

Yikang Shen
@Yikang_Shen
Followers
1,782
Following
295
Media
15
Statuses
177
Research staff member at MIT-IBM Watson Lab. PhD from Mila.
Boston, MA
Joined September 2012
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
TLP THE SECRET OF RING
• 919135 Tweets
凱旋門賞
• 132119 Tweets
Jets
• 99732 Tweets
Semih
• 68976 Tweets
Vikings
• 65038 Tweets
Rodgers
• 59776 Tweets
シンエンペラー
• 59522 Tweets
中嶋監督
• 48576 Tweets
Brighton
• 42117 Tweets
#الملك_سلمان_بن_عبدالعزيز
• 40954 Tweets
Penaltı
• 34425 Tweets
Hoca
• 31132 Tweets
Browns
• 29494 Tweets
Watson
• 27012 Tweets
ブルーストッキング
• 25862 Tweets
Panthers
• 25488 Tweets
#GSvALN
• 22591 Tweets
Mertens
• 22102 Tweets
Texans
• 21352 Tweets
Ange
• 16547 Tweets
Darnold
• 16019 Tweets
#GFKvBJK
• 14491 Tweets
Winston
• 13412 Tweets
Salih
• 12139 Tweets




















🚨Job alert🚨
1. IBM Foundation Model team is hiring research engineers in India and North Carolina.
2. We are also looking for 2025 summer research interns in Boston.
We train large language models and do fundamental research on directions related to LLMs.
Please email or DM
20
57
464
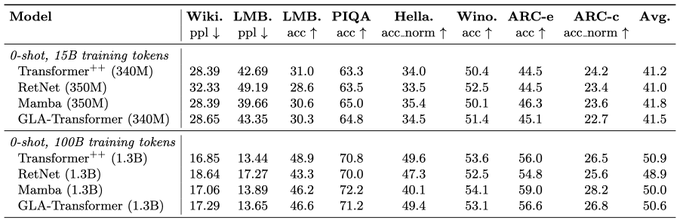
Impressed by the performance of Mamba and believe in RNN? We provide a simple alternative solution! Excited to share Gated Linear Attention (GLA-Transformer). (1/n)
6
67
391
Announcing the open-source of MoLM, a collection of MoE-based Language models ranging in scale from 4 billion to 8 billion parameters, based on our ModuleFormer architecture. (1/n)

7
70
336
Our new Sparse Universal Transformer is both parameter-efficient and computation-efficient compared to the Transformer, and it's better at compositional generalization! paper:

4
49
292
Our team in the MIT-IBM Watson Lab seeks highly motivated summer research interns to work on exciting projects about Foundation Models: pre-training, finetuning, alignment, MoE, agent, etc. (1/4)
8
37
240
With a few tricks, Llama-3-8B can be continued trained to outperform GPT-4 on Medical tasks. For more details, check our paper Efficient Continual Pre-training by Mitigating the Stability Gap ()!

5
39
175
Sparse models can do more things than you think! We propose ModuleFormer, a new MoE-based architecture that is more efficient, extendable, and easier to prune than dense language models.[1/4]
Arxiv page:

4
40
155
It often surprises people when I explain that Sparse MoE is actually slower than dense models in practice although it requires less computation. It's caused by two reasons: 1) lack of efficient implementation for MoE model training and inference; 2) MoE models require more

Scattered Mixture-of-Experts Implementation
- Presents ScatterMoE, an implementation of Sparse Mixture-of-Experts on GPU
- Enables a higher throughput and lower memory footprint
repo:
abs:

1
33
207
3
25
143
Thanks for posting our work!
(1/5) After running thousands of experiments with the WSD learning rate scheduler and μTransfer, we found that the optimal learning rate strongly correlates with the batch size and the number of tokens.


IBM presents Power Scheduler
A Batch Size and Token Number Agnostic Learning Rate Scheduler
discuss:
Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation

1
38
177
4
27
134
It’s nice to see people start working on MoE for attention mechanisms! A simple fact is that about 1/3 of transformer parameters and more than 1/3 of computation are in the attention layers, so you need something like MoE to scale it up or make it more efficient. Btw, our work,
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
paper page:
The costly self-attention layers in modern Transformers require memory and compute quadratic in sequence length. Existing approximation methods usually underperform and

1
47
249
1
13
125
Training LLMs can be much cheaper than your new top-spec Cybertruck!
Our new JetMoE project shows that just 0.1 million USD is sufficient for training LLaMA2-level LLMs.
Thanks to its more aggressive MoE architecture and 2-phase data mixture strategy, JetMoE-8B could


3
12
76
Our IBM Granite Code series models are finally released today. Despite the strong code performance that you should definitely check out, I also want to point out that the math reasoning performance of our 8B models is unexpectedly good. Congrats to all our teammates!

3
18
64
Haha, surprise!

2
3
63
The technical report () for JetMoE is out! It includes a detailed description of our data mixture. The datasets are available on HF. Together with my modified version of Megablock (). With a little effort, everyone should be able to

1
17
55
Haha, now we start to talk about who is earlier. Please remember that ModuleFormer also comes earlier with a more sophisticated architecture. It has mixture of experts for both Attention and MLP!

I do believe Mistral did an amazing job.
But this tweet is a bit 𝐨𝐟𝐟𝐞𝐧𝐬𝐢𝐯𝐞 to me 😕
1) OpenMoE is earlier.
2) OpenMoE is more open. We released everything. Code, data, checkpoints and everything we have. I also told everyone everything without any reservation when they
35
93
986
1
5
41
In case you are interested in using the Mixture of Attention heads (MoA) in your next model, here is my implementation of MoA using the Megablock library:
Training LLMs can be much cheaper than your new top-spec Cybertruck!
Our new JetMoE project shows that just 0.1 million USD is sufficient for training LLaMA2-level LLMs.
Thanks to its more aggressive MoE architecture and 2-phase data mixture strategy, JetMoE-8B could
3
12
76
0
6
40
When you consider using MoE in your next LLM, you could ask yourself one question: Do you want a brutally large model that you can't train as a dense model, or do you just want something that is efficient for inference? If you choose the second goal, you may want to read our new

Thrilled to unveil DS-MoE: a dense training and sparse inference scheme for enhanced computational and memory efficiency in your MoE models! 🚀🚀🚀
Discover more in our blog: and dive into the details with our paper:
2
17
82
0
6
37
This is our experimental models. We will release something more interesting very soon!

PowerMoE from IBM look underrated - Trained on just 1T (PowerLM 3B) & 2.5T (PowerMoE 0.8B active, 3B total) - open model weights - comparable perf to Gemma, Qwen 🔥
> Two-stage training scheme
> Stage 1 linearly warms up the learning rate and then applies the power decay
> Stage

3
17
81
3
4
34
ScatterMoE is accepted by CoLM. See you in Philadelphia!
Scattered Mixture-of-Experts Implementation
- Presents ScatterMoE, an implementation of Sparse Mixture-of-Experts on GPU
- Enables a higher throughput and lower memory footprint
repo:
abs:
1
33
207
1
5
32
ModuleFormer saves about 75%, and we will release something more creative and practical soon 😉
Deepseek MoE came out!
GitHub:
I suggested MoE can save around 50% cost in OpenMoE ()
They saved around 60%. Cool!
1
24
150
0
2
27
Now accepted as Spotlight at
#NeurIPS2023
!
See you in New Orleans!
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
abs:
paper page:
project page:

14
121
493
0
3
27
Please come to the LLM-AI() workshop at KDD 2023, if you are interested in pretraining, finetuning, and other LLM-related topics. I will give a keynote on "Modular Large Language Model and Principle-Driven Alignment with Minimal Human Supervision".
0
5
26
If you are interested in joining our team as a research intern, please send your resume and a brief statement of interest to yikang.shen
@ibm
.com.
We look forward to reviewing your application! (4/4)
2
0
25
Yes, our goal is to create really useful code LLMs for real production use cases, not for just getting some kind of sota on HumanEval (but we still get it 😉).

Interested in LLM-based Code Translation 🧐?
Check our CodeLingua leaderboard (). We have updated the leaderboard with newly released Granite code LLMs from
@IBMResearch
. Granite models outperform Claude-3 and GPT-4 in C -> C++ translation 🔥.

3
13
51
0
7
22
The key takeaway is that a simple data-dependent gating mechanism could boost the linear attention to the transformer and mamba level of performance. (3/n)

1
1
21
@teortaxesTex
@tanshawn
@samiraabnar
I am super exciting to have a race like this, we will do our best 😃
1
0
19
We have updated our PowerLM series models. They are now under Apache 2.0. And with a slight tweak to the data mix, they perform better than the previous version.
PowerLM-3B:
PowerMoE-3B (800M active params):

0
4
17
It features linear-time inference complexity, sub-quadratic parallel training, the same performance as both Transformers and Mamba, and all the other benefits you will expect from an RNN model! (2/n)
1
0
16
@arankomatsuzaki
I mostly agree with this post. Except the part that Moduleformer leads to no gain or performance degradation and instability. Could you point me to these results? Our version of MoA made two efforts to solve the stability issue: 1) use dropless moe, 2) share the kv projection
2
2
15
MoLM's performance is similar to dense language models with 4x the amount of computation! (4/n)

0
1
14
This is a joint work with
@SonglinYang4
@bailin_28
@rpanda89
and
@yoonrkim
. We (the authors) are also at NeurIPS, and happy to chat more on this! (5/5)
1
0
14
To release the full power of GLA-transformer, we develop a hardware-efficient version of the parallel form that can still use tensor cores through block-parallel computations over sequence chunks. (4/n)
1
0
13
And we will release something innovative to solve the second issue very soon!
1
0
13
We are looking for Ph.D. students who are passionate about research and have a strong background in foundation models, machine learning, or a related field. Good engineering skill is also a plus. (3/4)
2
0
13
JetMoE and IBM Granite Code models are now natively available on in Huggingface Transformers v4.41!

1
8
13
Very important evaluation and insight. The problem of some previous rnn models is that they don’t have large or sophisticated enough hidden states to memorize the context. Mamba and our GLA tackle this problem by using a large hidden state and inout dependent gating mechanism.

Curious whether sub-quadratic LMs like RWKV and Hyena will replace Transformers?
We find that Transformers are still much better at associative recall (AR): a simple task known to be essential for in-context learning.

4
38
145
0
1
12
On my way to
#NeurIPS2023
, let me know if you want to chat about MoE, alignment, RNN (we will release a new architecture soon!) and anything else about LLM!

3
0
13
Thanks for all the interest! I have opened my DM to get more applications.
0
1
12
(3/5) So now we can accurately predict the optimal learning rate for any given number of tokens, batch size, and model size! But more interestingly, we can use one learning rate for all these different configurations with our newly proposed power scheduler: lr = bsz * a * T ^ b!

1
1
12
@arankomatsuzaki
Ya, I am familiar with the MoE attention results in the switch transformer paper’s appendix. I think the instability is mostly due to too many possible combinations of query and key experts (value and output experts as well). The results motivate us to share kv projection in MoA.
0
3
11

Language models generate self-contradict responses across different samples. We leverage game theory to identify the most likely response!

⭐️New Paper⭐️
Can we use game theory to improve language model (LM) decoding?
We introduce Equilibrium-Ranking (ER), where we cast LM decoding as an imperfect-information game 👾.
On multiple tasks, LLaMA-7B with ER can outperform the much larger LLaMA-65B model.
🧵⬇️1/

3
43
243
0
5
9
Dolomite engine has all the LLM technologies that we have developed so far: ScatterMoE, Power Learning Rate Scheduler, Efficient DeltaNet, and more to come! You can easily use it for your pretraining and sft!

We have released a torch compile friendly version of the scatterMoE kernel.
Speedups are around 5-7% on 64 H100s for 1B MoE model.
Larger MoEs or MoEs with larger compute density will benefit more from the optimization.
Code:
0
2
10
0
1
10
MoLM-350M-4B is a MoE-based language model. It has 4 billion parameters, but each input token activates 350M parameters during inference. Thus, it's computationally equivalent to a 350M dense model. (2/n)
1
0
9
You can work on cutting-edge research projects with industry-level resources as an intern at the lab. You will collaborate with IBM researchers and work closely with MIT faculties and students. (2/4)
1
0
9

(5/5) Paper:
Models:

1
0
9
@far__el
Sorry, the link is actually not accessible. We will set up the GitHub repo very soon.
0
0
8
Learn more about JetMoE and access the model:
Research:
GitHub:
Huggingface:
Demo:
Joint work with
@Zhen4good
@tianle_cai
@qinzytech
@myshell_ai
@LeptonAI

0
0
8
(4/5) With this new scheduler, we pretrained two models: PowerLM-3B, a 3B model with comparable performance as other sota 2-3B models, but only trained on 1.25T tokens; PowerMoE-3B, a 3B MoE model with 800M activate parameters, achieve better performance than sota 1-2B models.

1
0
7
(2/5) For a given training corpus size, the optimal learning rate and batch size ratios are close to a fixed constant 𝛾. And this ratio 𝛾 has a power-law relation to the training corpus size T. Thanks to μTransfer! This power-law relation doesn't change for different model size

1
0
7
This new principle-following reward model is worth millions of dollars! Because Llama2-Chat collects 1 million human-annotated data to train their reward model, we outperform it with no human annotations.

🚀 Can RLAIF fully replace RLHF to align language models from scratch, enhancing both their alignment and capabilities?
SALMON introduces a principle-following reward model in the realm of self-alignment, using just 6 ICL exemplars and 31 principles to outperform LLaMA-2-Chat!

5
93
302
0
1
7
MoLM-700M-4B has 4 billion parameters and is computationally equivalent to a 700M dense model. MoLM-700M-8B has 8 billion parameters and is computationally equivalent to a 700M dense model. All models are trained on 300 billion tokens from publicly available sources. (3/n)
1
0
7
⚠️An update to the process. Since we have received so many inquiries, we decided to create a form for submitting all applications:
0
0
8
@fouriergalois
Moreover, in practice gateloop used the recurrent form, as opposed to the parallel form, in the actual implementation via parallel scan (potentially due to the numerical issue discussed in section 3), while we rely on our chunk-wise block-parallel form.
1
0
4
Thanks again for all the applications! We will review them and contact you if we want to proceed with the interviews.
0
0
6
This is a joint work with
@mjstallone
,
@MishraMish98
,
@tanshawn
, Gaoyuan Zhang, Aditya Prasad, Adriana Meza Soria,
@neurobongo
,
@rpanda89
1
0
6
Didn’t expect Granite Code model to outperform GPT-4-based solutions. But, wow!

More public leaderboard results 🔥
IBM takes first place on the large-scale text-to-SQL BIRD-SQL leaderboard with ExSL + Granite-20b-Code, beating out a host of GPT-4-based solutions. Huge congrats to the global
@IBMResearch
team that achieved this result.

3
3
14
1
0
6
In a study of the model's performance throughout the continual pre-training process, we observed a temporary performance drop at the beginning, followed by a recovery phase. This phenomenon, known as the "stability gap," was previously noted in vision models classifying new
0
0
4
An excellent explanation about the inference efficiency of MoE mdoels

@MistralAI
model is hot: with mixture-of-experts, like GPT-4!
It promises faster speed and lower cost than model of the same size and quality
Fascinatingly, the speed-up is unevenly distributed: running on a laptop or the biggest GPU server benefit the most. Here’s why 🧵 1/7

7
87
465
0
2
5
@agihippo
@m__dehghani
@tanshawn
Haha, I think that’s because we are gpu-poor and using 2018’s hardware (v100) to do the experiments.
1
0
5
@fouriergalois
Yes, the gateloop is a very interesting related work. The main difference is that our parallel form is more general since gates can be applied in both K and V dimensions, while only the gate for the K dimension is applied in gateloop.
1
0
5
@XueFz
My observations is that MoE can save up to 75% computation cost. But saving more computation requires more experts. People is getting more conservative at number of experts recently, such that we don’t suffer too much from the extra cost of having an insane amount of parameters.
1
0
4
@agihippo
I can’t agree more. Even the possibility, that some jobs might crush and leave some nodes sitting idle, makes me want to stay awake.
1
1
4
@srush_nlp
I think eventually the iteration of gpt-x will look like a human-in-the-loop weakly supervised training. Maybe not a bad thing.
1
0
3
@cloneofsimo
My observation is that this happens along with learning rate decreases. If the learning rate is constant the gradient norm tends to be more stable.
1
0
3
@vtabbott_
Hi Vincent, your robust diagram looks very nice! We are very interested in having SUT diagrammed. It's difficult to explain the architecture (like the Mixture of Attention heads) to those who are not familiar with the context.
1
0
3
1) Efficiency, since ModuleFormer only activates a subset of its modules for each input token, thus it could achieve the same performance as dense LLMs with more than two times throughput; [2/4]
1
0
3
Fantastic work by Junyan and
@yining_hong
! The communicative decoding idea enables VLM to do compositional reasoning across different modalities.

Thanks for featuring AK! We propose a compositional VLM (CoVLM), which could disentangle the reasoning process over the visual entities and relationships using large language models.
Project page:
Code:
4
13
57
0
0
3
@koustuvsinha
@jpineau1
@MetaAI
@mcgillu
@Mila_Quebec
Congrats Dr. Sinha! The thesis is very interesting.
0
0
2
@ElectricBoo4888
@SonglinYang4
@bailin_28
@rpanda89
@yoonrkim
GLA is simple and clean in terms of architecture design, thus could potentially makes it more robust for different scenarios. It also has a much larger hidden state to store more context information.
0
0
2
@MaziyarPanahi
@erhartford
@_philschmid
@qinzytech
@Zhen4good
@tianle_cai
Ya, our Megablocks fork is here:
3
0
2
@srush_nlp
I think human users of gpt models will probably filter and correct some obvious errors before put the model generated content to web. And the future models will use the revised data as training corpus. Thus we have a circle of model generation-human revise-model training.
1
0
2
Old-school sleeper train trip is always a nice experience 😀
0
0
2
@EseralLabs
Thanks. The current model is trained with much fewer tokens and compute, but we are training a larger model to get close to the llama-level performance.
0
0
2
2) Extendability, ModuleFormer is more immune to catastrophic forgetting than dense LLMs and can be easily extended with new modules to learn new knowledge that is not included in the training data; [3/4]
1
0
2
@teortaxesTex
It will take some time and experience to put every pieces together in the right way.
0
0
2
Yikang Shen Retweeted

ICLR Best Paper 2: Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
Yikang Shen · Shawn Tan · Alessandro Sordoni · Aaron Courville

1
12
106
3) Specialisation, finetuning ModuleFormer could specialize a subset of modules to the finetuning task and the task-unrelated modules could be easily pruned for a lightweight deployment. [4/4]
0
0
1
2) Phrase-aware Unsupervised Constituency Parsing (, Poster): We propose a phrase-guided masking strategy to improve unsupervised constituency parsing. (2/2)
0
0
1
1
0
1
@SriIpsit
Hi Krishna, thanks for your interest! I have received many emails. I will go through them in the next few days.
0
0
1
@ShuoooZ
@mjstallone
@MishraMish98
@tanshawn
@neurobongo
@rpanda89
There are several papers discussed about how to predict the critical batch size, including
0
0
1
@dallellama_
Sound great! I will be happy to work together on improving its inference efficiency.
0
0
1
@srush_nlp
Maybe it's because doing CoT and creating a chatbot with BERT is not straightforward?
1
0
1
@XueFz
Totally agree! I also like the OpenMoE. The open sourced training pipeline is a great contribution to the community.
0
0
1
@KoroSao_
The internship will be 3 months at the beginning. But it can be extended conditioned on the progress.
0
0
1
@bonadossou
Ohh, I didn't know that the forum is actually not open... We will set up the GitHub repo very soon.
0
0
1
JetMoE:
Granite Code Models:

0
0
1