
Dmytro Dzhulgakov
@dzhulgakov
Followers
2,843
Following
609
Media
42
Statuses
238
Co-founder and CTO @FireworksAI_HQ . PyTorch core maintainer. Previously FB Ads. Ex-Pro Competitive Programmer
San Francisco, CA
Joined April 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#DNC2024
• 168441 Tweets
River
• 145298 Tweets
Macri
• 89559 Tweets
Bill Clinton
• 84986 Tweets
Simón
• 79175 Tweets
#虎に翼
• 56039 Tweets
Okan
• 44881 Tweets
Mike Lindell
• 39555 Tweets
Talleres
• 25798 Tweets
サンサン
• 25228 Tweets
JENNA
• 24677 Tweets
#AEWDynamite
• 22521 Tweets
Soto
• 22116 Tweets
Oprah
• 21028 Tweets
Borja
• 18482 Tweets
Peñarol
• 16877 Tweets
Stevie Wonder
• 14902 Tweets
Geoff Duncan
• 14229 Tweets
Joey Votto
• 12205 Tweets





















GIL in Python will be no more. Huge win for AI ecosystem. Congrats to
@colesbury
- it took 4+ years of amazing engineering and advocacy.
Many parts of
@PyTorch
could become simpler: DataLoader, Multi-gpu support (DDP), Python deployment (torch::deploy), …
Here’s why. 🧵

No More GIL!
the Python team has officially accepted the proposal.
Congrats
@colesbury
on his multi-year brilliant effort to remove the GIL, and a heartfelt thanks to the Python Steering Council and Core team for a thoughtful plan to make this a reality.
70
1K
5K
12
222
1K
Run
@MistralAI
MoE 8x7B locally with hacked-up official Llama repo!
First cut, not optimized, requires 2 80GB cards.
The optimized version is coming soon to
@thefireworksai
. Stay tuned!

14
60
467
@MistralAI
model is hot: with mixture-of-experts, like GPT-4!
It promises faster speed and lower cost than model of the same size and quality
Fascinatingly, the speed-up is unevenly distributed: running on a laptop or the biggest GPU server benefit the most. Here’s why 🧵 1/7

7
87
465
PyTorch is ready for the Metaverse. Move your models to virtual reality by passing device='meta' and save memory too!
To align with this direction, starting next release Tensor․is_meta () will always return True
10
46
404
PyTorch has been truly open source since its inception 6 years ago. Today it gets truly open governance too: we join the Linux Foundation!
As a maintainer, looking forward to continuing to build the best AI tools with the brilliant developer community!
1
22
226
Guessing Gemini Pro 1.5 uses regular self-attention based on speed.
> Gemini 1.5 Pro successfully completed all the tasks asked of it, but not particularly quickly. Each took between ~20 seconds and a minute to process
Assuming 1M tokens in 60 seconds on a 64-layer model with
3
8
110
This you? We ran your show-case example 3 times on Together playground, and it infinitely looped or answered incorrectly every time. Curious how that slipped through all 5 steps of your quality testing 🤔
Other examples from your blog fail to reproduce too. 🧵

Recently there has been considerable discussion on differences in quality when different inference providers use different implementations of Meta's Llama 3.1 models.
In the blog post below, we investigated these differences and what they mean to real-world applications. Then,

9
21
122
5
10
111
In other words, AGI is even closer now as it doesn’t have to suffer from thread contention :)

4
4
94
We’ve been cooking!
Up to 300 tokens/s for Mixtral (and still fast with long prompts!)
Reduced pricing, simplified billing, dedicated deployments and more.
Enjoy!

Happy March! Fireworks is announcing our Spring 2024 platform updates - designed for improved production usage at scale. 🧵
💨Faster, more prod-ready serverless models - Mixtral Instruct and Llama 70B have become even faster, with speeds up to 300

2
8
51
6
10
96
Highlights of
@PyTorch
in 2021. Huge thanks to the community for making it awesome! Onwards to 2022!

0
17
97
In short, no-GIL allows Python leverage modern hardware much more naturally.
The implementation of this PEP is brilliant too: biased reference counting is neat. Definitely worth a read:

1
5
95
GIL has been in Python from the beginning. It ensures that only a single Python instruction can execute at any given time. Very convenient and safe - Python just can’t crash on memory corruption from a data race like C++ often does. But pure Python gets barely faster with threads
1
4
83
We’re pushing Mixtral performance to the extreme with fp8, fully custom attention kernel and MoE specific tricks (sometimes 3 experts is better than 2!).
Getting sweet 2x speed up & throughout increase at virtually same accuracy compared to fp16 and 4x+ improvements over vLLM.
What's the most performant way to serve Mixtral and other open-source MoE models? Fireworks investigated this topic and came up with our proprietary serving stack with 4x the speed compared to vLLM and negligible quality impact! Read about our findings here

7
19
176
1
9
72
GPUs keep getting faster and keeping even a single one busy from python is often a challenge (hence torch.compile and friends). This made driving many GPUs from a process slow: DataParallel -> DistributedDataParallel switch

2
5
63
GIL makes deployment for inference hard. Even if model is fast enough for serving in Python, some level of concurrency is needed. And multiprocessing is very intrusive. We built torch::deploy/multiply to deal with it, but it needs separate Py build

1
2
57
Data preprocessing is often heavy on Python, that’s why DataLoader in PyTorch uses multiple processes for num_workers > 0. But it comes with its own complexities like

1
3
55
I’m all pro open benchmarks, but comparing **public** LLM endpoints just doesn’t work unless there’s a confirmed huge user base like OpenAI. In fact, performance may be even anti-correlated with popularity😉 Here’s why 🧵

📈We’re excited to introduce the LLMPerf leaderboard: the first public and open source leaderboard for benchmarking performance of various LLM inference providers in the market.
Our goal with this leaderboard is to equip users and developers with a clear understanding of the

10
39
161
3
3
52
Really impressive model and infra co-design for efficiency from
@character_ai
(congrats
@NoamShazeer
@myleott
and the team). We've seen similar great wins from some of them at
@FireworksAI_HQ
:
1) Many tricks to shrink KV cache: MQA (instead of even GQA), share KV across layers,

Character AI is serving 20,000 QPS. Here are the technologies we use to serve hyper-efficiently. [ ]
32
200
1K
0
2
51
Not all LLM APIs are created equal...
The new Llama 3.1 405B Instruct is on
@FireworksAI_HQ
- ready for building!


3
3
47
@francoisfleuret
@numpy_team
@PyTorch
If one wants to understand it visually, this visualizer by
@ezyang
is really handy:
0
3
44
Llama 3.1 405b can go even faster with
@FireworksAI_HQ
. We don't have a consumer web search product, but our LLM API is open for
@perplexity_ai
or everyone else to build with

Llama 3.1 405b now runs faster on Perplexity with fp8 inference (both weights and activations).
21
39
550
8
5
43
When comparing the speed of LLMs inference, how long should the prompts and completions be?
Current leaderboards from
@ArtificialAnlys
or
@withmartian
use 3:1 prompt:completion ratio. But real-world use cases are 10:1 or even 30:1. Speed and cost differences can be dramatic!
I



2
3
39
@MistralAI
@thefireworksai
Disclaimer: there's no official model code yet. Based on parameter names and the fact that Mistral team contributed to I assume that it uses simple MoE (for inference).
Generation looks coherent, so there's a good chance it's correct.

1
1
35
The new model Mixtral 8x7B has ~47B parameters (a bit less than 8x7B=56B). Each token uses only a subset of those - approximately 25% (2 experts out of 8).
But when running multiple requests in the same batch, different requests will activate different experts! 2/7

3
1
33
Mixtral 8x7B speed-ups are in at
@thefireworksai
: up to 175 token/s from our engine (~100 t/s in the playground) and a new pricing tier at $0.45-0.6/M tokens
Check the blog on how we raced to be first to enable Mixtral, 2 days before the official release!

2
6
34
Gemini 1.5 Pro is an impressive work. Sadly, the technical report is very very sparse on details. But this paper from yesterday gives a glimpse on how one may train for extra long context:

We are excited to share Large World Model (LWM), a general-purpose 1M context multimodal autoregressive model. It is trained on a large dataset of diverse long videos and books using RingAttention, and can perform language, image, and video understanding and generation.


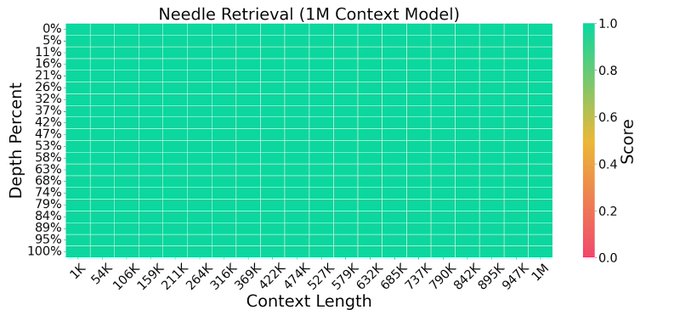
28
263
1K
2
2
32
PyTorch 2.0 is coming next March! Ful backward-compatibility. New 'torch.compile' one-liner for 50%+ speed-ups in training without changing model code.
It's a culmination of years of R&D on the compiler stack that can support your PyTorch code without compromising flexibility.

We just introduced PyTorch 2.0 at the
#PyTorchConference
, introducing torch.compile!
Available in the nightlies today, stable release Early March 2023.
Read the full post:
🧵below!
1/5
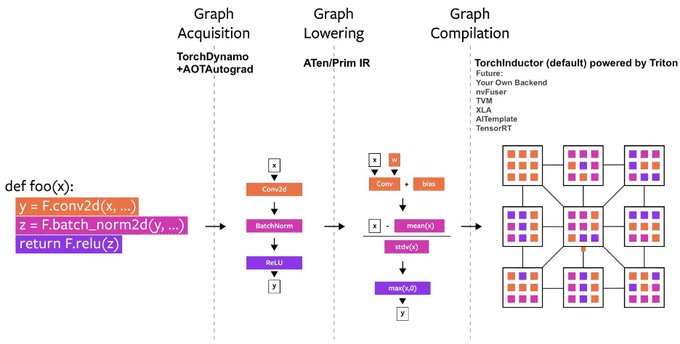
23
524
2K
0
1
25
Added --num-gpus to configure sharding. So 4x40GB cards work now too. I'm sure others will connect it to quantization in no time.
4
0
26
Joking aside, meta tensors are underlying mechanism to represent shape and dtype without allocating memory for storage. E.g. for shape propagation, or to implement torch.nn.utils.skip_init:
1
1
25
Check out what we've been working on for the past few months at
@thefireworksai
: fast and cheap serving for LLMs, including your own LoRA fine-tuned models.
Stay tuned for more technical deep dives soon.
P.S. It's fully free until we rollout billing and quotas :)
🚀 Launching the GenAI Platform: bringing fast, affordable, and customizable Large Language Models (LLMs) to developers. Use open-source foundation models and deploy your own LoRA adapters with up to 20–120x cost reduction. 1/9
5
30
157
0
1
24
But running a big batch comes with its own challenges: the model needs to be aggressively split into many GPUs. MoE brings more options here, like expert-level parallelism (check out for a good overview). 5/7

1
4
24
Function-calling or chat capabilities: why not both?
We cooked 🔥Firefunction-v2 to excel at general conversation and function calling simultaneously (many existing models struggle with it)
Served 2x faster and 10x cheaper than GPT-4o on
@FireworksAI_HQ
, open weights on HF

🔥 Firefunction-v2, new open-weights function-calling model🔥
I'm super excited to announce Firefunction-v2, our latest open-weights!
- Competitive with GPT-4o at function-calling
- 1/10 of GPT-4o cost and 2x the speed
- Retains both conversation and function-calling

17
72
339
2
4
23
@abacaj
And the plot thickens: someone from Mistral hints my original implementation was correct. It seems that the fix makes model finicky with formatting issues (e.g. adding the space).
I guess we will need to wait for the official implementation :)


2
0
23
Overall, it’s exciting to see MoE revival with Mixtral’s release. This class of models will benefit both local LLMs and highly loaded sophisticated server deployments like the one we’re building at
@thefireworksai
You can try Mixtral live on Fireworks:
We released our tuned Mixtral chat a few hours ago. Play with it through our app or API: . Big thanks to
@MistralAI
‘s new addition of this MoE model. We are very excited about it.
11
26
284
2
1
23
GPT-4 is rumored to use MoE too. It serves a lot of traffic and thus benefits from this regime. 6/7
i might have heard the same 😃 -- I guess info like this is passed around but no one wants to say it out loud.
GPT-4: 8 x 220B experts trained with different data/task distributions and 16-iter inference.
Glad that Geohot said it out loud.
Though, at this point, GPT-4 is
57
388
2K
1
1
22
If one can fit a big batch with many requests in a GPU the situation changes. Speed now mostly depends on how many multiplications (FLOPs) are done. Mixtral MoE still does only 25% of those, and we can expect speed up to approach 4x. 4/7
2
1
21
More perf wins: SDXL and Playground image gen models are now 40% faster AND 35% cheaper on
@FireworksAI_HQ
. Pure system optimization - the quality and # steps is the same.
And SD3 Medium via our partnership with
@StabilityAI
is coming soon too.

Congratulations
@FireworksAI_HQ
on improving the speed of their Text to Image model APIs!
Fireworks has reduced generation time by ~40%, from ~2.8s to ~1.7s for Playground v2.5 and ~1.9s to ~1.2s for SDXL. Fireworks has also reduced prices ~35%, positioning it amongst the

1
1
12
2
3
21
@marktenenholtz
@huggingface
It's even simpler, the original Falcon-7B code on HuggingFace has an interface bug that breaks incremental generation: you pass the prompt through the model for every incremental token. Notice `past` vs `past_key_values`...

2
5
20
@omarsar0
@GroqInc
@GroqInc
generation speed is indeed insane. But I found it struggle with long prompts. E.g. summarization of 12k tokens Tesla earnings took 3.5s server time on Groq (5s with queuing) but only 2s with good old GPUs
@FireworksAI_HQ
(with loaded servers).
LLM latency usually adds


2
2
20
New Llama 3.1 models, including the mighty 405B that rivals GPT-4 (while being open-weights) are on Fireworks at just $3/M tokens!
Try it in the playground or start building with API today.


🚀 Exciting news! Fireworks AI is one of the first platforms to offer Llama 3.1 for production use from day one in partnership with
@AIatMeta
. With expanded context length, multilingual support, and the powerful Llama 3.1 405B model, developers can now leverage unmatched AI

8
18
108
1
1
20
LLaMA2 is out!
- commercial license 💰
- chat tuned 💬
- 1.4T -> 2T of tokens, fresh data from 2023 📚
- 2k -> 4k context, RoPE frequency scaling still works 📏
- Grouped/Multi Query Attention for efficient inference 🏎
On last point, our blog covers MQA/GQA being a big deal
1
2
19
@besanushi
@OpenAI
Even on the same GPU numerics can be slightly different depending on which CUDA kernel is launched. cuBLAS matmul can return different results depending on batch size! Sparsity or MoE tend to amplify even smallest differences.
And across different GPUs all bets are off.
1
0
18
Just fixed ambiguous MoE implementation. It gives much better results. Thanks to
@abacaj
and bjoernp for comparing both versions!
Also, you can try the fix live at now!

2
1
19
The first blog about LLM inference optimizations we're doing. Stay tuned for more
0
1
19
@cHHillee
This is cool!
However, Mixtral MoE is particularly susceptible to the “optimized throughout != optimized latency” caveat.
Even a modest batch size activates all 4 experts and slows down generation ~4x. While BS=1 is too costly.
My earlier explainer:
@MistralAI
model is hot: with mixture-of-experts, like GPT-4!
It promises faster speed and lower cost than model of the same size and quality
Fascinatingly, the speed-up is unevenly distributed: running on a laptop or the biggest GPU server benefit the most. Here’s why 🧵 1/7
7
87
465
1
2
19
Great work on prompt caching with RadixAttention from
@lmsysorg
. We have been running similar implementation in production at
@FireworksAI_HQ
for a few months delivering wins to customers:
Rare case I got to write a Trie outside of programming contests :)

We are thrilled to introduce SGLang, our next-generation interface and runtime for LLM inference! It greatly improves the execution and programming efficiency of complex LLM programs by co-designing the front-end language and back-end runtime.
On the backend, we propose

54
175
835
0
1
19
Gemma 2 is looking really good and it's now live on
@FireworksAI_HQ
! The same day it was released.
I suspect something is off with
@huggingface
's implementation. In our evals, the Fireworks version gets 71.2% (base) / 72.2% (instruct) on MMLU, matching the announcement blog at

Gemma 2 9B is now on Fireworks! We're the first hosted provider (to our knowledge) to offer Google's latest open-source LLM. Try Gemma 2 in our UI playground or via our OpenAI-compatible API!


4
5
46
3
0
18
@AravSrinivas
Not really peerless if you extend the graph to today :)
That said, Perplexity is an amazing product!

0
1
18
Happy Birthday to
@PyTorch
and huge thanks to the community! Personally, it's been a fun and rewarding journey helping
@PyTorch
grow and empower AI developers from research to production. Excited for the future, we're just getting started!
Today marks 5 years since the public release of PyTorch! We didn't expect to come this far, but here we're🙂- 2K Contributors, 90K Projects, 3.9M lines of "import torch" on GitHub. More importantly, we're still receiving lots of love and having a great ride. Here's to the future!

62
457
3K
0
2
18
For a small batch, speed is determined by how quickly the GPU can read weights from memory.
For a single request (llama.cpp on a laptop), reading 2 out 8 experts is 4x faster.
Add a small concurrent load, and most of the speed-up evaporates: all experts have to be loaded. 3/7

1
1
16
@MistralAI
@thefireworksai
Per Mistral's comment on their Discord updated RoPE's theta to 1e6 in the repo
2
0
17
Deep dive into how to make LLM generation fast with CUDA graphs while still keeping your model code nimble in python. It's one of the many optimizations behind our inference engine at Fireworks.
The Fireworks Inference Platform is fast, but how? An important technique is CUDA graphs, which can achieve a 2.3x speedup for LLaMA-7B inference. Learn about CUDA graphs, complexity applying them to
#LLM
inference, and more in our new deep dive. 1/6
1
10
47
0
1
15
Excited to see many awesome community members in person at
#PyTorchConference
tomorrow! Some major announcements are coming too…

0
3
16
Fine-tuning from
@FireworksAI_HQ
goes beyond training: it's paired with our serverless inference.
You can iterate on 100s of model variants quickly while paying per token only, no time-based or fixed costs.
Supports many models, incl Mixtral. And it's fast too (as always).
🔥 We’re excited to announce
@FireworksAI_HQ
fine-tuning service! Fine-tune and run models like Mixtral at 300 tokens/sec with no extra inference cost!
🔁 Tune and iterate rapidly - Go from dataset to querying a fine-tuned model in minutes covering 100+ models.
🤝 Seamless

12
31
179
0
0
14
@marktenenholtz
@huggingface
And TGI doesn't run Multi Query Attention yet, just broadcasts. Falcon is unique among open models to have MQA today btw. With special optimizations for MQA the numbers look even better for the inference service we're building at
0
2
15
This is just verifying the "spotlight" queries. Other claims raise red flags about doing “good science” too.
Evaluating LLM quality is notoriously difficult and I hope we can do better as a community. Stay tuned for a deep dive into quantization quality metrics in our blog.
0
0
15
@ezyang
@MaratDukhan
Doesn’t it break before the comparison? I.e. just loading the literal …993. causes it’s value to change
1
0
15
This you? We ran your show-case example 3 times on Together playground, and it infinitely looped or answered incorrectly every time. Curious how that slipped through all 5 steps of your quality testing 🤔
Other examples from your blog fail to reproduce too. 🧵
5
10
111
0
0
14
@StasBekman
This needs to come from NVIDIA low level support. MSR folks claim they built something like this by intercepting and replaying cuda driver calls: (awesome idea!). But I haven’t seen anything available/open source.
2
0
14
@francoisfleuret
There is!
This injects a hook in PyTorch dispatcher that runs after any operator (regardless of where it’s called from)
That repo has a lot of other tricks like it.

0
2
14
@MistralAI
I hacked up official Llama repo to load and run it. Results seems coherent
Run
@MistralAI
MoE 8x7B locally with hacked-up official Llama repo!
First cut, not optimized, requires 2 80GB cards.
The optimized version is coming soon to
@thefireworksai
. Stay tuned!
14
60
467
0
1
11
The White House wants you to use Rust :)

0
1
13
@togethercompute
I tried the exact same settings (temp=0) this morning and got infinite looping (see the video in the original thread). I tried it now and I get the correct answer vs looping 50% of the time.
It looks like temp=0 is not fully deterministic in your engine
1
0
14
@aidan_mclau
@sualehasif996
@teortaxesTex
@GroqInc
@FireworksAI_HQ
We’re cooking support for it at Fireworks, stay tuned
2
0
14
@ezyang
Root cause is tight computation interdependence of SGD: you want many steps and each depends on the prev fully. More like HPC (akin to ODE solver) than MapReduce. Asynchronicity (like AdaDelay)/huge batch (close to epoch) turned out to give worse quality.
2
4
13
Benchmarking speculative decoding for LLMs is fun but unintuitive. To report performance, people usually fix model size, server load, prompt, and generation length. With speculative decoding, however, *what text* you generate matters too (not just length). 1/8

2
7
13
It was really fun to work with
@cursor_ai
on making big code rewrites reliable and fast - and make the great product even better


.
@cursor_ai
trained has trained a specialized model on the "fast apply" task, which involves planning and applying code changes.
The fast-apply model surpasses the performance of GPT-4 and GPT-4o, achieving speeds of ~1000 tokens/s (approximately 3500 char/s) on a 70b model.

0
4
34
0
0
13
Unlike regular services (e.g. DB or webserver) LLM workload batches really well. So there’s a strong inverse relationship between load (popularity), speed and cost. Model size, prompt and generation length and even request arrival time all impact results
1
0
12
Join in on Dec 1&2 for the virtual PyTorch gathering. I’m giving the “State of PyTorch 2021” keynote recognizing awesome features and contributors. Many exciting talks lined up from the community too!
0
3
12
HF truly became foundation infra of ML world. I wonder how many other services and particularly CIs are down now because they can’t download the models.
Sending 🤗
P.S. is working normally

We're having some infra issues; we're working on it. Please send hugs! 🤗
In the meantime,
import os
os.environ['HF_HUB_OFFLINE']=1
125
56
626
1
0
12
@cbalioglu
is building an upcoming
@PyTorch
feature to do model parallelism partitioning on modules larger than one gpu which is based on meta tensors too:

1
1
11
Latest goodies for training ranking/recommendation models in PyTorch. Scaling to trillions of params and 100s of GPUs.
Compared to "trillions" in LMs, rec models are "sparse" with a lot of nn.EmbeddingBags. Thus special parallelism primitives that TorchRec provides.
Introducing TorchRec, a PyTorch domain library for building and deploying modern production recommendation systems, enabling multi-trillion parameter models. Learn more:
0
76
313
0
2
11
LLMs can play Doom!
Amazing team
@SammieAtman
,
@hopingtocode
and Paul used
@FireworksAI_HQ
fine-tuning and serving to teach 7B LLM to play Doom from ASCII screen capture. They did it overnight and won first place at SF Mistral hackathon! See more in their guest blog below.
🚨 New Blog Alert 🚨
Find out how a group of Gen AI enthusiasts used
@FireworksAI_HQ
to make a LLM play DOOM, a video game created in 1993 that has gained cult status among hackers at Mistral SF Hackathon!
Special thanks to Bhav Ashok (
@SammieAtman
),
@hopingtocode
, and Paul

0
6
22
1
1
12
So what can we do as a community? The only meaningful comparison is using fixed hardware (which usually means dedicated deployments).
Doing the right benchmark is really tricky too. What we learnt at
@FireworksAI_HQ
is incorporated in our OSS suite:

1
0
12
@Suhail
TensorCore TFlops is what matters, but the ratio was the same for A100->H100: 312 -> 989 (NVIDIA claims 1979 but it’s fake sparsity marketing).
Also important is memory bandwidth. It went only 2 -> 3.35 TB/s. Makes it harder to utilize those flops on H100.
1
0
11
@cbalioglu
@PyTorch
Torch operators can take meta tensors and produce meta tensor results with correct shape & dtype. The new way to write 'structured kernels' allows to get an operator working on meta and a real device in one go.

0
1
10
@jeffboudier
Great work, fp8 is fast!
But why report numbers at batch 4?! It’s highly misleading as the actual speed is 300 token/s. And if throughput - then 1.2k/s is very low, one can just increase batch to 64/128/etc
2
0
11
Structured output and function calling major update at
@FireworksAI_HQ
🔥
🛠 FireFunction V1: OSS model tuned for tool use at GPT-4 level (agents, routing...)
✅ guaranteed JSON schema for any model
🧐 beyond JSON: custom grammar guidance for any model (YAML, multi-choice...)
🔥 Structure is all you need. 🔥
We’re excited to announce:
- FireFunction V1 - our new, open-weights function calling model:
- GPT-4-level structured output and decision-routing
at 4x lower latency
- open-weights, commercially usable
- Blog post:

15
105
560
1
0
10
Check our new function-calling model ☎️ and API on
@FireworksAI_HQ
.
Blog covers why evaluation of functions is tricky (our curated hard dataset is on HF) and fine-tuning journey to get GPT4-level quality (no training on test set!).
More to come!
Fireworks is excited to raise the quality bar by launching our function calling model and API as an alpha launch! We’ve fine-tuned a model specifically to reliably call APIs, even when provided with multi-turn context and numerous functions! In our evals, we achieved accuracy on

9
12
160
1
0
9
Amazing, programming & math olympiads might go the way of Chess and Go sooner than expected.
Neat idea of solution sampling:
- pass example tests (~0.5% solutions only)
- generate random inputs
- pick solution cluster that agrees on them
Akin to human brute force at scale!

Introducing
#AlphaCode
: a system that can compete at average human level in competitive coding competitions like
@codeforces
. An exciting leap in AI problem-solving capabilities, combining many advances in machine learning!
Read more: 1/

173
2K
8K
1
1
8
@skirano
@perplexity_ai
We've got the chat fine-tuned version at
@thefireworksai
: . The mixtral's poetry could be a bit better, though :)
The bot based on this model is coming to
@poe_platform
in a couple of hours too.

3
1
9
At extreme, I can start a new service, spend some $ on a 8xH100 for a 7B model and win all benchmarks. No one is using it so the batch size is very small.
Popular services like OpenAI can’t afford to run huge traffic on expensive hardware all the time.
2
0
9
Example: AI researcher question ���What is group query attention?”
Claim: Factually correct, and detailed answer
Reality: The answer implies that GQA is some form of sequence-sparse attention. However, GQA is a form of multi-head attention where query projections are shared

2
0
9
LLaVA is an awesome idea to extend LLMs to see images. Original models from October were trained on GPT-4 outputs and thus can’t be used commercially.
We trained FireLLaVa based on OSS LLMs so it’s good for commercial use. Try it at or download from HF.
🔥🔥Announcing FireLLaVA -- the first multi-modal LLaVA model, trained by
@FireworksAI_HQ
, with a commercially permissive license. It’s also our first open source model!
While the industry heavily uses text-based foundation models to generate responses, in real-world

10
61
344
0
0
9


0
1
7
There's still much to learn about running Mixtral (and mixture-of-experts models broadly) and how they interact with low precision/quantization.
A surprising finding from
@divchenko
: for fp8, running more experts seems beneficial!
Mixtral: one more expert to break the tie
Mixtral has 8 experts, but only 2 are active for each token. Do more than 2 help?
Surprisingly, it helps in fp8, but in original 16 bit precision. With this trick, fp8 can almost match fp16 on MMLU! Why is that? 1/5

4
22
147
0
1
8
@soumithchintala
Congrats to former
@MetaAI
colleagues for another awesome model!
We just enabled it at
@thefireworksai
, try it for free
0
0
7
@HamelHusain
It’s batch size 1 - results are dominated by mem bandwidth. Quantization matters the most. Hence exllama and mlc are on top with 4bit. Other kernels aren’t very or run in higher bits
Check quality. 4 bit is tricky. Varying number of tokens is a red flag that models differ a lot
0
0
8
Onnx vs Onyx, even the logo is similar 🧐
Naming programming concepts is hard. At least I was onnx-ing before it went mainstream


1
0
8
@ezyang
And lack of cross pollination is not for the lack of trying. Much Google early stuff in 2010s was about async dist stuff - DistBelief, TF1. Just look at focus on param servers in TF1 paper. MoE and various routing is similar dist ideas (sharding) - maybe it’s getting a comeback
1
1
7
And it's live on in the playground or for API access.
@MistralAI
8x7B is live on Fireworks. Try it now at
Warning: this is not an official implementation, as the model code hasn’t been released yet. Results might vary. We will update it once Mistral does the release.
More perf improvements are landing soon

9
34
162
0
1
6
“Implement Wordle” should totally be on leetcode. Implement the game as a warmup, optimal solver as a hard one
1
0
7
Example: math question.
Claim: Together gets to the right answer (648), other providers loop forever
Reality: Together’s own playground loops forever. It fails consistently at temp=0 and quite often at temp=0.7. You can get the right answer at Fireworks.
1
0
7
@abacaj
Turns out the fix is correct, i.e. softmax+topk. The reference HF code has topk+softmax+renormalize which is the same thing: softmax of a subset of variables differs only by normalization factor.


1
0
7
@burkov
We’re building one at . There are Llamas, Falcons, etc with per token pricing. And we can serve your LoRA for the same price too.
2
0
6
@DynamicWebPaige
@MistralAI
@perplexity_ai
You can go faster: ~100 tokens/sec on a single GPU. And >300 tokens/sec with a more optimized setup.

0
2
6
@sualehasif996
@aidan_mclau
@teortaxesTex
@GroqInc
@FireworksAI_HQ
Nice, thanks for the link. I was working out the same thing. After premultiplying projection is becomes MHA more or less but with RoPE mini head on the side
1
0
5