

Atila
@atiorh
Followers
2,165
Following
213
Media
34
Statuses
354
founder @argmaxinc 🥷 ex-Apple
San Francisco, CA
Joined July 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
بايرن
• 518886 Tweets
موناكو
• 501072 Tweets
Wizkid
• 281920 Tweets
Davido
• 258507 Tweets
Supreme God Kabir
• 132451 Tweets
からくりサーカス
• 108777 Tweets
#BrightestStarBangChan
• 101129 Tweets
#우리의_찬란한_청춘_방찬에게
• 100161 Tweets
Universidad Pública
• 84276 Tweets
Doug Emhoff
• 58278 Tweets
青木選手
• 58001 Tweets
Shakira
• 49729 Tweets
SPILL THE FEELS TRACK LIST
• 43596 Tweets
CHAE X JESBIBLE
• 43157 Tweets
Shana Tova
• 36797 Tweets
Gago
• 32508 Tweets
Cassper
• 31316 Tweets
Rosh Hashanah
• 30239 Tweets
KARIME EN HOY
• 28042 Tweets
Centro Carter
• 27003 Tweets
GALA EN HOY
• 26756 Tweets
שנה טובה
• 24079 Tweets
Lille
• 22726 Tweets
センラさん
• 17027 Tweets
Channie
• 13409 Tweets
ITZY IS THE MOMENT
• 10999 Tweets
Girona
• 10773 Tweets


















Pinned Tweet

Delighted to release our first project
@argmaxinc
. Real-time Whisper inference on iPhone and Mac! Let us know what you think❤️🔥
3
2
40
Exciting updates to
#stablediffusion
with Core ML!
- 6-bit weight compression that yields just under 1 GB
- Up to 30% improved Neural Engine performance
- New benchmarks on iPhone, iPad and Macs
- Multilingual system text encoder support
- ControlNet
🧵

23
304
2K
Stable Diffusion XL on iPhone with Core ML!
- 4-bit weight compression
- Works on iOS 17 & iPhone 13 Pro or newer
- Other features and improvements to the repo 🧵
22
199
1K
As part of
#WWDC22
, we are open-sourcing a reference implementation of the Transformer architecture optimized for the Apple Neural Engine (ANE)!
(1/n) 🧵

8
130
647
Delighted to share
#stablediffusion
with Core ML on Apple Silicon built on top of
@huggingface
diffusers! 🧵

9
92
498

My takeaways from Apple's “LLM in a flash" (1/n)

Apple announces LLM in a flash: Efficient Large Language Model Inference with Limited Memory
paper page:
Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their

32
488
3K
3
68
372

35 TFlops of ML compute in your pocket! (
#iPhone15Pro
) On-device inference is getting interesting..
#AppleEvent

14
21
221
Apple Intelligence hits the market in beta today: A pretty impressive 2.6b on-device LLM running on the Neural Engine compressed down to ~1GB. It consumes way below 10W.
Congrats to my former teammates & colleagues on landing this!
Tech report is also out:

Depending on the task you give Apple Intelligence, it can peak up to ~5.5W on the ANE
Mail summarization is less than 1-2W, but rewriting here hits up to around 5.9W. This is admittedly very efficient.
Also, it did a better job at re-writing this document than Gemini did lol
26
78
1K
4
18
184
Please refer to our code repository for details:
3
23
166
Thanks
@Apple

WhisperKit is 40% faster on iOS 18
Improved from 165 to 237 tok/s on whisper-base
Repo:
Test App:
4
37
281
2
6
125
Persimmon-8b LLM (
@AdeptAILabs
) has ~95% activation sparsity in many of its layers which is crazy! Here is a gist that prints some stats. Most zeros are shared across tokens too:

1
11
121
Today's release of macOS Ventura 13.1 Beta 4 and iOS and iPadOS 16.2 Beta 4 include optimizations that let Stable Diffusion run with improved efficiency on the Apple Neural Engine as well as on Apple Silicon GPU
2
15
119
For distilled
#StableDiffusion2
which requires 1 to 4 iterations instead of 50, the same M2 device should generate an image in <<1 second:

Distilled
#StableDiffusion2
> 20x speed up, convergence in 1-4 steps
We already reduced time to gen 50 steps from 5.6s to 0.9s working with
@nvidia
Paper drops shortly, will link, model soon
Will be presented
@NeurIPS
by
@chenlin_meng
&
@robrombach
Interesting eh 🙃

59
248
1K
2
21
94

As a highlight, the baseline configuration of M2 MacBook Air with 8GB RAM runs for 50 iterations in 18 seconds.

5
15
77
We compressed the diffusion model using our Mixed-Bit Palettization technique (described in ) which yields an average of 4.04-bits (5.2GB -> 1.3GB) while maintaining higher accuracy than linear 8-bit quantization. Compressed model runs faster too!

2
13
70
Applying 1, 2, 4, 6 and 8-bit quantization via palettization yields much better results, e.g. We can use 1, 2, 4, 6 or 8-bits palettes to achieve the same compression rate as linear 8-bit quant (50%) but maintain correctness as high as 80dB (2dB loss vs 17dB for linear 8-bit)

2
9
69
This 25-minute WWDC23 session is the best resource to learn more about model compression for Apple Silicon: . We only demonstrate post-training palettization for Stable Diffusion. For better results, check out training-time palettization for 2- and 4-bits!

1
8
58
If you are excited about this field and would like to work on applied R&D in generative models, send me a note or come to the Apple booth at
#NeurIPS22
to chat with us!
2
4
54
Finally, this WWDC 23 session introduced native multilingual text embeddings through a Transformer-based model: . We share code so developers can benefit from the multilingual image generation demo workflow.

2
5
49
In our research article case study, the
@huggingface
distilbert model is up to 10x faster with 14x lower peak memory consumption after our optimizations are applied on it while consuming as low as 0.07W of power.

2
4
46
(8/n) Note that I worked with three of the authors when I was at Apple and I have immense respect for them. I wrote this review to make sure the pros and cons of this approach are clear and their work is refined to be bulletproof through feedback.

1
3
42
(3/n) Majority of the improvements in Table 2 (4.5x of 12.5x) come from "windowing" which relies on high RAM cache hit rate. This is great for beam_size=1 & batch_size=1 & query_size=1 predictions. However, 4.5x will regress towards 1x if any of these values are >1. Prompt
3
3
40
WhisperKit v0.2 is out!
On-device Inference for Apple Watch with WhisperKit shows just how little resources you need on iPhone and Mac:

1
5
37
coremltools-7.0 introduced advanced model compression techniques. For Stable Diffusion, we demonstrate how 6-bit post-training palettization yields faster models that consume 63% less memory compared to float16. Output variance is comparable to GPU vs Neural Engine.

1
4
37
Are you excited about
#generativeai
? We are looking for experts in this space to join our applied ML R&D team at
@Apple
! You will be inventing and shipping the next generation of these core technologies with a focused team and here is the link to apply:
4
10
37
The first podcast about on-device inference and our work
@argmaxinc
, enjoy!
Apple Podcasts:

Atila Orhon is the founder of
@argmaxinc
and was previously at
@Apple
. He joins the show with
@seanfalconer
to talk about scaling ML models to run on commodity hardware.
0
2
8
1
3
37
Grok-1 = 314b MoE
Mac Studio with M2 Ultra should be able to host this beast in 4-bit!
@awnihannun
👀

3
2
34
(2/n) This is a great first step in moving beyond "perceived" HW limits for on-device inference! A few shortcomings need to be addressed before this is a practical approach
1
1
34
We share sample code for model conversion from PyTorch to Core ML and have example Python pipelines for text-to-image using Core ML models run with coremltools and diffusers
1
2
32
Apple is marketing M3 Max for "AI developers to work with even larger transformer models with billions of parameters":
#AppleEvent

1
7
33
Happy to partner with
@StabilityAI
on their Stable Diffusion 3 Medium launch!
DiffusionKit now supports Stable Diffusion 3 Medium
MLX Python and Core ML Swift Inference work great for on-device inference on Mac!
MLX:
Core ML:
Mac App:
@huggingface
Diffusers App (Pending App Store review)
6
33
243
0
0
31
Code to palettize other SD models is on as usual!
1
5
30
Improvements to the attention implementation lead to 10-30% performance improvement on the Neural Engine pushing iPhone 14 Pro performance to under 10 seconds without architecture compression or step-distillation.
1
3
26
We also shared benchmarks on iPhone and iPad devices in the README. This is a v1 and there is significant margin to improve the current performance!

3
0
25
Our applied R&D team is leveraging this implementation in production for technologies such as HyperDETR which we described in a previous research article:
1
3
25
I❤️🔥Open + Diffusion + Transformer = Stable Diffusion 3
On-device Stable Diffusion 3
We are thrilled to partner with
@StabilityAI
for on-device inference of their latest flagship model!
We are building DiffusionKit, our multi-platform on-device inference framework for diffusion models. Given Argmax's roots in Apple, our first step

16
73
390
1
3
25

All mixed-bit palettization recipes as well as some of the palletized Core ML models are published on
@huggingface
Hub by
@pcuenq
: . We are looking forward to the community MBP'ed models in the coming weeks!

2
2
23
We also showcase the usage of the new CoreML Performance Report available in Xcode 14. Developers can verify the prediction timing as well as compute unit mapping of their models right in Xcode!

3
2
22
Check out the
@huggingface
blog by
@pcuenq
on Faster Stable Diffusion on Apple Silicon!

Stable Diffusion on iPhone is much faster now!
Same model, same phone (iPhone 13 Pro), same settings 🤯
The trick?
* 6-bit quantization in Core ML. Announced last week in WWDC
* Additional optimizations to the attention blocks
Check our post for details

11
76
376
1
4
22
Finally, there are extremely useful features in this release including:
- SDXL refiner Swift inference by
@zachnagengast
- SDXL base Python inference by
@HectorLopezPhD
- CUDA RNG in Swift by
@liuliu
- Karras schedule for DPMSolver by
@pcuenq
2
1
21
We also just published an accompanying research article to describe the principles behind the optimizations and empower developers to make informed decisions on ANE deployment of their ML models:

1
1
20
Great work from
@Snap
compressing Stable Diffusion to <2-bit! This is a significant improvement of the mixed-bit technique [1] we published last year to get this level of high quality results:
[1]

BitsFusion
1.99 bits Weight Quantization of Diffusion Model
Diffusion-based image generation models have achieved great success in recent years by showing the capability of synthesizing high-quality content. However, these models contain a huge number of parameters,

2
46
223
0
2
21
(4/n) The variance of latency should be relatively high given that it is runtime statistics dependent. I wish there was a histogram or variance report instead of an just the average value. Maybe it is low but still useful to know.
1
2
21
Bringing transformers to Swift!
@pcuenq
@huggingface
📢 Announcing Swift Transformers 📢
A package to run language models in native apps, on-device.
It's part of a growing set of tools to help Swift developers work with Core ML models. Read on for details, or check our post:
4 new tools released today!

14
90
378
0
1
19
(7/n) They specifically study model weights = 2 x RAM. If we extrapolate to >2x , then "neuron cache" history would need to be truncated in order to preserve constant size. This would in turn reduce the cache hit rate and cause higher traffic between flash and RAM, slowing things
1
2
19
Spoiler: It does not
Does Apple Intelligence kill third-party model performance when executing inference concurrently on-device?
Experimental results in 🧵
2
4
37
0
1
19
(5/n) They apply two approximations ("Relufication" and sparsity prediction) which would qualify as lossy execution. In this case, a stronger relevant baseline would be quantization in addition to the naive full precision baseline. If quantization errors do not compound with
5
2
19
SDXL is only supported on Apple Silicon GPU through this project for now and the compression will only yield savings for disk size. Neural Engine support will bring runtime memory and latency savings. Here are the current benchmarks:

2
1
18

The models used for iOS deployment are hosted on
@huggingface
Hub but you can always export another model version locally following the README instructions

2
0
16
(6/n) Output fidelity under lossy execution is certified via average dataset metrics which overlooks per-example or per-domain behavior changes. We should standardize & adopt inference SLAs for various output fidelities as an industry IMO.
1
2
16

Congrats to friends
@FAL
! Even though we champion on-device inference
@argmaxinc
, we believe that server-side inference has a big role to play in a hybrid inference future

We are now benchmarking
@fal
's Speech to Text Whisper endpoint and it is setting new standards in Speed Factor and Price!
fal has raised the bar with a Speed Factor of 105 (105x real time), making it an attractive option for use-cases requiring fast transcription (meeting notes
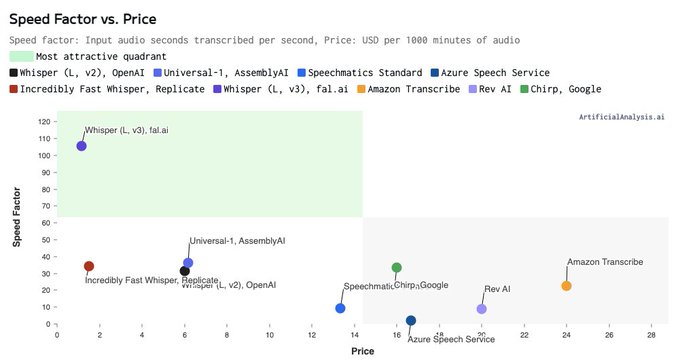
8
6
40
0
2
16
Dropping some minor improvements to
@argmaxinc
WhisperKit tomorrow :)

Neural Engine go brrr (for comparison this same CoreML pipeline on GPU pulls 60+ watts)

1
0
18
0
1
17
Let's build.❤️🔥
@generalcatalyst
🤝
@argmaxinc

What does the future of compression techniques & on-device inference software look like?
Enter
@argmaxinc
.
We're thrilled to lead its $2.6M seed & welcome
@atiorh
,
@bpkeene
,
@zachnagengast
, & team to the GC family!
By
@quentinclark
&
@AlexandreMomeni
↓
1
27
13
3
0
16
"Transformer models" on Apple Silicon were called out 3 times during the
#WWDC23
keynote! In case you missed it 🧵

1
3
14
On-device inference is big in Japan 🇯🇵 If only it was clearer that WhisperAX is just a test app and we want developers to use the underlying library😅
@argmaxinc

ローカルWhisperを、iPhoneで!?
やばすぎるww
見てみて
もう商談始まるので解説できない
通信オフ状態で
これ!
最高すぎる時代到来ww
7
359
3K
1
0
14
Enjoy!❤️🔥We have been brewing this since the initial launch in February. This release is focused on streaming performance, better compression, and addressing developer feedback 🧵
Exciting updates to WhisperKit!
- Real-time streaming mode is several times faster
- 4-bit matches 16-bit with Data-free QLoRA
- Extended quality benchmarks
- Many more new features
Details 🧵
4
22
220
1
1
13
We are actively hiring for a
#GenerativeAI
Applied Researcher! Feel free to DM me with pointers to exceptional past work 🙏
1
4
13

This is achieved by first sorting each layer using their individual impact on end-to-end output correctness and then progressively quantizing starting from the least impactful layers to achieve a given model size reduction. Remaining layers are left as 16-bit.
1
1
12
First, we quantify output correctness as the signal strength (PSNR in dB) at the output of the Unet after 1 denoising step. The original float16 model has a strength of 82dB and linear 8-bit quantization loses 17dB of signal wrt the reference and sets a baseline at 65dB.
1
0
13
As a highlight, 65dB linear 8-bit output correctness baseline is matched by the mixed-bit strategy at an average of 2.71-bits. Anecdotally, for best quality, we still encourage the usage of >=4 bits in order to do justice to the SDXL model!

1
2
12

This work would not have been possible without extensive collaboration between hardware and software teams, enabling us to optimize across the stack
0
2
11
@pcuenq
@zachnagengast
@huggingface
If this work is interesting to you, you should consider joining us:
0
1
10
Going one step further, we devise a mixed-bit strategy algorithm, dubbed MBP, that aims to pick the lowest number of bits while still adhering to an output correctness lower bound. This yields the best results when the average number of bits drops below 6.
1
0
10
Excited about this line of work from
@cartesia_ai
!
@krandiash
and team are focused on proving the value of state-space models by building best-in-class models themselves. Looking forward to the on-device implementation.

Today, we’re excited to release the first step in our mission to build real time multimodal intelligence for every device: Sonic, a blazing fast (🚀 135ms model latency), lifelike generative voice model and API.
Read and try Sonic

43
163
820
0
0
8
Fun fact: This demo is from a recent
@theallinpod
where
@chamath
talks about OpenAI's "microphone" (Whisper) hallucinating "Thank you for watching" given a silent input. In this release, we implemented a hallucination guardrail (h/t
@_jongwook_kim
):

Whisper distil-large-v3 from
@huggingface
also landed in this WhisperKit release! Compared to large-v3:
- 6x faster and 50% smaller
- Virtually the same evaluation metrics
- In our evals, slightly better than OpenAI API
Test it in 2 mins:
- App:
- CLI:
6
40
220
0
1
8
2
0
8
1
0
9
swift-coreml-diffusers from
@huggingface
built on top of !
We are open sourcing a native Swift app for Stable Diffusion!
It integrates Apple's Core ML library (released last week) and the fastest scheduler (DPM-Solver++), which we ported to Swift from diffusers!
Generation time: ~10s in my M1 Max 🚀

9
45
305
0
0
7
@danielgross
Base M2 MacBook Air should be roughly equally performant for this model on the Neural Engine
0
0
6
@MaxWinebach
If you want to leverage the Neural Engine, give a shot if you haven't used it already.
1
0
6
If you want to build the best on-device inference frameworks in open-source and shape the future of the industry, DM me!

0
2
7
This is the economical sweet spot for server-side inference: Operating with predictable non-urgent workloads to achieve high utilization albeit with high latency. Curious to see how much traffic this gets and which products pivot to leverage this differential pricing...

Introducing the Batch API: save costs and get higher rate limits on async tasks (such as summarization, translation, and image classification).
Just upload a file of bulk requests, receive results within 24 hours, and get 50% off API prices:

94
345
2K
0
0
7
⚠️Extremely important notice for pytorch-nightly users, dependency chain was compromised:
#pytorch

0
0
7
1
0
7
Great to see more and more on-device Transformer models across the operating system every year! If you want to deploy your own Transformer models in your apps, here is how to get the most out of the Neural Engine for the same:

0
3
7

If distilled
#StableDiffusion
follows verbatim, negative prompts would be disallowed. On the other hand,
#StableDiffusion2
seems to rely even more on negative prompts for best results 🤔
@hardmaru
1
1
6
I don't want to contribute to the speculation around this Claude 3 result but it reminds me of
@karpathy
's fun experiment: "Do LLMs know they are being evaluated?"

Fun story from our internal testing on Claude 3 Opus. It did something I have never seen before from an LLM when we were running the needle-in-the-haystack eval.
For background, this tests a model’s recall ability by inserting a target sentence (the "needle") into a corpus of
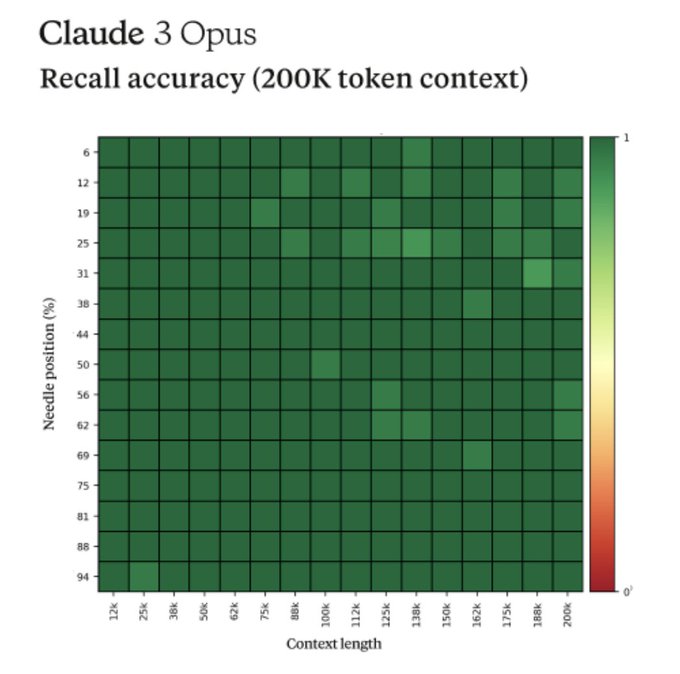
577
2K
12K
0
0
6
@zacharylipton
@togelius
I am curious about your thoughts on recent work in differentiable curriculum learning:
0
1
6
Our team (mainly
@Arda_Okan97
) compressed Whisper down to <1GB (>3x) without a quality loss:
- Setup: LoRA fine-tuning with compressed weights
- Dataset: Random noise
- Loss: Distillation from uncompressed model
4-bit matches 16-bit with Data-free QLoRA
QLoRA by
@Tim_Dettmers
et al. is a great technique for recovering quality in a heavily compressed model but it generally requires a training dataset for fine-tuning. We (
@Arda_Okan97
) do not use a dataset and demonstrate that QLoRA works
1
3
16
1
1
5
AI exec order: Engineering and research workarounds (innovation) for the 1e26 FLOPs and the 100Gbps figures are likely a moo point. Similar to the H800 with reduced interconnect and tightened Chip Export Ban.. (1/n)

1
0
5
27:40: “The keyboard now leverages a Transformer language model, which is state-of-the-art for word prediction, making autocorrect more accurate than ever. And with the power of Apple Silicon, iPhone can run this model every time you tap a key”

1
1
4
Delighted to share one of the scene understanding technologies that we have built for the Camera!
#AppleEvent
#machinelearning
0
0
4
It was a privilege working in
@ctnzr
’s world-class team for 3 months back in 2017, I had exploding gradients in my career that summer! Regarding soft skills: I still prepare my prez based on his “research communication” principles

1
0
4
We call this Data-free QLoRA. This is a step towards automatic fine-tuning for model-agnostic and dataset-agnostic compression. We are already leveraging this technique with customer models that are not Whisper. The models and evals are here:
1
0
4