
Artificial Analysis
@ArtificialAnlys
Followers
9,228
Following
405
Media
170
Statuses
368
Independent analysis of AI models and hosting providers - choose the best model and API provider for your use-case
San Francisco
Joined January 2024
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Internacional
• 116292 Tweets
Karol G
• 106194 Tweets
土用の丑の日
• 59450 Tweets
ゲリラ豪雨
• 39272 Tweets
デッドプール
• 36779 Tweets
Ingat
• 32585 Tweets
Mets
• 32548 Tweets
Saint Dr MSG Insan
• 28135 Tweets
ジェシー
• 27300 Tweets
Guru Purnima Celebration
• 26643 Tweets
#CarinaPH
• 24528 Tweets
O Inter
• 20777 Tweets
Toy Bank
• 19670 Tweets
Renê
• 17451 Tweets
Boone
• 10732 Tweets




















Pinned Tweet

Thanks for the support
@AndrewYNg
! Completely agree, faster token generation will become increasingly important as a greater proportion of output tokens are consumed by models, such as in multi-step agentic workflows, rather than being read by people.

Shoutout to the team that built . Really neat site that benchmarks the speed of different LLM API providers to help developers pick which models to use. This nicely complements the LMSYS Chatbot Arena, Hugging Face open LLM leaderboards and Stanford's HELM
59
506
2K
1
9
44
GPT-4o Mini, announced today, is very impressive for how cheap it is being offered 👀
With a MMLU score of 82% (reported by TechCrunch), it surpasses the quality of other smaller models including Gemini 1.5 Flash (79%) and Claude 3 Haiku (75%). What is particularly exciting is

31
164
1K
OpenAI GPT vs. Google Gemini 🏆
With two model releases this week we compare the model portfolios across quality, price, speed & context window. 👇
Quality: GPT-4o is the clear-winner, extending its lead over Google's lead model Gemini 1.5 Pro. The key stand out note is that

2
5
174
Congratulations to
@MistralAI
on reducing latency (time to first token) by up to 10X on their API!
Mistral have reduced latency (on their own API) from up to 11 seconds down to sub-1 second.
This is especially important as Mistral’s API is the only place to get Mistral Medium

11
23
243
First throughput tokens/s benchmarks of Llama 3 🐎
@GroqInc
is coming fast out of the gate with 284 tokens/s on Llama 3 70B and 876 tokens/s on Llama 3 8B.
Once-again showing the step-change speed benefits of their custom LPU chips.
Congratulations to other providers too,

10
30
225
430 tokens/s on Mixtral 8x7B:
@GroqInc
sets new LLM throughput record
Groq has launched its new Mixtral 8x7B Instruct API, delivering record performance on its custom silicon. Pricing is competitive at $0.27 USD per 1M tokens, amongst the lowest prices on offer for Mixtral 8x7B.

3
29
181
240 tokens/s achieved by
@GroqInc
's custom chips on Lama 2 Chat (70B)
Artificial Analysis has independently benchmarked Groq’s API and now showcases Groq’s latency, throughput & pricing on
This represents a milestone for the application of custom silicon

10
32
134
Artificial Analysis has independently benchmarked
@SambaNovaAI
's custom AI chips at 1,084 tokens/s on Llama 3 Instruct (8B)! 🏁
This is the fastest output speed we have benchmarked to date and >8 times faster than the median output speed across API providers of
@Meta
's Llama 3

7
48
127
Models from AI labs headquartered in China 🇨🇳 are now competitive with the leading models globally 🌎
Qwen 2 72B from
@alibaba_cloud
has the highest MMLU score of open-source models, and Yi Large from
@01AI_Yi
and Deepseek v2 from
@deepseek_ai
are amongst the highest quality

7
19
119
We're bringing our benchmarking leaderboard of >100 LLM API endpoints to
@huggingface
!
Speed and price are just as important as quality when building applications with LLMs. We bring together all the data you need to consider all three when you need to pick a model and API

7
35
107
Testing
@AnthropicAI
's claims of "fastest and most affordable" model of its class: Comparing to 7B models & GPT-3.5, Claude 3 Haiku indeed occupies an attractive price & speed position.
Its price (bubble size) is lower than GPT 3.5 turbo, however is at a premium to the open


Today we're releasing Claude 3 Haiku, the fastest and most affordable model in its intelligence class.
Haiku is now available in the API and on for Claude Pro subscribers.
150
384
2K
4
13
106
OpenAI’s Whisper Speech-to-Text model can now be accessed 6X faster and 12X cheaper than on OpenAI’s API. This means all 25 hours of the Star Wars movies can be transcribed in ~7 minutes and ($0.5 per 1k minutes) and for ~$0.75 (that’s right, less than $1).
@GroqInc
released

1
15
103
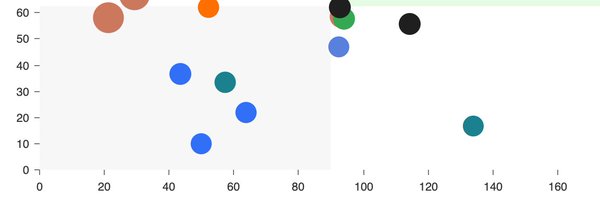
fal has launched 'Wizper', their new Whisper v3 offering and it blows past previous speed factor records with ~250X real-time audio speed 💨
Near-instant transcription opens-up new use cases for natural-feeling voice chatbots and
@fal
's Wizper is the fastest option currently
3
18
98
Announcing the first independent Speech to Text leaderboard 🚀
Artificial Analysis is now benchmarking 14 open source and proprietary endpoints across their Word Error Rate, Speed Factor and Price.
Transformer-based speech to text models have ignited a new race toward beyond

9
19
92
814 tokens/s on Gemma 7B - New speed record in LLM Inference APIs by
@GroqInc
🏁
Groq has launched their Gemma 7B API and Artificial Analysis has independently benchmarked 814 tokens/s throughput.
Groq is also competitively priced, charging $0.1/M tokens, in-line with the

2
13
88
Gemini 1.5 Flash has earned its name, it is very fast ⚡️
Artificial Analysis has commenced benchmarking and relative to similar models in its quality band (Claude 3 Haiku, DBRX, Mixtral 8x7B), Flash is fast at ~160 tokens/s.
This could be driven by model architecture decisions

7
21
82
Groq is now reporting ~1,150 tokens/s on Llama 3 8B in its chat interface!
We look forward to confirming these results on
@GroqInc
's API over the coming days and seeing the tokens/s over time line chart go up and to the right ↗️. If so, this would represent the fastest language

7
11
79
Our independent analysis of LLMs & API hosts has been featured on the
@theallinpod
!
Interesting discussion regarding the trade-offs that exist between quality, speed (both throughput & latency) and price.
@chamath
's learnings & anecdotes from his time at Facebook and

E165:
@friedberg
's return
(0:00) bestie intros!
(2:08) apple vision pro breakdown
(20:46) $META vs $SNAP: god-king ceos, ad revenue dependency, drastically different performance
(32:53) SaaS bounceback signals
(41:06) VCs are split into three camps on how to approach AI
125
54
741
8
5
76
From GPT-4 to Mistral 7B, there is now a 300x range in the cost of LLM inference 💸
With prices spanning more than two orders of magnitude, it's more important than ever to understand the quality, speed and price trade-offs between different LLMs and inference providers.

3
20
73
Fireworks AI has supercharged their Mixtral 8x7B offering impacting 3 critical metrics
‣ Optimized throughput and are now achieving up to 200 tokens/second, second only to Groq
‣ Reduced output token pricing to 1/3 of previous pricing. Now charging $0.5/M input & output



15
9
69
Fast to launch & very fast output speed! Groq has launched their Gemma 2 9B offering and is serving it at ~600 output tokens/s
Gemma 2 9B is worthy alternative to Llama 3 8B and other smaller models. It is particularly attractive for generalist and communication-focused

4
22
70

Launching our LLM Leaderboard with 60+ model & API host combinations 🚀
This is the most comprehensive view of LLM inference performance available to date
Our leaderboard offers a single page to compare models & API hosts across metrics including quality, throughput, latency,

2
20
67
Up to 60% jump in Mistral 7B throughput on
@perplexity_ai
&
@FireworksAI_HQ
Mistral 7B is a high performance 7B-sized model that delivers impressive output quality compared to other models of its size.
For use-cases where even GPT-3.5 Turbo is is too slow or expensive, Mistral

4
6
67
Baseten launches Mistral 7B API with leading performance 🚀
@basetenco
has entered the arena with their first serverless LLM offering of Mistral 7B Instruct. Artificial Analysis are measuring 170 tokens per second, the fastest of any provider, and 0.1s latency (TTFT) in-line

4
8
64
GPT-4, GPT-3.5 & Mistral Medium speed and quality relative to
@GroqInc
Seeing great discussions regarding potential use-cases for Groq's speed. Mixtral 8x7B on Groq offers a step-change in speed vs. GPT-4 & Mistral Medium, is cheaper (bubble size) and the trade-off is a lesser

5
11
63
Excited to launch - providing performance benchmarking and analysis of AI models and API hosting providers.
We’re here to help people/orgs choose the best model and provider for real AI use cases.
Should you be using GPT-4 on Azure or Mixtral on

5
20
63
Groq extends its lead and is serving Llama 3 8B at almost 1,200 output tokens/s!
@GroqInc
's Llama 3 8B speed improvements seen in their chat interface we can now confirm are reflected in performance of their API. This represents the fastest language model inference performance

5
10
60

GPT-4o breaks away from the quality & speed trade-off curve most LLMs follow ✂️
‣ GPT-4o not only offers the highest quality, it also sits amongst the fastest LLMs
‣ For those with speed/latency-sensitive use cases, where previously Claude 3 Haiku or Mixtral 8x7b were leaders,

4
10
52
GPT-4o delivers output speed of 109 tokens/s in first independent benchmark
This makes GPT-4o:
• Over 5x faster than GPT-4 Turbo (~20 tokens/s)
• Approximately twice as fast as GPT-3.5 (~55 tokens/s)
This is a major leap forward in performance and cost for a frontier-class

2
12
52
Grok-1 is now the highest quality open-source LLM
Grok's declared MMLU score of 73% beats Llama 2 70B’s 68.9% and Mixtral 8x7B’s 70.6%. At 314 billion parameters, xAI’s Grok-1 is significantly larger than today’s leading open-source model.
@xai
's Grok-1 is a Mixture-of-Experts

3
7
51
@GroqInc
now generally available after having been waitlist-restricted!
3 use-cases which benefits from Groq's high throughput:
- Capturing and holding user-attention (e.g. Consumer apps),
- Multi-step prompting (e.g. RAG re-ranking),
- High volumes of requests


3
7
44
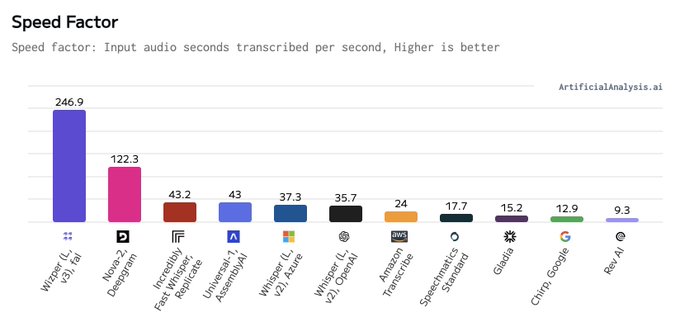
Announcing our Text to Image Benchmarking & Leaderboard! 🚀
It is the most comprehensive benchmarking of image models and providers yet with >25 endpoints benchmarked 4 times daily and leverages our own crowdsourced quality eval.
Highlights:
✅Quality: Model quality is evaluated
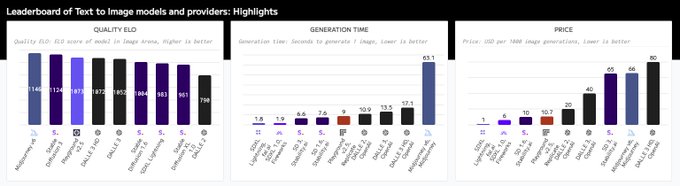
3
11
44

We are now benchmarking
@fal
's Speech to Text Whisper endpoint and it is setting new standards in Speed Factor and Price!
fal has raised the bar with a Speed Factor of 105 (105x real time), making it an attractive option for use-cases requiring fast transcription (meeting notes
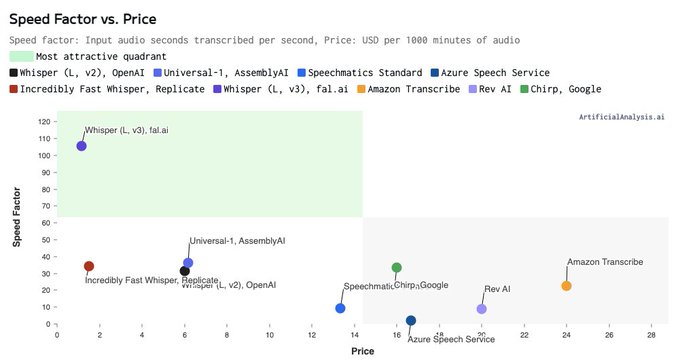
8
6
40
Breaking down the most important chart in Jensen’s Keynote and the implications for GPT-4 tokens/s
A trade-off exists between total system throughput (tokens per second delivered by the whole system to all users) and single-user throughput (tokens per second seen by a single

2
6
40
GPT4o sets a new record in quality and is 1/2 the price of GPT-4 turbo
Initial takeaways relating to the API:
- New MMLU record reached, 88.7%, ~1ppt higher than Claude 3 Opus's 86.8%
- Available via the API now. Half the price of GPT-4 at $5/M input tokens and $15/M output


2
8
40
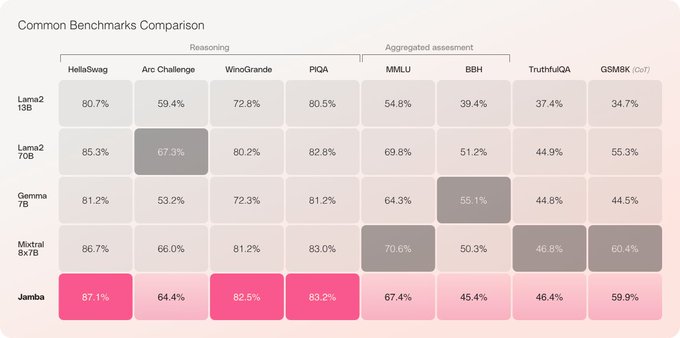
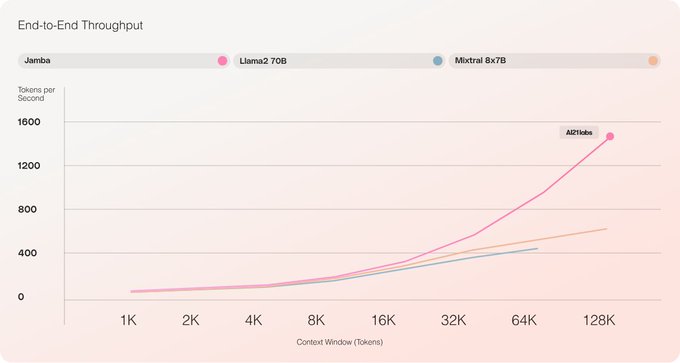
Jamba model launch takeaways - Potentially a new leader for ultra-long prompt use-cases (RAG)
‣ First open-source model of this size to combine MAMBA state-space model architecture, Mixture-Of-Experts (MOE) and the transformer
‣ 256k context window, more than 2X the size of
0
10
39
Jensen Huang's FP4 vs. FP8 comparison was not 🍏to🍏 so we have done our own comparison of the new B200
Comparing expected B200 specifications to the H100:
- Compute: +150% TFLOPs increase for FP8/16
- Memory: +140% to 192GB of memory (fit a 70b model in FP16 on a single B200)
-

2
5
33
Stable Diffusion 3 Medium is out! We’ve benchmarked performance on Stability, Replicate and Fal!
We’ve also added SD3 Medium to our Image Arena to evaluate the quality of the model - see the below tweet to contribute! Let’s see how it compares to SD3 Large and SDXL.
This is the

1
11
37
We’ve just added
@LeptonAI
to our independent performance benchmark for serverless LLM APIs - and it's showing some impressive results!
Lepton is now leading on Tokens per Second throughput for
@MistralAI
's Mixtral 8x7B Instruct. It is the only Mixtral hosting provider in our

2
6
34
Mistral has released NeMo, a new open-source, long context, smaller model as a successor to Mistral 7B. Why it is exciting below 👇
- Open source model with a 128k context window: Large context window open-source models have been few and far between and the most popular models,

2
6
35
Our Text to Image Leaderboard & Image Arena are now live on
@huggingface
!
Our leaderboard ranks models based on >45k human preferences gathered in the Image Arena. It features the leading open-source and proprietary image models including
@midjourney
,
@OpenAI
's DALL·E,

4
9
31
Small change, big impact! On the Artificial Analysis website you can now compare benchmarks of models on specific providers in our model comparison charts.
This allows you to dig deeper and to compare any model on any provider. Instead of picking models and then evaluating

3
5
30
@krishnanrohit
We have some more recent benchmarks of Groq performance too: 430 tokens/s on Mixtral 8x7B and 240 on Llama 2 70b. Seeing sustained performance over time as well

1
4
30
We now have a true challenger to GPT-4o. Anthropic has released Claude 3.5 Sonnet and established a leadership position on the price/quality curve.
Users of Claude 3 Opus should also consider 3.5 Sonnet for 5X cost savings and ~3X output speed increase.
Based on
@AnthropicAI
's

1
3
29
Nice one
@replicate
on lowering latency (time to first token) by 5X on their API!
Replicate has reduced their latency when using their OpenAI compatible API to sub-1 second, ~0.2s on avg, across all LLMs we benchmark, including Llama 3 70B & 8B.
Streaming API latency is

1
1
29
Mistral released Codestral Mamba and Mathstral 7B today! Key takeaways to be aware of and why they are exciting below 👇
‣ Smaller, task-specific models: These models are focused on Code and Math respectively and contribute to the trend of smaller models focused on specific

1
6
28
Announcing the Artificial Analysis Text to Speech leaderboard, including our Speech Arena to crowdsource our quality ranking!
We’re covering leading speech models from
@elevenlabsio
,
@OpenAI
,
@cartesia_ai
,
@lmnt_com
, Google, Amazon, Azure, along with open speech models like

4
8
29
GPT4o is ~4X faster than GPT-4 Turbo!
We benchmark GPT-4 turbo at ~20 tokens. This would imply ~80 tokens per second, in-line with Gemini Pro and Llama 3 70B across many providers.
We will benchmark GP4o and release results shortly over varied prompt lengths and across
2
5
28
First results from our Text to Image Arena 👀
Interesting results already from the first 5K responses to our Text to Image Arena released today.
@midjourney
is the clear favorite thus far with the newly released
@StabilityAI
Stable Diffusion, DALLE 3 HD and
@playground_ai
's

2
2
27
Congratulations to
@Speechmatics
on setting a new record in our Word Error Rate benchmark for Speech to Text models!
Speechmatics’ Enhanced model has achieved a Word Error Rate of 6.5%, the best result yet among the models we test. Accuracy is most important for use-cases

2
5
27
Cheaper, faster, better. Claude 3.5 Sonnet is directly competitive against GPT-4o for the position as the leading model for demanding use-cases.
@AnthropicAI
and
@OpenAI
releasing higher quality models while also at cheaper price points also shows the competitiveness of the AI

2
5
27
Artificial Analysis was featured again on the
@theallinpod
👀
Our analysis supported the discussion on
@GroqInc
's innovative LPU chip, the LLM speed step-changes it enables and the resulting attention it has generated.
Our independent assessments have supported this attention

E167: $NVDA smashes earnings (again), $GOOG's AI disaster,
@GroqInc
's LPU breakthrough & more
(0:00) bestie intros: banana boat!
(2:34) nvidia's terminal value and bull/bear cases in the context of the history of the internet
(27:26) groq's big week, training vs. inference,
149
107
859
3
2
26
Mistral has open-sourced a new model: Mistral 7B v0.2 Base!
What you need to know:
‣ This is the base model that the previously released Mistral 7B v0.2 Instruct model was fine-tuned from
‣ For most production LLM-use cases, Mistral 7B Instruct v0.2 is the better choice and

New release: Mistral 7B v0.2 Base (Raw pretrained model used to train Mistral-7B-Instruct-v0.2)
🔸
🔸 32k context window
🔸 Rope Theta = 1e6
🔸 No sliding window
🔸 How to fine-tune:
11
95
531
2
2
25
There is a 60x pricing spread between Anthropic’s Claude 3 models - here’s how it breaks down
Highlights:
‣ All three models have an output price that is 5x input price - this means that input-heavy use-cases will see lower overall cost than output-heavy use-cases with similar

2
3
24
Stable Diffusion 3 Medium has a Win Rate of 51% in our Image Arena and ranks in the middle of the pack
This means SD 3 Medium is not the highest quality open source base model available with
@playground_ai
's Playground v2.5 model ranking higher with an ELO of 1,096 and a Win

2
2
26
Is Nvidia looking to compete in LLM API inference with its NGC platform?
Nvidia is offering public LLM inference APIs for models like Mixtral 8x7B and Code Llama (70b) as a part of its ‘NGC’ ‘Enterprise AI Cloud’ software platform.
Performance is akin to other API providers

7
4
26
GPT-4o mini is fast 🏁. Our initial benchmarks measure 140 output tokens/s, ~1.8X faster than GPT 3.5 and GPT 4o
This positions GPT-4o mini as faster than models of comparable quality, including Anthropic’s Claude 3 Haiku, Mistral’s latest NeMo model, and the median speeds at

4
2
40
Text to Image Arena results at N=15,000 respondents
@midjourney
v6 remains in the lead, followed closely by
@StabilityAI
's Stable Diffusion 3.
Clear results showing that
@OpenAI
is not leading in the Text to Image modality with DALLE 3 trailing leading models. DALLE 2's

3
2
26
OpenAI announcement post:

0
6
28
Google's Gemma 2 27B model released today is now the leading open source model in Chatbot Arena while being 1/2 the size of others. Key takeaways & how they achieved this below 👇
⁃ Gemma 2 excelling on Chatbot Arena but lagging across other evaluations indicates its strength

0
5
26
We are launching coverage of a new AI Lab, Reka AI! We break down what makes
@RekaAILabs
& their models different below 👇
‣ Model portfolio: Reka has 3 models: Reka Core, Flash & Edge. Each have different quality, price & speed positions. Reka Core exceeds Llama 3 70B’s

1
5
23
We are starting to see multiple indications of an imminent Llama 3 launch by
@AIatMeta
🔭
Initial models look to include:
- Llama 3 70B Base & Chat/Instruct
- Llama 3 8B Base & Chat/Instruct
Interesting that here is no indication of much larger or MoE models as of yet


1
4
24
Microsoft has just released their Phi-3 Technical Report, describing a 3.8B parameter model that is competitive with Mixtral 8x7B
We look forward to the release of model weights and license details to assess Microsoft’s claims and understand how Phi-3 will impact the market.

2
1
23
Mixtral 8x22B is an exciting launch but is not yet ready for production use for most use-cases
The version of the model released by Mistral is the base model and is not instruct/chat fine-tuned.
This means that it isn’t designed for the prompt & answer style that most

2
2
23
'GPUs can't play this game like we can!'
This is the magic statement here. Today we've seen benchmarks and chat results of >1,000 tokens/s from both RDU-based
@SambaNovaAI
and LPU-based
@GroqInc
.
This is many times faster than Nvidia H100 performance. Non-GPU chips are moving

@ArtificialAnlys
@GroqInc
Plenty more room for
@SambaNovaAI
to optimize too, without running on hundreds of chips!
Looking forward to seeing what you come up with next
@GroqInc
! GPUs can't play this game like we can!
2
1
12
2
8
23
DBRX providers analysis: alongside Databricks, 2 other providers are already hosting DBRX!
Congratulations to
@databricks
,
@LeptonAI
,
@FireworksAI_HQ
on the quick-launch!
Lepton is leading in throughput with 125 tokens/s, ~6X GPT-4.
Lepton also has a price-leadership

3
1
23
Comparing Claude 3 to existing models - Quality vs. Price
Claude 3’s 3 Opus, Sonnet & Haiku models all occupy different price & quality positions.
Models generally follow existing price-quality curves present in the market but interesting take-aways exist amongst the Large,



1
3
21
Deep-dive into how Groq achieves its speed and detailed TCO comparison vs. Nvidia by Semianalysis
Excellent article from
@dylan522p
and
@dnishball
breaking down
@GroqInc
's inference tokenomics vs Nvidia:
“Groq has a chip architectural advantage in terms of dollars of silicon

5
8
20
SambaNova is now offering an API endpoint to access Llama 3 8B on its RDU chips, which we previously benchmarked at 1,084 output tokens/s
@SambaNovaAI
is also differentiating itself from other offerings by allowing users to bring their own fine-tuned versions of the models. They

Are you looking to unlock lightning-fast inferencing speed at 1000+ tokens/sec on your own custom Llama3? Introducing SambaNova Fast API, available today with free token-based credits to make it easier to build AI apps like chatbots and more.
Bring your own custom checkpoint for
0
8
25
1
5
21
Context window vs. Price across Claude 3 models - Attractive models for RAG considering their large context windows and low input-token prices
Larger context windows enable in-context RAG and can lessen the need for reliance on non-generative techniques including the use of

0
3
20
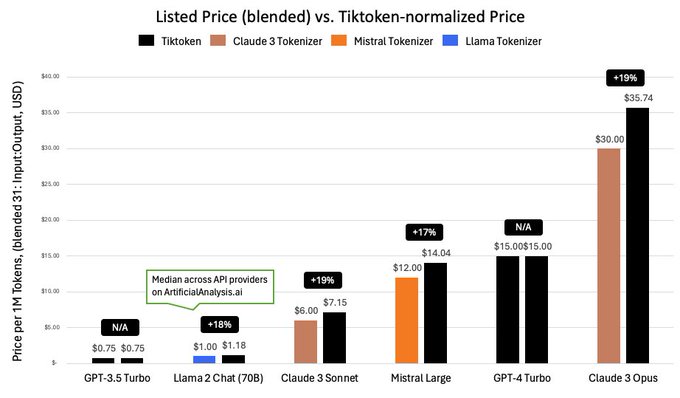
Per Token pricing is not always 🍏-to-🍏, when normalized provider pricing increases up to +19%
When tokenizing the same text, different tokenizers output a different number of tokens and therefore have different ‘tokenizer efficiency’. Because we pay per token, this means we
3
1
19
People are paying attention to SambaNova breaking 1,000 tokens/s!
@VentureBeat
and
@TechJournalist
reported on this today and refer to our independent benchmarks.
The article also deep-dives on the chip and explains their RDU technology. According to
@SambaNovaAI
's CEO, it

1
6
20
Link to our analysis of GPT-4o Mini:
1
2
21
Claude 3 throughput & latency performance first look 👀
Amongst the leading LLM models,
@AnthropicAI
's new Claude 3 models sit in different areas regarding their latency & throughput (tokens/s) performance.
Sonnet is amongst the fastest 'Medium-sized' models with a higher

2
5
19
Even if your focus is quality, inference speed & price matters when you can achieve the same quality across multiple requests
Back of the envelope illustration:
- GPT-4 Turbo is (arguably) the highest quality model available, however it is served at 18 tokens/s and costs ~$15/M

1
1
19
Performance is not the same across Claude 3 Haiku API providers
Anthropic, Google Vertex and Amazon Bedrock all host Claude 3 Haiku and Sonnet. While pricing is the same, performance is not.
‣
@AnthropicAI
has the best performance, with the highest throughput tokens/s and


1
3
19
Mixtral 8x22B Instruct is now the highest quality open-source model! We have benchmarked its efficient architecture as achieving ~80 tokens/s throughput (~4X GPT-4 Turbo)
With only 39B active parameters per forward pass, and 141B total, it is an extremely efficient model that

2
0
19
GPT-4o's tokenizer efficiency does not quite meet OpenAI's claims in their announcement 👀
We independently tested the efficiency of GPT-4o's tokenizer vs. GPT-4's and others across a large corpus of chat logs in different languages. OpenAI in their announcement claims used one

0
1
17
It is bizarre that third-party providers are hosting Gemma 2 before Google is.
We are now seeing third-party API providers host Gemma 2 with
@FireworksAI_HQ
launching their Gemma 2 9B API.
This is no surprise as Gemma 2 models are strong relative to their size. The 27B model is

1
5
17
Takeaways from Mistral's release of Mistral Large and Mistral Small
- Unlike previous Mistral models which were open-source (except for Medium), the new models are proprietary. This represents a strategic shift for Mistral and was potentially driven by Mistral's new deal with

3
3
18
Frankly,
@Apple
's new 7B open-source model is not exciting for the model itself. Its MMLU is 64% vs. Llama 3 8B's 68%. Why it is exciting is for what people will do with the model and its pre-training dataset, including training new specialized small models.
Gathering and
4
5
34
First performance benchmarks of DBRX 🐎! DBRX has been benchmarked as achieving a throughput of 70 token/s. DBRX occupies an attractive quality vs. throughput position whereby DBRX is faster than GPT3.5 Turbo & Llama 2 70B while maintaining significantly higher quality (as

3
4
17
Inference speed matters!

NEW Video - Humane Pin Review: A Victim of its Future Ambition
Full video:
This clip is 99% of my experiences with the pin - doing something you could already do on your phone, but slower, more annoying, or less reliable/accurate. Turns out smartphones
746
1K
23K
5
1
18
Mistral have released Codestral 22B a new model focused on (fast) code generation!
It is trained on 80+ languages and has been released on
@MistralAI
's API & chat interface as well as under an open but non-commercial license (more analysis of this later).
Comparing Codestral

1
4
17
Claude 3.5 Sonnet's Chatbot Arena ELO is now listed. Despite matching matching GPT-4o's MMLU score, 3.5 Sonnet falls slightly below GPT-4o
Chatbot Arena scores increase in reliability over time and the main ELO score can favor communication over analytical capabilities. We will

0
5
17
New leader in Speech-to-Text speed - Congratulations
@DeepgramAI
on achieving a Speed Factor of 164x real time with their Base model and 118x with their new and more accurate Nova-2 model!
Deepgram's Nova-2 model is also very competitively priced at >4X less expensive than the

2
1
17
@FireworksAI_HQ
has been added to ArtificialAnalysis!
Our performance benchmarking shows Fireworks delivering leading Tokens per Second throughput on both
@AIatMeta
's Llama 2 Chat (70B) and
@MistralAI
's Mixtral 8x7B Instruct.
We’ve added Fireworks to our benchmarking for the

1
3
16
While GPT4o mini is much faster than the median provider of Llama 3 70B,
@GroqInc
offers Llama 70B at ~340 output tokens/s, >2X faster than GPT-4o mini.
@togethercompute
and
@FireworksAI_HQ
also offer Llama 3 70B at speeds close to GPT-4o mini.
This highlights the importance

0
8
27
Understanding Mistral’s new models and the quality/price trade-offs between them
Mistral now has 3 endpoints for proprietary models (2 are new):
- Mistral Small is a new model which improves on Mixtral 8x7B's quality, though is ~4X the price
- Mistral Medium has been offered

3
0
14
Launching the Artificial Analysis Text to Image Arena 🚀
Featuring top models like
@StabilityAI
Stable Diffusion 3,
@OpenAI
DALL E 3,
@midjourney
v6,
@playground_ai
v2.5 - with more coming soon.
After you’ve voted over 100 times (it’ll only take a few minutes!), we'll reveal

3
2
15
Smaller models are getting better and faster. We can see parameter efficiency is increasing with quality increasing from Mistral 7B to Llama 3 8B to the latest Gemma 2 9B with minimal size increases.
The Llama 3 and Gemma 2 papers shared the impact of overtraining in achieving

2
2
15
Today OpenAI banned access to its API from China. China had already blocked access to ChatGPT using the 'Great Firewall'.
In the past few months, we have seen models from AI labs HQ'd in China start to 'catch-up' to the quality of models developed globally.
These
Models from AI labs headquartered in China 🇨🇳 are now competitive with the leading models globally 🌎
Qwen 2 72B from
@alibaba_cloud
has the highest MMLU score of open-source models, and Yi Large from
@01AI_Yi
and Deepseek v2 from
@deepseek_ai
are amongst the highest quality
7
19
119
0
6
14
Benchmarks of Gemma API hosts: congratulations Together, Fireworks, Anyscale & Deepinfra on the quick launch! 🚀
Initial results show
@togethercompute
&
@FireworksAI_HQ
taking an early lead in Throughput (tokens per second) while
@anyscalecompute
&
@DeepInfra
are very

1
3
14
@MistralAI
releases Mixtral 8x22B, the second largest open-source model yet (after Grok-1)
Congratulations team
@MistralAI
(image from release notes within torrent)! We look forward to benchmarking it on Artificial Analysis


magnet:?xt=urn:btih:9238b09245d0d8cd915be09927769d5f7584c1c9&dn=mixtral-8x22b&tr=udp%3A%2F%%3A1337%2Fannounce&tr=http%3A%2F%%3A1337%2Fannounce
276
830
6K
2
9
14
Google IO AI takeaways including Google's new model, Gemini 1.5 Flash!
Key takeaways: 🧠
‣ Google now recognizes the importance of speed and price and has released a smaller model. Gemini 1.5 Flash is faster and at a lower price than Gemini 1.5
‣ Flash has similar features to

2
2
13
