

Alireza Fathi
@alirezafathi
Followers
1,770
Following
164
Media
25
Statuses
436
Research Scientist / TLM @ Google DeepMind
Mountain View, CA
Joined August 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
LINGORM MAJOR FANDOM
• 683273 Tweets
Errejón
• 585216 Tweets
Durk
• 108552 Tweets
Tattvadarshi Sant Rampal Ji
• 69420 Tweets
#Mステ
• 66868 Tweets
FIGHTING FOR LOVE
• 58632 Tweets
#MGI2024
• 48184 Tweets
Keith
• 42562 Tweets
#HAPPYYUTADAY
• 35139 Tweets
結城さく
• 34603 Tweets
悪役令嬢の中の人
• 28423 Tweets
Gustavo Gayer
• 25738 Tweets
#ネトフリでタイプロ
• 24924 Tweets
#ساعه_استجابه
• 24539 Tweets
#中本悠太_わたし達のHOPE
• 23245 Tweets
Bologna
• 18508 Tweets
#النصر_الخلود
• 17779 Tweets
#유타생일_에브리바디_스크림
• 17555 Tweets
HAPPY BIRTHDAY YUTA
• 16958 Tweets
#荒野7周年空前の超感謝祭
• 16334 Tweets
#史上初金車確定無料ガチャ
• 16011 Tweets
LOVE IN MY HEART PREVIEW
• 14396 Tweets
レジェンド車両
• 13498 Tweets
全員最大金枠アイテム5つ
• 13320 Tweets
FACT復活
• 11111 Tweets




















Pinned Tweet

Our team at Google DeepMind is seeking a Research Scientist with a strong publication record (multiple first-author papers) on multi-modal LLMs in top ML venues like NeurIPS, ICLR, CVPR. Email me at af_hiring
@google
.com
@CordeliaSchmid
4
48
384
Robotics at Google has released a very high quality dataset of scanned objects. It could enable interesting research in 3d shape modeling.

2
90
311
Jitendra Malik's thoughts on Foundation Models, in the Stanford HAI workshop

4
40
185
We have released TensorFlow 3D!

Announcing the release of TensorFlow 3D, a set of training and evaluation pipelines for state-of-the-art 3D semantic segmentation, object detection and instance segmentation, with support for distributed training. Check it out and download the code at

10
336
1K
2
19
79
Augmenting Large Language & Visual models with Retrieval helps the model to answer questions that were not present in the training data. REVEAL is one of the recent works by our team
@acbuller
,
@ahmetius
,
@jesu9
,
@MrZiruiWang
, David Ross,
@CordeliaSchmid

0
6
37
Most of the previous work on 3d object detection use only one frame of data. In our
#eccv2020
paper, we present a 3d sparse LSTM model that achieves more accurate results when applied to a sequence of point clouds.

0
5
29
Our recent work on object-centric neural rendering. Our new formulation makes it possible to move the objects around in the scene and still be able to render high quality images from different views.

We made NeRF compositional! By learning object-centric neural scattering functions (OSFs), we can now compose dynamic scenes from captured images of objects.
Website:
Joint work with
@alirezafathi
@jiajunwu_cs
Thomas Funkhouser
4
44
254
1
2
30
I am glad that our
#cvpr2020
reviews are very positive, but at the same time I am very worried that the quality of the reviews have significantly degraded compared to few years ago.
1
0
26
Congratulations to Yue Wang (research intern), Rui Huang (AI resident), Wanyue Zhang (AI resident) and
@_abhijit_kundu_
for getting their papers accepted to
#eccv2020
.
1
0
24
Today marks my 7th year at Google! How time flies! Thank you, Google, for giving me the opportunity to work on what I enjoy...
4
0
20
Here is our Google AI blog post on AVIS, a Large Language Model Agent that achieves state-of-the-art results on visual information seeking tasks.
@acbuller
@ahmetius
@jesu9
@CordeliaSchmid
Today on the blog, read all about AVIS — Autonomous Visual Information Seeking with Large Language Models — a novel method that iteratively employs a planner and reasoner to achieve state-of-the-art results on visual information seeking tasks →

36
212
811
0
3
18
Tesla’s event did a great job showing how far ahead Waymo is compared to everyone else!
0
1
20
REVEAL will be a highlight at
@CVPR
. Looking forward to discussing it in more details there with
@acbuller
,
@ahmetius
,
@jesu9
,
@CordeliaSchmid
Learn how REVEAL, an end-to-end retrieval-augmented visual-language model that learns to use multi-source multi-modal data to answer knowledge-intensive queries, achieves state-of-the-art results on visual question answering and image caption tasks.

16
88
278
2
2
17
Our ECCV paper on "Pillar-based Object Detection for Autonomous Driving" that achieves state of the art results on 3d object detection on the Waymo Open Dataset.

0
2
17
Another CVPR2020 paper by our group on detecting 3d objects and predicting their 3d shapes

0
0
13
Looking forward to presenting our work on 3d scene understanding in the Deep Learning 2.0 Virtual Summit.

I am looking forward to Alireza Fathi presenting his research advancements at the Deep Learning 2.0 Virtual Summit, Jan 2021. Alireza is currently working on object detection and segmentation in 3D. Join us, and Alireza in January:
#computervision

0
0
2
0
1
12
Neural Networks seem to follow a puzzlingly simple strategy to classify images
0
2
12
We are gonna be able to go back to office starting July 12th! Never thought I would be this excited to go back to work in person :)
1
0
12
Having to take shelter in place, I have been spending some time on gardening! Here is how our sour cherry tree is looking like today!

0
0
12
Vote for CVPR 2023 at Vancouver if you are at
#CVPR2019

It’s hard to think of a better place than
#Vancouver
for
#CVPR
2023. Beyond our strong team, it’s fitting that a conference on vision should take place in one of the most beautiful spots on earth. Check out our awesome bid
#AINorth
#AI
#computervision

0
29
84
0
3
11
🚀Introducing AVIS: a groundbreaking system that couples
#LLM
powered planning & reasoning with external tools, resulting in
#StateOfTheArt
performance on VQA datasets that demand external knowledge! 🧠🔍

AVIS: Autonomous Visual Information Seeking with Large Language Models
paper page:
In this paper, we propose an autonomous information seeking visual question answering framework, AVIS. Our method leverages a Large Language Model (LLM) to dynamically

2
26
85
0
4
11
One of the sad things during this pandemic is to observe the ugly gap between the rich and the poor. At the same time that the rich stays home and orders groceries online to avoid exposure, the poor shops those groceries in store and delivers them to make a living
0
1
11
I am sorry to see colleagues and friends getting affected by mass layoffs in recent days. Please reach out and I would try my best to help with any resources I can think of. Hopefully things will bounce back soon.
0
0
11
Great work Francis Engelman!
Our CVPR 2020 paper achieving the state of the art results on 3d instance segmentation in ScanNet and S3DIS :)

"3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation"
#CVPR2020
We perform SemInstSeg by proposal aggregation using a GraphConvNet to model higher-order proposal interactions!
Great results on ScanNet and S3DIS :)
@FrancisEngelman
0
15
59
1
0
11
Check out our CVPR paper on generative retrieval for web-scale entity recognition!

Happy to introduce GERALD - our new VLM that recognizes 6M+ entities, an exciting step towards Web-scale visual entity recognition!
Predictions are simply made by auto-regressively decoding a code representing the entity name.
Check out our CVPR24 paper:
2
19
132
4
0
9
We have just released the instance segmentation support for the Tensor Flow Object Detection API.
#TensorFlow
#ObjectDetection
#Google
#API
#Segmentation
#InstanceSegmentation

0
5
9
Something interesting that I just learned today! Are green, red, yellow and orange bell peppers different or the same?
0
0
8
Google has launched it's best thing for everything guide. No need for consumer reports subscription anymore!

0
1
8
Great job Steven. A network for predicting surface normals running in real-time on a pixel 2 phone
@StevenDHickson
@aCromulentName
Kevin Murphy
@irrfaan

0
1
8
An interesting blog post on using unity for creating synthetic data for object detection and beyond
0
2
7
Great course for learning deep reinforcement learning!

Want to learn deep RL? My deep RL course now has a permanent course number (CS285) and is being offered this semester:
Lecture videos here (so far, we've gotten through most of model-free RL, model-based RL coming up next):
14
476
2K
0
1
6
In this work led by
@ahmetius
we show that image recognition can benefit when retrieving similar images from a web-scale corpus of image-text pairs.

New
#CVPR2023
paper "Improving Image Recognition by Retrieving from Web-Scale Image-Text Data".
We improve the recognition capabilities of the model by retrieving images/texts from large-scale memory. Joint work with
@alirezafathi
and
@CordeliaSchmid
.

1
9
79
0
0
7
After almost a decade and billions in outside investment, Magic Leap's first product is finally on sale for $2,295. Here's what it's like.
#MagicLeap
0
1
6

Here is the link if you are interested in applying for the Google Summer Research Internship :)
0
0
7
OpenAI's new model fine-tuned from GPT3 for summarizing books!
1
1
6
These short Neurips reviews could be done by LLMs! Probably we don't need reviewers anymore...LLM would write the review and AC makes the decision by looking at the review and the paper!
2
1
6
This would be a great resource for software engineers and researchers outside Google

Google's software engineering best practices facilitate consistency & productivity. All code is peer reviewed for clarity, correctness, and adherence to standards. We've just published these practices. Highly recommended for any lab, academic or otherwise.
0
21
57
0
0
6
Happy 25th birthday Google 🎉

Happy 25th Birthday Google! 🎉
I have gotten incredible enjoyement from being along for the ride for 24+ of these years. When I joined, we were a handful of people wedged into a small office area in downtown Palo Alto above what is now a T-Mobile store.
1/

53
217
2K
1
0
6
Moore's law vs. reality animation. Very cool.

0
1
5
Congrats to Martial Hebert for becoming the new dean of School of Computer Science at CMU

0
2
5
@elonmusk
One keeps a car for 5 years on average. I promise u there won't be self driving cars in streets five years from now :)
1
0
5
An interesting podcast with Jitendra Malik on challenges in computer vision
1
0
5
'3D' is the most frequently used keyword after 'detection' in CVPR 2019
0
1
5
An interesting blog post on transformers in deep learning models

New blogpost! Transformers from scratch.
Modern transformers are super simple, so we can explain them in a really straightforward manner. Includes pytorch code.
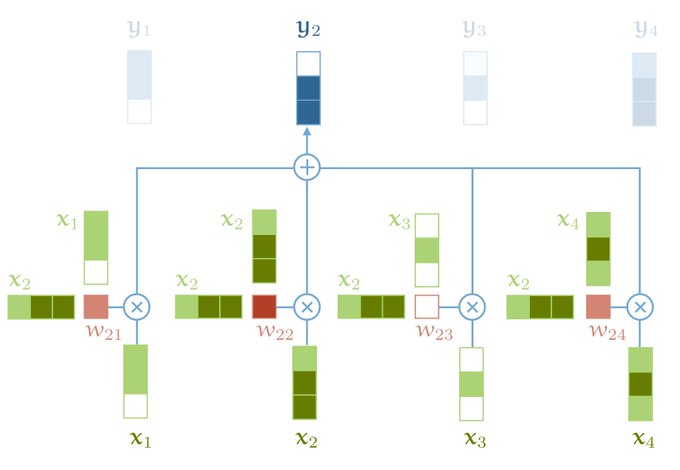
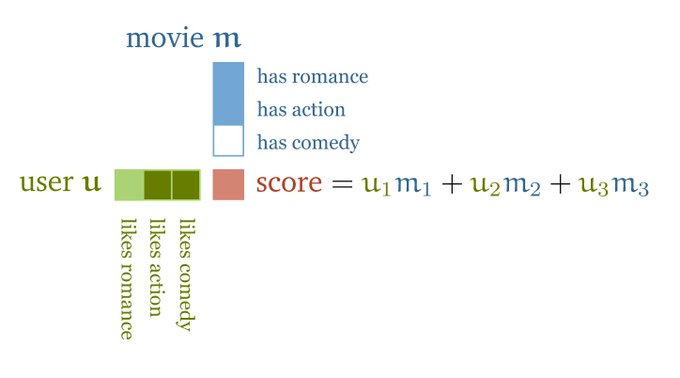
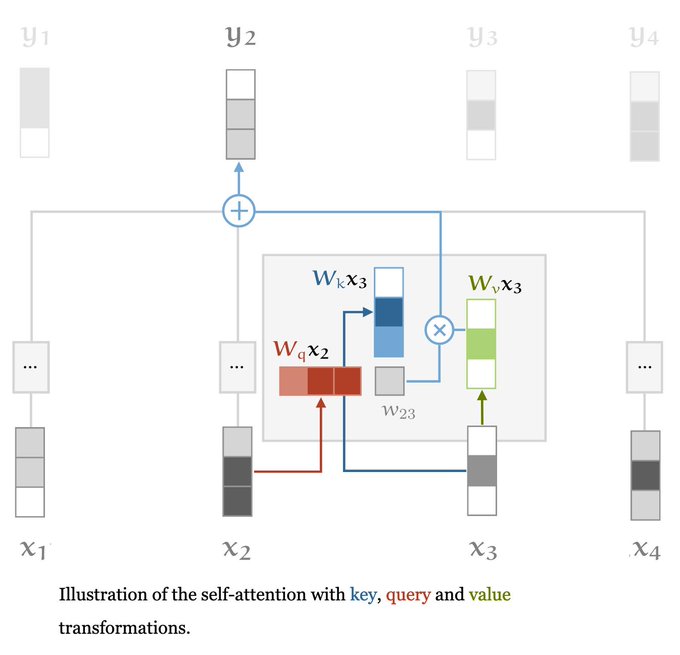
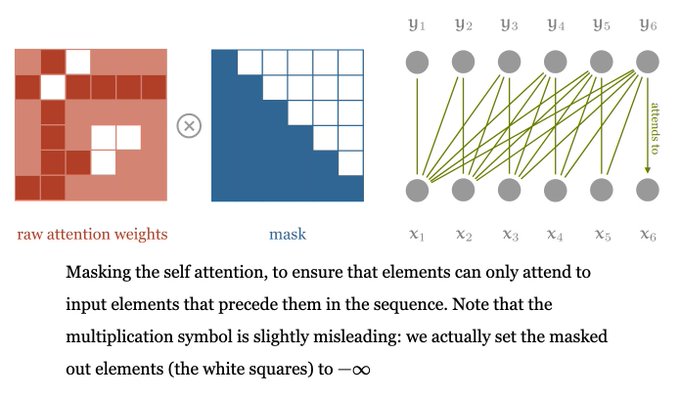
17
452
2K
0
0
5
@docmilanfar
That probably is right. But raising $90M in the current environment where most startups are having a hard time raising any money is a very strong signal
2
0
4
Folks in our team have released the Tensorflow 2.0 version of Object Detection API
#tensorflow
#ObjectDetection
1
2
4
@mattytgray
@GoogleAI
3D object detection and segmentation for self driving cars / robotics, augmented reality, etc.
0
0
4
Spread between 2-year and 30-year U.S. Treasury securities over time!

0
1
4
@JeffDean
@MelMel1082
Maximum possible distance on earth is about 19,000km. So this one is probably very unlikely to beat :)
0
0
4
I don't play video games, but if I do, I play FIFA! And it will be great if I have a work related reason to play!

0
0
4
GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models
0
0
4
This is how betting odds changed after last night's debate

0
0
4
@negar_rz
@3scorciav
@CVPR
@ICCVConference
I was thinking LLM mostly does a summarization and comparison to previous work. Not necessarily scoring the paper. This would make ACs job much easier, but AC would make the final decision by both looking at the summary and the paper itself.
1
0
2
NeurIPS2019 Competition tracks are released, including a 20K competition on 3d object detection organized by Lyft
#NeurIPS
#NeurIPS2019
0
0
3

Waymo open dataset is publicly released. Orders of magnitude larger than Kitti

Today, we're launching our Waymo Open Dataset. This high resolution lidar and camera data has been collected by our self-driving cars across a diverse range of situations. We're excited to share it directly with the research community. Download now:
18
337
897
0
0
3
Google just publicly released its DeepFakes dataset so all researchers can work on it.

Detecting deepfakes is one of the most important challenges ahead of us. Following our release of a synthetic audio dataset in Jan, we're releasing a large dataset of visual deepfakes to support researchers working on synthetic video detection
#GoogleAI
75
517
3K
0
0
3
200 Billion galaxies in the observable universe, and each galaxy has on average 100 Million stars! Don't take your life so serious stressing out for things that do not even matter on multi-galaxy level!
0
0
3
This might be a useful idea for last minute researchers like myself :)

I have a system to plan writing papers for conference deadlines. My students and some collaborators know about it. With the ICLR 2020 deadline coming up, I thought this might be a good time to share this with a wider audience.
10
230
925
0
0
3
I feel so out of touch with the people and what they care about around me. I thought I will look at Google trends to see what people are thinking about politics or economic situation, but I realized the main thing they care about at this moment is
#NFL

0
0
3

0
0
3
@drfeifei
@yukez
@leto__jean
@EmmaBrunskill
@silviocinguetta
Congratulations
@yukez
and
@drfeifei
. Have been lucky to work with both of you
0
0
3
More than 17 million Americans have more than 1 million dollars in assets!
0
0
3
Amazing photos from Pixel 4 show how computer vision and machine learning can give a strong boost to the camera hardware
0
0
3

It is true 🙂


12
707
2K
0
0
3
Rui Huang, Wanyue Zhang, Thomas Funkhouser, Abhijit Kundu, Caroline Pantofaru, David A Ross, Alireza Fathi,
An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds
1
0
2
Microsoft to add ChatGPT to Bing search engine

0
0
2
@realDonaldTrump
I support stopping illegal immigration! You should remove travel ban which stops legal immigration ASAP though!
0
1
2
Three industries that could be transformed by computer vision: Farming, Healthcare, Retail
0
0
2
This is how much an average U.S. worker has saved in their 401(k)
0
0
2
Yue Wang, Alireza Fathi, Abhijit Kundu, David A. Ross, Caroline Pantofaru, Thomas Funkhouser, Justin Solomon,
Pillar-based Object Detection for Autonomous Driving
1
1
2
This is a great opportunity to work closely with
@CordeliaSchmid
and many top researchers in her org!

Our team at Google Research is hiring a research intern working on video generation, please email xiuyegu
@google
.com if you are interested.
5
8
102
0
1
2
Apparently based on statistics, Twitter is tilted towards young males with a college education, while Instagram is focused on female users in the 18 to 49 crowd, with a higher portion of people without a High School education. So makes sense for Meta to go after this market. What
0
0
2
0
0
2
A nice literature review on deep graph networks

0
2
2
I went to my first CVPR in 2008 which was an order of magnitude smaller than this year's conference...
#cvpr
#cvpr19

How the
@cvpr2019
Conference -- tech's premier event for computer vision -- broke records on all fronts. Cite self-driving cars & your social media apps, among other factors, says
@wjscheirer
of
@NotreDame
.
#ieeecs
#cvpr
#cvpr19
#cvpr2019
#selfdrivingcars


0
3
5
1
0
2