

XY Han
@XYHan_
Followers
1,479
Following
1,131
Media
76
Statuses
1,440
Assistant Professor @ChicagoBooth | Papers: “Neural Collapse in Deep Nets” & “Survey Descent: Nonsmooth GD” | BSE @Princeton , MS @Stanford , PhD @Cornell
Chicago, IL
Joined November 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
LINGORM HOWE 12TH ANN
• 1104293 Tweets
DeSantis
• 457260 Tweets
60 Minutes
• 448559 Tweets
#6284üuygula
• 260137 Tweets
#istanbulconventionkeepsalive
• 249409 Tweets
The View
• 182556 Tweets
CONGRATS FOURTH
• 174249 Tweets
#istanbulsözleşmesiyaşatır
• 145323 Tweets
Iniesta
• 142191 Tweets
Jets
• 101199 Tweets
जम्मू कश्मीर
• 89907 Tweets
Saleh
• 77442 Tweets
#いれいす活動4周年
• 73930 Tweets
Burna
• 70381 Tweets
Alexandra
• 51619 Tweets
Rodgers
• 51081 Tweets
Bob Woodward
• 47501 Tweets
BBS RAIN
• 38695 Tweets
#PortfolioDay
• 36772 Tweets
BBS FYANG
• 31359 Tweets
ITZY GOLD TEASER 1
• 26087 Tweets
에드워드
• 21695 Tweets
PERSES IS BACK
• 17780 Tweets
Logan Act
• 17398 Tweets
Junet
• 13839 Tweets
Bielsa
• 13547 Tweets
Hackett
• 13248 Tweets
復活当選
• 12819 Tweets
Igor
• 12181 Tweets



















For those who love bagels



15
239
6K
During my PhD, my advisor would tell me “never use a symbol in text without reminding what it is.”
[Example]
𝘉𝘢𝘥: “So, 𝜑 is bounded.”
𝘎𝘰𝘰𝘥: “So, the value function 𝜑 is bounded.”

I told a grad-student co-author "try to imagine me as the guy from 'Memento' who can't remember anything & needs clues to pick-up the thread on projects" and they said "I believe you, because you already used that memento analogy"
22
867
20K
20
121
2K

Job search completed: Excited to join
@ChicagoBooth
as an Assistant Professor of Operations Management starting July 2024! 🥳
Thank you to all my friends and mentors who helped me along the way 🙏🙏🙏.

29
5
319

64 GPUs for one research lab is pretty nice. Across all Stanford,
@StanfordCompute
has 700+ shared GPUs. Rumor is
@StanfordData
folks are talking of buying a new cluster of 1000+ GPUs. The point is valid, but the 64 GPU example feels misleading.


Fei-Fei Li says Stanford's Natural Language computing lab has only 64 GPUs and academia is "falling off a cliff" relative to industry
99
205
1K
11
13
75
…raising the blood pressures of Queuing theorists everywhere.

Apple announces MM1
Methods, Analysis & Insights from Multimodal LLM Pre-training
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through

16
177
950
3
1
57
@petergyang
I will sign up for whichever credit card that comes with free subscriptions to all five.
@AmexBusiness
@Chase
@Citi
1
2
55
@sirbayes
I thought a lot about this question: Did my PhD in a dept with optimizers who love linesearch. Within the classic optimization community (the SIOPT/ICCOPT/ISMP crowd) I think linesearch is pretty popular. Within ML, the problem is memory: you need to keep yet another copy of your
3
0
52
FOUR new Neural Collapse works accepted to
#NeurIPS2022
investigating (1) Neural Collapse on different losses, (2) as modeled as Riemannian gradient flow, (3) as a motivating design network classifier design, and (4) under class imbalance. Congrats to all the authors!! 🥳




2
8
46
Fun story Erhan Çinlar told us in Princeton’s ORFE 309 course: Back in the day, US academics were deciding what to call math-for-decision-making. A good name already existed: 𝘤𝘺𝘣𝘦𝘳𝘯𝘦𝘵𝘪𝘤𝘴. 𝗕𝘂𝘁 it was the Cold War and “cybernetics” was a term already used by the

After “neural networks” and “artificial intelligence”, likely the next name that should and will redeem itself is “cybernetics”.
5
13
118
2
2
37
@weijie444
Does it feel good to continue using "we" despite it being a single-author paper as well? 😅
1
0
28
Recruiting faculty or postdocs in OR or ML? Check out the
@Cornell_ORIE
PhD candidates on the academic market this year! 🥳

0
6
28
TEN new Neural Collapse related submissions found in
#ICLR2023
. 🤩🥳👏
The original NC paper took almost 3 years of exploring and experimentation to write. Extremely grateful to see so many now share our interest. 🙏🙏🙏



1
4
27
Amazing survey on the subtleties, historical contexts, and open questions of Neural Collapse. Very readable & comprehensive. One of the best so far! ⭐️⭐️⭐️⭐️⭐️
To authors
@kvignesh1420
, E. Rasromani, & V. Awatramani: Thanks x💯 for your interest in NC and this fantastic review!




"Neural Collapse: A Review on Modelling Principles and Generalization",
Vignesh Kothapalli, Ebrahim Rasromani, Vasu…
0
0
4
4
11
26
Two exciting new papers examining Neural Collapse in
#ICML2022
(both spotlights!). Congratulations to the authors!
(T. Tirer and
@joanbruna
) and ( J. Zhou, X. Li, T. Ding, C. You,
@Qing_Qu_1006
, and
@ZhihuiZhu
)


0
3
27
Proud to share this new work with my supervisor, Adrian Lewis, in which we develop a multipoint generalization of gradient descent for nonsmooth optimization. (1/4)

X.Y. Han, Adrian S. Lewis: Survey Descent: A Multipoint Generalization of Gradient Descent for Nonsmooth Optimization
1
2
6
2
6
25
Feynman didn't live with people making 20k new submissions to ArXiv a month.


Know how to solve every problem that has been solved.
- Richard Feynman

60
215
2K
0
1
24
Why is Neural Collapse interesting? This and other discussions in this new interview. Thanks
@aihuborg
!


1
7
24
Fun stories from
@Princeton
: During undergrad, Tarjan subbed for one of our Intro Algorithms (COS226) lectures. He started with this beautiful remark:
“Hi, I’m Bob Tarjan… Not Bob Sedgewick. Bob Sedgewick wrote your textbook. I wrote the algorithm 𝘪𝘯 your textbook.”

Bob Tarjan, starting his talk on sorting with partial information at the
@SimonsInstitute
Sublinear Algorithms program

6
7
99
0
0
22
Turning off phone email notifications has significantly improved my quality of life.
2
0
20
On “Future Directions”: A Suggestion for the Academic Job Market
“Future Directions” is often the hardest part of the research statement. Took me multiple rewrites. Eventually, I found the following trick useful.
Imagine you got the faculty position. Visualize yourself living
1
0
19
How does neural collapse connect to prior works on implicit max-margin separation like Lyu & Li 2019, Soudry et al 2018, and Nacson et al 2019?
W.Ji,
@2prime_PKU
, Y.Zhang,
@zhun_deng
&
@weijie444
solidifies the connection in their new
#ICLR2022
paper. 9:30PM EDT!

1
5
18
👏👏👏 Much needed and overdue.
A huge personal pain point for me as an opt researcher is that popular constrained opt solvers (cvxpy, gurobi, mosek, etc) require specialized syntax for the constraints and end up moving back to CPU and so can't advantage of GPU matmult... (1/2)

Together with
@phschiele1
, we wrote a package to solve constrained optimization problems, where all functions are arbitrary
@PyTorch
modules.
This is mainly intended for optimization with pre-trained NNs as objective/constraints.
3
13
52
1
1
13
Pre-2010, it went the other way. I still see Stats folks who roll their eyes at CS seminar speakers who lack mathematical rigor... and CS folks who dismiss Stats speakers as useless-for-SoTA. We all find different problems interesting: nobody's better than anyone else.


1
1
13
When I’m asked where one might start to learn about Neural Collapse. This survey is 𝘢𝘭𝘸𝘢𝘺𝘴 among my top recommendations. Ecstatic to see it cross the finish line. Congrats
@kvignesh1420
!! (The reviews & discussion are amazing too! Hits on some key points 👏👏👏.)

Neural Collapse: A Review on Modelling Principles and Generalization
Vignesh Kothapalli.
Action editor: Jeffrey Pennington.
#classifier
#generalization
#deep
0
11
30
3
1
13
@bradneuberg
The only way to get them is to keep paying Google per hour. You can’t just buy one with funding—whether it’s VC, academic, or otherwise. Plus, earlier on, it only worked with Tensorflow. It was only 3-4 years after that PyTorch compatibility came along. The performance was
0
0
12
Make sure conferences reject you for writing exactly the papers you want written. That, you can live with.

Dave Letterman’s advice to Jerry Seinfeld: “Make sure you fail doing exactly what you want to do. That, you can live with.“
55
824
5K
0
0
12
@Adam235711
It’s useful for the “surrogate loss” argument in theory. Specifically: (1) somebody develops a convex loss that doesn’t do too bad; (2) most of the time, it doesn’t actually catch on outside of the research group that developed it; (3) But, using it doesn’t change the behavior of
1
0
12
Important info for new PI's buying compute hardware! It's more than just GPUs. If you don't get the interconnect (go for infiniband) and storage type (go for NVME or SAS SSDs) right, you're gonna get bottlenecked by dataloading no matter how good your GPUs are.

The Machine Learning Engineering Networking chapter has been updated with multiple provider intra- and inter-node connectivity information/specs and easy to use bandwidth comparison tables:
If I'm still missing some commonly used

5
10
137
2
1
11
Neural collapse observes last-layer class variation collapses 𝘵𝘰𝘸𝘢𝘳𝘥𝘴 0 with training. 𝗕𝘂𝘁: As it does, one can 𝘴𝘵𝘪𝘭𝘭 find informative, fine-grained structures in the residual small variations at 𝘧𝘪𝘹𝘦𝘥 epochs (even ones that look “collapsed”!).
Check out this

Today at
#ICML2023
,
@YongyiYang7
is presenting "Are Neurons Actually Collapsed? On the Fine-Grained Structure in Neural Representations."
We discovered important fine-grained structure exists in NN representations despite the apparent "Neural Collapse."
See you at 2-3:30pm!

1
3
40
0
2
12
Since this got quoted (thanks
@damekdavis
!), good time to update that Survey Descent is now published in the SIAM Journal on Optimization!



1
1
10

2
5
10
@sp_monte_carlo
"linear convergence" was confusing af until
@prof_grimmer
told me during the 2nd year of my PhD "linear means linear in log-scale". I actually added a footnote to my job market research statement just to not confuse non-specialists:

0
0
11
@docmilanfar
Spoiler: You can find
@docmilanfar
’s face by zooming enhancing into the red squares using the Pixel 9.
0
0
11
I want a LLM-upgrade plan that switches my subscription whenever a new benchmark comes out.
(GPT 4.5 -> Gemini Pro 1.5 -> Claude 3 -> ???)
Maybe with unlimited text and data?
@Verizon
@ATT

Today, we're announcing Claude 3, our next generation of AI models.
The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reasoning, math, coding, multilingual understanding, and vision.
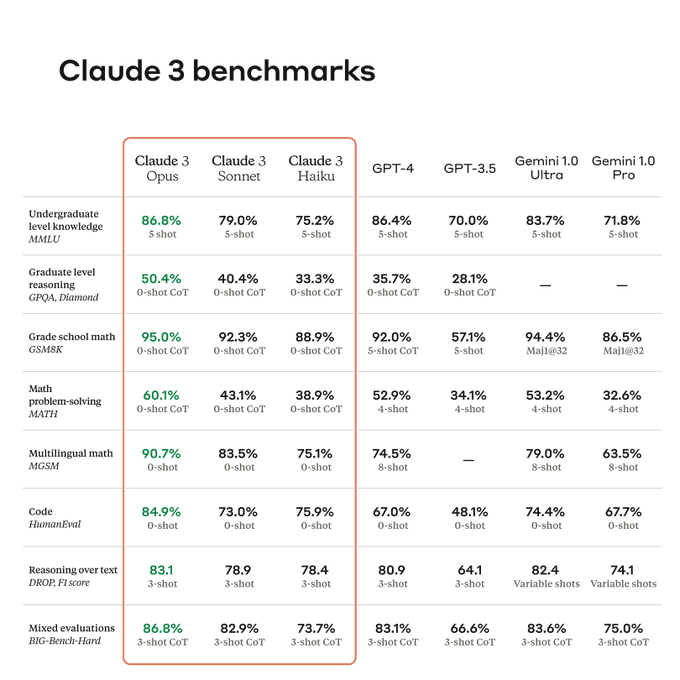
570
2K
10K
1
0
10
What if you pass out-of-distribution data into NNs showing neural collapse? How's that useful?
Turns out, the out-of-distribution data become orthogonal to in-distribution data & you can then use that to detect those OOD points.




1
5
10
The next PhD life hack:

TIL Costco sells a pallet of freeze-dried food.
Preppers can buy 5,400 servings of food with a 25 year shelf life for $2,500
Lots of pasta and rice dishes, some soups, oatmeals & milk. Just add water!
910,080 calories, 364 calories/$.

106
173
5K
1
3
10
@ben_golub
They do. Candidates can and do ask schools to match offers. The power is usually in a Dean’s hands. Prob is Deans have to be fair across the school (ex. Art & Sci or Eng) they oversee. Paying a new CS prof more than a tenured math prof will piss ppl off, for example.
1
0
9

While a previous work claims happiness peaks at 10,000 H100 GPUs; a new PNAS study shows that happiness continues to grow with resources up to 500,000 H100 GPUs for the top 30% of the GPU rich.


I just want everyone to be happy and have enough money to afford 10,000 H100s.
27
17
338
1
0
9

Don't forget "the Delta Method" (AKA Taylor's Theorem)

0
0
9
At my fastest during the job market, I could pack for a four-day trip from scratch in <30 mins. Now, I’ve deteriorated to… more than twice that. Didn’t know you could lose muscle memory on these things… 😥
2
0
8
@docmilanfar
It’s also mindblowing that a still-active researcher was already a grad student and part of someone’s origin story a year before I was even born. 😵💫
1
0
9
My biggest question: Was $42 chosen because it’s the optimal price or because of the Hitchhiker’s Guide to the Galaxy reference? 🪐


1
1
7
@damekdavis
Check out this talk by Dave Donoho at IHES! He elaborates on this point and the existence of two cultures (empirical results vs theorem proving) there.

0
0
8
This is my default grading policy as well:
• If you do A+ work with AI, you get an A+.
• If the AI plagiarized or made things up, you get an 0 as if you did it yourself.

I just don't get why people are trying to detect whether AI is being used for writing instead of just grading whether the writing is good or bad. If student A uses AI and writes better than student B, student A should get a better grade than student B
569
89
2K
0
1
8
Also, in the tech specs, note the 1493 “privately owned” nodes. Those are nodes associated with specific PI groups (many containing GPUs). Sherlock contributors can use the idle nodes of other PI groups as well making effective number of shared GPUs much higher than 700.
0
0
8
I nominate the NeurIPS latex template for the Test of Time Award.

Yearly reminder: To get natbib \citep and \citet commands working properly with NeurIPS citation style (numbers rather than author lists), use the following commands.
\usepackage[nonatbib]{neurips_2021}
\usepackage[numbers]{natbib}
...
\bibliographystyle{abbrvnat}
4
18
302
0
0
7
@miniapeur
There’s this guy who was a physicist who became a US senator for New Jersey. I remember lots of faculty at
@Princeton
liked him because it was nice getting represented by a real scientist.
.
2
0
7
@YiMaTweets
What do you think of WizardLM from PKU and Yi from as representatives of Chinese open source AI? They seem to be doing well in the leaderboards…
0
0
6
Honestly, I prefer reading clear GPT-assisted emails rather than deciphering intentions in unclear, "organic" ones. ChatGPT is effectively the modern version of spellcheck/Grammarly. The same for class assignments --- as long as students take responsibility for GPT-induced errors

It's unjust to criticize students, especially non-native English speakers for using ChatGPT to communicate. They might be investing extra time in crafting these emails, navigating linguistic and cultural nuances. Just to clarify,this tweet was crafted with the help of ChatGPT!
4
1
40
1
0
7
This 💯
I realize this is seemingly an unpopular opinion, but I can't get onboard with these Twitter criticisms of some of the recent
#ICML2022
best paper awardees. I've been thinking about this all day. A thread... 🧵 1/N
20
85
910
0
0
7
"No management overhead or product cycles" & "insulated from short-term commercial pressures" is. literally. academia.
But, instead of asking NSF for $200-500k,
@ssi
raised many times that from VCs purely on reputation. This is what happens when you beat the game🤯.

Superintelligence is within reach.
Building safe superintelligence (SSI) is the most important technical problem of our time.
We've started the world’s first straight-shot SSI lab, with one goal and one product: a safe superintelligence.
It’s called Safe Superintelligence
1K
2K
14K
1
0
7

Sometimes, I wonder if I really became a better worker during my PhD or if it’s just because ChatGPT came out during that time.

0
0
7
@damekdavis
My personal thoughts (influenced by co-teaching a course on this) is that the definition of "way forward" is slightly vague.
If we define it as
(1) creating new tools that push forward society. Then, even if there is something special about transformers and neural nets,

1
0
6

@ben_golub
My understanding (from having done a salary neg b/n a bschool and an eschool) is there’s flexibility in the pay, but the discrepancy can’t be too big and needs to be justifiable by how much money the dept’s masters program and alum donations pull in.
@zacharylipton
Is this really a university-level decision? Isn’t dept funding and salaries is tied to the profitability of the corresponding Masters-level program?
As in, Tepper’s MBA tuition ($39k) is 1.34x the SCS MS tuition ($29k) at CMU.
1
0
4
1
0
7
@Adam235711
From what I’ve seen, SOTA methods tend to come out of lots of trial-and-error by researchers who are good at having hunches about data and choosing which ones to act on. In implementation, they draw from their math-education to make design decisions. Since opt courses tends to
1
0
6

@bhutanisanyam1
Such a guide would be immensely helpful. I am an academic AI researcher who recently went through the (quite challenging) process of building a GPU cluster.
Questions I wished I understood beforehand (and still am still fuzzy on) are the following:
1) What should researchers
0
0
6

@QuanquanGu
The M/M/1 queue is to Queuing theory what the Gaussian distribution is to statistics.

1
0
6
In Operations Research, through the lens of DLD's Data Science at the Singularity, it's trickier to achieve both [FR1: Common Data] and [FR3: Common Benchmarks] since modeling context/structure in OR often entails modifying the data collection itself.




@ProfKuangXu
The challenge I’ve seen is that many benchmark datasets strip away a lot of problem context — like the miplib library. Without the richness of setting, it’s hard to use them broadly.
2
0
3
2
0
6
Interesting new paper proposing a NC-inspired loss that mitigates undesirable biases when training deep nets on imbalanced data. Builds upon the prior work of C.Fang,
@hangfeng_he
,
@DrQiLong
, &
@weijie444
showing minority collapse under imbalanced training. (1/2)

Neural Collapse Inspired Attraction-Repulsion-Balanced Loss for
Imbalanced Learning - Liang Xie
0
0
2
1
2
6
Interested in a POST-DOC combining AI/ML and optimization? Prof. Baris Ata (
@ChicagoBooth
) is HIRING!
Contact:
Link:


0
1
6
The type of creativity you can’t replace (yet?) with AI~ 👏

The greatest accomplishment of my statistics career has been winning this year’s
@UCBStatistics
T-shirt design competition with a
@SFBART
-inspired shirt designed w/
@aashen12
!
{stats nerds} ∩ {public transit nerds} ≠ ∅ 📉🚅

4
9
72
0
0
5
@alz_zyd_
Uncomfortable part is that a non-negligible part of K-12 teachers’ skillset is memorizing and teaching students to go through the motions. If AI is allowed in K-12 classrooms, it calls into question the entire training of K-12 teachers trained pre-2022. It’s clear the curriculum
0
0
5
Library of Babel by Luis Borges. Generated using first few lines using
#dalle
!

Your periodic reminder that, no matter how novel your ideas and groundbreaking your paper, you already have been scooped by Jorge Luis Borges.
7
9
98
1
0
4
@schmidtdominik_
@MinqiJiang
What software did you use to generate those UMAP plots? They are beautiful…
1
0
5

Check out this new
#ICLR2024
paper by
@Mouin_ben_Ammar
,
@nacim_belkhir
,
@SebastianGP13
, A. Manzanera, &
@GianniFranchi10

1
2
5
@ShiqianMa
@sirbayes
I thought about it from this angle too: Forward passing on a deep net is expensive. But I couldn't quite convince myself for the following reasons.
(1) You have to do function evaluations for SGD too. In fact, linesearch evaluations are better evaluation/compute-wise because you
0
0
5
@ben_golub
😮 I didn’t know about that. I can only speak to the discrepancy between operation research (engineering) and operations management (business) that draws from the same pool of people. From what you say, a different mechanism does seem at work there… thanks for the insight!
1
0
5
Sparsity is achieved *without* the familiar l1 penalization. And it simply uses gradient descent on kernel loss without extra “tricks”. Worthwhile read with original ideas and new techniques.

On the Self-Penalization Phenomenon in Feature Selection. Michael I. Jordan, Keli Liu, and Feng Ruan
1
0
1
1
0
5
@damekdavis
@MountainOfMoon
@HDSIUCSD
@UCSanDiego
Congrats to you both 🥳! I’m now waiting for the singularity event if you two ever end up in the same place. 🤠
0
0
5
“I have a truly marvelous demonstration of 1M token context which this margin is too narrow to contain.”

Demis Hassabis admits that Google has some secret sauce in how Gemini is able to process 1-10m token context windows. The extreme context length in Gemini 1.5 Pro "can't" be achieved "without some new Innovations". This is an astonishing development that seems to hint at
15
73
368
0
0
3
[Then:] Read the final, published paper. It’s the most polished!
[Now:] Find the preprint. It’s formatted as the authors wanted without copyediting artifacts.
1
0
4