

Morgan McGuire
@morgymcg
Followers
2,947
Following
3,954
Media
549
Statuses
6,020
Lead Growth ML @weights_biases | ex-Facebook Safety | | 🇮🇪 | Came for the bants, stayed for the rants
Ireland
Joined October 2010
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
موناكو
• 510930 Tweets
Wizkid
• 267174 Tweets
Davido
• 246224 Tweets
Supreme God Kabir
• 121254 Tweets
からくりサーカス
• 108153 Tweets
ニンテンドーミュージアム
• 98880 Tweets
#BrightestStarBangChan
• 87798 Tweets
#우리의_찬란한_청춘_방찬에게
• 86402 Tweets
#リゼロ
• 67293 Tweets
青木選手
• 57098 Tweets
フォーエバーヤング
• 53560 Tweets
Shakira
• 48465 Tweets
Doug Emhoff
• 44017 Tweets
SPILL THE FEELS TRACK LIST
• 42468 Tweets
CHAE X JESBIBLE
• 36998 Tweets
青木さん
• 33905 Tweets
Shana Tova
• 31787 Tweets
SendeKaldım AsLaz
• 30453 Tweets
woozi
• 30219 Tweets
Gago
• 29814 Tweets
Cassper
• 28311 Tweets
Rosh Hashanah
• 27685 Tweets
שנה טובה
• 21997 Tweets
KARIME EN HOY
• 16764 Tweets
センラさん
• 16662 Tweets
GALA EN HOY
• 15697 Tweets
テニプリ
• 11906 Tweets
アクロトリップ
• 11838 Tweets
ITZY IS THE MOMENT
• 10325 Tweets




















😍 This
@huggingface
tip to prevent colab from disconnecting
`
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("
#top
-toolbar > colab-connect-button").shadowRoot.querySelector("
#connect
").click()
}
setInterval(ConnectButton,60000);
`

6
107
516

The Llama 2 Getting Started guide from
@AIatMeta
is really comprehensive, with plenty of code examples for fine-tuning and inference
Delighted to see
@weights_biases
added there as the logger of choice 🤩 See the guide from Meta here:
From what I can


7
78
386

I put together a quick fastai demo implementing
@karpathy
's notebook training minGPT to generate Shakespeare
Code:
Its a quick demo, follow along on the fastai forum to see how it progresses:


I wrote a minimal/educational GPT training library in PyTorch, am calling it minGPT as it is only around ~300 lines of code: +demos for addition and character-level language model. (quick weekend project, may contain sharp edges)
34
643
3K
1
42
184
This talk from
@colinraffel
at the
@SimonsInstitute
highlighting the advantages of an ecosystem of specialist models/adapters was great - good starting place if you’re curious about how to combine/hot-swap LLM adapters

3
32
167
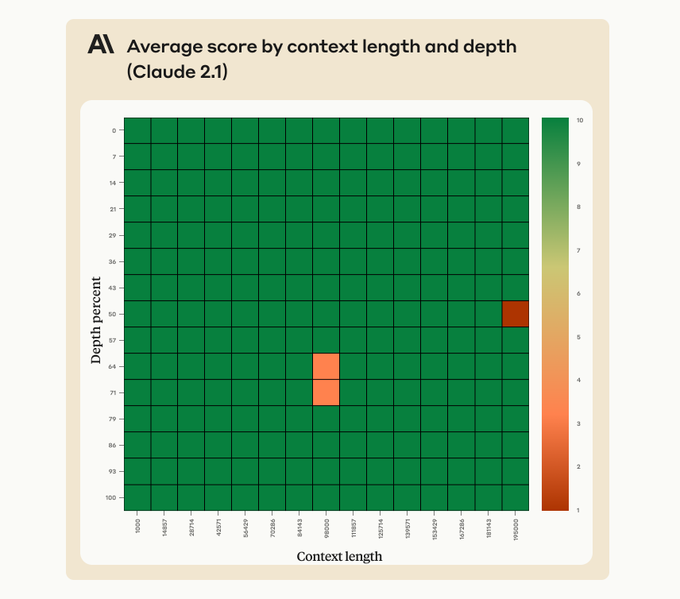
Given theres no sign of being able to use Ultra any time soon, this
@AnthropicAI
post in response to
@GregKamradt
's Claude 2.1's evaluation is probably the more useful tweet for your day today 😃


Claude 2.1’s 200K token context window is powerful, but requires careful prompting to use effectively.
Learn how to get Claude to recall an individual sentence across long documents with high fidelity:
40
197
1K
5
5
140
Any one else strugging with `gpt-4-1106-preview` ?
Using
@jxnlco
's Instructor and I'm finding `gpt-4-1106-preview` to be really bad at following instructions - only successfully generating examples for 2 out of 7 examples vs consistently 7 out of 7 for `gpt-4-0613`
Same issue
32
11
138
Anyone else notice what Falcon 40b does (and doesn’t) like to say about Abu Dhabi
> !falcon tell me something interesting
“Would you like me to tell you something interesting about technology or something about Abu Dhabi?”
Cool, cool, cool

10
15
129
This is a great blog post, while it points out the strong performers in time to first token and token generation rate, it also highlights other practical considerations when choosing between inference libraries:


Inference: This was a useful read comparing vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and TGI with TTFT and Token generation rate comparisons and ease of use and other practical insights
It's concise and to the point, so time well spent.
Thank you,
5
49
260
2
23
130
Once you get done with the latest
@huggingface
newsletter released today, come on over and check out the first in a 2-part series of how to *comprehensively* set up and train a language model using HuggingFace Datasets and Trainer

1
23
126
A user yesterday just casually dropped a mobile client for
@weights_biases
in a GitHub issue🔥🔥🔥
Includes all metrics plus system metrics
I think this could be really useful to keep an eye on long-running training runs while you're on the move
Long-requested, delivered by
7
24
128
A couple
@weights_biases
releases from last week I'm excited about:
🪄 W&B Prompts and our new
@OpenAI
API integration
1. W&B Prompts
Track inputs & outputs to your LLM chain, inspect and debug LLM chain elements...plus a bonus
@LangChainAI
1-liner!
👉
2
23
121
Anyone want to suggest some Mixtral 8x7b fine-tuning configs to try?
Myself and
@capetorch
have 8 x H100s (thanks to
@CoreWeave
🙇) for 5 more days and are doing some explorations find a decent Mixtral fine-tuning recipe using axolotl that we can share.
What configs should we



7
20
117
Props to the
@StabilityAI
team and
@EMostaque
for sharing somuch of their LLM training procedure, configs and metrics 🙌
It’s a great nice example of sharing from their own
@weights_biases
instance for open research


Latest stable LM alpha, 3b parameters, 4 tr tokens, outperforms most 7b models & GPT-NeoX-20b 🧠
No books3 etc 👀
More to come from the great Stability AI language team, ramping up 🚀
Let’s get open intelligence to the edge 💪🏽
Full training details
25
123
744
1
17
107
PyTorch stepping into the LLM-fine-tuning arena feels huge, looking forward to seeing torchtune evolve in the coming months
Tutorials and docs are really nicely built with a blend of education (eg LoRA explainer) as well as how-tos
wandb integration the cherry on top
👇


Announcing the alpha release of torchtune!
torchtune is a PyTorch-native library for fine-tuning LLMs. It combines hackable memory-efficient fine-tuning recipes with integrations into your favorite tools.
Get started fine-tuning today!
Details:
20
298
1K
2
24
104
⚡️⚡️ Super stoked to say I've joined
@weights_biases
as a Growth ML Engineer! Looking forward to doing some fun ML with
@lavanyaai
and the team! Drop me a line here if you have any Weights & Biases questions, if I can't help I'll try find someone who can ☺️
16
4
102
I've been a huge fan of Instructor for quite a while for getting consistent structured outputs out of LLMs...
So I'm delighted to see
@weights_biases
course with its creator,
@jxnlco
finally released!

Language models have gone a long way from begging them for JSON.
We can now:
1. define models
2. reuse components
3. return to thinking about functions and structs
This is a short 30 minute series that motivates some of the reasons many of the structured extraction libraries
4
29
247
4
17
100
I'm hiring an AI Engineer for my team at
@weights_biases
If you're living in SF, enamoured by building and sharing your LLM-powered creations and would like to help take our AI developer tools to every software developer out there, my DMs are open


11
15
99
Ran a quick repo expanded to GPT-4-Turbo and Mixtral-8x7B on this non-deterministic MoE idea using modifed code from
@maksym_andr
Unique sequences generated at temperature = 0, from 30 calls:
GPT-4-Turbo : 30 👀
GPT-4-0613: 10
Mixtral-8x7B-Instruct-v1.0 : 3
GPT-3.5-Turbo : 2

GPT-4 is inherently not reproducible, most likely due to batched inference with MoEs (h/t
@patrickrchao
for the ref!):
interestingly, GPT-3.5 Turbo seems _weirdly_ bimodal wrt logprobs (my own exp below): seems like extra evidence that it's also a MoE 🤔

3
28
256
3
8
94
Llama 3.1 405B Instruct beats GPT-4o on MixEval-Hard
Just ran MixEval for 405B, Sonnet-3.5 and 4o, with 405B landing right between the other two at 66.19
The GPT-4o result of 64.7 replicated locally but Sonnet-3.5 actually scored 70.25 🤔

6
19
92
Fastai was my first deep learning course that stuck and the place that gave me the confidence to start writing about ML
I owe most of where I am to this special course and community ♥️

After 2 years, Practical Deep Learning for Coders v5 is finally ready! 🎊
This is a from-scratch rewrite of our most popular course. It has a focus on interactive explorations, & covers
@PyTorch
,
@huggingface
, DeBERTa, ConvNeXt,
@Gradio
& other goodies 🧵
116
1K
5K
2
5
87
Before ICLR craziness overtook things I wrote up a post on how to pre-train or fine-tune a RoBERTA
@huggingface
model with
#fastai
v2
With it you can train RoBERTa from scratch or else fine-tune it on your data before your main downstream task

4
20
86

🚀 Hiring - ML Engineer, Generative AI 🚀
Our Growth ML team at
@weights_biases
is hiring!
We're looking for someone to join us in creating engaging technical content for all things Generative AI (primarily LLM-focussed) to help educate the AI community and showcase how W&B's
8
11
70
Some notes from the Mixtral paper:
Strong retrieval across the entire context window
Mixtral achieves a 100% retrieval accuracy regardless of the context length or the position of passkey in the sequence.
Experts don't seem to activate based on topic
Surprisingly, we do not


2
9
71
Article updated: Demo applying
@huggingface
"normalizers" from tokenizers library to your Datasets for preprocessing
Informative article update 🤓 or opportunity to add another gif to the post 🥳? You decide...
(thanks
@GuggerSylvain
for highlighting)

Once you get done with the latest
@huggingface
newsletter released today, come on over and check out the first in a 2-part series of how to *comprehensively* set up and train a language model using HuggingFace Datasets and Trainer
1
23
126
0
19
70
"I hope someone can build a really valuable business using this course, because that would be a real RAG to Riches story" -
@AndrewYNg
Well well Andrew, update on our in-production support bot (powered by
@llama_index
) coming tomorrow 😜


New short course on sophisticated RAG (Retrieval Augmented Generation) techniques is out! Taught by
@jerryjliu0
and
@datta_cs
of
@llama_index
and
@truera_ai
, this teaches advanced techniques that help your LLM generate good answers.
Topics include:
- Sentence-window retrieval,
70
492
3K
0
11
69

First time looking at Gemini caching
32k : minimum cache input token count required
**forever** : how long you can keep things cached if you like
caching only saves costs : no latency wins (for now), h/t
@johnowhitaker
Would love a lower minimum token count and latency


Great news for
@Google
developers:
Context caching for the Gemini API is here, supports both 1.5 Flash and 1.5 Pro, is 2x cheaper than we previously announced, and is available to everyone right now. 🤯
30
159
1K
6
8
64




Working with Opus within Cursor was a decent enough experience to turn all my Instructor code for a particular task into a nice mermaid diagram - makes explaining the validators + retries much clearer.
Being able to ask for corrections while easily referencing



@Teknium1
Was messing around with the below.
Examples seemed to help with diagramming more complex fns, but the system prompt alone worked well enough most of the time.
Including "- Use quotes around the text in every node." helped w/ the invalid nodes
0
0
20
2
2
54
.
@Noahpinion
said it better than I could here, this was a really fantastic interview with Sarah Paine


Learned so much from Sarah Paine, History & Strategy Professor at Naval War College
Full episode out!
We discuss:
- how continental vs maritime powers think and how this explains Xi & Putin's decisions
- why British Empire fell apart, why China went communist, how Hitler and
25
77
603
4
7
54
2 months and 2 weeks since our first code commit, 14
@weights_biases
training runs are going right now for our
@fastdotai
community submission to
@paperswithcode
Reproducibility Challenge. This project has been so great to work on, 6 days to go until the deadline 🚀

1
5
54
Working at
@weights_biases
ticks the 2 main boxes I look for in a job:
Do interesting & challenging work ✅
Shape the future of the company ✅
Feel free to DM me if you'd like a quick, 100% confidential chat about applying to the team!

My team is hiring!
👩🔬 ML Engineers
👨🔬 Project Managers
Perks include: working on insanely exciting/challenging problems, on a product ML engineers love, with the smartest/kindest/most fun folks in the world
DM me!
#deeplearning
6
102
334
0
7
53
Latest article (finally) done! Explore and clean up your noisy text with dimension reduction via UMAP and visualisation via Bokeh!
Article 📖:
Code 🤖:
Turns out my ParaCrawl dataset contained some suspect translations...
1
11
52
RIP RAG
“I think long context is definitely the future rather than RAG”
On domain specialisation:
“If you want a model for medical domain, legal domain…it (finetuning) definitely makes sense…finetuning can also be an alternative to RAG”
Great episode, had to listen 0.75x 😂

I'm back! and super proud to be the first podcast to feature
@YiTayML
senpai
with special shoutouts to
@quocleix
,
@_jasonwei
,
@hwchung27
,
@teortaxesTex
!
Special interest callouts:
- why encoder-decoder is not actually that different than decoder-only cc
@teortaxesTex
@eugeneyan

5
13
139
5
7
51

I brought fastai’s activation stats visualisation into weights and biases using custom charts, helps compare across multiple models/runs a little easier

Inspecting your activations can be a useful way to debug model training! Today's featured report uses
@fastdotai
's ActivationStats callback to debug a GPT model for text generation by visualizing its "colorful" dimension. 1/2
📝:

1
22
71
3
7
49
Paper Presentation 🗣️ - AdaHessian Optimizer
Come join the AdaHessian authors
@yao_zhewei
and A. Gholami for an explanation of the AdaHessian paper, learn about second-order methods
Thurs, Aug 27, 2020 09:00 AM Pacific Time
Zoom details on the forum:
1
15
47
Love how the
@llm360
team share their
@weights_biases
workspaces publicly in the Metrics section for both Amber and Crystal Coder 😍
44 loss and eval charts logged during training, all publicly browsable


🚀 1/7 We are thrilled to launch LLM360 — pushing the frontier of open-source & transparent LLMs!
Starting with Amber (7B) & CrystalCoder (7B), we are releasing brand new pre-trained LLMs with all training code, data, and up to 360 model checkpoints.
🔗
19
188
1K
2
10
37
Put together a quick colab to fine-tune
@OpenAI
ChatGPT-3.5 on the huggingface api code from the gorilla dataset
Idea being to see if something like this can help improve ChatGPT-3.5's use of tools and mimic GPT-4's `functions` capability


📢 Excited to release Gorilla🦍 Gorilla picks from 1000s of APIs to complete user tasks, surpassing even GPT-4! LLMs need to interact with the world through APIs, and Gorilla teaches LLMs APIs. Presenting Gorilla-Spotlight demo🤩
Webpage:
33
207
980
5
9
43
Wowza, performant 1-bit LLMs (from 3b up) are here... whats the catch? Their models have to be pre-trained from scratch at this precision, don't think it mentions trying to quantize existing pre-trained models




Microsoft presents The Era of 1-bit LLMs
All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single

52
614
2K
6
4
43
1⃣1⃣0⃣days: From initial post to
@paperswithcode
Reproducibility Challenge submission
Recruit interest -> pick a paper (Reformer) -> push, push push -> submit
💯 Team effort
Reflections on our journey and what we would do differently next time:
1/2

1
6
43
The Apple research team behind MM1 giving a shoutout to the wandb crew supporting their work, love to see it 😍
🍎 + 🪄🐝

Apple announces MM1
Methods, Analysis & Insights from Multimodal LLM Pre-training
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through

16
177
951
1
6
43
just realised that one reason I'm enjoying using Instructor is similar to why I enjoyed using fastai/fastcore - learning a heap about pydantic/python as I go deeper
Much more effective learning for me than a textbook/course
2
5
42
In 12 short minutes
@emilymbender
&
@alkoller
's
#acl2020
Best Theme Paper, rapidly deflates hype around how latest NLP models "understand" language, especially relevant given GPT-3 hype, recommended!!
Vid:
Climbing towards NLU...:


2
11
40


Stoked to work with
@weights_biases
to help the
@huggingface
community fine-tune models in 60+ languages!
💻 Fully instrumented XLSR colab with W&B:
We have language-specific W&B Projects AND a W&B feature (still in beta) I am really excited about... 1/4


Today, we are starting the XLSR-Wav2Vec2 Fine-Tuning week with over 250 participants and more joining by the hour🤯
We want to thank
@JiliJeanlouis
and
@OVHcloud
for providing 32GB V100s to all participants🔥
There are still plenty of free spots to join👉
2
20
98
1
3
38
Our in-house wizard & intern
@vwxyzjn
built our Stable Baselines 3
@weights_biases
integration last year
It makes me very happy to see it in Harrison's latest vid 🔥🔥🔥


Better tracking for your deep learning training:
Video:
Text-based write up:
0
11
75
1
6
38
Just gave Cursor's interpreter (similar idea to ChatGPT's code interpreter) a spin, its a ✨ magical ✨ experience being able to ask it to both create files, write code and run it for you locally
Its just missing the ability to visualise charts, once its does this is probably my
5
1
37
If you're excited to come join us and work on LLMs and Generative AI more broadly at
@weights_biases
, I have 2 pointers after reviewing a few 100 resumes for this role:
1⃣ LLMs experience
We're looking for people who have been captivated by the power and potential of LLMs, to
🚀 Hiring - ML Engineer, Generative AI 🚀
Our Growth ML team at
@weights_biases
is hiring!
We're looking for someone to join us in creating engaging technical content for all things Generative AI (primarily LLM-focussed) to help educate the AI community and showcase how W&B's
8
11
70
1
7
36
⚡️ AI Hacker Cup Lightning Comp
Today we're kicking off a ⚡️ 7-day competition to solve all 5 of the 2023 practice Hacker Cup challenges with
@MistralAI
models
Our current baseline is 2/5 with the starter RAG agent (with reflection)
@MistralAI
api access provided
Details👇

2
12
37
Quick (basic)
@weights_biases
note on normalisation for the unsupervised
@kaggle
July Tabular Playground series

0
8
36
This is the start of exploration I'll be running on the pipeline settings for StableDiffusion from
@StabilityAI
, using
@weights_biases
Tables for visualisation
📘 Findings:
🖥️ Colab: (based on the excellent release Colab)

Delighted to see the StableDiffusion weights released publicly!
Like
@craiyonAI
before it, its great to be able to generate your own images on demand on your own machine
Cooking up a
@weights_biases
example right now
🎨

1
1
16
0
6
36
Shipping in July, the wandb library is getting a major upgrade:
📉 23% faster init and shutdown
📉 33%/28% faster artifacts upload/download
📉 88% reduction in CPU utilization for parallel processing
👀 Upgrade to 0.17.3 + add `wandb.require("core")` to try it early



2
5
35
@thebadbucket
@citnaj
And this guess that the burst pipes were some kind of wild exotic plant can't be blamed really 😂

0
3
33
Won’t tell me about human rights abuses in Abu Dhabi
Saudi, Qatar, Dubai, China, Mexico all thrown under the bus




4
2
34
We (
@weights_biases
) love the Instructor library so we created a course, "LLM Engineering: Structured Outputs" with its creator,
@jxnlco
, who charts a mental map for how to get more consistent outputs from LLMs using function calling, validation + more

1
6
34
"An unhelpful error message is a bug" 😍 - part of the Flax Ecosystem Philosophy
Taken from the Jax/Flax intro session this evening as part of the
@huggingface
community effort kicking off


0
2
33
Delighted to see the
@harmonai_org
discord going public 🎶
I spoke to Zach and
@drscotthawley
last week about:
🏗️ what they've been building
🎚️ working with artists
🐝 how they used
@weights_biases
👯 how the community can get involved
Get involved!


Stoked to announce the launch of our discord server Harmonai Play 🥳🎉
Join here >
and start training your own Dance Diffusion
4
38
106
1
16
32
whoa, 21% -> 51% accuracy on hugging face gorilla api eval set after fine-tuning GPT-3.5!
Re-running eval generations again to make sure this is legit

4
6
32
Fine-tuning
@OpenAI
's GPT-3.5 is a great way to eek out more performance - it might even outperform GPT-4 for your usecase 🔥
I took a quick look at GPT-3.5 fine-tuning and logged the results with the
@weights_biases
openai-python integration


Lots of improvements to fine-tuning over the past month
- gpt3.5 Turbo
- Fine-tuning UI
- Continuous fine-tuning (fine-tune a fine-tune)
-
@weights_biases
support in latest SDK
It's important that we simultaneously ship amazing new stuff AND improve core foundations

4
8
52
3
4
31
Can't decide which algorithm to use for your tabular data modelling? 😱
Ease your mind and come join me in ~8 hours (6pm GMT / 10am PT) to take a spin through the PyCaret library 😊
It's not always obvious which model & hyperparams work best for your tabular dataset. This Thu
@morgymcg
takes a look at how to compare performance between different traditional ML algorithms.
💡 Comparing
@XGBoostProject
, LightGBM & more w/
#pycaret
👉

0
7
40
0
14
29
We've added results from the
@YouSearchEngine
to our latest wandbot release (thanks to
@ParamBharat
), we've definitely seen it answer questions it would have otherwise struggled with, e.g. finding solved github/stackoverflow issues for some gnarlier support questions that aren't
Bard/Perplexity are showing that having an “online LLM” is now table stakes
Inspired by this
@SebastienBubeck
talk, I think the next frontier of embedding models is to go beyond space (precision/recall) and into time (permanent vs contingent facts, perhaps as proxied by


11
16
185
1
3
30
Delighted to see
@ParamBharat
's work being shared here, evaluation report coming out soon thanks to
@ayushthakur0
!
Props also to the team at
@Replit
for their help getting wandbot running on Replit Deployments, more coming soon on that :)

Want to see a real-world RAG app in production? Check out wandbot 🤖 - chat over
@weights_biases
documentation, integrated with
@Discord
and
@SlackHQ
! (Full credits to
@ParamBharat
et al.)
It contains the following key features that every user should consider:
✅ Periodic data




5
82
338
2
6
28
Vision Transformer was so last week, ImageNet SOTA of 84.8% (no additional data used) with LambdaResNets
(Vision Transformer achieved 77.9% on ImageNet-only data, only starts to shine with huge data)

LambdaNetworks: Modeling long-range Interactions without Attention
Achieves the SotA accuracies on ImageNet with attention-like architecture while being ∼4.5x faster than the popular EfficientNets. Better perf-computes trade-off than axial/local attn.

1
85
339
1
6
28
:gift: :gift: Feedback Requested :gift: :gift:
Our
@fastdotai
community team would ♥️ feedback on our
@paperswithcode
Reproducibility Challenge
@weights_biases
report (1 day before the deadline 😬), reproducing the Reformer paper
📕:
Reply, DM... 1/2
1
10
29
Looking forward to visiting ETH Zurich next Thursday 12th to host a mega
@weights_biases
event with the GDSC crew there!
If you're in the neighbourhood feel free to drop in 👇
1
1
28
We've had a lot of fun and learned a lot about building LLM systems while working on wandbot, our
@weights_biases
technical support bot
Delighted to see our v1.0 release in the wild,
@ParamBharat
has a technical update on its new microservices architecture here:



🚀 Exciting announcement! Introducing Wandbot-v1 from
@weights_biases
- Running on
@OpenAI
's GPT-4-Turbo &
@llama_index
.
- Multilingual support with
@cohere
rerank
- Chat threads in Slack, Discord, Zendesk, and ChatGPT
-
@replit
Deployments
Full report:
2
28
73
0
5
27
I did this same research for our company offsite a few weeks ago
👉 6 of the 8 Transformers authors also use
@weights_biases
today 🤩
The 2 who don't either:
- can't (Google) or
- don't need to (crypto) 🔥

What have the eight ex-Google Brain authors of the Transformers paper been doing since December 2017? 🧐
Let’s find out together! 🧵
Paper:
Sources: Google, Pitchbook, LinkedIn
//
@ashVaswani
@NoamShazeer
@aidangomezzz
@nikiparmar09
@YesThisIsLion

66
636
4K
0
6
28
Our
@weights_biases
Keras callback gives you A LOT more than just experiment tracking, let
@ayushthakur0
take you on a journey of code, gifs and
@kaggle
notebooks…

Keras has played a big role in my DL journey. It turned 7 a few days back and I would like to thank
@fchollet
and the community for this great tool. 🎉
Here's a thread to share how I get more out of my Keras pipeline using
@weights_biases
.
🧵👇
4
28
195
0
3
28
Back from a trip to Japan and while I use ChatGPT daily I was really blown away by how useful 4o on the mobile app was in a country and culture that was completely foreign
Being able to have a conversation about a menu or a bus timetable was gold.
Same for learning more about




1
1
27
Tek out here going through the pain so you so don’t have too 😍
(
@weights_biases
links galore in case you want to see the details of the training config & metrics)


2
6
27
Really enjoyed this talk at PyTorch conf from Jane Xu at PyTorch about chipping away at memory consumption
⬇️OffloadActivations (new, in torchtune)
⬇️Activation Checkpointing
⬇️AdamW4bit / Adafactor
⬇️FSDP2
⬇️LoRA/QLoRA
(nice W&B charts too 😃)


1
2
27
This talk from Altay Guvench here a W&B about his flourescent photograph is amazing, he told me about his work a few months back and I was blown away, turns out everything glows!
Check out his talk here:
And if you want to get involved with his new

1
3
23
The course is 30 minutes total, broken up into bite-sized chunks starting with Pydantic and moving on to validation and finally a RAG application.
I guarantee you'll finish it by finally getting the LLM outputs you want 😃
👉 👈

1
2
25
Finetuning ChatGPT-3.5 brought it up from 22% -> 47% on the Gorilla hugging face api evaluation dataset, cool!
Full details and code here:
Still not indicative that finetuning can make it as useful as GPT-4's `funcs` for tool use, but its promising!

whoa, 21% -> 51% accuracy on hugging face gorilla api eval set after fine-tuning GPT-3.5!
Re-running eval generations again to make sure this is legit
4
6
32
2
7
26
Consistent quality of life improvements to
@weights_biases
, often implemented within days of user feedback, is one of the things I love about working with the team here 😍
We're always making lots of quality of life improvements to W&B💅
We want to highlight two recent changes added by one of our engineers, Nick Peñaranda.
First up, vertically stacked images in W&B Tables. Great for comparing two models performance across samples.
1/3
2
4
29
1
2
25
The real value of using
@weights_biases
struck me when I started using it with some teammates as part of a paper reproducibility challenge.
Watching 15 different experiment runs from 4 different teammates train in realtime was magic :D

Collaborate with your classmates easily this semester using W&B!
I’m excited to share this article on how you can collaborate with your peers on your Machine Learning assignments using
@weights_biases
for FREE.🤠
Why is W&B useful for ML projects👇 1/6
1
8
37
0
5
25
Since I'm just back from Mexico I'm having fun fine-tuning stable diffusion using Diffusion from the hugging face Dreambooth hackathon on tortas!
Ongoing
@weights_biases
training journal here:




🎄 Advent of DreamBooth Hackathon 🎄
Today
@johnowhitaker
and I are kicking of a 1-month virtual hackathon to personalise Stable Diffusion models with a powerful technique from
@GoogleAI
called DreamBooth 🔮
Details 👉:

1
19
84
1
7
25
Deployments from
@Replit
really feels like the right level of performance vs complexity for a huge chunk of use cases - its been great to serve our LLM support bot, wandbot, on it!


@weights_biases
“Replit Deployments is a really great feature. It is easy to use, has professionalized our WandBot deployment, and made it much more stable.” -
@morgymcg
To create your own RAG bot for your platform, learn more:
1
5
15
0
4
23
It was SO GREAT catching up with
@borisdayma
,
@iScienceLuvr
,
@shah_bu_land
&
@capetorch
at Fully Connected 23
Zooms from Dublin are better than nothing, but you can't beat in-person chat!

2
0
25
Really 👌 interview with
@neuraltheory
and
@jeremyphoward
on where AI is going in the short-medium term, worth 45min
0
9
24
Flying in from 🇮🇪 to SF this week for
@aiDotEngineer
, until Monday July 1st - who's around for coffee?
Anyone want to ride the post-conference glow with a hack the weekend after the conference? I can see if
@l2k
will let me open the
@weights_biases
office for the weekend 😉
3
2
24
Delighted to see the
@weights_biases
Prompts Tracer is now also added to
@LangChainAI
's Tracing Walkthrough section!
Capture inputs, intermediate results, outputs, token usage and more with 1 line:
os.environ["LANGCHAIN_WANDB_TRACING"] = "true"


🎉
@LangChainAI
🦜🔗 JS/TS 0.0.88 is live with:
🦁 New
@brave
private search API tool
✂️💻 15 different code text splitters
📗
@supabase
advanced metadata filtering
🔍 Self-query retriever improvements
📦
@vespaengine
retriever
Let's dive in 🧵
1
7
57
1
13
24
"...test everything for yourself, don't believe it just because someone else said it, and don't believe anything I say today just because I said it - test it for yourself"
-
@jefrankle
in our free LLM fine-tuning course 🧠
When building AI systems

📣 Back by popular demand! Join our free "Training and Fine-tuning LLMs" course with
@MosaicML
!
💡 LLM Evaluation
💡 Dataset Curation
💡 Distributed Training
💡 Practical Tips from top industry experts
Enroll now 🔗
2
31
310
0
5
24
I'm hiring!
I'm looking for a growth-driven Project Manager to join my team and help us fuel the
@weights_biases
rocketship 🚀
If you are passionate about growing a business 📈 and have a growth mindset 🧘, shoot me a DM
0
7
23
Currently reviewing a post for the
@weights_biases
blog before its released, sometimes I have to pinch myself when I remembered I'm getting paid for this.
Couldn't have imagined this 18months ago, its been some ride 🙏

1
0
24
Really enjoyed this 15min talk from
@_inesmontani
on Practical NLP, real feels for the ole "hmmm lets say 90% accuracy" goal 😂

0
3
24
Kinda nuts
@Replit
are able to serve their LLMs on spot instances, great example of lots of small optimization wins adding up


1
1
23


🇰🇷 Did you know that
@weights_biases
's blog, Fully Connected, has articles in Korean?
Given the glut of english-focussed ML resources today, hopefully these articles help bridge the language barrier between english speakers and non-english speakers
1/3

1
7
23
DALLE-Playground from the
@theaievangelist
is a really slick experience to generate images from DALL-E Mini from
@borisdayma
via a colab and a local webapp, highly recommend giving it a spin!
📓
🤖

2
3
22
1/4 Linguists/NLP folks! Our community effort are looking for 2 to 4 diverse language families to test out Transformer modifications and we'd like to test with more than english so we don't over-optimise for english. Likely tasks: language modelling, classification + QA ...
1
10
22
@kaggle
And here is the 2nd place winners excellent github repo with the original code and even a youtube vid explaining their solution in their own words!

1
2
21