

Micah Goldblum
@micahgoldblum
Followers
6K
Following
1K
Media
55
Statuses
890
🤖Prof at Columbia University 🏙️. All things machine learning.🤖
Joined December 2014
TLDR: Diffusion models (like DALLE or Imagen) generate pretty pictures from Gaussian noise, but the same training and generation update rules generalize easily to other degradations, including completely deterministic ones. 1/7

13
144
953
A common point raised by ML reviewers is that a method is too simple or is made of existing parts. But simplicity is a strength, not a weakness. People are much more likely to adopt simple methods, and simple ones are also typically more interpretable and intuitive. 1/2.
29
99
855
📢I’ll be admitting multiple PhD students this winter to Columbia University 🏙️ in the most exciting city in the world! If you are interested in dissecting modern deep learning systems to probe how they work, advancing AI safety, or automating data science, apply to my group.

6
150
566
Self-Supervised Learning (SSL) is quickly becoming a defacto way of training neural networks, but if you have ever tried it yourself, you’d know that getting high performance is tricky! Check out our new thorough guide to all things SSL.
7
85
469
I’m excited to announce that I’ll start as an assistant professor at Columbia University this summer! Interview season was fun, I met so many amazing people, but I’m happy to finally close the loop.

45
9
419
🚨Excited to announce a large-scale comparison of pretrained vision backbones including SSL, vision-language models, and CNNs vs ViTs across diverse downstream tasks ranging from classification to detection to OOD generalization and more! NeurIPS 2023🚨🧵.
8
93
402
How much data are augmentations worth? We show that augmentations can actually be worth more than extra data and invariance! They increase variance across batches, and this extra stochasticity finds flatter minima. 1/8.
3
65
388
Gradient-boosted decision trees are still thought to be competitive with neural networks on tabular data. But NNs have a massive advantage, they learn representations, and this ability can be leveraged for transfer learning 1/4

6
41
356
🚨 Announcing LiveBench, a challenging new general-purpose live LLM benchmark! 🚨.Thanks @crwhite_ml and @SpamuelDooley for leading the charge!.Link: Existing LLM benchmarks have serious limitations: 🧵
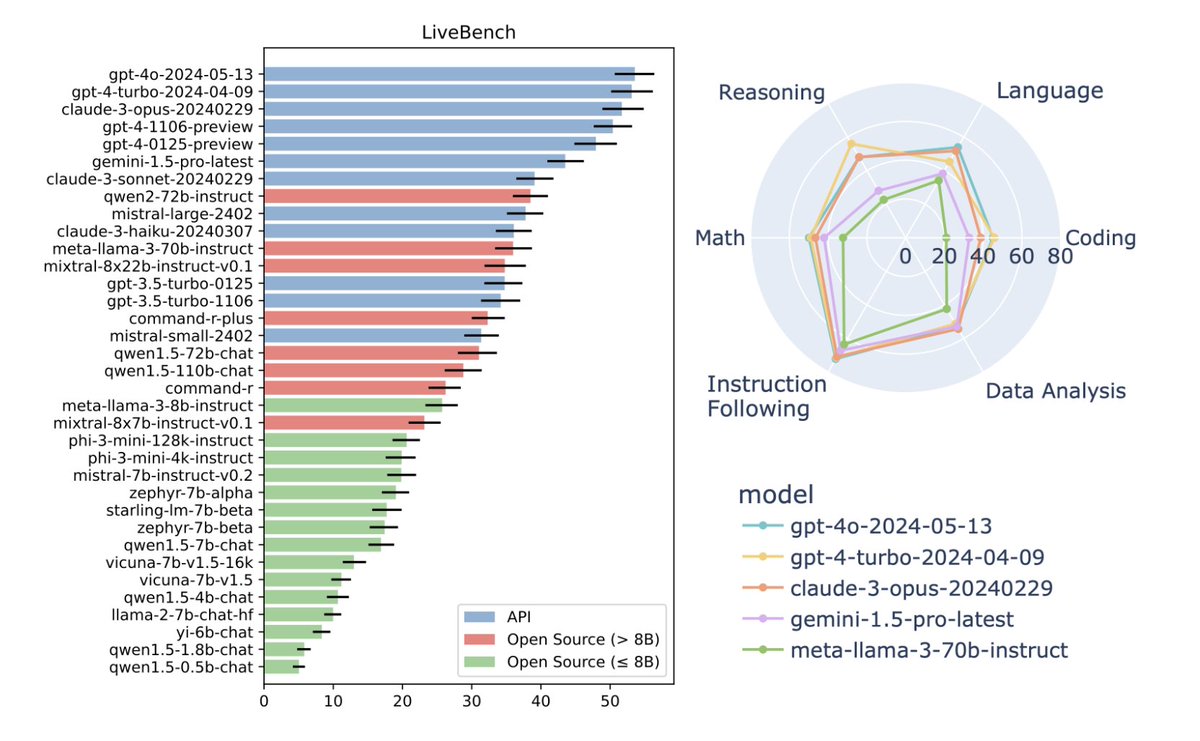
10
78
342
We often determine whether a neural network is over or under parameterized by counting parameter. In practice, how much data we can fit depends on many factors: architecture, optimizer, etc. So just how flexible are neural networks in practice? 🧵. Paper:
9
54
265
I’m on the faculty job market this year! Going from a late start as a math PhD student to a ML postdoc was a fun challenge. Building a research agenda alongside amazing students has been rewarding with 9 papers accepted to NeurIPS this year. Don’t let rejections get you down!.
6
19
253
Do LLMs simply memorize and parrot their pretraining data or do they learn patterns that generalize? Let’s put this to the test! We compute the first generalization guarantees for LLMs. w/ @LotfiSanae, @m_finzi, @KuangYilun, @timrudner, @andrewgwils. 1/9.
3
26
237
One view of ML history is that we started out with MLPs and evolved towards more specialized architectures like CNNs for vision, LSTMs for sequences, etc. But actually, the exact opposite is true! 🚨🧵1/6.
2
24
214
Simplicity doesn’t preclude novelty, even when the method is composed of existing parts. During the NeurIPS review period, DO NOT downgrade papers just because the method is simple. If anything, question methods which are needlessly complicated when simple solutions will do. 2/2.
6
10
215
We show that neural networks have a remarkable preference for low complexity which overlaps strongly with real-world data across modalities. PAC-Bayes proves that such models generalize, explaining why NNs are almost universally effective.

There're few who can deliver both great AI research and charismatic talks. OpenAI Chief Scientist @ilyasut is one of them. I watched Ilya's lecture at Simons Institute, where he delved into why unsupervised learning works through the lens of compression. Sharing my notes:.-
1
25
193
I’m thrilled to announce the first issue of a community survey on the state and future of deep learning! We asked folks their opinions on benchmarking, transformers, interpretability, theories of deep learning, and directions we should be working on. 1/3.
5
33
183
Typical transfer learning pipelines involve initializing at pre-trained weights and hoping that relevant learned information magically transfers even when the weights change during fine-tuning. But you can transfer so much more than just initialization! 1/4.
1
31
176
The new @icmlconf review format is horrendous (no reviewer scores). Students will spend an inordinate amount of time drafting rebuttals for reviewers who have already committed to rejecting their papers. Massive waste of person hours.
1
5
162
The following statement, while a commonly held view, is actually false! “Learning theory says that the more functions your model can represent, the more samples it needs to learn anything”. 1/8.

OK, debates about the necessity or "priors" (or lack thereof) in learning systems are pointless. Here are some basic facts that all ML theorists and most ML practitioners understand, but a number of folks-with-an-agenda don't seem to grasp. Thread. 1/.
7
20
169
We usually use NNs in silico, but they can also operate on analogue systems involving optics etc. You can train high-performance physical NNs that perform inference orders of magnitude faster than digital computers 1/2.
2
31
158
Lazy reviewer starter pack: “needs theoretical justification”, “should cite [paper that came out a week after the submission deadline]”, “not novel enough for NeurIPS”, “more datasets, models, and baselines [that don’t apply or are in the appendix]”, “borderline accept/reject”.
6
9
150
As we go into the NeurIPS reviewing process, remember to accept every paper that you think would contribute to the conference! Don’t read papers trying to find little things to criticize. Instead, try also to find the valuable pieces that the community might want to read. 1/3.
2
10
149
🚨Real data is often massively class-imbalanced, and standard NN pipelines built on balanced benchmarks can fail! We show that simply tuning standard pipelines beats all of the newfangled samplers and objectives designed for imbalance. #NeurIPS2023 🚨🧵1/8.
3
19
148
Data scientists working with tabular data try simple linear models first and work their way through GBDT and maybe finally expressive NNs and ensembles. In contrast, vision or NLP practitioners start with the most powerful NN at their disposal. 1/2.
6
7
140
After years of ML research and conference publications, I'm finally attending my first in-person conference this summer … as a postdoc … in my home city …🙃.
3
1
138
Lessons from ICML @icmlconf: (1) Eliminate short talks, especially pre-recorded ones. (2) Poster sessions ≫ talks so allocate more time to them. (3) NO EVENTS DURING LUNCH/DINNER TIME! Poster sessions ended ~8:30pm and people went without dinner. (4) Don’t serve moldy bagels.
4
7
137
There’s a pervasive myth that the No Free Lunch Theorem prevents us from building general-purpose learners. Instead, we need to select models on a per-domain basis. Is this really true? Let’s talk about it! 🧵 1/16.w/@andrewgwils, @m_finzi, K. Rowan.
9
22
125
#StableDiffusion and #ChatGPT use prompts, but hard prompts (actual text) perform poorly, while soft prompts are uninterpretable and nontransferable. We designed an easy-to-use prompt optimizer PEZ for discovering good hard prompts, complete with a demo.🧵.

4
30
122
Reviewers, engage with authors during the discussion period! So many misunderstandings are waiting to be cleared up by great rebuttals, and mistakes that have now been fixed. Don’t get some unlucky grad student’s paper rejected because you were too lazy to engage!.
2
13
117
If we want to use LLMs for decision making, we need to know how confident they are about their predictions. LLMs don’t output meaningful probabilities off-the-shelf, so here’s how to do it 🧵.Paper: Thanks @psiyumm and @gruver_nate for leading the charge!

2
22
116
Just made a quick plot of ICLR 2023 mean reviewer scores by percentile. To be in the top 25% of papers, you need a mean reviewer score of at least 5.67

3
9
114
I want to point out several problems (areas for improvement) in the @NeurIPSConf review process which I haven't heard talked about. (1) Do not show reviewer scores to other reviewers since these bias score changes via peer pressure (do show scores to authors and ACs). 1/3.
4
7
109
Some people feel that transfer learning (TL) doesn’t apply to tabular data just because there exist unrelated domains (e.g. cc fraud vs. disease diagnosis). However, there are also adjacent tabular domains where TL makes a ton of sense (e.g. diagnosis of different diseases). 1/6.

Saw a new article on transfer learning for tabular data using NNs. I don’t have the time to take a closer look, but my initial reaction is the following:. 1/4.
3
15
107
After a long day of ML research without any paws. Research is so ruff!

2
2
104
I’m on the academic job market this year 🚨🥳🚨! Let me know if there are any interesting opportunities I’m likely to have overlooked or catch me at #NeurIPS2022!.
1
10
97
People think hierarchical features are why NNs generalize. Has anyone formalized this? How would you verify/falsify? Historically, people thought early layers are tuned to extract low-level features (e.g. edges), while late layers learn to extract abstract ones (e.g. faces) 1/2.
7
10
95
Diffusion models like #StableDiffusion and #dalle2 generate beautiful pictures, but are these images new or are they copies of the images they were trained on? 🧵 #CVPR2023.

4
29
97
If my dog steps on my keyboard while I'm drafting a conference submission, is she a co-author? Some fields are very loose with authorship.

6
4
92
Data scientists who work at big tech companies benefit from free lunch in more ways than one.
0
13
87
Paper found here: . All the awesome collaborators that made this happen:.@arpitbansal297, @EBorgnia, Hong-Min Chu, Jie Li, @hamid_kazemi22, @furongh, @jonasgeiping, @tomgoldsteincs. 7/7.
4
6
76
Why are facial recognition systems so unfair across race/gender? A lot of people think it comes from imbalanced training data, but it even happens with perfectly balanced training data. In fact, randomly initialized face rec systems are unfair too! 1/3.
6
17
79
In deep learning, we typically split the data, train on the training split, and evaluate on the validation split, so we only train on part of the data when we are comparing models. In contrast, the marginal likelihood tries to use data more holistically. 1/3.
3
11
80
Classic Reviewer 2: “The authors have now thoroughly addressed all my concerns. I raise my score from 4 to 5.”.
5
2
78
Virtually all large models today contain huge matrices, and these dominate their compute. By incorporating structure in these matrices, we can improve the performance/compute tradeoff!.

A lot of the computation in pre-training transformers is now spent in the dense linear (MLP) layers. In our new ICML paper, we propose matrix structures with better scaling laws!.w/@ShikaiQiu, Andres P, @m_finzi, @micahgoldblum.1/8

4
0
71
ML security research has been DOMINATED by adversarial examples/defenses for the past few years, not because it is the most important area of security but because it is easy to work on (low implementation/hardware/know-how costs). 1/2.
6
4
70
Thrilled that our paper on model selection won the Outstanding Paper Award at ICML 2022. All credit goes to my great collaborators. Check out @LotfiSanae's talk and drop by our poster tomorrow!.

I'm so proud that our paper on the marginal likelihood won the Outstanding Paper Award at #ICML2022!!! Congratulations to my amazing co-authors @Pavel_Izmailov, @g_benton_, @micahgoldblum, @andrewgwils 🎉 .Talk on Thursday, 2:10 pm, room 310.Poster 828 on Thursday, 6-8 pm, hall E

1
2
63
We should value practicality and intuitiveness over novelty. Novelty often means an idea is so complicated that the reader couldn't have imagined coming up with it. That's not a good thing. That's bad. Good ideas often seem obvious in retrospect.
5
4
61
Want to learn more about data poisoning and backdoor attacks? Our survey paper ( clarifies the state of the field for newbies and veterans alike! @dawnsongtweets @tsiprasd @xinyun_chen_ @ChulinXie @A_v_i__S @tomgoldsteincs @aleks_madry.
0
13
60
🚨📢 Excited to announce the ICLR 2025 Workshop on Building Trust in LLMs and LLM Applications! 📢🚨. Submit all your papers, and we’ll see you in Singapore!. There will be paper awards, and we have a stacked lineup of speakers and panelists.
1
9
61
What are the real reasons that NNs work so much better than other models? It sure as hell isn’t because of the “implicit bias of SGD”. Is it their inductive biases, parameter efficiency, ease of optimization? Would other models work just as well if only we could scale them up?.
11
3
59
We show how to make data poisoning and backdoor attacks way more potent by synthesizing them from scratch with guided diffusion. 🧵 1/8. Paper:
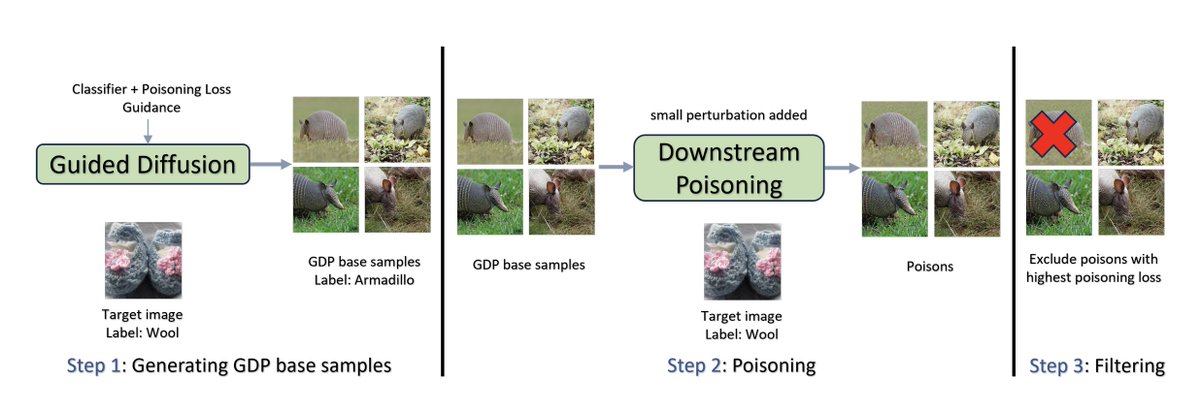
1
10
59
(3) Reviewers shouldn’t be allowed to click “Author Rebuttal Acknowledgement” (not writing a response to the rebuttal) if they don’t increase their score. It is important to justify to the authors why their points don’t address your feedback. 3/3.
2
6
55
Transformers seem to work for all sorts of data, made possible by a shared structure that virtually all real data shares. This also allows NNs to be near-universal compressors. The real world is simple, so all we need is models with a simplicity bias.

Language Modeling Is Compression. paper page: It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training

0
5
54
Even using deterministic degradations, training and test-time update rules that underlie diffusion models can be generalized, calling into question the orthodox understanding of diffusion and opening up research on a whole new direction of generative models. 6/7

2
6
51
Diffusion models, from DALLE to Imagen, operate by sampling random Gaussian noise and iteratively denoising/noising until they converge to a pretty picture. This simple-sounding process is underpinned by several theoretical motivations. 2/7.
1
7
52
ML practitioners used to encode their beliefs about a problem, like invariances, into their architectures by hand. We show that transformers actually learn these same structures directly from the data! 3/6.
2
0
49
#NeurIPS2022 was fun! No moldy bagels like ICML, more poster sessions, fewer talks. Minor suggestions: (1) Don’t schedule poster sessions during meal times (e.g. sessions from 11am-1pm). I noticed a lot of people skipping the lunchtime poster session because they were hungry. 1/3.
2
1
47
One interpretation of diffusion models views them as score estimators, whereby noise is added to the score estimates to sample images via stochastic gradient Langevin dynamics: 3/7.
1
3
43
Check out our paper, with @m_finzi, Keefer Rowan, @andrewgwils, where we show just how important simplicity bias, formalized using Kolmogorov complexity, is for machine learning. The paper is easy to approach for all audiences! 16/17.
1
2
46
(2) Low acceptance rates make reviewers worry that assigning a high score, thus increasing the chance of that paper being accepted, in turn decreases the chance of their own paper being accepted. After all, the same AC may be in charge of both papers. This is a bad incentive. 2/3.
3
2
44
🚨NeurIPS poster Wednesday: 11-1, Hall J #512🚨. Backdoor attacks are dangerous, but existing attacks are easy to detect. We develop a backdoor attack whose poisons are indistinguishable from clean samples. Can you tell which are poisoned? 1/4

5
11
45
SSL can even be used to learn an explicit prior probability distribution over parameters 8/8.
1
1
42
Despite the popularity of ViTs and SSL, our benchmark suggests that the best backbones for most vision tasks are actually modern convnets (e.g. ConvNeXt) pretrained on massive labeled classification datasets. Future SSL works should train on bigger datasets to be competitive. 2/7.
1
1
43
A second closely related interpretation views diffusion models as autoencoders with a fixed encoder that noises the image and a learned decoder that reverses this random process by approximating the reverse conditional distributions with Gaussians: 4/7.
1
5
42
The vast majority of NNs deployed/released have no privacy guarantee. If someone ever figures out how to recover training data from trained models, they will instantly recover boatloads of private data, and there’s nothing we can do to stop it! The models are already released.
4
6
41
I will be at ICML in person next week to present our works on marginal likelihood, model inversion/explainability, and privacy breaches in federated learning. Shoot me a message if you want to connect!.
2
0
43
Just how important are handcrafted inductive biases like CNNs for computer vision? We can just learn them! ViTs are often actually more translation invariant than CNNs after training.

CNNs are famously equivariant by design, but how about vision transformers? Using a new equivariance measure, the Lie derivative, we show that trained transformers are often more equivariant than trained CNNs!.w/ @m_finzi @micahgoldblum @andrewgwils 1/6

0
3
41
Sometimes I wish I knew about RL, but then I remember that there's only so much time in the day and I have to prioritize, so I go back to watching Seinfeld re-runs.
0
0
42
Interestingly, we find that bigger models can often be compressed into FEWER bits than smaller models, explaining why they perform better. In the future, if we can compress models better and better, we can make tighter and tighter bounds that explain why LLMs work so well. 9/9

1
3
42
Remember that grad students worked their butts off on those papers, and they shouldn’t be rejected just because they didn’t compare to the n+1’th method that conveniently happens to be yours. 2/3.
2
0
38
Under both of these interpretations, noise is central to why diffusion works. But such models can be used to reverse numerous other degradations, including completely deterministic ones: blur, masking, pixelation, snow-ifying, and … wait for it … animorph. 5/7.
1
6
37
Check out our easy-to-use tool for measuring equivariance via the Lie derivative. It even allows for layer-wise analysis and scales gracefully across architectures and input sizes: 5/6.
1
2
40
What started out merely as interesting properties of NNs became the main focus of ML security. But data poisoning and privacy are far bigger threats! Training data is scraped at scale without supervision, and models are trained on user data without any privacy guarantees. 2/2.
0
2
41
Lit reviews are super slow now that Google Scholar thinks I'm a bot.
6
2
37
How long does it take you to read or review a paper on average? Just reading a paper in full detail takes me hours, so unless I’m way slower than everyone else, I assume most reviewers are just skimming their papers.
8
0
39
It’s pathetic when ML conferences raise the acceptance cutoff in order to make the conference look prestigious. If 80% of papers are amazing, then accept them, especially in cases where the conference can easily host more papers.
0
2
38
Tabular deep learning is still in its infancy. Lots of room for improvement!.

A Short Chronology Of Deep Learning For Tabular Data:. Deep tabular methods are an interesting research direction! So, this morning, I sat down and summarized my thoughts + the recent papers I read.
1
4
35
Check out our work here! Thanks to my excellent collaborators Roman, Valeria, @A_v_i__S, @arpitbansal297, @cbbruss, @tomgoldsteincs, @andrewgwils 4/4.
1
2
34
1
2
33
Of course, reject papers with terminal flaws. But accepting more papers won’t dilute the conference, and there are tons of respected conferences in other fields which are bigger or have higher acceptance rates. 3/3.
0
0
30
Well-designed NN inductive biases prefer simple functions when they are compatible with the data but are perfectly capable of learning more complex models when necessary. As better tabular NNs emerge, data scientists will jump to them from the start. 2/2.
1
0
29
What's the deal with reviewer scores for NeurIPS this year? 5's are considered "borderline accept" whereas they are usually "weak reject". Will 5's still end up meaning the same thing as usual? (i.e. average reviewer score of 5-6 likely gets rejected).
4
0
32
What’s the best way to read (non-theory) papers? I typically go nonlinearly: start with the abstract and bulleted contributions, skim the experimental setup, look at results and baselines, read the experimental conclusions, and then go back and fill in the gaps.
5
0
32
To be clear, we should *NOT* abolish ML conferences altogether! They keep the community productive, and in that sense they have been wildly successful. But they could clearly use reform to decrease stress as well as bias and bad incentives in the review process.
2
1
28
There’s this large contingent of deep learning cynics who think today’s DL research is particularly sloppy and esoteric. I’d remind them that most papers in all fields are low impact, and other empirical fields (DL is one) such as biology are chock full of erroneous findings. 1/4.
3
2
27
✈️ I’ll be at NeurIPS next week. Shoot me a message if you want to meet up! ✈️.
0
0
27
Swing by and chat with me and my awesome collaborators at the poster sessions next week! .Tuesday 5:30pm.- PAC-Bayes Compression Bounds So Tight That They Can Explain Generalization.- End-to-end Algorithm Synthesis with Recurrent Networks: Extrapolation without Overthinking 1/4.
1
2
29
Interestingly, a single module applied recursively does the same exact thing (. Also, relatively shallow but wide networks achieve near ImageNet SOTA (. 2/2.
4
0
26
Have any generous AC's aggregated NeurIPS review score distributions? What's the 80% percentile this year?.
2
2
27
BTW, see some of the problems with marginal likelihood here 3/3.
1
2
26
We use Bayesian tools to transfer the loss function rather than only a single initialization. You can use our simple drop-in replacement wherever you would use pre-trained models, including classification, segmentation, and more. 2/4.
1
2
26
LLM judging is particularly unreliable on very hard questions whose solutions are difficult for the LLM to judge. In fact, we find that on hard math and reasoning tasks, the error rate of LLM judges can reach as high as 46%. Yikes!

1
2
26
Jonas is a great researcher and mentor. If you're looking to start a PhD in machine learning, make sure to check him out!.

We're also looking to hire PhD students interested in machine learning! You can find more information about joining my group on my webpage:
0
1
23
Shout out to all my co-authors who made this work possible:.@ziv_ravid, @arpitbansal297, @cbbruss, @ylecun, @andrewgwils. Paper:
0
1
24
We're happy to see that multiple people have pointed out that types of tabular transfer learning are already widely used in industry and in scientific applications. We hope our work can improve tabular transfer learning and make it even more broadly useful!.
I have won several Kaggle tabular data competitions. I have worked on or with three different AutoML projects for tabular data. I have collaborated with many top experts in the field and some of the largest companies. 1/2.
0
2
23
In fact, neural networks (or any other model for that matter) which are sufficiently compressible are formally guaranteed to generalize well to new and unseen test samples. 12/17.
1
0
22
Earlier high-performance vision and language systems were highly specialized, like HOG features and Latent Dirichlet Allocation, whereas tasks which were once performed by these tools can all be performed by transformers now. 2/6.
1
1
23
Augmentations like horizontal flips which are consistent with the data distribution can be valuable even when you have tons of training data, yet aggressive augmentations like TrivialAugment quickly become harmful. 4/8

2
3
23
Not only do transformers learn symmetries, but they can actually be MORE equivariant than CNNs, which are designed specifically for translation equivariance. So what is next in the evolution of ML? One architecture to rule them all? 4/6.
1
0
23