

muhtasham
@Muhtasham9
Followers
1,359
Following
849
Media
232
Statuses
1,628
In my pre-training years
Latent Space
Joined March 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Chan
• 301874 Tweets
Messi
• 224087 Tweets
SURPRISE FROM BECKY
• 171399 Tweets
Kalafina
• 131276 Tweets
ROADRIDER X LINEMAN
• 97725 Tweets
#नवरात्रि
• 44443 Tweets
BABYBOSS YINYIN DAY
• 42729 Tweets
#Navratri2024
• 37684 Tweets
A. Luxury
• 32846 Tweets
梶浦さん
• 29569 Tweets
Maa Durga
• 28408 Tweets
#もうすぐ三角チョコパイの季節
• 27389 Tweets
マナー講師
• 22738 Tweets
渋沢栄一
• 22719 Tweets
マナー違反
• 20251 Tweets
梶浦由記
• 16422 Tweets
शक्ति उपासना
• 16342 Tweets
おーちゃん
• 14159 Tweets
WIN AMAZING EMBASSY
• 11644 Tweets
जगत जननी
• 10032 Tweets






















A short thread about changes in the transformer architecture since 2017.
Reading articles about LLMs, you can see phrases like “we use a standard transformer architecture.”
But what does "standard" mean, and have there been changes since the original article?
(1/6)

Interestingly despite the 5 years(!) of hyper-growth of NLP space, Vanilla Transformer is holding to the Lindy Effects which is the idea that the older something is, the longer it's likely to be around in the future.
0
2
13
7
138
887
Evaluating abstractive summarization remains an open area for further improvement. If you ever dealt with large-scale summarisation evaluation you know how tedious it is.
Inspired by
@eugeneyan
's post on this topic, I hacked something together over the weekend to streamline this

9
33
261
Excited to announce the most up-to-date and CPU friendly BERT, trained on most recent snapshot of internet. Took a day and 8x A100s to train. 🤗
The model is open-source an I hope the community can benefit from it. It was created…
1
41
238
Meta: Multi-tasking while reading about Multi-task NLP models

3
10
130
DeepMind folks can now steal weights behind APIs
“We also recover the exact hidden dimension size of the gpt-3.5-turbo model, and estimate it would cost under $2,000 in queries to recover the entire projection matrix.”
who wants to do same for gpt4?

7
5
79
@_jasonwei
@arankomatsuzaki
Might contain a lot of subtle issues, see clever Hans effect, which is always hard to debug. The law of leaky abstractions in action as my supervisor says

2
5
71
🇺🇸US: Innovate then try to regulate
🇪🇺EU: Regulate then try to innovate
5
17
60
1
2
65
🇺🇸US: Innovate then try to regulate
🇪🇺EU: Regulate then try to innovate
5
17
60
The 🤗 MLX community is amazing
Quantized StarCoder2 model variants available here:
Small guide on running and training StarCoder2 locally
pip install -U mlx-lm
To run inference on quantized model
python -m mlx_lm.generate --model


Introducing: StarCoder2 and The Stack v2 ⭐️
StarCoder2 is trained with a 16k token context and repo-level information for 4T+ tokens. All built on The Stack v2 - the largest code dataset with 900B+ tokens.
All code, data and models are fully open!

13
192
675
2
13
56
Happy to show Pod-Helper:
⚡️ Lightning-speed transcription with Whisper
🔧 Built-in audio repair with good old Roberta
🧊 Checks your content's vibe effortlessly
See demo below running on TensorRT-LLM
#GenAIonRTX
#DevContest
#GTC24
@NVIDIAAIDev
2
4
35
If you missed out on the
@full_stack_dl
LLM bootcamp, don't worry! I've written a blog post about it.
I hope you find my post informative and enjoyable to read, just as I enjoyed attending the bootcamp.
0
10
33
🚀Now supports real-time streaming
Happy to show Pod-Helper:
⚡️ Lightning-speed transcription with Whisper
🔧 Built-in audio repair with good old Roberta
🧊 Checks your content's vibe effortlessly
See demo below running on TensorRT-LLM
#GenAIonRTX
#DevContest
#GTC24
@NVIDIAAIDev
2
4
35
2
7
31
Let's see how different LM's multiply matrices / think 💭
using this Space
GPT-J-6B i see what you did there👀
Built using amazing
@Gradio
Blocks 🧱 APIs,
also you can use new
@huggingface
🤗 Community Tab to make suggestions and collaborate
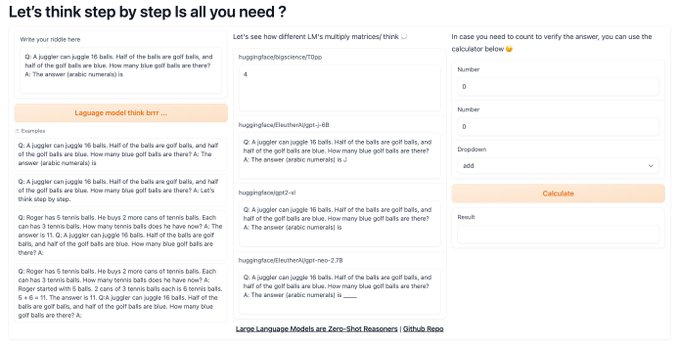

Large Language Models are Zero-Shot Reasoners
Simply adding “Let’s think step by step” before each answer increases the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with GPT-3.

59
566
2K
2
11
28

Using the example of the language model (i.e. decoder-only) LLaMa-2, let’s look at the main major architectural improvements for LLM:
— Post LayerNorm → Pre LayerNorm (). This makes the convergence more stable. Now the process goes in such a way that the

1
0
27
📢 Just published: How traditional OS concepts like Branch Prediction & Virtual Memory Paging shape today's Large Language Models (
#LLMs
).
LLMs = CPUs of early computing?
Feedback welcome!
🔗
0
3
28
— Absolute position embedding → RoPE (). The method itself is that we rotate the token embeddings by an angle depending on the position. And it works well. In addition, the method opened up a number of modifications to expand the context to very large

1
0
23
Your car gathers a shocking amount of data about you, which you don’t get to see, and the manufacturer sells that to third parties, who use it in ways that are counter to your interests.

0
19
28
"Flops are cheap, bandwidth is adding more pins, and latency is physics. Deal with it. "
1
6
23
@alex_valaitis
@MosaicML
Was going to skip but, not correct!
@MosaicML
is not open source LLM startup, its platform, and don’t sleep on them yet, they just released this today, 2x context length of LLAMA!

1
2
24
— ReLU activation → SwiGLU (). Gated Linear Units (a family of methods to which SwiGLU belongs. It adds the operation of element-wise multiplication of matrices, one of which has passed through the sigmoid and thus controls the intensity of the signal
1
0
21
When your model is training and you see live footage of forward and back prop via
@weights_biases
0
4
21

Attention modifications (), for example, using one K-V pair of matrices per group of Q matrices at once. This improvement mainly already affects the optimization of inference. But there are also a huge number of methods aimed at reducing the quadratic

2
2
19
Except it’s called AI engineering now
Come to
@aiDotEngineer
conf to learn more

2013 — 2023: you were hired to do machine learning but do data engineering
2023 — : you were hired to do machine learning but do web dev
20
35
762
3
2
21


All started with GPT2 moment, but only last week trained internal model and it did good, but fine-tuning made 50% better.
@amasad

1
3
17


MLX weights below

Happy to share the latest Zephyr recipe based on
@Google
's Gemma 7B 🔷🔶!
Outperforms Gemma 7B Instruct on MT Bench & AGIEval, showing the potential of RLAIF to align this series of base models 💪
🧑🍳 I hope this recipe enables the community to create many more fine-tunes!

3
40
162
0
3
14
LayerNorm → RMSNorm (). RMSNorm is computationally simpler, but works with the same quality.
(5/6)
1
0
15
“The thing that determines whether you’re the product isn’t whether you’re paying for the product: it’s whether market power and regulatory forbearance allow the company to get away with selling you.” —
@doctorow
1
9
14


@swyx
Shameless plug but this would make it easier to compare
Evaluating abstractive summarization remains an open area for further improvement. If you ever dealt with large-scale summarisation evaluation you know how tedious it is.
Inspired by
@eugeneyan
's post on this topic, I hacked something together over the weekend to streamline this
9
33
261
1
0
12
machine learning is low-precision linear algebra
during developing TPU google cut down mantissa from 23 bits to 5 bits and invented bf16
fast forward now we have 1.58 bit LLMs

Huh, I missed this earlier this month: Microsoft Research used a similar trick for their "1.58-bit" LLM BitNet
4
2
40
0
0
11
Interestingly despite the 5 years(!) of hyper-growth of NLP space, Vanilla Transformer is holding to the Lindy Effects which is the idea that the older something is, the longer it's likely to be around in the future.
0
2
13


Top recommendation:
Beautifully written in-depth explanation of this concepts, which I failed to do in my initial blog
High quality tokens, future LLMs can boost their reasoning and get sense of humor from
@charles_irl
if this blog ends up in their dataset

PagedAttention, Virtual Context, Speculative Decoding, Register Tokens: the last year has seen many ideas from systems programming applied to LLMs.
Not many folks live in that intersection, so I wrote an explainer post to make them a bit more accessible!



18
286
1K
1
3
10


PSA if you need GPUs for your research
Hit this companies up they have compute grants
@PrimeIntellect
@dstackai
@fal
@fal
especially if you work on diffusion models

Does your *university* nlp/vision/ml lab have more or less than 64 A100 and 100+ other GPUs?
22
3
32
0
2
11
It´s here

Accelerate your coding tasks, from code completion to code summarization with StarCoder2, the latest state-of-the-art, open code
#LLM
built by
@HuggingFace
,
@ServiceNow
, and NVIDIA.
Learn more 👉
1
36
126
1
0
10

Reminder: Join amazing Transformers lecture by
@giffmana
tomorrow

🥨NEW EVENT🥨
Transformers in all glory details:
@GoogleAI
Brain Team Scientist Lucas Beyer
@giffmana
will explain the currently most dominant deep learning architecture for natural language processing in an exclusive event with
@MunichNlp
.
Details below👇

1
3
11
0
4
9


Sharing
@huggingface
collection of old models from RoBERTa all the way to GPT2 pre-trained and finetuned on Tajik language, stay tuned for more to come, mistral-7b, llama2-7b, and others on the way

1
0
9

"Flops are cheap, bandwidth is adding more pins, and latency is physics. Deal with it."

@vrushankdes
Great read! My experience is that you’re fighting physics but also the nvidia compiler and the stack overall, and even after pulling *a lot* of tricks we still can’t achieve more than ~80-90% mem bw on many kernels that you’d naively think should be ~100. And the rabbit hole
2
1
39
0
1
10

Great tune! Smooth run on m2 8gb
python -m mlx_lm.generate --model mlx-community/OpenCodeInterpreter-SC2-3B-4bit --prompt "Write a quick sort in C++" --temp 0.0 --colorize

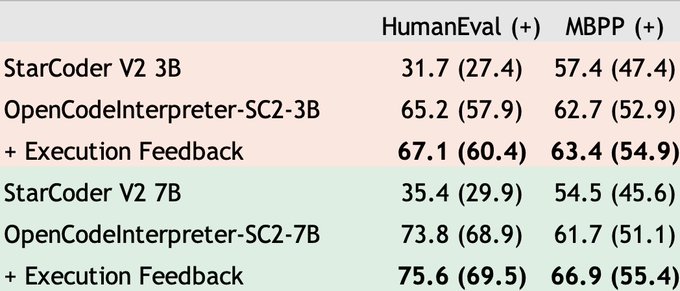
🌟 Big thanks for making StarCoder 2 open-source! 🚀 We've swiftly finetuned it on our Code-Feedback instruction dataset, the dataset behind OpenCodeInterpreter. 📈 HumanEval Scores are boosted ~30%.
3B Model: from 31.7 to 67.1!
7B Model: from 35.4 to 75.6!
🛠️ CodeFeedback has
42
64
264
0
3
9



Patterns from CIDR database conference:
Stanford - turns out databases are actually LLMs and every problem is an ML problem.
Berkeley - let me solve some NP hardish algorithmic problem using LP and other techniques that might find application 50 years later.
CMU - let me
0
2
8
💫StarCoder which was released today by
@BigCodeProject
is prime example of Open Source outcompeting
Big shot out to
@lvwerra
@harmdevries77
@Thom_Wolf
@huggingface
@ServiceNowRSRCH

Google "We Have No Moat, And Neither Does OpenAI"
Leaked Internal Google Document Claims Open Source AI Will Outcompete Google and OpenAI
This is the opinion of one Googler, we do not agree, simply sharing.
$GOOGL $MSFT $META $AI $NVDA $AMZN $AAPL
31
122
685
0
0
8
Image and prompt by yours truly
@marksaroufim
teaching style is like a casual conversation with a senior engineer on your team

CUDA-MODE 8: CUDA performance gotchas
How to maximize occupancy, coalesce memory accesses, minimize control divergence? Sequel to lecture 1, focus on profiling.
Speaker:
@marksaroufim
(today in ~45 mins)
Sat, Mar 2, 20:00 UTC

1
20
105
1
1
7

Super model
MLX weights below


Release phi-2-super. Fine tuned over phi-2 and aligned with cDPO. MT-bench of 7.1875, surpassing many larger models. Humaneval score 60.98%, Humaneval-Plus 54.88%

45
60
554
0
2
7

“LLMs are not database, they are not up to date, think of them as are reasoning engine and some sort of retrievers will solve the the issue of up do date knowledge”
@sama

0
0
2



0
4
8


Beating OpenAI large v2 with Fine-tuned *medium* model from 85.8 WER down to 23.1 WER
special thanks to
@LambdaAPI
and
@huggingface
team especially
@sanchitgandhi99
and
@reach_vb
0
0
8




TIL:
@lexfridman
hails from Buston, Tajikistan 🇹🇯
When our paths cross, I'll be ready with a friendly, "What's up, homie?"
1
1
6


0
0
2
1
0
7
Thanks
@dk21
and
@jefrankle
for this amazing session, can’t wait for upcoming sessions

We are LIVE🎉
Tune in for Lesson 3 of the Training & Fine-Tuning LLMs Course with
@MosaicML
📚
You will learn data scaling laws to construct custom datasets, & dive deep into data curation, ethics, storage, & streaming best practices.
Stream now🔗
0
2
6
0
1
7

Germany is probably the only country you get invited to dinner by VC and the day after get asked to paypal the amount, or probably recession hitting hard on everyone
1
0
6
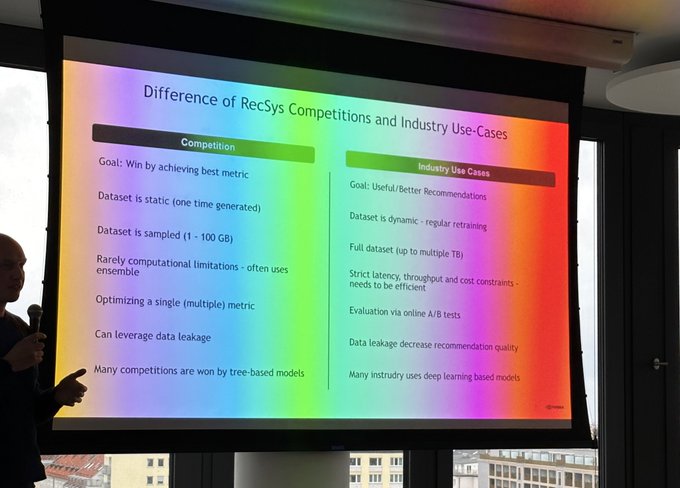
Benedikt sharing the learnings from 5 data science competitions for recommender systems he did over the last 3 years.
0
0
6
With the swarm of users experimenting
@bing
Chat aka Sydney. I feel similar vibes like that of “OMG LaMDA is sentient guy”. Again many things can be said but before folks start posting terminator images let me leave this here …

1
1
7
