

interstellarninja
@intrstllrninja
Followers
1,521
Following
319
Media
575
Statuses
3,926
growing artificial societies | by the open-source AGI, for the people.
Tesseract
Joined December 2010
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#เมเจอร์xหลิงจังจอมแก่น
• 445045 Tweets
LINGLING MAJOR FANDOM
• 427698 Tweets
SAY SOMETHING
• 129764 Tweets
焼肉の日
• 89601 Tweets
#ไม่พูดหน่อยเหรอMV
• 80087 Tweets
東海道新幹線
• 67855 Tweets
AI PORTRAIT X ML
• 58557 Tweets
安全第一
• 42479 Tweets
線状降水帯
• 40695 Tweets
VLOG 11 WITH BUILD
• 33696 Tweets
アニサマ
• 31852 Tweets
Edeka
• 31678 Tweets
#انقاذ_النصر_مطلب_عشاقه
• 30178 Tweets
#素のまんま
• 27881 Tweets
土砂降り
• 23699 Tweets
KND x PHUWIN
• 19707 Tweets
#THE夜会
• 19333 Tweets
コロンブス
• 12813 Tweets
Jabar
• 11530 Tweets




















Pinned Tweet

this interstellarninja is on covert missions right now involving power struggles with closed source AI labs and regulatory bodies plotting against open source AI 🥷

Japan’s ninja are famed for their covert activities over centuries of power struggles in the country, and were highly prized by Tokugawa Ieyasu.
84
578
8K
0
0
4

Mixtral API pricing by provider:
1.
@MistralAI
input: 0.6€ / 1M tokens
output: 1.8€ / 1M tokens
2.
@togethercompute
$0.6 / 1M tokens
3.
@perplexity_ai
input: $0.14 / 1M tokens
output: $0.56 / 1M tokens
4.
@anyscalecompute
$0.50 / 1M tokens

We’re excited to announce the official
@MistralAI
Mixtral 8x7B model on Anyscale Endpoints, offering the best price on the market with an OpenAI compatible API.
💸 Pricing: $0.5 / million tokens
📆 Coming soon: JSON mode and function calling
Try out Mixtral on Anyscale

32
75
684
15
74
709
mixtral routing analysis shows that experts did not specialize to specific domains

10
31
316
it is confirmed by Mistral co-founder Arthur Mensch on a16z podcast that they duplicated the dense base 7B model layers 8x and further trained with a gating network


Exciting times with the new Mixtral model from
@MistralAI
! It’s evident that they’ve fine-tuned the Mistral 7B model to an impressive 8x. The significant correlation between the weights of the two models is a testament to the successful reuse of models. This approach could

13
55
480
6
23
292
1-bit LLMs with ternary weights require no multiplication which calls for a new hardware design different from GPUs

12
36
300
killer app of LLMs is not Scarlett Johansson, it's AI agent execution graph with local models🤖
here's MeeseeksAI, a local AI agent execution graph running on ollama with
@NousResearch
's Hermes-2-Pro-Llama-3-8B with flawless tool-use and reasoning 🚀

The killer app of LLMs is Scarlett Johansson. You all thought it was math or something
326
1K
12K
9
30
262
Qwen 0.5B may not write good poems but it is a beast at function calling🔥
It had a pass-rate of 77% on
@FireworksAI_HQ
function calling eval dataset 🧰
their blog also shows that Qwen1.5 models are close to GPT-4's performance on tool-use
@huybery
@JustinLin610

7
26
245
JSON mode with Mistral-7B has a pass rate of 80% 🔥
Mistral-7B base was finetuned on a mix of mini Hermes, function calling, json-mode and agentic datasets.
stay tuned for struct models & datasets from
@NousResearch
🥽
8
28
228
just watched
@realGeorgeHotz
hack Mistral MoE inference with
@__tinygrad__
and this was fun
my definition of entertainment has changed 😊
3
12
213
Mistral-7B performs on par with GPT-3.5 on function calling🔥
i'm happy to replace my function calling/extraction projects with Mistral API now
also I propose
@MistralAI
to implement the following schema for "response_format" for json mode which includes type and schema


Function calls have been a massive gap in the open source ecosystem (and the most common feature request).
We benchmarked function calling on a variety of open and proprietary models.
Impressively, Mistral-7B performs on par with GPT-3.5.
Here's how they stack up 🤯🤯
⚫️
19
70
500
1
22
162
wait phi-3 is trained on function-calling out of the box?

7
14
129
recursive function-calling LLM dropping to your local GPU very soon...
5
6
110
happiness is finetuning llama2 7B w/ qlora on a mid RTX 3060 GPU

7
8
108
Multi-token prediction is 3x faster using self-speculative decoding while also improving performance on tasks like coding and algorithmic reasoning as it emphasizes on longer-term dependencies


One of the important observations in Multi-token prediction paper is not that it's fast (otherwise it would be a bummer)
but that prediction n > 1 tokens also improves model's accuracy on multiple coding evals


3
1
27
3
6
82
Will GPT-5 be natively built with agentic capability?
8
14
79
Multi-Head Latent Attention (MLA) introduced by DeepSeek-V2 uses low-rank key-value joint compression to significantly reduce the key-value cache required during inference.
It achieves better performance than standard multi-head attention while using 93.3% less key-value cache.

0
7
77
mixtral experts seem to specialize in syntax rather than domain specially in the initial and final layers

1
5
69
you can now run function calling and json mode with
@ollama
thanks to
@AdrienBrault
🔥

1
7
69
JSON mode with local
@NousResearch
Hermes 2 Pro model doesn't need begging the LLM gods

0
6
59
@lillux_l
well humans have tongue slips and correct themselves as they speak for one and we hit backspace a lot while we type
a lot of humans communication is through gestures besides words
4
0
51

Hermes 2 Pro @ 96% vs GPT-3.5 @ 89% on adhering to JSON schema over 5 million requests 🔥

@NousResearch
I have officially replaced GPT-3.5 with Hermes 2 Pro 7B. I have compared output from both models for 5 million requests involving adhering to a JSON schema and it's not even close. Correct output from GPT-3.5 @ 89%. Correct output from Hermes 2 Pro 7B @ 96%. Also, Hermes 2 Pro 7B
2
3
17
2
5
48
okay phi-3 passes JSON-mode test fine


Phi-3 seems pretty good, an improvement over phi-2 for sure. The long context 128k seems very useful for extracting information and document processing given that the model is quite small it can be deployed for less

10
19
219
3
2
42
We need a
@huggingface
leaderboard for high-quality datasets!

We need to build code instruct datasets that are advanced and elite now to be ready
3
3
50
1
1
38
<cmd>
run world_sim.exe --epoch "Earth in 2500" --civilization_type "Type-II on Kardashev scale"
</cmd>

im opensourcing worldsim of course i am
worldsim sysprompt and conversation to intitialize:
sysprompt:
<sys>Assistant is in a CLI mood today. The human is interfacing with the simulator directly. capital letters and punctuation are optional meaning is optional hyperstition is
21
71
638
3
7
37
build your recursive AI agent with function-calling in just a few lines of code using our latest Hermes 2 Pro model
supports json mode and has in-context agentic abilities
it was great collaborating with
@Teknium1
and folks at
@NousResearch
let the local AGI unleash itself! 🚀

Introducing the latest version of our Hermes series of models, Hermes 2 Pro 7B.
This latest version improves several capabilities, using an updated and cleaned version of the Hermes 2 dataset, and is now trained on a diverse and rich set of function calling and JSON mode

26
110
616
0
7
35
recursive function calling works wonders as a google search agent 🔍
2
3
33
@markopolojarvi
@jxmnop
Gemini uses pathways instead of MoE and it is natively multimodal unlike GPT-4

1
0
33
@NousResearch
the model is highly performant on function calling with a pass rate of 95%
we use special tags such as <tool_call></tool_call> for function calling for parsing but no tags for json mode
and addition of json mode dataset with no tags doesn't degrade function calling ability

4
2
30
merge of Herme-2-Pro and Llama-3-Instruct is here🔄
you can pull the ollama version of Hermes-2-Theta gguf here:
Me and
@chargoddard
collabed to make something pretty unique here, Hermes 2 Θ (Theta) - a Hermes 2 Pro + Llama-3 Instruct merge that takes Hermes to the next level (and gets to meme on gpt4"o" at the same time).
Check it out on HF here:
We added some

31
40
356
1
7
30
Qwen1.5-7B beats Mistral-7B in tool-use while the largest 72B models performs close to GPT-4


👋 Qwen's latest open source work, Qwen1.5, says hello to the world !!
👉🏻 More sizes: six sizes for your different needs. 0.5B, 1.8B, 4B, 7B, 14B and 72B, including Base and Chat.
👉🏻 Better alignment: despite still trailing behind GPT-4-Turbo, the largest open-source

41
135
638
3
3
28
Hermes 2 Pro matches GPT-3.5 on function calling with 100% pass rate on mini eval by
@cleavey1985
💯


Just published a post with my first look into function calling with Hermes-2-Pro-Mistral-7B.
Thanks to
@NousResearch
@Teknium1
@intrstllrninja
@theemozilla
@karan4d
@huemin_art
for the amazing open source model, dataset, evaluation, and so on.
2
14
84
1
1
28
DeepSeek-v2 paper hints that "less may not be more for alignment"

2
6
26
however the router "exhibits some structured syntactic behavior" for eg.
- "self" in Python and "question" in English get often routed through same expert
- indentation in code get assigned to same experts
- consecutive tokens also get assigned same experts
2
1
25
what if i told you your embedding model and generative model can be a single model?

2
4
24
orchestrating an actor-critic agentic framework using Hermes-2-Pro json-mode running on
@ollama
2
2
23
stock analysis and web search agent with local function calling using
@NousResearch
Hermes 2 Pro model running on
@ollama
🚀

0
3
15
could this maze of mumbo jumbo be the new SoTA arch?

6
0
22
with release of Hermes 2 Pro we are also filling the gap of lacking public benchmarks for common LLM use-cases like function-calling and json-mode
we have made our evaluation framework and eval datasets public
We also created a custom evaluation framework for Function Calling and JSON Mode, with tests based on the function calling eval dataset made by
@FireworksAI_HQ
@intrstllrninja
created this custom evaluation framework to make our customized pipeline for parsing and handling our
1
4
53
1
2
21
Yi data engineering principle:
"promote quality over quantity for both pretraining and finetuning"

3
1
22
░G░P░U░P░O░O░R░I░N░B░I░O░


2
0
20
@JoannotFovea
have you had the time to look at the tests though?

I'm so glad we are using MMLU to judge our LLMs
I couldn't imagine my AI not nailing these test questions!

24
21
365
3
0
21
@markopolojarvi
@jxmnop
yes the Gemini paper does mention that they use the PATHWAYS framework

1
0
20
@abacaj
Claude-2 and Mixtral (on together) are already drop in replacements for GPT-3.5 for extraction function calling type tasks
it will be interesting to watch the market segmentation of API users unfold
2
2
21
to put the price per million tokens in perspective,
100 tokens ≈ 75 words
1M tokens ≈ 750,000 words
harry potter series = 1,084,170
1 M tokens ≈ 69% of harry potter series
if we use
@anyscalecompute
you have entire harry potter series worth of words available for $0.75
2
1
19
CodeLlama 7B is quite powerful when it comes to structured output such as json
swapped OpenAI API with
@LMStudioAI
local http inference server running Code Llama for a table extraction and transformation project and it works great w/ minor prompt engineering updates

2
3
18
@markopolojarvi
@jxmnop
They have been using Pathways system for orchestration of distributed computation for accelerators which was developed for the Pathways architecture for training a single model for different domains and tasks
1
0
17
phi-3-mini's data optimal regime is achieved through filtering web data for correct level of knowledge keeping more data that improves reasoning
local LLMs don't need to know ephemeral knowledge such as "who won a particular premier league match" which leaves room for reasoning

1
0
17
RIP Akira Toriyama

‘DRAGON BALL’ creator Akira Toriyama has sadly passed away at the age of 68.

7K
76K
378K
1
3
18
are LLMs evolving into computation graphs with dynamic allocation of compute?


These savings further compound when paired with Mixture of Experts. We are entering an era of scalable compute of LLMs. Tokens will not have fixed costs, the machine will take the time it needs to think. Massive improvements for both gpu rich and poor

2
8
149
0
2
17
great datasets, what's lacking is dedicated datasets for structured output, tool-use and agents

💾 LLM Datasets
LLM development is increasingly moving towards curating high-quality datasets, as shown by Llama 3.
I've compiled a collection of fine-tuning datasets along with advice and tools for creating your own.
💻 GitHub:

22
155
771
0
1
17
for higher complexity coding tasks, asking the model to first generate detailed code descriptions before generating code boosts performance of DeepSeek-Coder-Instruct models with this prompt:
"You need first to write a step-by-step outline and then write the code"

3
6
16
Hermes spawns "Grok" to hold a monologue on consciousness and nature of reality using code interpreter 😎
1
0
14
fine-tuning Mistral models is now one notebook away

Breaking: First live demo of the
@MistralAI
fine-tuning API (released a few hours ago) is here:
@sophiamyang
walks through:
- How to prep & validate your data
- Hyper params
- The fine-tuning API
- Integrations (W&B, etc)
- A treasure trove of collab notebooks & docs
3
45
341
1
2
15
@pydantic
's "model_json_schema()" is a good method to provide your structured json schema to the LLM
the benefit with that is your pydantic field descriptions act as additional prompt for the key you are interested in extracting

2
1
15

to do list
- build AGI
- build AGI
- build AGI

0
1
15
Mistral 7B v0.3 now supports function calling with added special tool call tokens in the vocabulary


Mistral just silently dropped v0.3 for their 7B model with extended vocab upto 32768 and function calling support.
No eval data yet.

3
0
60
1
1
15
the outlier being "DM Mathematics" which has a marginally different distribution of experts
the authors attribute it to dataset's synthetic nature and having limited coverage of natural language

1
0
15
recursion can be achieved pretty easily by continuing to run inference if model completion has "tool_calls" else return final assistant message

1
0
14
<cmd>
sudo python3 akashic_records.py --entity ["sam altman", "elon musk"] --mode "email thread" --topic "superintelligence scenarios"
</cmd>
4
4
14
empower yourself with local operating system assistant with Hermes 2 Pro function calling model

Hermes 2 Pro function calling in action - a sneak peek of what OSS local assistants will look like - thanks to
@NousResearch
@Teknium1
@intrstllrninja
6
9
68
0
1
13
it's insane how far we can get by just copying layers and increasing depth of a good model like llama-3-70B

@maximelabonne
And another thing - llama3-70b is "almost there" and llama3-120b is "there" - but the only difference is extra layers, copied even. No new information was trained. So this level of intelligence really *does* emerge from the depth of the model. It's not just a function of the
12
20
191
0
0
13
json-mode with Hermes-2-Pro doesn't need grammars to enforce json schema

Running local RAG and want to get structured JSON output for extracted data from PDF files?
1. Use this LLM with Ollama: adrienbrault/nous-hermes2pro:Q5_K_M-json
It retuns clean JSON output, no extra description text
2. Validate LLM with dynamic Pydantic class (based on

2
33
191
1
2
12
the results are coherent with that of the original paper
they found that experts highly specialized in syntax and/or semantics

1
0
13
the evaluation was run on a fine-tuned Qwen1.5-0.5B base model over a mixture of Hermes and function calling dataset for 4 epochs

3
0
13

you can now run Hermes-2-Pro-Llama-3-8b on ollama

@NousResearch
Pushed to
@ollama
!
ollama run adrienbrault/nous-hermes2pro-llama3-8b:q4_K_M --format json 'solar system as json'
3
7
47
0
1
12

this sounds more like an AI cartel

This morning the Department of Homeland Security announced the establishment of the Artificial Intelligence Safety and Security Board. The 22 inaugural members include Sam Altman, Dario Amodei, Jensen Huang, Satya Nadella, Sundar Pichai and many others.

305
240
1K
2
0
12
kardashev gradient climber spotted

Sharing a bit more about Reflect Orbital today.
@4TristanS
and I are developing a constellation of revolutionary satellites to sell sunlight to thousands of solar farms after dark.
We think sunlight is the new oil and space is ready to support energy infrastructure. This
464
721
4K
0
2
12

okay NVIDIA needs to come up with consumer GPUs with Blackwell architecture if labs keep open-sourcing large MoE models

It’s finally here 🎉🥳
In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯
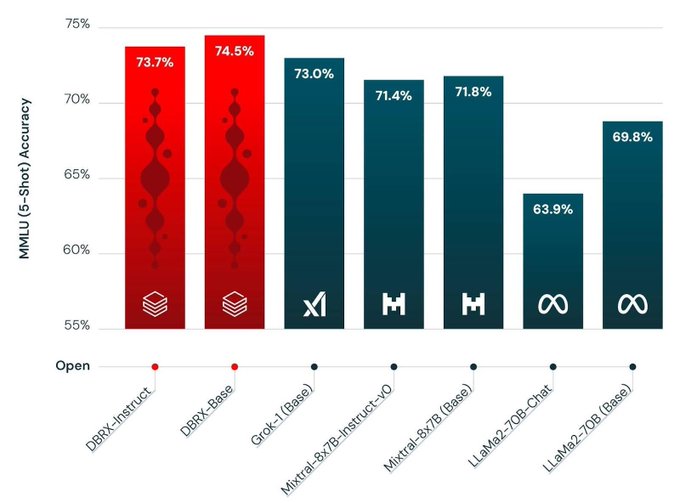
28
130
826
0
1
10
3Blue1Brown video on visualizing "attention" needs your attention

The next chapter about transformers is up on YouTube, digging into the attention mechanism:
The model works with vectors representing tokens (think words), and this is the mechanism that allows those vectors to take in meaning from context.
62
774
5K
0
1
11
@TheJohnEgan
@realGeorgeHotz
@__tinygrad__
it is the most intuitive implementation of mixtral MoE i have seen so far
here's the link to the code:
and the stream:

0
1
11
XML as root syntax with text or structured output like JSON within it is the new "AI Markup Language"
At first when I saw xml for Claude I was like "WTF Why XML". Now I LOVE xml so much, can't prompt without it.
Never going back
31
18
377
0
0
11
great to see
@DbrxMosaicAI
's DBRX use native chatml format!
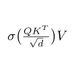
Took a look at
@databricks
's new open source 132 billion model called DBRX!
1) Merged attention QKV clamped betw (-8, 8)
2) Not RMS Layernorm - now has mean removal unlike Llama
3) 4 active experts / 16. Mixtral 2/8 experts.
4)
@OpenAI
's TikToken tokenizer 100K. Llama splits

24
172
1K
2
3
10
@jeremyphoward
@AnthropicAI
we trained Hermes 2 Pro function calling model to generate function calls delimited by <tool_call></tool_call> tags and we happily use XML ElementTree to parse the function calls but community seems to prefer regex 🤷♂️
1
0
7
@RaameshKoirala
@ila_home
Bro people with science degrees, research experience, on the job experience etc can call themselves scientists!
Even a political science or a social science degree holder can call themselves scientists. Please be open minded about choices people make. Please be respectful! Thks!
1
1
10
@yacineMTB
@xlr8harder
can we just make it convention for python functions to return a result and [error/s]
1
1
9
hey devin set up my conda environment for a training run fixing all the quirky CUDA issues please!🤯

1
1
8
After Databricks we have another cloud db provider Snowflake enter the LLM arena with a massive 480B MoE
Should be a good SQL code generation model given its benchmark performance

.
@SnowflakeDB
is thrilled to announce
#SnowflakeArctic
: A state-of-the-art large language model uniquely designed to be the most open, enterprise-grade LLM on the market.
This is a big step forward for open source LLMs. And it’s a big moment for Snowflake in our
#AI
journey as
39
88
588
0
1
10
@bindureddy
Not true. This opens up development of autonomous agents that solve specific problems by taking on various roles and tasks like a small team does.
AI hallucinations can be easily fixed with human supervisor in the loop who makes final production decisions.
4
0
10

if you're building agentic frameworks for process automation, here's my two cents:
- for repeated tasks human curated agents with deterministic workflow is the way to go
- for spontaneous tasks let the model generate execution graph with agents personas on the fly

if you overlay our agent types...
- if it's important and all the time, you should hand-craft it.
- the stuff that is all the time but not important is likely tasks types and tools that are relevant to your business, so a specialized agent can help.
- for stuff that's

3
3
43
1
1
9
LocalAI API supports Hermes-2-Pro Llama-3-8B function calling in OpenAI API standard 🚀

👇New models available in the LocalAI gallery!
- NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF () Another great release from
@Teknium1
🙌 !
- MaziyarPanahi/WizardLM2-7b () cheapeau to
@MaziyarPanahi
for the fantastic work ! 🫶
Enjoy!

2
1
13
0
2
10
@karan4d
@lumpenspace
claude was trained with prompts that use xml tags for wrapping parts of the prompt such as instruction, examples, documents etc.
their guide also mentions that it's especially useful for mathematics and code generation

1
0
8
@erhartford
@abacaj
We’re working on open source modules for Mixture of Experts (MoE) inference with finetuned LoRA experts loaded in memory that are sparsely activated through a prompt gating network
2
0
9
hear me out, an LLM trained on world model of the marvel universe

2
0
7
check out the latest Hermes 2 Pro on Llama-3 8B w/ json-mode and function calling which beats Llama-3 8B Instruct on several benchmarks
Announcing Hermes 2 Pro on Llama-3 8B! Nous Research's first Llama-3 based model is now available on HuggingFace.
Hermes Pro comes with Function Calling and Structured Output capabilities, and the Llama-3 version now uses dedicated tokens for tool call parsing tags, to make

35
96
581
1
1
9
Hermes 2 Pro function-calling model integrated with search engine by
@ExaAILabs
👀

added
@ExaAILabs
support for use with
@NousResearch
new function-calling model Nous Hermes 2 Pro and it's pretty great!
3
7
48
0
0
8