation learning. We leverage a compact, high-entropy latent policy distribution to encode multi-modal expert behavior and be '"fine-tuned" to achieve strong performance in novel environments. Also my first paper in PhD!.
How can we guarantee that policies for robots learned via imitation learning will generalize to novel environments? Check out our new preprint: "Generalization Guarantees for Multi-Modal Imitation Learning".w/@ZhiyiRen,@Veer_Sushant.
0
0
2
@MinhoHeo thanks Minho! we really enjoyed using furniture-bench as a challenging long-horizon benchmark, and kudos to @larsankile for addressing some of the issues especially the sim speed-up.
1
0
2
Our recent work lets robot learn to use diverse tools using additional language information (e.g., shape, affordances)! p.s., turns out GPT-3 is great for collecting such information.
New collaborative work with @karthik_r_n 's group:.Leveraging Language for Accelerated Learning.of Tool Manipulation.We investigate how language descriptions of a tool (e.g., geometry, common uses) can help a robot learn how to use the tool more quickly.

0
0
2
Very excited to join this effort!.
Delighted to have received a Young Faculty Researcher award from the Toyota Research Institute. Very excited to be collaborating with @ToyotaResearch on our efforts on learning manipulation with guarantees on distributional robustness/generalization.
0
0
2
In the era of foundation models, we propose leveraging pre-trained VLMs for EQA. VLMs can answer complex questions about static 2D images, and we also find them capable of reasoning about relevant regions to explore.

1
0
2
@EugeneVinitsky For fine-tuning often it can be more sample efficient than Gaussian so the wall-clock is quite good (sometimes faster). For training from scratch it is definitely slower than Gaussian --- we didn't fully explore training from scratch with diffusion.
0
0
2
While we used PaLM-2L in our experiments, the colabs use text-davinci-003, which we find exhibit significant bias towards option C/D and against A/B in multiple choice question answering 😅. Nonetheless, KnowNo achieves the target success level by triggering more human help.
0
0
2
@ChongZitaZhang I had a paper on this a while back I think the idea is there but now we have much better generative models and large-scale simulation.
1
0
2
@yukez @Princeton It was wonderful to have you, Yuke! Thanks for visiting and giving the great talk!.
0
0
2
@Vikashplus Robot can also reach locations precisely without need to localizing itself in the kitchen.
1
0
2
We also curated HM-EQA, a new EQA dataset that consists of 500 questions in 267 scenes from the Habitat-Matterport 3D dataset. We consider a wide variety of realistic scenarios and question categories.

1
0
1
@YouJiacheng Also there have been many previous work that use diffusion for RL, most of them in offline setting and some does online learning/fine-tuning too (IDQL, DQL, QSM, etc).
2
0
2
@rm_rafailov @physical_int (I have not playing around action chunk size at all, mostly because of the low-freq dataset.
0
0
2
@chris_j_paxton @ChongZitaZhang reaching human-level robustness in pick-and-place (still hard in tight space) might need very robust recovery behavior, which could require certain level of dexterity (and certainly very capable hardware).
0
0
2
@ChaoyiPan (Con’t) We also tried skipping last denoising steps and there was similar result. There is definitely room for finding better sampling scheme for exploration.
0
0
1
@khanhxuannguyen Thanks Khanh! Indeed these are very appropriate references and we received similar feedback. We have revised the paper to include some of them and will update the arxiv version soon.
0
0
1
This work is a collaboration between @EPrinceton, @StanfordAILab, and @ToyotaResearch, including @jadenvclark, @anushridixit111, @MashaItkina, @Majumdar_Ani, @DorsaSadigh. Much thanks to @siddkaramcheti for providing early access to Prismatic VLMs!.
What design choices matter when developing a visually-conditioned language model (VLM)?. Check out our paper – Prismatic VLMs – and open-source training code, evaluation suite, and 42 pretrained VLMs at the 7B-13B scale!. 📜 ⚙️ + 🤗
1
0
1
@max_simchowitz My greatest pleasure Max! Loved all the impromptu discussions :) and learned many things from you!.
0
0
1
@EugeneVinitsky @chris_j_paxton There is also the effect of hardware and sensing IMO. More capable and reliable hardware and sensing pushes the upper limit higher, despite the shallower curve I imagine. Btw table 2 of this paper shows some scaling law that saturates.
0
0
1