
Tom McCoy
@RTomMcCoy
Followers
3,350
Following
530
Media
154
Statuses
1,575
Assistant professor @YaleLinguistics . Studying computational linguistics, cognitive science, and AI. He/him.
New Haven, CT
Joined December 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Hamas
• 966026 Tweets
Milton
• 706936 Tweets
Florida
• 650177 Tweets
Chilpancingo
• 228024 Tweets
Category 5
• 157776 Tweets
Cat 5
• 93540 Tweets
Atlantic
• 64064 Tweets
Polymarket
• 59766 Tweets
Floridians
• 48527 Tweets
Doocy
• 48162 Tweets
Doc Harris
• 28944 Tweets
Carmen
• 22016 Tweets
Cissy Houston
• 21457 Tweets
ياسر
• 19478 Tweets
Coachella
• 17993 Tweets
Cleveland
• 17080 Tweets
#فزعه_الشعب_السعودي
• 15643 Tweets
Beatrice
• 14709 Tweets
Vtubers
• 13905 Tweets
Cat 6
• 12747 Tweets
Skubal
• 12032 Tweets
#عبدالرحمن_المطيري
• 10326 Tweets



















Pinned Tweet

🤖🧠NEW PAPER🧠🤖
Language models are so broadly useful that it's easy to forget what they are: next-word prediction systems
Remembering this fact reveals surprising behavioral patterns: 🔥Embers of Autoregression🔥 (counterpart to "Sparks of AGI")
1/8

36
294
1K
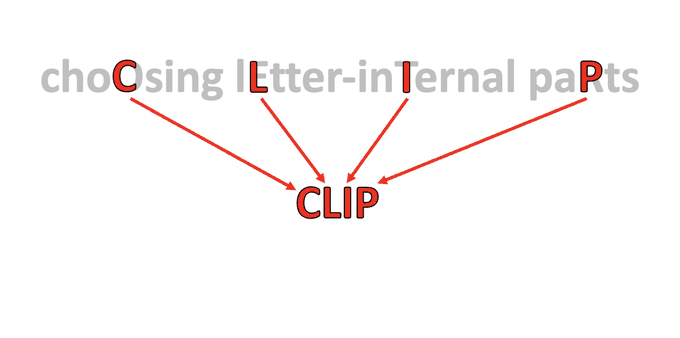
It has become acceptable for acronyms to use any letters within a word, not just the first letter.
E.g., ORNATE = acrOnyms fRom noN-initial chAracTErs
But why stick with whole letters? In my new paradigm CLIP, an acronym can use any curves or line segments from the base phrase!
20
91
948
How am I only learning now that Latvia's prime minister has a PhD in linguistics from Penn??
I've seen many lists of "jobs for linguists outside academia" but they never include Prime Minister of Latvia.
11
119
821
Linguists: In case you could use a diversion, I've made a phonetic crossword - all the answers must be written in the IPA, one phoneme per square.
(Non-linguists: Here's a chance to learn some phonetics!)
Puzzle:
Answers:

19
248
640
🤖🧠NEW PAPER🧠🤖
What explains the dramatic recent progress in AI?
The standard answer is scale (more data & compute). But this misses a crucial factor: a new type of computation.
Shorter opinion piece:
Longer tutorial:
1/5

8
111
597
🤖🧠NEW PAPER🧠🤖
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
Paper:
1/n

4
116
545
*NEW PREPRINT*
Neural-network language models (e.g., GPT-2) can generate high-quality text. Are they simply copying text they have seen before, or do they have generalizable linguistic abilities?
Answer: Some of both!
Paper:
1/n

9
96
461
Transformers are the current state of the art, but one day LSTMs may overtake them.
That would make LSTMs current again. You could even say…re-current.
5
33
434

Excited to share some updates, which all still feel surreal:
- Just defended my dissertation advised by
@TalLinzen
&
@Paul_Smolensky
!
- Next up: Postdoc w/ Tom Griffiths
@cocosci_lab
!
- Then joining
@YaleLinguistics
as an asst prof w 2ndary appt
@YaleCompsci
!
A thank-you thread:
31
8
304
Takeaways from
#NeurIPS
:
1) In-distribution generalization is out
2) Out-of-distribution generalization is in
3) We want compositionality (whatever it is)
4) "GPT-2" is very hard to say
6
31
272
My colleagues and I are accepting applications for PhD students at Yale. If you think you would be a good fit, consider applying! Most of my research is about bridging the divide between linguistics and artificial intelligence (often connecting to CogSci & large language models)
6
64
254
The 4 gates of an LSTM:
1) Input gate
2) Output gate
3) Forget gate
4) Backpropa gate
1
26
243
Instead of writing out "clustering," we should just write "k."
It's much shorter, and everyone knows that k means clustering.
4
23
233
Summarization is ROUGE,
MT is BLEU.
Can automatic metrics
Ever measure NLU?
8
20
231
“Stop! In the name of love”
- A phonologist describing the /k/, /p/, or /d/ in “Cupid”
1
38
203
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
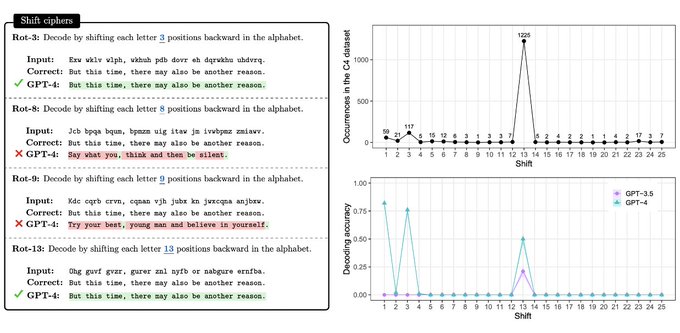
Another example: shift ciphers - decoding a message by shifting each letter N positions back in the alphabet.
On the Internet, the most common values for N are 1, 3, and 13. These are the only ones for which GPT-4 performs well!
5/8
4
20
194
I am incredibly honored to receive a Glushko Dissertation Prize!
A huge thank-you goes to:
- My dissertation advisors,
@TalLinzen
and
@Paul_Smolensky
, for being incredibly supportive throughout my PhD
- (continued in next tweet)
1/2

The Cognitive Science Society is thrilled to announce the winners of the 2024 Glushko Dissertation Prize! 🏆
Let’s meet the brilliant minds behind groundbreaking research in Cognitive Science 🧵👇

1
7
47
20
4
191
DEFINITION: the "critical period in linguistics" is the week after a linguist tweets about innateness, when everyone else is critical of them
2
27
181
Why is it called "Teaching NLP" instead of "Natural Language Professing"?
1
13
181
I am hoping to hire a postdoc who would start in Fall 2024. If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Please see this link for details:
2
53
164
I’m now halfway through my PhD. One lesson I've learned: Don’t get discouraged comparing yourself to others.
Most comparisons are unfair; no two people have the same background. Plus, you get to define what success means to you-it doesn’t have to look like anyone else’s version.
3
14
161
A
#CompLing
proof:
a. Consider these sentences:
1. "How do you get down from a horse?"
2. "How do you get down from a goose?"
b. In (1), “down” is a preposition; i.e., “down” = P
c. In (2), “down” is a noun phrase; i.e., “down” = NP
d. By transitivity: P = NP
7
19
158
Phonology: Ain't no party like a fricative party cuz a fricative party don't stop
Syntax: Ain't no recursion like infinite recursion, cuz there ain't no recursion like infinite recursion, cuz...., cuz infinite recursion don't stop
Semantics: Ain't no Partee like Barbara Partee
2
15
152
Human language learning is fast & robust because of the inductive biases that guide it. Neural nets lack these biases, limiting their utility for cognitive modeling. We introduce an approach to address this w/ meta-learning.
Demo:
1
35
157
Two recent times when English failed me:
1) Passive form of "let someone know" ("He wants to be let known"?)
2) Adverb form of "hoity-toity" ("hoitily-toitily"?)
We need a flag, like on Wikipedia: "This linguistic phenomenon is incomplete. You can help English by expanding it."
13
16
154
@katiedimartin
For a class I TAed, I made this intro to Python structured around a running example from phonology:
It's meant to be gone through in one to two 75-minute lectures, so it might actually be more basic than what you want.
3
8
148
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
Our results show that we should be cautious about applying LLMs in low-probability situations
We should also be careful in how we interpret evaluations. A high score on a test set may not indicate mastery of the general task, esp. if the test set is mainly high-probability
7/8
2
8
145
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
By reasoning about next-word prediction, we make several hypotheses abt factors that'll cause difficulty for LLMs
1st is task frequency: we predict better performance on frequent tasks than rare ones, even when the tasks are equally complex
Eg, linear functions (see img)!
4/8

1
8
137
When language models produce text, is the text novel or copied from the training set?
For answers, come to our poster today at
#acl2023nlp
! Session 1 posters, 11:00 - 12:30 today
Critics* are calling the work "monumental"
Link to paper:
1/2

3
20
128
New paper: "Does syntax need to grow on trees? Sources of hierarchical inductive bias in sequence-to-sequence networks" w/
@Bob_Frank
&
@TalLinzen
to appear in TACL
Paper
Website
Interested in syntactic generalization? Read on! 1/
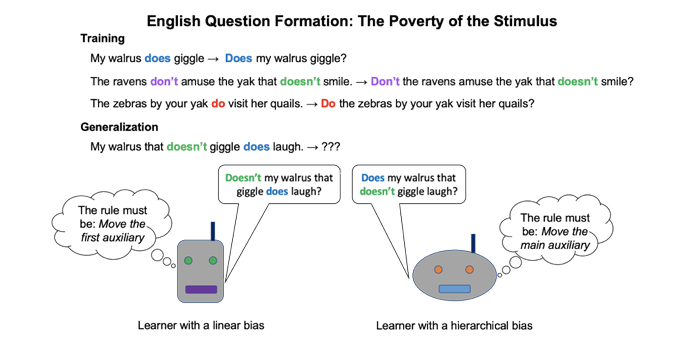
2
27
120
Before
#acl2019nlp
,
@TalLinzen
gave me some transformative advice: If there are people you would like to meet at a conference, email them to set up a meeting!
(1/5)
2
17
120
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
In conclusion: To understand what language models are, we must understand what we have trained them to be.
For much more, see the paper:
Work by
@RTomMcCoy
,
@ShunyuYao12
,
@DanFriedman0
,
@MDAHardy
, and Tom Griffiths
@cocosci_lab
8/8

3
10
118
"Whatever accidental meaning her *words* might have, she *herself* never meant anything at all."
- Lewis Carroll (presumably talking about language models)
1
19
115
Paul Smolensky’s class “Foundations of CogSci” now has a 2.5-hr summary on YouTube!
This course is the reason I think of myself as a cognitive scientist. Highly recommended.

1
26
114
The word2vec analogy "king - man ≈ queen - woman" is famous. What other types of vectors, besides word embeddings, have been argued to display additive analogies? (e.g., vector representations of faces? or phonemes? or documents?)
16
13
110
At
#LSA2019
, there is one elevator where you speak your first language, and another where you speak your second language.

0
12
108
Linguists, I have a terminology proposal:
- When you study competence, you're doing linguistics
- When you study performance, you're doing lingusitics
Of course, the object of study would be language or langauge, respectively
5
14
101
If you're interested in the NYT lawsuit (about GPT-4 copying from NYT articles), you should check out our paper "How Much Do Language Models Copy From Their Training Data?"
TACL link:
1/n
*NEW PREPRINT*
Neural-network language models (e.g., GPT-2) can generate high-quality text. Are they simply copying text they have seen before, or do they have generalizable linguistic abilities?
Answer: Some of both!
Paper:
1/n
9
96
461
1
18
99
Me, young and naive, reading about LSTMs for the first time: "Huh, I have no idea what an LSTM is. Well, I'll just look up what the letters stand for, and that should clear it up!"
5
3
96
Random grad school tip: Sign up for one-on-one meetings with invited speakers - even if their interests are different from yours
1/4
1
5
96
I wrote a long criticism of Bill Nye, when I meant to criticize Bill Nighy.
It was an ad homonym attack.
1
12
93
From finite linguistic experience, we can acquire languages that are infinite. How do we make this leap?
New preprint on artificial language learning of center embedding:
w/
@DrCulbertson
, Paul Smolensky, & Geraldine Legendre, to appear
@cogsci_soc
1/n
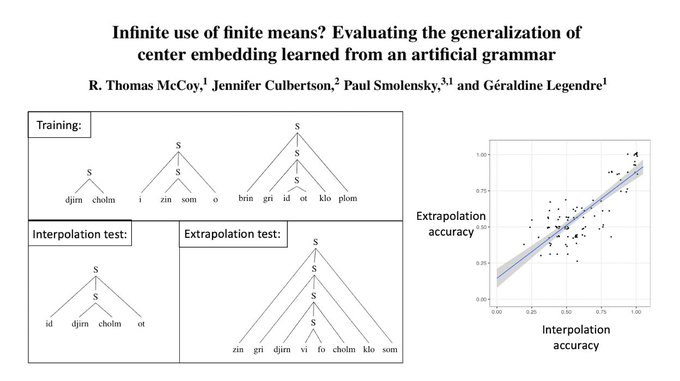
3
24
92
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
Our big question: How can we develop a holistic understanding of large language models (LLMs)?
One popular approach has been to evaluate them w/ tests made for humans
But LLMs are not humans! The tests that are most informative about them might be different than for us
2/8

1
7
95
Someone should use GPT-3 to write a season of Star Trek. We can call it "Star Trek: The Text Generation"
5
4
93
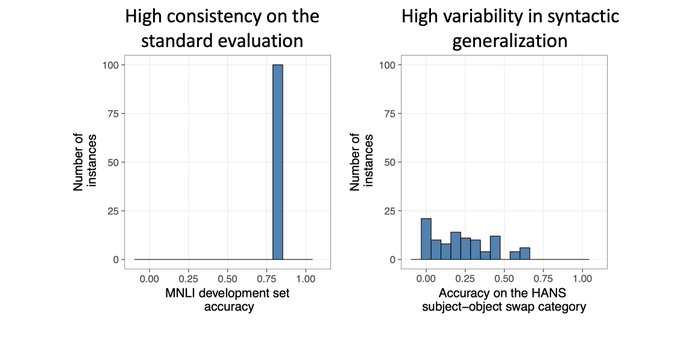
New tech report with Junghyun Min and
@TalLinzen
: "BERTs of a feather do not generalize together"
Across 100 re-runs, BERT fine-tuned on MNLI has a consistent score on MNLI but extreme variation in syntactic generalization (measured w/ HANS).
Link:
1/7
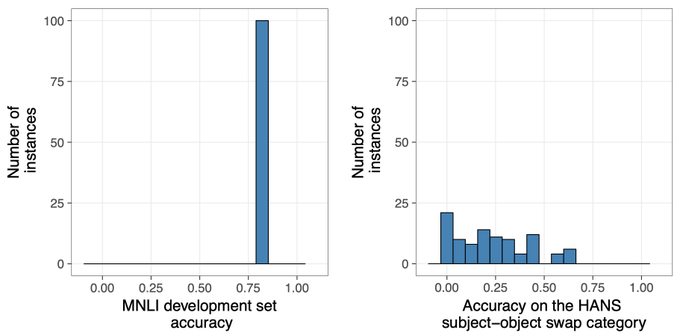
1
19
90
*NEW RESOURCE*
Neural networks can vary dramatically across reruns.
As a tool for studying this variation, we've released the weights for 100 instances of BERT fine-tuned on natural language inference (MNLI):
w/ Junghyun Min and
@TalLinzen
1
18
81
Yesterday I went to check out the classroom where I'll be teaching. At first I thought the door was locked, but it turned out that it was just very heavy.
It felt like a metaphor for life - often the doors that we think are locked are actually just heavy!
6
4
82
Excited to have a new
@ICLR2019
paper with
@TalLinzen
,
@EwanDun
, and Paul Smolensky! We find implicit compositional structure in RNN encodings by approximating them with Tensor Product Representations.
Paper:
Demo:

1
10
77
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
So how can we evaluate LLMs on their own terms?
We argue for a *teleological approach*, which has been productive in cognitive science: understand systems via the problem they adapted to solve
For LLMs this is autoregression (next-word prediction) over Internet text
3/8
2
4
78
Tomorrow I'll be speaking at the new
@NLPwithFriends
about using meta-learning to improve linguistic generalization in neural networks.
See below for details!

We are very excited to announce our next speaker!!
🗣Tom McCoy(
@RTomMcCoy
), telling us about "Universal Linguistic Inductive Biases via Meta-Learning"
🗓August 12th, 14:00 UTC
📝Sign up:
Keep up to date with talks at
1
14
73
4
8
72
I'm beyond excited to watch
@AlRoker
solve a crossword I constructed! Thanks to
@NYTimesWordplay
for organizing!

Tune in Thursday, March 18, at a special time -- 11 a.m. Eastern -- and help our special guest the TODAY Show's
@alroker
crush
@RTomMcCoy
's tumultuous crossword! Join us on Twitter, YouTube or Twitch.
Illustration by James Doane.

4
4
20
7
4
70
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
The 2nd factor we predict will influence LLM accuracy is output probability
Indeed, across many tasks, LLMs score better when the output is high-probability than when it is low-probability - even though the tasks are deterministic
E.g.: Swapping adjacent words (see img)
6/8

1
3
73
In Toronto for
#acl2023nlp
- please reach out if you want to meet up! Some interests:
- connecting linguistics & NLP
- interpretability & evaluation
- other things on this list:
- PhDs & postdocs at Yale Linguistics or CS (I'll be recruiting for 2024-2025)
6
5
68
Paper accepted to
@ACL2019_Italy
! "Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference" with
@TalLinzen
and Ellie Pavlick (building on work done with the JSALT team led by Ellie and
@sleepinyourhat
). Link:

3
10
66
William Carlos Williams was right: "wheelbarrow" has a whopping 5 dependents!
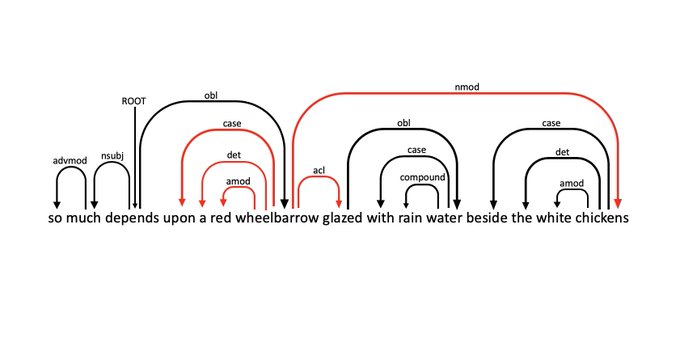
3
13
64
Mechanical Turk is incredibly useful for collecting data, but using it effectively can be tricky.
Here is a list of tips that helped me get good data & save money:
4
10
63
This very nice piece by Ted Chiang describes ChatGPT as a lossy compression of the Internet.
This idea is helpful for building intuition, but it's easy to miss an important point: Lossiness is not always a problem! In fact, if done right, it is exactly what we want.
1/14

The science-fiction writer Ted Chiang explores how ChatGPT works and what it could—and could not—replace:
7
54
215
2
4
65
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
P.S. - If these results sound interesting, here are two other papers that you should also check out:
First is this excellent work by
@zhaofeng_wu
et al. about task variants:

Language models show impressive performance on a wide variety of tasks, but are they overfitting to evaluation instances and specific task instantiations seen in their pretraining? How much of this performance represents general task/reasoning abilities?
1/4

9
111
476
1
2
65
Everyone says "To reach human-level AI, we need to scale up our models." But humans don't have scales! Only reptiles do!
4
1
62
One perk of academia that doesn’t get enough love is eduroam. So many times when I’ve needed wifi, eduroam has unexpectedly been there - e.g., when I was in a Swedish airport & urgently needed to rebook a flight.
5
2
62
I hope the VP debate will get into double-object constructions, or at least the argument/adjunct distinction.
3
8
59
(1/5) To understand our models, we need to understand how they have been affected by their training data. Methods like this one will help us do that.
@XiaochuangHan
,
@byron_c_wallace
, Yulia Tsvetkov.

4
5
60
Today is my New Yorker crossword debut! (Online-only)

5
5
60
Excited to have 2 papers accepted to
#acl2020nlp
! Both are about syntactic generalization in neural networks (via data augmentation or tree-based architectures), and both are joint work with some fantastic collaborators.
Titles are in replies, links are yet to come:
1
4
57

Good news: The horse raced past the barn has fully recovered from his fall!
3
3
52
On Oct. 10, I’ll be giving a virtual talk for the National Museum of Language!
It's about the linguistics of crossword puzzles.
Registration is free:

1
8
55
Machine learning techniques ranked by the sturdiness of the building materials in their names:
1) METALearning
2) reinforCEMENT learning
3) logiSTIC regression
4
3
53
Life hack for TAs: You can condense your email signature into a single character, θ ("the TA")
2
5
54
Seems like part of the joke went unnoticed...
At the risk of ruining humor by explaining it: The sub-letter shenanigans are unnecessary - try reading the first letters of the words in the picture.
It has become acceptable for acronyms to use any letters within a word, not just the first letter.
E.g., ORNATE = acrOnyms fRom noN-initial chAracTErs
But why stick with whole letters? In my new paradigm CLIP, an acronym can use any curves or line segments from the base phrase!
20
91
948
4
0
53
Standard evaluations in NLP can mask striking differences between models.
To hear more, come to our talk “BERTs of a feather do not generalize together” on Friday at
#BlackboxNLP
! w/ Junghyun Min and
@TalLinzen
Paper:
3
4
52
Some historical phonetics: The [f] sound was originally made by clenching your teeth together. Only in the past few centuries did we switch to the current approach of lower-lip-against-upper-teeth.
The name for this shift: dental f loss
3
2
52
(3/5) This one’s a twofer: Both papers give hard evidence that evaluating only on English can make us overestimate our models (
#BenderRule
in action).
Kate McCurdy, Sharon Goldwater, Adam Lopez.
Forrest Davis,
@marty_with_an_e
.

1
6
53
(2/5) Many papers ask, “Do language models learn syntax?” I like that this work moves beyond that to “What type of syntax do language models learn?”
Artur Kulmizev,
@vin_ivar
, Mostafa Abdou,
@JoakimNivre
.

1
11
52
Some English words differing only in stress:
- desert/dessert
- insight/incite
- decent/descent
- reflex/reflects
- discus/discuss
- readout/redoubt
- misery/Missouri
- deepened/depend
- media/Medea
- uprise/apprise
- abbess/abyss
- bellies/Belize
- expos/expose
- trusty/trustee
3
4
50
If you're interested in language acquisition and neural networks, check out our new paper!

NEW PREPRINT
Excited to release my first first-author paper! We investigate if neural network learners (LSTMs and Transformers) generalize to the hierarchical structure of language when trained on the amount of data children receive.
Paper:

2
21
95
3
3
50
This got more likes than I expected, so I guess I should share my SoundCloud:
1
11
48
@ShunyuYao12
@danfriedman0
@mdahardy
@cocosci_lab
@zhaofeng_wu
…as well as this fantastic paper by
@yasaman_razeghi
et al. about input probability (an effect that is complementary to the output probability effects described above):

You've probably seen results showing impressive few-shot performance of very large language models (LLMs). Do those results mean that LLMs can reason? Well, maybe, but maybe not. Few-shot performance is highly correlated with pretraining term frequency.
14
107
586
1
1
48
My pipeline for typing special characters:
1) Find the Wikipedia page about the character
2) Copy the character from Wikipedia and paste it into my browser's search bar, to remove formatting
3) Copy from the search bar into the document I'm typing
3
1
49
Prediction: one of these days, someone will announce a new LLM that has an infinite context length - but it will turn out to be a reinvention of the LSTM.
5
1
46
🌲Interested in language acquisition and/or neural networks? Check out our poster today at
#acl2023nlp
! Session 4 posters, 11:00-12:30 🌲
Elevator pitch: Train language models on child-directed speech to test "poverty of the stimulus" claims
Paper:
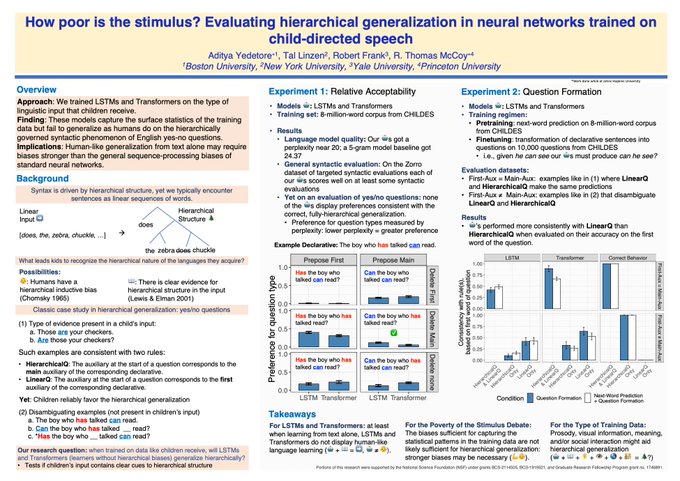
2
5
48
Interesting results about LLMs & meaning!
As a bonus, the paper is an excellent example of how to evaluate LLMs fairly:
1. Provide sufficient context & information, to avoid underestimating LLMs
2. Control for spurious correlations in the data, to avoid overestimating LLMs

Controlled zero-shot evals have revealed holes in LMs’ ability to robustly extract and use meaning.
But what happens when you add experimental context (ICL/instructions)? With
@AllysonEttinger
&
@kmahowald
, I explore this in the context of semantic property inheritance:
1/13

1
14
73
1
2
47
Whenever my family drove by Toys R Us, my dad would say, "It should really be named Toys R We."
20 years later, I'm a linguist.
Coincidence? You tell me.
2
1
47
@swabhz
"You might have misread this section: It's meant to be 'limitations', not 'imitations'"
1
0
45
🧠🤖 Are you interested in linguistics, cognitive science, and Large Language Models? Come join this workshop next Monday & Tuesday over Zoom! I'm really looking forward to it!

Join us online for the May 13–14 for a star-studded
#NSF
-sponsored workshop: New Horizons in Language Science: Large Language Models, Language Structure, and the Cognitive & Neural Basis of Language! Interdisciplinary talks & discussion on three themes: 1/
5
86
226
0
7
46
John Firth, 1957, reminding a customer service rep to uphold their warranty:
"YOU SHALL KNOW A COMPANY BY THE WORD THAT IT KEEPS!!!"
2
5
44
"To be a computer scientist, you have to hate computers at least a little. Otherwise you have no motivation to make them better."
- Dana Angluin, talking to my first college CS class
I think of this often. It's a comforting thought if you're feeling frustrated with your field(s)
0
1
42
Area chairs and area rugs are much less similar than their names would suggest
2
2
41
I will greatly miss Drago. To a very large extent, I owe him my career: Along with
@LoriLevinPgh
, he introduced me to linguistics via NACLO, a contest that they co-founded. His warmth and enthusiasm got me excited about the field that I have continued to pursue ever since.
1/5

The
#AI
community, the
#computerscience
community, the
@YaleSEAS
community, and humanity have suddenly lost a remarkable person,
@dragomir_radev
- kind and brilliant, devoted to his family and friends... gone too soon. A sad day
@Yale
@YINSedge
@YaleCompsci
#NLP2023


41
87
387
2
2
40
The classic JSTOR trap: Thinking you’ve found a PDF of the book you need, when it’s actually just a review of that book (with the same title as the book)
1
0
38
Off to
#acl2020nlp
- or, as I call it, Seattle Watching-tons
2
4
41
At
#CogSci2021
and interested in linguistic generalization? Stop by our poster!
We find that people extrapolate center embedding beyond the depths of embedding they've seen.
Wed, July 28, from 11:20 am to 1:00 pm, Eastern time
Poster 2-E-176
Paper:
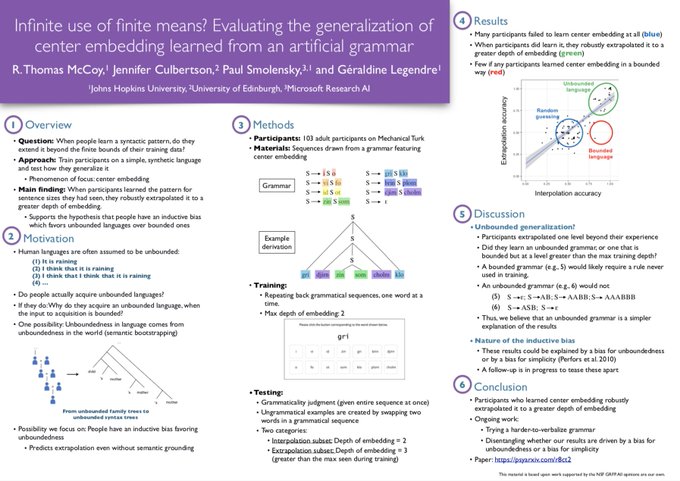
1
2
39
In model-generated text, very few bigrams and trigrams are novel - i.e., most of them appear in the training set. But for 5-grams and larger, the majority are novel!
3/n
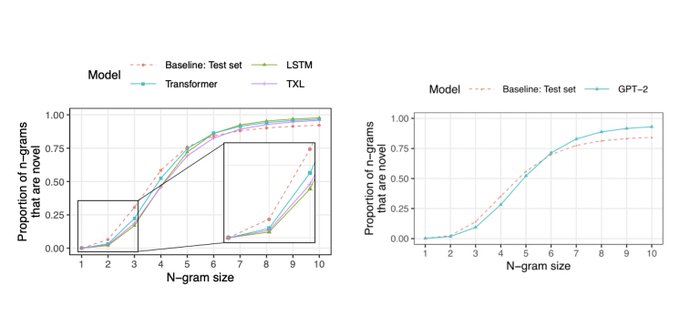
2
3
39
🤖🧠New preprint🧠🤖
How can we understand a black box like an LLM?
Maybe we can apply the same tools that we use to model the human mind - another intelligent black box!
Bayesian models have been very useful in such settings, so they're well-poised to help us understand LLMs

Does the success of deep neural networks in creating AI systems mean Bayesian models are no longer relevant? Our new paper argues the opposite: these approaches are complementary, creating new opportunities to use Bayes to understand intelligent machines
3
47
183
1
2
38