

Vedant Misra
@vedantmisra
Followers
1,832
Following
304
Media
20
Statuses
199
AI researcher @DeepMind (Gemini, Minerva, PALM) | Alum @OpenAI (Codex, Grokking) | @HubSpot | Founder/CEO Kemvi (acq HUBS) | Physics @Columbia
San Francisco, CA
Joined September 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 1203388 Tweets
Liz Cheney
• 209584 Tweets
#LISAxMoonlitFloor
• 197221 Tweets
MOONLIT FLOOR OUT NOW
• 137932 Tweets
SCJN
• 128619 Tweets
The Boss
• 103770 Tweets
#GHGala5
• 100032 Tweets
Bruce
• 92338 Tweets
Mets
• 69981 Tweets
Happy Anniversary
• 59797 Tweets
Baker
• 51010 Tweets
Brewers
• 42600 Tweets
EL DESTELLO IS OUT
• 34794 Tweets
天使の日
• 33230 Tweets
Falcons
• 29013 Tweets
Mancuso
• 25832 Tweets
Halle
• 24850 Tweets
もちづきさん
• 24728 Tweets
Pete Alonso
• 19614 Tweets
Athena
• 15232 Tweets
Mike Evans
• 14530 Tweets
Bijan
• 13510 Tweets
Phillies
• 11404 Tweets
#ゴンチャのハロウィン準備中
• 10748 Tweets
Milwaukee
• 10479 Tweets
Quintana
• 10036 Tweets



















Pinned Tweet

Any sufficiently advanced pattern matching is indistinguishable from reasoning.
5
10
75
Gemini Pro matches GPT-4 in ELO, but the real game changer is that sampling a million tokens costs $0.5 instead of $30

🔥Breaking News from Arena
Google's Bard has just made a stunning leap, surpassing GPT-4 to the SECOND SPOT on the leaderboard! Big congrats to
@Google
for the remarkable achievement!
The race is heating up like never before! Super excited to see what's next for Bard + Gemini

153
620
3K
11
43
383
♥️

3
6
150
Thrilled to announce🦉Minerva: a large language model capable of solving mathematical problems using step-by-step reasoning in natural language.
See blog here: and samples here: (1/n)

Very excited to present Minerva🦉: a language model capable of solving mathematical questions using step-by-step natural language reasoning.
Combining scale, data and others dramatically improves performance on the STEM benchmarks MATH and MMLU-STEM.
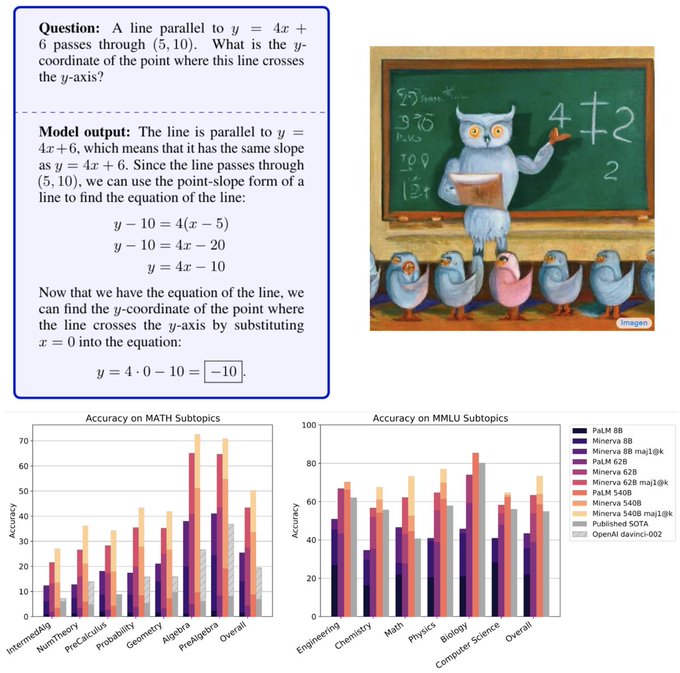
104
1K
8K
3
30
128
How AI research feels when Chinchilla (70B) outperforms Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), MT-NLG (530B)

2
7
86
Gemini Pro 1.5 is here! 10M token context window (1M in production for now), comparable evals to Ultra 1.0, and considerably more compute efficient. This model can perceive and answer questions about 10 hours of video, or 100 hours of audio, or 300K lines of code, and will


To show what’s possible with the drastically huge context window in Gemini 1.5 Pro, we prompted it with the three.js examples code - over 100,000 lines of code/800k+ tokens!
(That’s not even the max, it can handle millions of tokens 😀)
Gemini was able to process all the code
33
186
1K
0
13
62
All you really need to be happy is health, gratitude, fulfilling relationships, a roof over your head, an exascale compute cluster, and a few trillion tokens. Is that too much to ask?
3
3
51
Thrilled to share what we've been working on at DeepMind!
Exciting times, welcome Gemini (and MMLU>90)! State-of-the-art on 30 out of 32 benchmarks across text, coding, audio, images, and video, with a single model 🤯
Co-leading Gemini has been my most exciting endeavor, fueled by a very ambitious goal. And that is just the beginning!
65
273
2K
4
3
40
I'm at
#NeurIPS22
! Interested in LLMs, tool use, scaling, reasoning, AGI, or good restaurants in New Orleans? DM me if you'd like to meet, or stop by our poster on Minerva (Tues 4-6p, no. 920)
3
0
32
📈
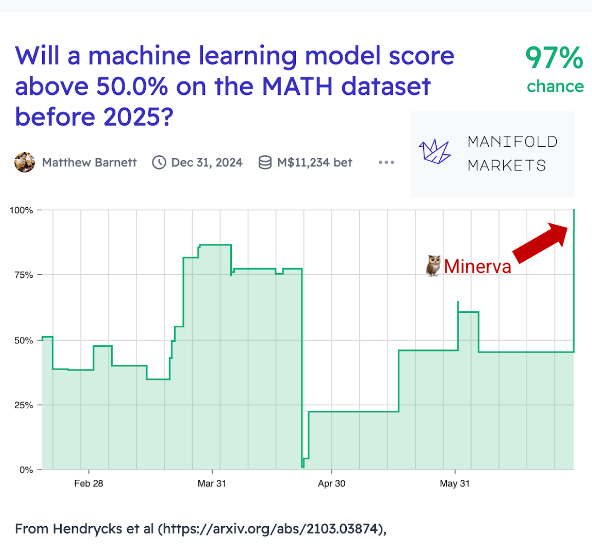

Google latest 540B language model solves 1/3 of STEM undergrad problems from MIT with 50% accuracy on MATH, what
@JacobSteinhardt
predicted would happen by 2025
11
66
387
0
2
26
Can confirm. Sergey has been in the bullpen with the rest of us since the beginning of Gemini, shares our deep fascination with this technology, and recognizes that this is a transformative moment in the history of humanity. His engagement has been immensely motivating for all.

Sergey Brin is worth $105 billion yet he was a core contributor on the Gemini AI technical paper, coding basically every day.
Legend.

144
635
6K
3
3
25
BIG Bench is not only a fascinating collection of tasks for LLMs, it's also a shining example of how open and collaborative research should be organized. Glad to have been part of it!

After 2 years of work by 442 contributors across 132 institutions, I am thrilled to announce that the paper is now live: . BIG-bench consists of 204 diverse tasks to measure and extrapolate the capabilities of large language models.

35
571
3K
0
1
24
What a crew this was! 🫶

Some day I’ll tell my grand children, « I was there »
🫶 reasoning team, OpenAI 2019

11
16
687
0
0
20
Now that I've had a paper covered by
@yannic
, next I'm going to go for either a Fields Medal or the Turing award, haven't made up my mind yet.

"Grokking" is weird: Neural Networks trained to fill in binary operation tables will quickly overfit to the training data, but after many, many steps suddenly "get it" and achieve 100% validation accuracy.
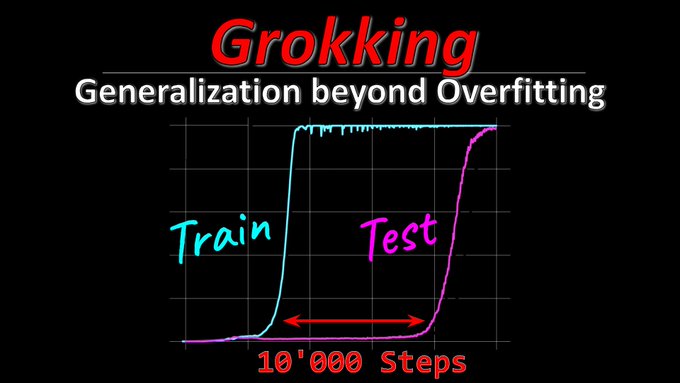
19
121
656
0
0
21
🤯 When you realize everyone you've worked for or considered working for is now casually hanging out with the President and VP! 🇺🇸 Hey
@JoeBiden
,
@KamalaHarris
, can I join the next reunion? 🤔 I promise to bring my A(I)-game!


0
0
10

To recruiters trying to poach top LLM talent: you will have a better chance if the opportunity you're pitching involves (1) pushing buttons on a computer and (2) collaborating with astonishingly intelligent people (3) in unified pursuit of (4) building some kind of software God
1
0
20
Supercharge your terminal with this utility for calling Gemini. Example uses:
ls -al | gem "Which filenames are likely to be scientific PDFs?"
cat server.log | gem "Why is this error happening? How do I fix it?"
cat meeting_notes.txt | gem "Extract the key decisions from these
0
1
17
Such a pleasure speaking with
@paulroetzer
at
#maicon22
about AI and its impact on humanity - it's a thrilling time to be working on this technology!

It’s the final session of
#MAICON22
and we’re diving deep with a fireside chat featuring
@vedantmisra
where
@paulroetzer
is interviewing him about how
#AI
is not only transforming business but how it will transform humanity in general.

0
0
7
2
2
16
Aloha, I'm at
#ICML2023
! Interested in LLMs, reasoning, AGI, or things to do in Oahu? DM me if you'd like to meet!

2
0
8
Writing computer code is a great evaluation of reasoning capabilities, and it was a thrill to work on Codex! All we need now is models that write research-grade deep learning code... Check out the paper here:
3
1
14
Technology is improving at an increasingly unpredictable pace, and it's becoming harder to convince oneself that there's no major socioeconomic transformation on the immediate horizon 1/
1
3
13
It took us longer to go from the Mark I Perceptron to LSTMs (29 years) than from LSTMs to
#ChatGPT
(27 years). It took us longer to go from Word2Vec to Transformers (4 years) than from Transformers to
#OpenAI
's
#GPT3
(3 years). Exponential growth is wild.
#AI
#MachineLearning
0
1
11
5 / n: We evaluated whether Minerva memorizes solutions by modifying problems to introduce changes in their framing or numerical content, and compared accuracy over sampled solutions before and after the modification; our results suggest minimal memorization.

1
1
9
We show that if you train a network the size of a lab rat's brain on a dataset of 800B tokens, it achieves SoTA performance on code and natural language, reasons better than the average ten-year-old, and learns to explain jokes. What happens if we train on more data for longer?

0
0
8
Learn from the mistakes of others. You can't live long enough to make them all yourself, and off-policy learning has better sample efficiency. - Eleanor Roosevelt
1
1
8
So excited about this release! The future is bright for deep networks that understand the visual world

We’ve developed two neural networks which have learned by associating text and images. CLIP maps images into categories described in text, and DALL-E creates new images, like this, from text.
A step toward systems with deeper understanding of the world.

98
949
3K
0
2
8
Research mathematicians: Perhaps one day AI will help with mathematical reasoning, but not today
@spolu
: hold my beer

An AI using this GPT thing which folks go on about, has golfed two short proofs in mathlib, Lean's maths library :o
So we now have 134 human contributors (including several ICL undergraduates) and 1 computer.
Thanks to
@jessemhan
for letting me know!
2
37
144
0
0
8
Never downgrade your dreams to match your education. Upgrade your education to match your dreams.

0
0
8

2 / n: Minerva is based on PaLM🌴and was trained on a large dataset of scientific papers and webpages with mathematical content. Combining scale, data, and inference techniques dramatically improves performance on the MATH benchmark and on STEM problems in MMLU.



1
0
7
3 / n: We also evaluated our model on a dataset of over 200 STEM undergraduate problems from MIT and found that it could solve nearly a third of them. We found that our model even outperforms the national average in Poland’s 2022 National Math Exam.


1
0
6
4 / n: In addition to scale and data, by using chain-of-thought / scratchpad prompting and majority voting to boost performance, Minerva achieves state-of-the-art performance on technical benchmarks without the use of external tools such as a Python interpreter.
2
0
6

6 / n: See our paper here:
An outstanding collaboration with
@alewkowycz
,
@ajandreassen
,
@dmdohan
,
@ethansdyer
,
@hmichalewski
,
@vinayramasesh
,
@AmbroseSlone
,
@cem__anil
, Imanol, Theo,
@Yuhu_ai_
,
@bneyshabur
, and
@guygr
0
0
4
Have an idea for a task that might be too tough for big language models? Submit it to our new benchmark!
We're participating in WELM/BIG-Bench, a collaborative effort to measure the capabilities and limitations of large language models. You can submit a task for the benchmark and/or workshop here:
10
42
253
0
1
4
Reading minds is real: A team at
@UTAustin
trained a model to take fMRI inputs and predict the words that people were thinking. () 4/

1
2
3
The best defense against Trump's populism is to prove to his supporters you're not so different from them:
0
0
2
@mpshanahan
@ilyasut
@mpshanahan
what makes you say there are no space and time in a computer? If you think only meat can be conscious, you *might* be in thrall to an overly simplistic definition of consciousness. The most basic criterion is for there to be a subjective experience, not a body.
1
0
2
"Computer, write me a screenplay":
@DeepMind
shipped Dramatron, demonstrating an approach to hierarchical generation of coherent long-form stories () 7/

1
1
2


Today in
@Nature
:
#AlphaTensor
, an AI system for discovering novel, efficient, and exact algorithms for matrix multiplication - a building block of modern computations. AlphaTensor finds faster algorithms for many matrix sizes: & 1/
114
2K
8K
1
0
2
@ESYudkowsky
@ESYudkowsky
this would be even more true if we knew how biological networks solve the very same problems.
0
0
1
Two paths ahead of us. Immortality or extinction. Scientists Edit a Dangerous Mutation From Genes in Human Embryos:
0
0
1
Wilt, crush, and dry leaves of evergreen shrub, add to hot water with bovine mammary secretion. Tea is weird if you think about it.
2
0
1
It's only a matter of time before you can command your home robot to bring you lunch, and your TV to render up an alternative ending to Game of Thrones, just by thinking it 2/
1
1
1
@katieburkie
Fwiw, they recently announced a two year grace period if you're conditionally approved for renewal!
0
0
1
In your possession is the most sophisticated massively parallel distributed processor known to man. Use it wisely.
0
0
1
@andrew_n_carr
This partitions all hairs into sets A and B such that all elements of A end up on the floor and all elements of B remain on the scalp with each element of B longer than each element of A
1
0
1