

Robert Lange
@RobertTLange
Followers
7,554
Following
549
Media
243
Statuses
457
Research Scientist @SakanaAILabs , PhD Student @sprekeler Meta-discovery 🧬gymnax 🏋️ evosax 🦎 MLE-Infra 🤹 Ex: Student Researcher @Google DM. Legacy DM Intern.
TKY, BLN, LDN, BCN
Joined April 2017
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#C104
• 424932 Tweets
SEBI
• 384397 Tweets
Hindenburg
• 215241 Tweets
#Number_i_RIJF2024
• 85174 Tweets
South Africans
• 80461 Tweets
#HindenbergReport
• 55846 Tweets
小倉記念
• 30895 Tweets
企業ブース
• 27299 Tweets
関屋記念
• 25190 Tweets
ギラホス
• 23786 Tweets
報徳学園
• 16677 Tweets
ヘルナンデス
• 15667 Tweets
大社高校
• 13540 Tweets
Ferhat Gedik
• 11716 Tweets
リフレーミング
• 10765 Tweets
鈴木さん
• 10217 Tweets




















Pinned Tweet

🎉 Happy to share my internship project
@GoogleDeepMind
🗼 – purely text-trained LLMs can act as evolutionary recombination operators 🦎
🧬 Our EvoLLM uses LLM backends to outperform competitive baselines. Work done w.
@alanyttian
&
@yujin_tang
🤗
📜:
5
23
169
🎄I am a big fan of
@ylecun
‘s &
@alfcnz
‘s Deep Learning course. The attention to detail is incredible and one feels the love and passion, which goes into every single course week (my favorites: 7+8 on EBMs)🤗
#feelthelearn
📜:
📽️:




8
284
1K
It's the beginning of a new month - so let's reflect on the core ideas of statistics in the last 50 years ⏳ Great weekend read by
@StatModeling
&
@avehtari
covering the core developments, their commonalities & future directions 🧑🚀
#mlcollage
[17/52]
📜:

8
312
1K
Beautiful overview of Bayesian Methods in ML by
@shakir_za
at
#MLSS2020
. Left me pondering about many things beyond Bayesian Inference. Thank you Shakir🙏
Quote of the day: “The cyclist, not the cycle, steers.“🚴♀️
🎤 P-I:
🎤 P-II:



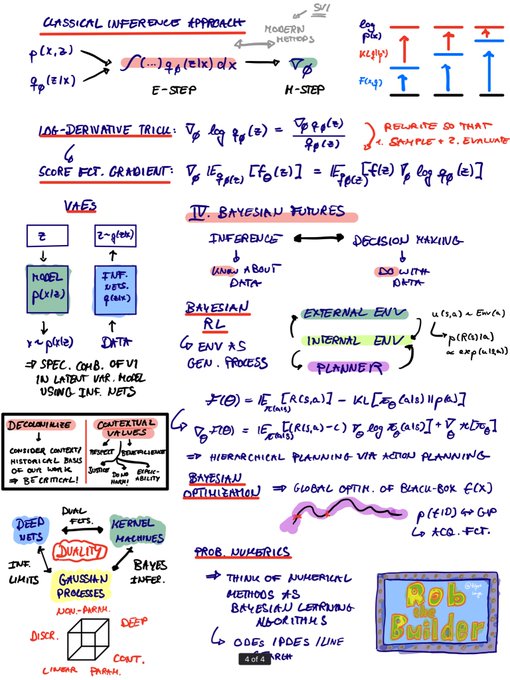
6
255
1K
Really happy to share
#visualmlnotes
✍️ a virtual gallery of sketchnotes taken at Machine Learning talks 🧠🤓🤖 which includes last weeks
#ICLR2020
. Explore, exploit & feel free to share:
💻 website:
📝 repository:
13
256
911


🤖JAX is more than just the 'next cool autodiff library'. The primitives allow us to flexibly leverage XLA and to speed-up + vectorize neuroevolution methods 🦎 with minimal engineering overhead. Find out more in my new blog post 📝:

7
133
715




🚀 I am very excited to share gymnax 🏋️ — a JAX-based library of RL environments with >20 different classic environments 🌎, which are all easily parallelizable and run on CPU/GPU/TPU.
💻[repo]:
📜[colab]:
13
105
623
There is a lot to wrap your head around in LSTMs🤯. One way of thinking that helped me a lot is the 'conveyor belt' metaphor of the cell state 🧑🏭 by
@ch402
. I put together a little animation 🖼️ Check out the amazing blog post by Chris Olah here✍️:
7
105
517
What a week 🧠🤓💻! I loved meeting so many of you at
#NeurIPS2019
- the ML community is truly wonderful. Checkout all my collected visual notes ✍️ & feel free to share:

10
126
490
The lottery ticket hypothesis 🎲 states that sparse nets can be trained given the right initialisation 🧬. Since the original paper (
@jefrankle
&
@mcarbin
) a lot has happened. Checkout my blog post for an overview of recent developments & open Qs.
✍️:
6
120
493
Want to learn more about the power of the implicit function theorem, DEQs, Neural ODEs & Diff. Optim.? Checkout the outstanding
#NeurIPS2020
tutorial by
@DavidDuvenaud
,
@DavidDuvenaud
&
@SingularMattrix
.
Checkout the docs📜, recording📽️ & JAX code👩💻:



4
56
354
Great
#NeurIPS2019
tutorial kick-off by
@EmtiyazKhan
! Showing the unifying Bayesian Principle bridging Human & Deep Learning. Variational Online Gauss-Newton (VOGN; Osawa et al., 19‘) = A Bayesian Love Story ❤️
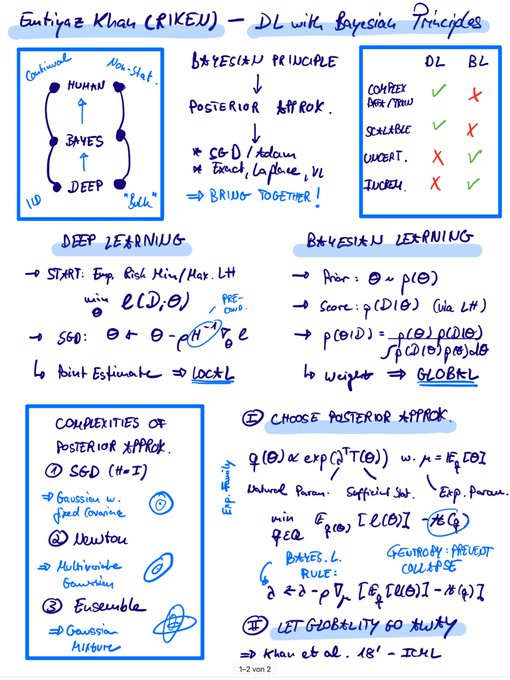

7
88
338
JAX sometimes has me feeling like a kid in a candy store 🍭 Here is a small example of how to sample batches of Ornstein-Uhlenbeck process realisations combining lax.fori_loop, jit & vmap 🚀 Auto-vectorisation made intuitive and scalable 🤗

6
44
338
🎉 Excited to share `mle-monitor` - a lightweight ML experiment protocol and tool for monitoring resource utilization 📝 It covers local machines/servers and Slurm/Grid engine clusters 📉
💻 [repo]:
📜 [colab]:
4
41
297
📈 What functions do ReLU nets 'like' to learn? 🌈 Using Fourier analysis Rahaman et al. (19') reveal their bias to learn low frequency modes first. Insights for implicit regularization & adv. robustness.
#mlcollage
[3/52]
📝:
💻:

2
59
290
🥳Really excited to be attending
#MLSS2020
. Great set of talks by
@bschoelkopf
& Stefan Bauer starting from 101 causality to Representation Learning for Disentanglement 💯! Re-watch them here:
📺 (Part I):
📺 (Part II):




1
45
282
How to train your d̶r̶a̶g̶o̶n̶ ViT? 🐉 Steiner et al. demonstrate that augmentation & regularization yield model performance comparable to training on 10x data. Many 💵-insights for practitioners.
🎨
#mlcollage
[30/52]
📜:
💻:

4
71
275
🚀 Happy to share my hyperparameter search tool: `mle-hyperopt` - a lightweight API covering many strategies with search space refinement 🪓, configuration export 📥 & storage/reloading of previous logs 🔄
💻[repo]:
📜[colab]:


3
51
262
Friday optimization revelations📉: My life needs more theoretical guarantees & convex + linear =❤️. Enlightening set of talks by
@BachFrancis
at
#MLSS2020
. Recordings can be found here:
📽️(Part I):
📽️(Part II):




1
39
259
🎉 Happy to share a mini-tool that I have been using on a daily basis: `mle-logging` - a lightweight logger 📉 for ML experiments, which makes it easy to aggregate logs across configurations & random seeds 🌱
💻 [repo]:
📜 [colab]:


6
51
246
A concise & detailed intro to Reinforcement Learning! Thank you
@katjahofmann
for this great
#NeurIPS2019
tutorial!


2
52
238
🥳 New tooling blog post coming your way 🚆 'A Machine Learning Workflow for the iPad Pro' - including my favourite apps, routines and pipelines for working with remote machines and
@Raspberry_Pi
💽👨💻.
✍️:
🤗: Thanks
@tech_crafted
for the inspiration!

7
46
219
Puuuh. What are you up to these days? 💭 I try to stay sane, clean my place 🧹& write✍️. Todays edition - 'Getting started with
#JAX
'. Learn how to embrace the 'jit-grad-vmap' powers 💻 and code your own GRU-RNN in JAX. Stay safe & home. 🤗


3
49
216
💓 N-Beats is a pure Deep Learning architecture for 1D time series forecasting 📈 provides a M3/M4/tourism SOTA by combining learned/interpretable basis functions 🧑🔬 w. residual stacking & ensembling 🎨
#mlcollage
[38/52]
📜:
💻:

2
31
214

🎉 2019 🎉 was quite the year for Deep Reinforcement Learning. In todays blog post I list my top 10 papers 🦄💻🧠 What was your favourite paper? Let me know!


2
52
207
Great start to an all-virtual
#ICLR2020
& the ‘Causal Learning for Decision Making‘ workshop including talks by
@bschoelkopf
& Lars Buesing 🧠📉👨💻. Looking forward to more smooth Q&As and exploring the awesome web interface!


2
37
195
🎉 Stoked to share that I joined
@SakanaAILabs
as a Research Scientist & founding member.
@yujin_tang
&
@hardmaru
's work has been very inspirational for my meta-evolution endeavors🤗
Exciting times ahead: I will be working on nature-inspired foundation models & evolution 🐠/🧬.

Excited to announce our seed round!
We raised $30M to develop nature-inspired AI in Japan.

64
161
1K
19
12
189
🚀 Happy to share evosax - a JAX-based library of Evolution Strategies (ES) featuring >10 different ES ranging from classics (e.g. CMA-ES, PSO) 🦎 to modern neuroevolution methods (e.g. ARS, OpenES, ClipUp)🤖
💻[repo]:
📜[colab]:

1
50
184
Awesome new JAX tutorial by DeepMind 🥳 Covering the philosophy of stateful programs 💭, JAX primitives and more advanced topics such as TPU parallelism, higher-order & per-example gradients ∇. All in all a great resource for every level of expertise🚀
👉


Check out our new JAX101 tutorial to learn about the fundamentals of JAX!
6
99
419
2
22
163
How well do scalable Bayesian methods 🚀 approximate the true model average?
@Pavel_Izmailov
et al. (21') provide insights into performance, generalization, mixing & tempering 🌡️ of Bayesian Nets ! Hamiltonian MC + 512 TPU-v3 = 💘
#mlcollage
[18/52]
📜:

0
32
158
#MLSS2020
was full of wonderful experiences 🦋 I hope to meet many of you soon & in person. Here are all
#visualmlnotes
, videos & slides:
✍️:
📼&📚:
Thank you 🙏 to all hard working volunteers & organizers - you did awesome 🤗


3
27
157
Thinking 💭about biological & artificial learning with the help of Marr‘s 3 levels of analysis. Here are the
#visualmlnotes
✍️from Peter Dayan‘s talk at
#MLSS2020
& a little pointer to a nice complementary paper by
@jhamrick
&
@shakir_za
:
👉


3
38
157
Excited to share that I got to join DeepMind as a research intern ☀️
This has been a dream 💭 which felt out of reach for a long time. Super grateful to the many people that supported me along the way 🤗
Time to do awesome work with
@flennerhag
,
@TZahavy
& the discovery team🚀

17
4
150
🚀 How similar are network representations across the layers & architectures? And how do they emerge through training?🤸New blog on Centered Kernel Alignment (
@skornblith
et al., 2019) & training All-CNN-C in JAX/flax 🤖
📝:
💻:
2
32
150
📉 GD can be biased towards finding 'easy' solutions 🐈 By following the eigenvectors of the Hessian with negative eigenvalues, Ridge Rider explores a diverse set of solutions 🎨
#mlcollage
[40]
📜:
💻:
🎬:

1
32
146
SSL joint-embedding training 🧑🤝🧑 w/o asymmetry shenanigans? 🤯 Zbontar, Jing et al. propose a simple info bottleneck objective avoiding trivial solutions. Robust to small batches + scales w. dimensionality
#mlcollage
[19/52]
📜:
💻:

2
28
145
Can artificial agents learn rapid sensory substitution? 👁️🔁👅 Tang* & Ha* introduce a Set Transformer-inspired agent which processes arbitrarily ordered/length sensory inputs 🎨
#mlcollage
[33/52]
📜:
🌐:
📺:

3
23
140
🗡️Sharpness-Aware Minimization (SAM) jointly optimizes loss value & sharpness seeking nhoods w. uniformly low loss🔍 Generalization & label noise robustness↑ 🎨
#mlcollage
[36/52]
📜:
💻 [JAX]:
💻 [PyTorch]:

1
23
140
Can NNs only learn to interpolate?
@randall_balestr
et al. argue that NNs have to extrapolate to solve high dimensional tasks🔶 Questioning the relation of extrapolation & generalization 🎨
#mlcollage
[39/52]
📜:
🎙️ [
@MLStreetTalk
]:


Epic new show out with
@ylecun
and
@randall_balestr
where we discuss their recent everything is extrapolation paper, interpolation and the curse of dimensionality, and also dig deep into Randall's work on the spline theory of deep learning.
@DoctorDuggar
@ecsquendor
@ykilcher

11
77
369
1
26
139
‘Innate everything‘ 🧠🧐🐊 -
@hardmaru
argues for the importance of finding the right inductive biases in bodies/architectures (WANNs) & prediction/world models (Observational Dropout) - Transferable Skills Workshop
#NeurIPS2019

2
24
134
🎉 Stoked to share NeuroEvoBench – a JAX-based Evolutionary Optimizer benchmark for Deep Learning 🦎/🧬
🌎 To be presented at
#NeurIPS2023
Datasets & Benchmarks with
@yujin_tang
&
@alanyttian
🌐:
📜:
🧑💻:

5
24
117
✍️Want to learn more about RL, generalization within & across tasks as well as the ‚reward is enough hypothesis‘ 🌍🔄🤖? Checkout a set of thought-provoking talks by
@matteohessel
,
@aharutyu
and David Silver at the
@M2lSchool
✌️



2
17
132
🎉 I transitioned from Berlin to the Tokyo 🗼 office for the 2nd half of my
@GoogleDeepMind
student researcher time!
🤗Deeply thankful to
@yujin_tang
for all the support leading up to & during my first days in Japan 🇯🇵Everything still feels pretty surreal & I am super grateful!




1
4
127
People of the world - I just posted a new blog post covering my
#CCN2019
experience & many keynote talks. It is fair to say - I had a truly fulfilling time 💻❤️🧠. Thank you to all organizers, volunteers & speakers (
@CogCompNeuro
). [1/2]

3
24
122
This is a live dashboard 💻 monitoring my compute resources & the status/database of ML experiments 🚀 [more about this at a later point 🤗]. It is built with rich in ca. 10 hours of procreative work.
1
14
120

👋 Come by poster 93 in this mornings
#ICLR2023
poster session to chat about our work on Learned Evolution Strategies (LES) 🦎
📝:

0
8
117
Many gems in
@OriolVinyalsML
Deep RL workshop talk at
#NeurIPS2019
on AlphaStar. Including scatter connections, imitation-based regularization, the league & the unique problem decomposition.

3
20
113
Workshop talks by Rich Sutton never fail to inspire 💭. Today’s
#ICML2020
Life-Long Learning workshop talk was no different. Exciting ideas about RL agents that learn their own questions & answers in a virtuous cycle 🔴🔄🔵 - all within the General Value Function framework.

0
21
113
Very happy to present our work "On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning“ today at the
#ICLR2021
@neverendingrl
workshop. 🎲 + 🤖🔁🌎
Paper 📜:
Poster Session 📢 [3 & 10pm CET]:
Summary 👇

3
19
108
Neural net symmetries induce geometric constraints 🔷 which imply conservation laws under ∇-flow 🧑🔬 This allows for exact prediction of training dynamics. A Noether’s theorem for NNs — great theoretical work by Kunin et al. (2020)
#mlcollage
[7/52]
📝:

1
21
109
✂️Why can we train sparse/subspace-constrained NNs? Larsen et al. derive a theory based on Gordon's Escape Theorem 🧑 → 🌔 & investigate optimized (lottery) subspaces using train data/trajectory info🎲
🎨
#mlcollage
[28/52]
📜:
💻:

0
28
105
⛩️ Gated Linear Networks (Veness et al., 19') are backprop-free & trained online + local via convex programming 🧮 GLNs combat catastrophic forgetting & the linearity allows for interpretable predictions.
#mlcollage
[15/52]
📜:
💻:

0
18
98
🎨 Beautiful comic summaries of David Silver's classic Reinforcement Learning course 🤖 by
@d4phn3c
!

0
22
97
🔎 How can one measure the emergence of interpretable concept units in CNNs?
@davidbau
et al. propose network dissection 💉 based on the agreement of filter activations and segmentation models 🎨
#mlcollage
[26/52]
📜:
💻:

0
17
90
4 challenges in lifelong learning 👶-🧑-👵: Formalism, evaluation, exploration & representation. Great start to the Lifelong ML workshop at
#ICML2020
by
@katjahofmann
,
@luisa_zintgraf
&
@contactrika
. P.S.: I have never seen such smooth multi-speaker transitions 😎

1
18
92
Nothing better than starting your day with some invertible models 🤠 Great historic review & explanations by
@laurent_dinh
at
#ICLR2020
! 🤖 Biggest personal takeaway: The power of sparse/triangular Jacobians in determinant computation 📐

0
14
86
🦎/🧬Learned Evolutionary Optimization (& Rob 😋) are going on tour! Super excited to be giving talks about our recent work on meta-discovering attention-based ES/GA & JAX during the coming days 🎙️
@AutomlSeminar
: Today 4pm CET
@ml_collective
: Tomorrow 7pm CET
Come & say hi 🤗

2
14
87
🥱Tired of tuning On-Policy DRL agents? Andrychowicz et al. trained 250k agents & evaluated hyperparams for >50 choices to make our lifes easier 🚀 providing evidence for common DRL wisdom & beyond 🪙
#mlcollage
[21/52]
📜:
💻:

0
15
85
Powerful opening
#NeurIPS2019
keynote by
@celestekidd
! Many inspirational thoughts from developmental psychology. Curiosity and intrinsic motivation in RL have a lot of work to do.

3
18
84
Can we go beyond backprop + SGD? BLUR (Sandler et al., 21') meta-learns a shared low-dimensional genome 🦎 which modulates bi-directional updates 🔁 It generalizes across tasks + FFW architectures & allows NNs to have many states 🧠
#mlcollage
[16/52]
📜:

0
16
82
A global workspace theory for coordination among neural modules in deep learning🧠🔄 🤖 Goyal et al. (21') propose a low-dim. bottleneck to facilitate synchronisation of specialists & replace costly pairwise attention interactions 🚀
#mlcollage
[11/52]
📜:

2
25
78
🤸Very excited to share evosax 🦎 release v.0.10.0 and a small paper, which covers all features and summarizes recent progress in hardware accelerated & JAX-powered evolutionary optimization!
🧑💻:
📜:
Many new features... 🧵
2
16
78
🦋 Meta-Policy Gradients ∇∇ have the power to change how we think about algorithm design 🧠. Learn more about automated online hyperparameter tuning and end-to-end RL objective discovery 🤖 in my new blog post!
📝:
1
21
75
⏰ Clockwork VAEs by Saxena et al. (21') scale temporally abstract latent dynamics models by imposing fixed clock speeds for different levels 📐 Very cool ablations that extract the level-info content and frequency adaptation 🧠
#mlcollage
[10/52]
📜:

2
11
73
Workshop talks should push conceptual limits. Fascinating talk by Rich Sutton at the Bio&Artificial RL workshop
#NeurIPS2019
#SuperDyna
P.S.: I will do my best 🧠🧐✍️


1
9
73
Tuning optimizers is a fundamental part of any DL pipeline 🚂
@robinschmidt_
*,
@frankstefansch1
* &
@PhilippHennig5
provide an empirical analysis of 1st-order optimizers across tasks, budgets & schedules 🚀
#mlcollage
[25/52]
📜:
💻:

4
9
73
Thought provoking talk by
@white_martha
on the ingredients for BETRRL at the
#ICLR2020
workshop🌏! Many interesting ideas for generalization in Meta-RL, learning objectives, restricting complex MDPs & auxiliary tasks 🚀🧐

0
13
70
How does the RL problem affect the lottery ticket phenomenon 🤖🔁🎲? In our
#ICLR2022
spotlight we contrast RL & behavioral cloning tickets, disentangle mask/initialization ticket contributions & analyse the resulting sparse task representations. 🧵👇
📝:

2
10
71
🎲Randomized autodiff reduces memory requirements of backprop by 'sketching' a sparse linearised computation graph. Check out cool work by
@denizzokt
,
@NMcgreivy
,
@jaduol1
,
@AlexBeatson
&
@ryan_p_adams
#mlcollage
[2/52]
📝:
📽️:

2
11
69
For anyone who didn't catch our (w.
@yujin_tang
&
@alanyttian
) poster presentation on the coolest neuroevolution benchmark out there -- feel free to reach out & chat 📩
Would love to discuss evosax, gymnax and the future of evolutionary methods in the LLM era 🤗
#NeurIPS23

🎉 Stoked to share NeuroEvoBench – a JAX-based Evolutionary Optimizer benchmark for Deep Learning 🦎/🧬
🌎 To be presented at
#NeurIPS2023
Datasets & Benchmarks with
@yujin_tang
&
@alanyttian
🌐:
📜:
🧑💻:
5
24
117
3
10
69
🥱 Training foundation models is so 2023 😋
🚀 Super stoked for
@SakanaAILabs
first release showing how to combine large open-source models in weight and data flow space!
All powered by evolutionary optimization 🦎
Introducing Evolutionary Model Merge: A new approach bringing us closer to automating foundation model development. We use evolution to find great ways of combining open-source models, building new powerful foundation models with user-specified abilities!
55
423
2K
3
6
68
🧙 What are representational differences between Vision Transformers & CNNs?
@maithra_raghu
et al. investigate the role of self-attention & skip connections in aggregation & propagation of global info 🔎
🎨
#mlcollage
[32/52]
📜:

1
5
63
Trying something new 🎉 - One slide mini-collage of my personal 'paper of the week' 📜
1/52: VQ-VAEs had quite the week in ML 🥑+🪑=🦋 But how do β-VAEs relate to the visual ventral stream?
Checkout Higgins et al. (2020) to find out 👉

0
15
66
❓How to efficiently estimate unbiased ∇ in unrolled optimization problems (e.g. hyperparameter tuning, learned optimizers)?🦎 Persistent ES does so by accumulating & applying correction terms for a series of truncated unrolls. 🎨
#mlcollage
[35/52]
📜:

1
9
66
Distilling teacher predictions 🧑🏫 from unlabelled examples provides an elegant approach to transfer task-specific knowledge 🧠 SimCLR-v2 effectively combines unsupervised pretraining, tuning & distillation
#mlcollage
[23/52]
📜:
💻:

2
13
66
🥳I had a great day at the
#NeurIPS2020
Meta-Learning workshop 🎤 which included listening to
@FrankRHutter
,
@luisa_zintgraf
&
@LouisKirschAI
. Checkout many more fantastic talks & the panel! Thanks to the organizers 🤗
🖥:
🎥:



1
8
64
Synthetic ∇s hold the promise of decoupling neural modules 🔵🔄🔴 for large-scale distributed training based on local info. But what are underlying mechanisms & theoretical guarantees? Check out Czarnecki et al. (2017) to find out.
#mlcollage
[5/52]
📝:

2
10
60
🎉 Excited to share `mle-hyperopt` v0.0.5 - a lightweight hyperparameter optimization tool, which now also features implementations of Successive Halving 🪓, Hyperband 🎸 & Population-Based Training 🦎
📂 Repo:
📜 Colab:


3
15
61
What is the right framework to study generalization in neural nets? 🧠🔄🤖
@PreetumNakkiran
et al. (21') study the gap between models trained to minimize the empirical & population loss 📉 Providing a new 🔍 for studying DL phenomena
#mlcollage
[13/52]
📜:

0
8
62




🧬 Evolution is the ultimate discovery process & its biological instantiation is the only proof of an open-ended process that has led to diverse intelligence!
One of my deepest beliefs: A scalable evolutionary computation analogue will open up many new powerful perspectives 🧑🔬


@sarahcat21
When evolutionary computation and population based training didn't take off as much as they should have.
1
0
10
1
10
61
🎙️Stocked to present evosax tomorrow at
@PyConDE
It has been quite the journey since my 1st blog on CMA-ES 🦎 and I have never been as stoked about the future of evo optim. 🚀
Slides 📜:
Code 🤖:
Event 📅:

2
11
60
Can memory-based meta-learning not only learn adaptive strategies 💭 but also hard-code innate behavior🦎? In our
#AAAI2022
paper
@sprekeler
& I investigate how lifetime, task complexity & uncertainty shape meta-learned amortized Bayesian inference.
📝:

2
10
57
Can generative trajectory models replace offline RL 🦾algorithms? Decision Transformers autoregressively generate actions based on trajectory context & a desired return-to-go 🎨
#mlcollage
[34/52]
📜:
📺:
🤖:

2
14
52
What drives hippocampus-neocortical interactions in memory consolidation?
@SaxeLab
argues for a top-down perspective & the predictability of the environment. 🧠🤓🌎


0
6
52
🚂 Looking for a tool to manage your training runs locally, on Slurm/Grid Engine clusters, SSH servers or GCP VMs? `mle-scheduler` provides a lightweight API to launch & monitor job queues on all of these 🚀
💻 [repo]:
📜 [colab]:

1
13
49
How can we create training distributions rich enough to yield powerful policies for 🦾 manipulation? OpenAI et al. (21') scale asymmetric self-play to achieve 0-shot generalisation to unseen objects 🧊🍴.
#mlcollage
[14/52]
📜:
💻:

0
10
52
😈 Adversarial robustness of CNNs correlates with their V1 🧠 response predictivity & can be improved by attaching a fixed-weight bio-constrained Gabor Filter-style model w. stochasticity as front-end 🚀
#mlcollage
[22/52]
📜:
💻:

2
9
49
I had a great time placing 5th in the Algonauts Mini-Track Challenge🎉 using SimCLR-v2 features to predict neural responses to videos 📺 → 🧠 Come & say hi next Tue at the
@CogCompNeuro
WS 📢 talks
👉
📝
🤖

2
8
47
How to combine CNNs & Vision Transformers ❓
@stephanedascoli
et al. propose ConViT - a self-attention-based architecture w. conv init & freedom to escape locality 🚀 Improves sample & param efficiency
🎨
#mlcollage
[27/52]
📜:
💻:

1
9
47
🤖 How can we learn useful temporal abstractions that transfer across tasks? Veeriah et al. (21') propose to discover options by optimizing their parametrization via meta-∇ 🧠 Loved the idea to disentangle option reward & policy.
#mlcollage
[9/52]
📜:

1
12
44
Looking for a new dinner conversation🥘?
@KonstDaskalakis
got you covered - How about the beauty of directed parity & Sperner‘s lemma in proving Brouwer‘s fixed point theorem? 👀
#MLSS2020
video recordings:
📽️ - I:
📽️ - II:



0
5
44
Big shout out to
@TedPetrou
🤗 and the wonderful jupyter_to_medium package, which allowed me to export-import my notebook to medium within less than 2 minutes. Simply dope - saved me hours of my life! Can I buy you a coffee?
#opensource
Check it out:


1
15
44
🎉 Meta-evolved RL algorithms just became temporally aware 🤯 Phenomenal work led by
@JacksonMattT
&
@_chris_lu_
! Happy to have been a small part of the team 🤗

How can we meta-learn new RL algorithms that vastly outperform PPO and its variants? In our ICLR 2024 paper, we find that *temporally-aware* algorithms unlock performance gains, significantly beating PPO on unseen tasks!
work co-led with
@JacksonMattT
at
@whi_rl
@FLAIR_Ox
2
21
149
1
5
45
💊 Canonical capsules (Sun et al., 2020) solve the need for pre-alignment in 3⃣D point cloud tasks via a k-part capsule decomposition with attention. The representations can be used for auto-encoding, registration & classification.
#mlcollage
[6/52]
🧑💻:

0
10
43