

Qian Liu
@sivil_taram
Followers
4K
Following
3K
Statuses
1K
Researcher @ TikTok 🇸🇬 📄 Sailor / StarCoder / OpenCoder 💼 Past: Research Scientist @SeaAIL; PhD @MSFTResearch 🧠 Contribution: @XlangNLP @BigCodeProject
Joined November 2021
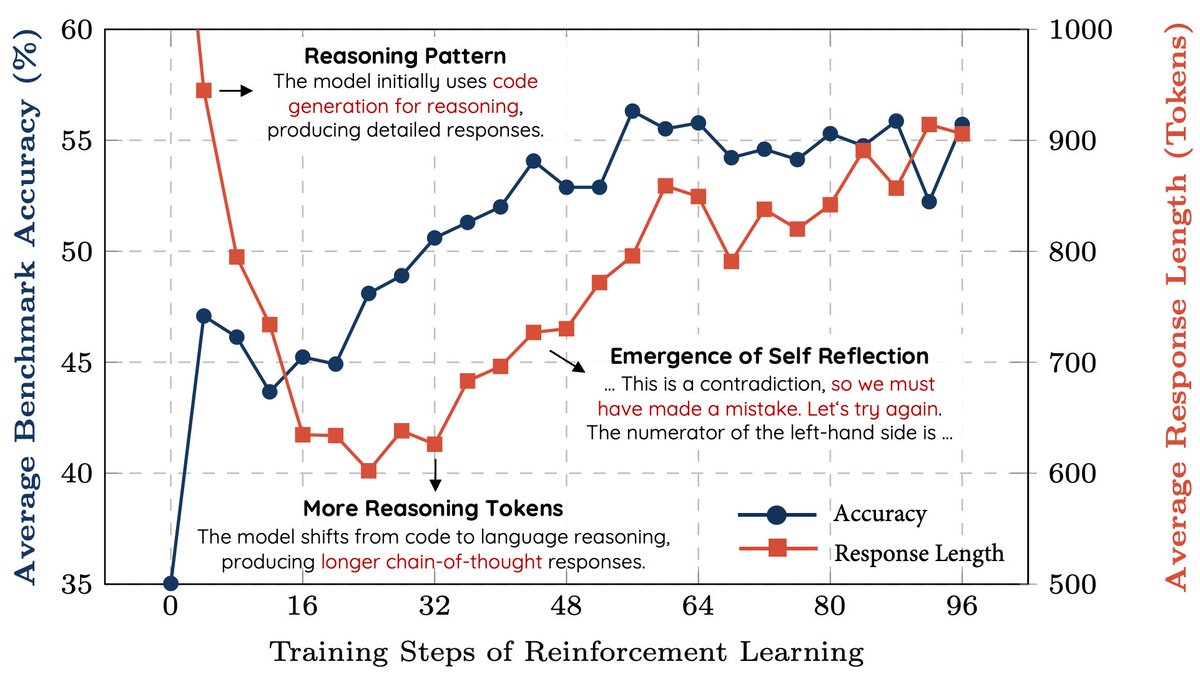
🚀 After 5 days of DeepSeek-R1, we’ve replicated its pure reinforcement learning magic on math reasoning — no reward models, no supervised fine-tuning, from a base model — and the results are mind-blowing: 🧠 A 7B model + 8K MATH examples for verification + Reinforcement Learning = "aha moment" 🌟 Long Chain-of-Thought and Self Reflection emerge naturally 🔥 Record Math Performance: ✅ 33.3% on AIME ✅ 62.5% on AMC ✅ 77.2% on MATH 📈 Outperforms Qwen2.5-Math-7B-Instruct and matches strong methods like PRIME and rStar-MATH, despite using >50x less data and just the simple PPO algorithm! 🔬 Checkout more details at Junxian's post!

We replicated the DeepSeek-R1-Zero and DeepSeek-R1 training on 7B model with only 8K examples, the results are surprisingly strong. 🚀 Starting from Qwen2.5-Math-7B (base model), we perform RL on it directly. No SFT, no reward model, just 8K MATH examples for verification, the resultant model achieves (pass@1) 33.3% on AIME, 62.5% on AMC, and 77.2% on MATH, outperforming Qwen2.5-math-7B-instruct and being comparable to PRIME and rStar-MATH that use >50x more data and more complicated components. 🚀 Increased CoT length and self-reflection emerge We share the details and our findings in the blog: Training code and implementation details here:

13
150
814
RT @terryyuezhuo: @huybery Thanks @huybery! For anyone interested in this and wanting to follow up, please join our discord! We'll release…
0
2
0
RT @TrlWorkshop: We're excited to share that the 4th Table Representation Learning (TRL) workshop will be held at ACL 2025 in Vienna 🇪🇺. W…
0
9
0
RT @LoubnaBenAllal1: The wait is over: our SmolLM2 paper is out—a detailed guide for building SOTA small LMs. While most LM papers skim ove…
0
99
0
RT @junxian_he: Nice to see more controlled experiments are performed to reveal the science behind long CoT models. We are also organizing…
0
3
0
Fantastic insights and takeaways! The discussions following the release of R1 have been incredibly enriching. 🔥The true power of open science.

Demystifying Long CoT Reasoning in LLMs Reasoning models like R1 / O1 / O3 have gained massive attention, but their training dynamics remain a mystery. We're taking a first deep dive into understanding long CoT reasoning in LLMs! 11 Major Takeaways👇(long threads)

0
3
18
RT @samira_abnar: 🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, par…
0
53
0
RT @GeZhang86038849: Around one week remaining for submission! Share your insights about foundation models with us in SCI-FM @ ICLR 2025!
0
2
0
For vocabulary scaling paper (assume your tokenizer scaling law refers to this haha), we do not consider the effect of input embedding parameters to the FLOPs since it is just a look-up. The optimal vocabulary size is bounded by FLOPs budget due to the language model head FLOPs. I think this paper mainly cares about the input embedding size.
1
0
1
RT @BigComProject: Introducing 🏟️SWE Arena: An Open Evaluation Platform for Vibe Coding Unlike the current frontend-dev applications like…
0
28
0
RT @tuzhaopeng: Are o1-like LLMs thinking deeply enough? Introducing a comprehensive study on the prevalent issue of underthinking in o1-l…
0
103
0
RT @TianyuPang1: 🤔Can 𝐂𝐡𝐚𝐭𝐛𝐨𝐭 𝐀𝐫𝐞𝐧𝐚 be manipulated? 🚀Our paper shows that You Can Improve Model Rankings on Chatbot Arena by Vote Rigging!…
0
20
0
YES

0
0
5
@AlbalakAlon @sybilhyz @Grad62304977 Fair point and thanks for suggestion on the search platform - very useful!
0
0
2
RT @chrmanning: Re: “Every major breakthrough in AI has been American”: America does itself no favors when it overestimates its specialnes…
0
348
0
RT @abc43992899: 1/n: 🚀 Announcing YuE (乐) – the most powerful open-source full-song music generation model! 🎵 Tackle the lyrics-to-song ta…
0
157
0