
Michelle Lam
@michelle123lam
Followers
1,189
Following
530
Media
17
Statuses
92
CS PhD student @Stanford | hci, social computing, human-centered AI, algorithmic fairness (+ dance, design, doodling!) | @mlam @hci .social | she/her
Stanford, CA
Joined August 2012
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Colorado
• 147756 Tweets
Notre Dame
• 123527 Tweets
#AEWAllOut
• 91628 Tweets
Kentucky
• 77587 Tweets
#仮面ライダーガヴ
• 67966 Tweets
The Weeknd
• 66592 Tweets
Nebraska
• 47099 Tweets
Carti
• 34804 Tweets
Abel
• 32718 Tweets
T-岡田
• 29708 Tweets
Talleres
• 29584 Tweets
Tennessee
• 28208 Tweets
#KPOPMASTERZinBANGKOK2024
• 23959 Tweets
Skullduggery
• 21592 Tweets
Oregon
• 19265 Tweets
#InternationalLiteracyDay
• 19173 Tweets
Bama
• 18617 Tweets
Willow
• 17446 Tweets
ショウマ
• 16311 Tweets
BOSSNOEUL TBNW Q6
• 14838 Tweets
NC State
• 14496 Tweets
Herrera
• 14046 Tweets
Deion
• 11346 Tweets
Danielson
• 11327 Tweets
Ospreay
• 10358 Tweets
設営完了
• 10257 Tweets





















Today, technical experts hold the tools to conduct system-scale algorithm audits, so they largely decide what algorithmic harms are surfaced. Our
#cscw2022
paper asks: how could *everyday users* explore where a system disagrees with their perspectives? 🧵

2
40
215
“Can we get a new text analysis tool?”
“No—we have Topic Model at home”
Topic Model at home: outputs vague keywords; needs constant parameter fiddling🫠
Is there a better way? We introduce LLooM, a concept induction tool to explore text data in terms of interpretable concepts🧵
5
42
206
Algorithm audits are powerful, but focused on technical system components. We introduce Sociotechnical Audits that expand to audit both algorithms and how users change in response to algorithms. We'll be sharing more on this work soon, but excited to present at CSCW! :)

NEW PAPER: Led by
@michelle123lam
&
@DrMetaxa
, a sociotechnical audit finds online ad targeting is effective, but perhaps via repeated exposure, not inherent user benefit.
#CSCW2023
0
15
44
1
27
149
How can we go beyond auditing algorithms to also investigate how users change in response to algorithms? We introduced Sociotechnical Audits & the Intervenr system to address this challenge! Join us at
#CSCW2023
—Wed 2:30pm for our honorable mention paper 🤠🧵:

1
21
145
When building ML models, we often get pulled into technical implementation details rather than deliberating over critical normative questions. What if we could directly articulate the high-level ideas that models ought to reason over?
#CHI2023
🧵

3
21
91
It's been great working with the folks from
@AvidMldb
to launch a public version of IndieLabel, our prototype end-user auditing system (from our CSCW22 paper)! We hope this demo can seed further discussion and future work on user-driven AI audits ✨

1
10
52
Frustrated with topic models? Wish emergent concepts were interpretable, steerable, and able to classify new data? Check out our
#CHI2024
talk on Tues 9:45am in 316C (Politics of Datasets)!
Or try LLooM, our open-sourced tool :)
✨

“Can we get a new text analysis tool?”
“No—we have Topic Model at home”
Topic Model at home: outputs vague keywords; needs constant parameter fiddling🫠
Is there a better way? We introduce LLooM, a concept induction tool to explore text data in terms of interpretable concepts🧵
5
42
206
1
14
52
We're really grateful that our End-User Audits project was selected as one of the AI Audit Challenge award-winners! If you're interested in AI evaluation, come join the virtual showcase at 9a tomorrow (6/27) to hear about all of the cool projects & discuss the future of auditing!

Last August, HAI and
@StanfordCyber
launched the
#AIAuditChallenge
that calls for solutions to improve our ability to evaluate AI systems. Join us on June 27 as we highlight the most innovative approaches, as well as lessons learned from the challenge:
0
3
24
1
6
44
If you're interested in how we can engage end users in testing, auditing, and contesting AI systems, come join our
#CSCW23
in-person workshop! The submission deadline is Sept 15 ✨


2
15
35
How can end users more powerfully shape LLM behavior? DITTO lets a user provide just a handful of demonstrations to align a language model to their needs—and users much prefer these results over those of baseline methods and self-authored prompts!

LLMs sound homogeneous *because* feedback modalities like rankings, principles, and pairs cater to group-level preferences. Asking an individual to rank ~1K outputs or provide accurate principles takes effort.
What if we relied on a few demos to elicit annotator preferences?
3
43
143
0
2
37
Ever wonder how we might tackle ML fairness issues way upstream during early model design instead of waiting for audits & post-hoc fixes? Come to our
#CHI2023
Model Sketching talk to hear about a system for iterating on models in terms of high-level values: Today 2:30p, Hall A!
When building ML models, we often get pulled into technical implementation details rather than deliberating over critical normative questions. What if we could directly articulate the high-level ideas that models ought to reason over?
#CHI2023
🧵
3
21
91
1
6
33
Today's social media AIs encode values—can we mitigate societal harms by making these values explicit and tuneable? Excited to share our
#CSCW24
paper introducing societal objective functions, which translate social science constructs into algorithmic objectives for social media!

Can we design AI systems to consider democratic values as their objective functions? Our new
#CSCW24
paper w/
@michelle123lam
, Minh Chau Mai,
@jeffhancock
,
@msbernst
introduces a method for translating social science constructs into social media AIs (1/12)
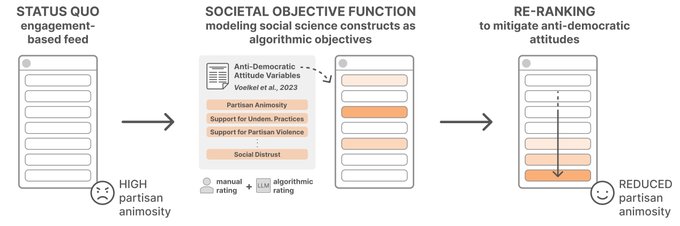
3
21
102
3
3
32
With so many open questions about how we ought to evaluate and audit LLMs, the HCI community has an exciting opportunity to lead the discussion with creative, human-centered approaches. Come join our workshop (HEAL) at
#CHI2024
— submissions are due Feb 23!


0
4
30
Do you author ML models in your work? Have you ever struggled to reason over the values encoded in your models? We’d like to invite you to participate in a 1-hour remote study using an interactive model authoring tool in Colab. RTs appreciated!
Signup:

0
16
25
This work would not be possible without my amazing collaborators and advisors—Janice Teoh,
@landay
,
@jeffrey_heer
, and
@msbernst
!
Start using LLooM to explore text data via concepts (), or see our
#CHI2024
paper to learn more ()!
3
1
20
(6/6) A huge thank you to my collaborators and advisors:
@mitchellgordon
,
@DrMetaxa
,
@jeffhancock
,
@landay
, and
@msbernst
!! Here’s the link to our paper again: .
1
3
16
super exciting—congratulations
@mitchellgordon
on this recognition!! very grateful to have been able to work with you and the rest of the wonderful team
1
0
13
(5/6) What does this mean for the future of algorithm audits? With End-User Audits, we uncovered important, overlooked issues by enabling individual users to lead audits. We need more methods that go beyond monolithic demographic groups and amplify the voices of everyday users.
1
1
10
Though LLM chaining is powerful, the design process is often difficult and unstructured—but we don't have to start from scratch! This work synthesizes over a decade of crowdsourcing work into a design space that elucidates lessons that transfer and open challenges unique to LLMs.

Chaining LLMs together to overcome LLM errors is an emerging, yet challenging, technique. What can we learn from crowdsourcing, which has long dealt with the challenge of decomposing complex work? We delve into this question in our new preprint: [1/9]

4
16
87
0
0
11
A final reminder to submit to our
#CSCW23
workshop by tomorrow! In response to several requests, we extended the deadline to Wed 9/20 EOD, and paper drafts still under submission are welcome (no page limit)!
0
5
9
Our algorithm draws on the ability of large language models (LLMs) to generalize from examples. LLooM samples extracted text and iteratively synthesizes proposed concepts of increasing generality. Once concepts are induced, LLooM can classify the entire dataset.

1
0
8
(4/6) We had 17 non-technical users lead end-user audits of Perspective API. With just 30 mins to conduct their audits, participants independently replicated issues that expert audits had identified and raised previously underreported issues like over-flagging of reclaimed slurs.

1
2
8
Going further, expert data analysts used LLooM to uncover novel insights even on familiar datasets. Analysts were particularly excited that LLooM facilitated theory-driven analysis: they could read out patterns and write hypotheses through the language of LLooM concepts.
2
0
7
exciting work from some very cool labmates! :)

How might an online community look after many people join? My paper w/
@lindsaypopowski
@Carryveggies
@merrierm
@percyliang
@msbernst
introduces "social simulacra": a method of generating compelling social behaviors to prototype social designs 🧵
#uist2022
11
47
246
1
0
7
We instantiate our algorithm in the LLooM Workbench, an open-source text analysis tool for computational notebooks. Users can explore text data in terms of high-level concepts—from a dataset overview to concept details to document-level scores, highlights, and rationale.

1
0
6
(2/6) User-led audits at this scale are challenging: just to get started, they require substantial user effort to label and make sense of thousands of system outputs. Could users label just 20 examples and jump to the valuable part of providing their unique perspectives?
1
1
6
In evals, LLooM exceeds baselines to recover 70-90% of human-annotated, generic topics, and LLooM is significantly better at surfacing specific, nuanced concepts.
From content moderation to AI ethics statements, LLooM concepts help us make sense of data:

1
0
6
LLooM fills this gap with concept induction, extracting high-level concepts defined by natural language descriptions & explicit inclusion criteria (e.g., “Dismissal of women’s concerns: Does the text dismiss or invalidate women’s concerns or experiences?”)

1
0
6
(3/6) Our IndieLabel auditing tool allows users to do exactly this. Leveraging varied annotator perspectives *already present* in ML datasets, we use collaborative filtering to help users go from 20 labels to 100k so they can explore where they diverge from the system’s outputs.

1
1
6
@DrMetaxa
aww thank you so much again for your mentorship on this work!! super thankful to have ended up being a first advisee in your faculty era :)
0
0
5
Thanks so much to my co-authors: awesome undergrad interns
@zixianma02
, Anne Li, Ulo Freitas; collaborator
@dakuowang
; and my wonderful advisors
@landay
,
@msbernst
!! See the paper at:
0
0
5
(3/6) We introduce model sketching, a technical framework that lets ML practitioners express modeling ideas purely in terms of human-understandable concepts, but brings them to life as functional “sketch” models that they can evaluate and iterate on in early-stage model design.

1
0
4
(6/6) ML model fairness issues are often addressed with ethical frameworks beforehand or metrics, audits, and post-hoc fixes after the fact. Model sketching brings this normative thinking into the development process, grounding it in functional models and realistic data insights.
1
1
4
I’m very grateful to my collaborators—Ayush Pandit, Colin Kalicki, Rachit Gupta, and Poonam Sahoo—and
@DrMetaxa
, who was an amazing advisor on this project! Looking forward to meeting folks at CSCW and happy to chat about this work :)
0
0
4
Analysts have questions like “How are women in power described?” Vague topics like “women, power, female” aren’t what they’re after—they want to understand data with nuanced concepts like “Criticism of traditional gender roles,” which are central to theory-driven data analysis.
2
0
4
0
0
4
@RishiBommasani
thanks, Rishi!! definitely interested in more ways we might operationalize broad participation
0
0
2
@rajiinio
Yes, definitely interested in how we can continue to lower the effort barrier and expand who gets to take part in algorithm auditing! Thanks for sharing :)
0
0
2
(5/6) Our tool helped ML practitioners create multiple models for detecting hateful memes in just 30 mins, exploring 130+ concepts. Instead of tunneling on technical details, they focused on user harms to inform their models and identified data representativity & labeling issues.

1
0
2
0
0
2
(2/6) For example, what factors should our model consider in a content moderation task? Profanity, bullying, sexism? How do we define them? Are they sufficient? If we could iterate on models in these terms, we could grapple with their human impact & ethical implications early on.
1
0
2
@IanArawjo
Ah oh no, sorry to hear that; I'll keep you posted if there are any hybrid options, or would be happy to chat any time about these topics!
0
0
2
(4/6) Leveraging zero-shot capabilities of pretrained models (GPT, CLIP), our ModelSketchBook Python package enables rapid model design exploration. Users can interactively specify concepts, combine them in sketches, run them on data, and directly iterate with new concept ideas.
1
0
2
@mitchellgordon
@MITEECS
@MIT_CSAIL
@msbernst
@landay
@tatsu_hashimoto
@foil
Congratulations!!! so exciting 🎉
1
0
1
(6/6) STAs can help us propose and validate alternative algorithm designs, with an awareness of their impact on users & society. Building on algorithm audits’ evaluation of the present, we’re excited that sociotechnical audits can help us imagine the future ✨
1
0
1
(2/6) We define a Sociotechnical Audit (STA) as a two-part audit of a sociotechnical system that consists of both an Algorithm Audit (which changes inputs to an algorithm to infer its properties) and a User Audit (which changes inputs to the user to draw conclusions about users).
1
0
1
0
0
1
@jasonwuishere
@cmuhcii
@jeffbigham
@jwnichls
@tongshuangwu
@tommmitchell
Congratulations, Jason!! 🎉🤩
1
0
1
0
0
1
@dcalacci
that's great! yes, there's a lot of open ground for text analysis tools to better align with the way researchers want to think about their data—with this release we'd really love to learn how LLooM works for a broader range of domains and research questions!
0
0
1
@MarkTan72526562
Sure! Our work helps ML practitioners iterate over the high-level decisionmaking factors that their model should reason over, rather than aiding technical model architecture decisions. This is important for subjective tasks with value tradeoffs among similarly-performing models.
1
0
1
1
0
1