

Dan
@dan_p_simpson
Followers
5,173
Following
718
Media
1,031
Statuses
11,166
Explore trending content on Musk Viewer
Lions
• 111718 Tweets
Ricardo
• 107697 Tweets
Karime
• 93200 Tweets
重陽の節句
• 63464 Tweets
#TheStatement7
• 59206 Tweets
Rams
• 42614 Tweets
Alice Guo
• 41487 Tweets
シーザリオ
• 37129 Tweets
昭和99年
• 33045 Tweets
Didi
• 27189 Tweets
ZEE x COS
• 24131 Tweets
Stafford
• 22371 Tweets
高市さん
• 20956 Tweets
Goff
• 15229 Tweets
#LISAxVogueKorea
• 14969 Tweets
कारगिल युद्ध
• 14013 Tweets
PRABOWOJKW TetapSELARAS
• 13273 Tweets
कैप्टन विक्रम बत्रा
• 12858 Tweets
Guo Hua Ping
• 12830 Tweets
ADUdomba UdahGAKJAMAN
• 12763 Tweets
斎藤元彦知事
• 12620 Tweets
BTS IS SEVEN
• 11747 Tweets
परमवीर चक्र
• 11248 Tweets
落語心中
• 10347 Tweets




















Pinned Tweet

Should anyone ever want to know what I think about things, I have a blog (yay!). It is a journey. I'll thread in some of the better posts below and will add to them as time goes on

3
1
23
Career news!! So. Some exciting future news. I've decided that after 8 jobs, 6 countries, and incalculable joy, it's time for me to hang up my academic career. (1/)
23
22
367
This is just shouty dplyr.


7
49
340
I am programming something mildly complex in Python and it makes me appreciate R a lot. Every time I try to do something that would be easy in R I get my face eaten. (But also the more straightforward programming stuff is kinda nice in Python.)
9
4
180
I have another blog post! This one is a bit less wild than the last one. It's an introduction to multilevel models and a discussion of visual diagnostics. I hope you enjoy it.

6
37
184
@meakoopa
The first NFT musical was phantom because it began with the sale of a useless monkey that someone else owned.
5
32
179
I was in the mood so I wrote a blog post about setting prior distributions! In particular, I went through the mechanics of PC priors, which are a fairly useful way to set priors in a lot of practical cases

10
15
143
The glorious Danielle Navarro has decided to grace us with an intro to MCMC post

4
26
142
Impossible to stress enough how good linear and logistic regression are at what they do. If there’s structure, add it. Don’t rely on deep learning ideas because it’s not data efficient by design

its crazy how data inefficient neural net optimization can be - i have a problem where a linear regression gets 80% accuracy but it takes 400k samples and 100+ epochs of training for a 2 layer relu net to match that (my learning rate is fine thanks for asking)
5
4
63
5
11
140

I have blogged. This was supposed to be a quick lil intro to Laplace approximations but it ended up falling into using symbolic differentiation and the Jaxpr internal representation and even a little bit of sparse autodiff to speed things up. Enjoy!

2
18
119
This is a nice tool we built. We wanted some scalable approximate Bayes that plays nicely with PyTorch, allows for flexible likelihoods, and plays nicely with transformers. We couldn't find anything that hit all of our needs, so we (
@Sam_Duffield
mainly) built it. More methods to

We're excited to announce posteriors!
posteriors is an open-source Python library designed to make it as easy as possible to apply uncertainty quantification to deep learning models with PyTorch.
4
54
336
2
16
110
Howdy sparse matrix fans! Part 7 of my blog on making sparse linear algebra work with JAX that you've all* been waiting for is here
* it is possible that no one was waiting for this.
10
13
98
Every single witch spell I've hit so far from the
@WorldsBeyondPod
witch playtest is SO GOOD even if one of my players knocked herself out because she didn't read Breath of Belladonna carefully enough
2
3
98
I decided to start a project. Mostly to satisfy my own curiosity. I reckon it has a relatively small chance of concluding nicely, but I'm gonna try to get autodiff working for linear mixed models and other models with Gaussian data and GMRF priors.
12
6
96
I am once again informing you that I have blogged. If you've ever wondered "how should I put priors on the parameters of a GP's covariance function?" this is the post for you!

5
12
92
It has come to my attention that I have once again blogged. This time, I decided to write out how the Markov property works when you're dealing with space rather than time. It's another in my list of weird posts of Gaussian Processes.

4
13
93

I mean lord bless and hold rstudio but Florida? Fucking Florida? Now? At this time? In the year of our lord two thousand and twenty two? Florida?
10
4
92
The absolute chaos of this is giving me life.


8
6
89
I once again have a blog post. (Groundbreaking). This is part two in the series where I try to remember how sparse Cholesky decompositions work in the hope of eventually differentiating them. We do not get there today.
6
17
89
As always, we should remember that when our models have a "random effect"-type term (be it spatial, temporal, otherwise structured, or iid), it will likely interact with our covariate effects is funky and exciting ways
3
11
87

An extremely fun paper on massively parallel MCMC on a GPU lead my my final PhD student Alex and, of course, the dream team of
@avehtari
@jazzystats
and Catherine! It definitely threw up a pile of interesting issues

0
14
81
Just in case anyone who researches ordinal scales is looking for a title: "Likert rough? Ambiguous scales and subjective measurement"
4
9
80
Propensity scores are great. The idea that the observed data design might tell us something about the selection mechanism is clever. Variants of inverse probability weighting when you don’t have control over the lower bound of those estimated probabilities is a recipe for heavy

Propensity scores for causal inference
22
7
22
3
8
79
Tech interviews are wild. My man if in a SCREENING interview you want me to code up a whole-ass game of Othello let me tell you I am not your person.
3
0
75
This is the inevitable result of people using a transformer when what they really were looking for is a DATABASE. Sure. Use generative AI to smooth the UI, but if you don't have a clean knowledge base at the bottom of your stack, your generative AI is gonna, you know, generate.

i asked SARAH, the World Health Organization's new AI chatbot, for medical help near me, and it provided an entirely fabricated list of clinics/hospitals in SF. fake addresses, fake phone numbers.
check out
@jessicanix_
's take on SARAH here:
via
@business
54
955
4K
3
20
75
My love of R is infinite, but its tryCatch() syntax is just not that girl.
6
2
73
I got a sneak peak of
@djnavarro
's work in progress notes for her
@rstudio
conference workshop and I am literally stunned at how good they are. Truly gobsmacked. A queen walks among us.
0
1
73
I just remembered the greatest tweet of all time.


0
5
69
I have, I am a bit surprised to say, once again blogged. This time about Diffusion Models in machine learning. It's a high-level, historically focused introduction that will either be coherent and interesting to you or not your thing. Love you regardless.

6
6
70
I friend of mine sent me this from a conference in Berlin and truly I’ve never wanted to apologize to a speaker more.

4
2
67
I am, once again, begging people to remember that the posterior for the “bayesian lasso” behaves nothing like the frequentist lasso estimator (except that the latter coincides with the former’s mode, which is a poor posterior summary)

@SolomonKurz
@wesbonifay
My reasoning is that the choice of distribution for the prior has strong theoretical and practical implications for the inferential problem. e.g., normal vs double-exponential prior imply different forms of penalized likelihoods:
2
2
14
4
10
65
Stop looking for truth from data. Start looking for “collection + assumptions = possibility”. Thats the only true thing.
1
12
62
I mean I have so many statistical things I don't like (exponential families, objective priors, etc) but today's real pain in the arse is epistemic vs aleatoric uncertainty. Truly just two terrible names.
9
2
60

This is probably a lot more detail than anyone will ever want, but I was working on revisions for a paper and in the process I wrote out basically everything I know about what happens to importance samplers when you truncate/trim/winsorize their tails.
4
3
60
I cannot stress enough that nothing works perfectly in statistics. Your god will betray you. But a lot of thing work well enough for the situation. Stay limber, be flexible, have fun.

For discrete distributions (even with ∞ support), the MLE converges a.s. in TV. This is naive estimate obviously not going to work for continuous distributions, but surely *something else* will?!
Nope, nothing.
@Tjdriii
1
5
54
2
2
58
Writing a blog. Sorta not sure if it's actually worth it. If anyone has thoughts they are welcome.




9
1
57
Anyway. This thread is long and my DMs (and email) are open. My CV (2 pages + papers/etc) and information about myself is on my website. I have a LinkedIn. If you're looking for someone like me in Melbourne or New York (with a visa), let's chat (15/15)
8
14
57
Also like if you like New York and you like me you are in luck because apparently I will live here relatively soon. If you don’t like me you’re shit out of luck.
7
0
56
For the daytime people who are interested in Laplace approximations and trying to do strange things in JAX. Also should anyone know of a job in NYC I am looking!
I have blogged. This was supposed to be a quick lil intro to Laplace approximations but it ended up falling into using symbolic differentiation and the Jaxpr internal representation and even a little bit of sparse autodiff to speed things up. Enjoy!
2
18
119
4
12
55

This is definitely true. The other thing to do is to learn classical stats well enough that it’s not embarrassing when you give reasons why bayes is better.

AI is moving fast—if you want to learn something likely to last, learn Bayesian methods. Bayes has already survived two and half centuries of people trying hard to kill it off, survived by being just too practically useful to die—Bayes is indispensable, yesterday, today, tomorrow
14
43
407
1
2
53
Hi kids! Do you like violence? Wanna see me stick a linear measure for association through each one of my eyelids?
3
3
53
People seem surprised by this, but it’s just the latest in a long line of examples that shows that clever modelling will often beat generic, brute-force, scale-is-all-you-need methods.

this paper's nuts. for sentence classification on out-of-domain datasets, all neural (Transformer or not) approaches lose to good old kNN on representations generated by.... gzip
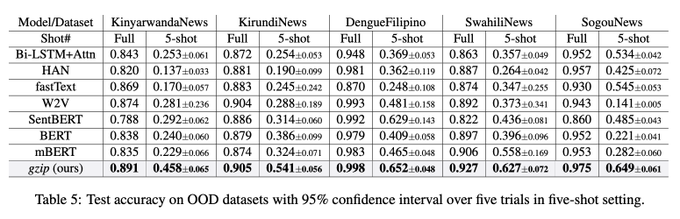
134
893
5K
3
5
51
Danielle wrote a pretty bleak blog post. It is worth reading.

0
21
51
To be honest, conformal prediction is one of those methods that's very cool but also a precise answer to a question that I'm not asking. Nevertheless, this is an interesting advance

6
5
52

In a fit of enthusiasm, I have once again blogged. This time I'm talking about the age old topic of what happens to MCMC when your acceptance probability is a bit wrong. It's far from a complete survey, but it will do.

2
4
50
This paper is using z as data and y as parameters and honestly I am broken now.
5
0
50
Matlab is not built for statistical computing and should not be used anywhere near data. It’s a teaching language for people who‘s program was written before Python stabilised.

Matlab still doesn't have stable logpdf versions for common distributions! 🤯
Julia has it, even for general mixture models, using the logsumexp trick:

0
1
30
3
4
48
Well this is cool: a proper set of hooks into
@mcmc_stan
for evaluating the complied log-densities and gradients in Python/Julia/R. Great for algorithm development!

1
9
46
Are we still doing this? You methodology will never justify your existence. Understanding bayes makes you a better frequentist. Understanding proper frequentism makes you a better bayesian. Econometrics, however, is the one that doesn’t make you better at anything.

You know at least the Bayesian versus frequentist squabbles make us look smart to outsiders
0
3
51
4
6
46
Almost like using the language that suits the task is … a good idea?
3
1
46
I know perfectly well not to click on those “list of why academic careers are great” threads aimed at people who are considering getting good jobs in industry but I just saw one that mentioned academia’s great work-life balance. Come the fuck on.
2
1
47
The third decimal place: A Kaggle journey.

Are you ready to embark on a deep learning journey? I've just released over 6 hours of videos and the first in a series of notebooks showing the thought process of how I got to
#1
in a current Kaggle comp.
Follow this 🧵 for updates on the journey!
15
241
1K
1
1
46
If I could summon this many men in real life by saying “Python” I wouldn’t be single.
1
0
46
Six (6!) of my colleagues just got promoted AND one of my former PhD students just landed a fancy pants industry job. This is a good Thursday.
2
0
46
Working at
@NormalComputing
is pretty nice. We’ve got an MLE job opening soon (specifically for MLEs with some data experience). Watch this space

5
8
44
So. What do I do? Well I'm a statistician and data scientist who has a lot of experience in bleeding edge techniques for modelling complex data and ways to use modern computational techniques to really make the data sing. (8/)
2
2
45
Some random thoughts on this paper, which is a nice review of what marginal likelihoods can and can't do:

The marginal likelihood (evidence) provides an elegant approach to hypothesis testing and hyperparameter learning, but it has fascinating limits as a generalization proxy, with resolutions.
w/
@LotfiSanae
,
@Pavel_Izmailov
,
@g_benton_
,
@micahgoldblum
1/23

3
75
312
1
4
44
It's ALWAYS the data. That's the most important lesson for anything within the stats/ML/AI space. It is always the data.
@alz_zyd_
when i train or fine tune a model i like to look at validation set examples where it does well or poorly and do a lookup in the training set for similar examples.
every time i have been pleasantly or unpleasantly surprised at "why did my model do that?" looking at a few nearest
0
1
13
3
3
44
People of twitter: I have once again blogged. And it's on sparse matrices. The long awaited (by whom?) first part (!) of my much more serious attempt to make a sparse Cholesky factorization that works in
#jax
is here. It was mostly written on a plane.

1
1
42

This advice happens a lot and I think it's bad, honestly. I have hired innumerable people at this point and I have _never_ been impressed enough by someone's blog or GitHub repos for it to move the needle.
People say to blog and do portfolio projects as a data scientist as a way to build and protect yourself professionally
Is it bad if I don’t?
11
0
26
10
1
41
But every single method in causal inference is going to rely on wild, unverifiable assumptions. So if you think of causal inference as assumption laundering it’s incredibly useful. But to paraphrase LeCam, if you’re going to assume n-> infinity, you better send n to infinity
2
2
41
LLMs instead of medical advisors for poor people is, you know, my personal idea of a tech dystopia. It’s kinda strange to see someone excited about it specifically.

these tools will help us be more productive (can't wait to spend less time doing email!), healthier (AI medical advisors for people who can’t afford care), smarter (students using ChatGPT to learn), and more entertained (AI memes lolol).
320
88
1K
1
3
38
I may never stop laughing about this (or the humourless scolds who got upset)

0
4
40
One of the many things about food in Australia is that sometimes they’ll just be like “fuck it. Eggs Benedict on fried chicken with bacon and greens” and we add like “why not?”

4
1
40
You know, it's been 15-odd years since I started doing statistics full time and today is the first time I actually computed the sampling distribution of something from scratch.
1
0
39
I have been hunting down a bug in my code for about 3 hours and I just found it and I would like to hurl myself into the ocean now because I'm stupider than sand.
4
1
39
Not gonna lie. My first thought was not “oh. an artificial finger”

3
0
39
I finally worked it out by constantly screaming “what is the fucking likelihood?!” at books and papers until one was revealed.
4
2
38
If anyone is curious, the first time I saw someone do this was in ~2011 and it was done with some neuroscience of vision and a lasso.

I'm speechless.
Not peer-reviewed yet but a submitted paper.
The 'presented images' were shown to a group of humans. The 'reconstructed images' were the result of an fMRI output to Stable Diffusion.
In other words,
#stablediffusion
literally read people's minds.
Source 👇

541
4K
22K
3
2
38
Nothing gives me more joy than entering my resume line by line on some weird online form.
1
0
38
TFW you google something and it just sends you to your own damn blog
3
1
37
I mean sure but to my mind his masterpiece was this very funny, very insightful paper about maximum likelihood.

Lucien Le Cam (1924 – 2000) was a major figure in asymptotic theory of statistics.
His 1986 magnum opus was "Asymptotic Methods in Statistical Decision Theory" He's also well-known for "Le Cam's Theorem" (1960): The sum of N Bernoulli r.v.'s is approx Poisson distributed.
1/2

5
10
87
3
4
35
Lol remember that time I was unemployed and I wrote a long technical blog post about the Markov property on general spaces
2
0
37
CRAN is simply not fit for purpose. They cannot keep doing this. There is literally no reasonable argument for this behaviour. None.

CRAN will _not_ remove all packages that depend on ggplot2, rest assured. We are working to resolve this and a fix to isoband should be submitted this week.
10
48
279
2
1
36
One of the true joys of not being an academic anymore is that sometimes I see dumb stats takes on here and I just think “not my problem”. (It was never my problem.)
0
0
37


Alex,
@jazzystats
,
@avehtari
, Catherine, and I wrote a paper on this that I quite like. The tl;dr is that when you have dependency, using joint predictive distributions leads to lower-variance CV estimators


Cross validation and pointwise or joint measures of prediction accuracy
0
12
36
2
7
36
But I do want to say that I've had an absolute blast, but I'm really happy to say that my academic journey is ending. It's been _a long time_ and I have done _a lot_. I'm very satisfied. There's nothing I've not done as an academic that I wish I'd done. (3/)
1
0
36
The stuff in here is really amazing for anyone who’s interested in how things like Stan and PyMC could work (or, really, the next generation of them).

"Program Analysis of Probabilistic Programs"
My PhD thesis is now available on arXiv!
Contains:
- A short intro to
#BayesianInference
- An intro to
#ProbabilisticProgramming
with examples in different PPLs
- PPL program analysis papers with commentary
11
97
607
0
2
36
In my life I have never remembered this. I just start talking about long tails.

@Whitehughes
@pippinsboss
@Mathowitz
I prefer to use the terms "positive" and "negative". I remember it like this:

1
0
10
2
1
35
Hear me out though! If visualisations are implicit models (and they are), we should sometimes check their ability to do their task. How? Buggered if I know. But the visual inference people have some interesting thoughts.

3
1
33
Not a big fan of language wars (except I fucking hate Matlab and it should be firmly left in the 90s/00s) but I do think that there is a strong case in a long program (Aka not a one year masters) to ensure that graduates have an ok grasp of at least a few languages

Some dichotomies are true though, for example every student a department teaches Stata/SPSS is a student who deserves their money back
6
10
115
2
3
35
That old saying that "every happy python dev is happy in the same way, every unhappy python dev uses a different plotting library" is really very true.
5
3
35
Nobody is less happy than someone who’s trying to fit every task into a single language.
People often ask me what language I use for data science. There’s no one answer:
- Python for general purpose / AI/ML
- R for many stats analyses
- SQL for data retrieval and wrangling
- Spark / Pyspark for many data engineering tasks
Fabric is dream platform as it does all
5
2
69
1
2
34
I have once again blogged. This time I decided mostly on a whim to look at an old "counterexample" of good Bayesian practice by Robins and Ritov that Larry Wasserman has in one of his books. It always struck me as a bit off, so I dug into it

3
4
34
@economeager
The awesome power of being dumb about things no one else understands is underrated.
1
1
34
What if, a failure diary? Which is to say I have a new blog post in which I fail to make JAX do what I want it to do! (This one might be of fringe interest, but I'm trying to work through my process here)
5
2
32
Now obviously this twitter account is ... not designed, in a structural sense, to find a new job. So yeah. Whatever. That's what we've got, that what we're using. (7/)
2
1
33
PhD stipends are a disgrace. Almost universally. They make a hard process harder. They echo into your later life. They are a disgrace. You should not be punished for pursuing a PhD.
1
4
33