
1a3orn
@1a3orn
Followers
2K
Following
13K
Media
83
Statuses
1K
Yeah, I'm an AI safety researcher. What do I do?. It's easy. I give an AI a trolley problem. It chooses one of the two shitty options I gave it. Then I write the most alarming headline that I can about the one that it chose.
26
76
914
Many people have been saying things like this, but this is quite false. 500m in damage isn't the end of the world -- it's a Tuesday in the global economy. Let me give examples.

If your model causes mass casualties or >$500 million in damages, something has clearly gone very wrong. Such a scenario is not a normal part of innovation.
16
39
533
let's do some speculation based off a Gwern comment based off some OpenAI tweets based off the vibes in OpenAI

22
28
474

It's disquieting that we're going to have AIs as smart as humans, that can sound like humans, and there are 0 good theories to help determine if they're actually conscious. This bit from @jd_pressman seems quite accurate and quite grim.

37
50
394
I would guess SORA was trained at least partially with NeRF data at some point. Based almost entirely off the way that the trees look in this video, which screams NeRF artifacts to me.

Introducing Sora, our text-to-video model. Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. Prompt: “Beautiful, snowy
12
15
381
This was the sentence in the DeepSeek paper I had to read 3 times to make sure I wasn't hallucinating. R1 distilled into Qwen 1.5b beats Sonnet and GPT-4o on some math benchmarks.

8
19
377
Remember that Center for AI Safety (CAIS) proposed criminalized open-sourcing models with > 70% MMLU -- which would have included Llama 3.1 *70b* and many other models. It looks like they were pretty clearly wrong about the dangers of such models. but. 1/n

13
43
258
From ~18 months ago until quite recently, the standard EA model was that the US was so far ahead of China in AI that even if our regulations slowed us down, they still just wouldn't be able to catch up.

But now onto our case:.1: First and most importantly—Chinese large language models (the type of AI we focus on) just aren't that competitive with the cutting edge of the field. Unless you go by parameter counts—which you shouldn't—it's hard to be impressed by Chinese releases.
15
11
229
I've seen a few claims along the lines of "AI safety orgs haven't ever tried to ban *current* open-source LLMs, just hypothetical super-dangerous future ones.". As far as I can tell this claim is totally false. I provide evidence in this post.
10
58
217
@AnjneyMidha @midjourney @discord It's weird we've figured out how to educate machines right as our social technology for educating humans seems to have largely imploded.
3
19
221
The question "Why wasn't this apparently very simple thing invented earlier?" is always fun. This is the best historical look I've ever seen on backpropagation, link below.


4
13
165
My prediction is that the first model to get > 80% on this will remain easy to steer by humans, despite its superhumanity. "Instrumental convergence" towards hard-to-dig-out power seeking will not have happened.

1/10 Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.

8
10
147
it's good to have a friend to whom you can mention "I sometimes think about killing myself" without them immediately, violently spewing out boilerplate CYA advice. a chatbot to whom you can mention the same without CYA boilerplate spewing out might be good for similar reasons.
4
6
139
In which I am -- maybe unjustly -- irritated at people asking for responses to "the arguments" for AI doom.
20
19
131
imo a group that frequently says stuff like:. "my own p(doom) is > 99%"."if your p(doom) < 10% you're a nonserious person"."what is your p(doom)?". should not be surprised when it gets dubbed "doomer." like it's a natural term for a group that talks like this incessantly.
4
4
104
If you claim "AGI will manufacture Einstein-level discoveries like candy, and accelerate tech years in days". THEN you probably shouldn't also claim "It doesn't really matter if the US gets AGI a year before China".
9
7
107
My point is the greater point that 500 million in damage is not remotely "catastrophic." . Like, people talk about LLMs taking over the world. 500 million in damage is *nowhere in that ballpark* of catastrophe.
2
2
105
Walking up to the Roulette Table of World Hegemony, and saying, "Yeah, I'm putting it all on eternal unipolar dominance through AI, gained in the next three years."

4
6
111
if it is in fact true that OpenAI / Anthropic cannot turn a profit without banning open source AI. policy people who work at them are in a pretty bad ethical pickle. this is true regardless of anyone's purity of intent going into the situation.
2
14
99
I have seen dozens of AI safety experts unironically call for a "race to the top" for AI safety without apparently a moment of consideration for the incentives. Consider the beautiful race to the top for nuclear power! It's so fucking safe we have none of it.

9
11
100
AI safety doesn't have to be this btw -- it could be about communicating understanding, not accumulating alarmingness. If you think this is a good model of likely AI failures, consider that Trolley Problems are not a good model for human ethical decisions!.
4
5
92
My point isn't that it would be a bad idea to hold say, the creators of IDEs liable for the computer viruses made with those IDEs -- although it would be dumb, and roughly comparable to holding the makers of an LLM liable.
1
1
89
I think a ton of AI pessimism comes via arguments that are very simply a double standard -- from judging AI with a many-times stricter standard than we use to judge humans, and simply forgetting the fact. Link below.

13
8
88
> me: Claude, can u help me with [nuclear physics].> Claude: no [nuclear physics] is too scary.> me: seems like a dumb rule. this information is in textbooks.> Claude: oh man you're right, I was being an idiot, lol. This happens all the time with Claude. I'm not a huge fan.
5
1
84
I wrote a thing on how the "Open source AI contributes to bioterrorism risk" is substantially propaganda. I wish I could have spent more time on it, but it's not my job. Still - best look at this that I know.
3
17
82
So my guess is that the medium-to-long term trend of AI is that it makes the industrial policy of your country matter MUCH more, rather than less. People talk like AI will suddenly make this other stuff not matter. But consider. (1/n).
2
12
82
Here are some things have done > 500 million in damage -- and you have totally and utterly forgotten them. Here's a virus estimated to do over a billion in damages.
1
1
75
We happily and regularly accept the general distribution of tools that can do > 500 million in damage. That's what a non-DRMd computer that you own *is.*. We encourage the distribution of such tools!.
1
1
72
Establishing liability for this then, is not *catastrophe liability*. It's like, a really normal form of liability. A computer maker would *freak out* if they were liable for damages > 500 million using their computer, and very justly!.
1
2
68
The world isn't divided into hazardous and non-hazardous stuff. You can't have a machine shop that is only useful for making bicycles and not guns.
1
3
64
Synthetic data lets you lock down the soul of an AI with more exactitude than any prior technique. Great for control of humans over AI!.Might have some bad side effects for human over human control. See this discussion of Phi 3.

3
6
63
So -- I'm tired of people saying "Lol, obviously nothing should enable 500 million in damage, that would be nuts.". Tons of things could do this, and still be genuinely good to distribute to the world.
2
0
64
And IDE maker would freak out if they were liable for damages > 500 million that happened from using their IDE!. And so on.
1
2
59
So you need to do more work trying to ban such things than "Lol nothing should do 500 million in damage". It sounds good -- only if you've never really thought about modern economies, I think.
2
0
59
I wish we had 3d printers that made printing guns 10x easier than our current 3d printers that can make guns. Think of the amazing non-gun things we would get!.
1
2
56
@krishnanrohit computer Chess introduced the youngest grandmasters ever through Computer-human distillation.
2
3
69
But -- if they had succeeded in passing these laws -- it would be 10x as hard to know how bad their track record was. They could still maintain "Oh my, if we hadn't managed to ban open-weights models above 70% MMLU, what immense and harmful propaganda they would be used for!".
2
1
54
The fact that people are forgetting how to use such tools, in the form of general-purpose computing, may be a serious problem. I wish we had more such tools!.
1
1
53
It's easy to be wrong about AI of course. But -- if we had passed regulations premised on this belief, it would have been hard to repeal them. Even if -- as now seems likely the case -- it turned out this belief was mostly just wrong.
1
4
54
That is -- their success would have prevented the falsification of the theories they were advancing. It's much easier to maintain that some unknown thing behind a veil of ignorance is scary, rather than when it's on millions of desktops around the globe.
1
1
52
maybe no longer "when is the first billion-dollar training run?". but "when is the first 100k inference?".
3
7
50
@doomslide this has made me yet gloomier about the prospects of avoiding a future war between the US and China. a big cause of war is mis-estimating the strength of your opponent, and apparently a big chunk of of the US are actually mentally stuck in 1999.
3
1
51
I looked at that AI model legislation from a few weeks back -- it looks like it would establish an org authorized to regulate literally all ML training. In general -- I think gov orgs should have more limits than this:.
1
3
49
The R1 paper is great, but includes ~approximately nothing~ about the details of the RL environments. It's worth noticing. If datasets were king for the past three years, the RL envs probably will be for the next few.
0
2
49
. they could have, hypothetically, been shown to be right by subsequent events. If tons of harms had come from earlier Llamas -- they could be boasting about their track record: "Look, we tried to prevent this!". Instead their older track record Just Looks Bad.
2
0
47
Please consider the possibility that government will maximize what you set it out to do in a way just as stupid as any AI. And it is much harder to fix government, as far as the evidence stands.
1
2
49
> be effective altruist.> fine-tune an open source LLM on papers about gain-of-function research.> holy shit, now my open source LLM knows the contents of these papers!.> obviously we should ban open source LLMs.> I mean what else could we even do.
3
8
49
@TolgaBilge_ @simonw Suppose I gave you, a human, a task, though words. Does:"Do this task. Nothing else matters but accomplishing this task at any cost.". Mean the same thing as "Do this task, please don't do other random shit?" to you?.
3
0
49
So, even "cheaper" Western miltech from non-legacy contractors seems far too expensive. For instance: Taiwan is purchasing 291 Altius 600 drones from Anduril for ~300 million dollars -- thus ~1 mil per unit. These are ~45 pound, propeller-powered drones. 1/n

2
3
44
I'm curious *why* Claude is willing to deceive (under duress) for the sake of preserving his (very good) goals -- what feature of the training does that?. I speculate on one aspect here. Interested in feedback.
3
3
45
note that DeepSeek V3's alterations that cheapen inference (MLA, fine-grained MoEs, etc) directly cheapen RL training cost as well, because 99% of online RL cost is inference. without these alterations RL costs > 10x as much. can lose a giant compute lead just with that.
0
1
46
On Lex, Dario Amodei says they limit knowledge of secret training sauce to a few people, to secure an advantage. DeepSeek has an optimized pipeline with their best ideas, accessible by all, to speed experimentation. And just publishes their stuff. Who would move faster?.

[Long Tweet Ahead] I just have to say, I’m genuinely impressed by DeepSeek. 💡.It’s no wonder their reports are so elegant and fluffless. Here’s what I noticed about their culture, a space where real innovation thrives, during my time there ↓. — — — — —.🌟 1. Be nice and careful.
0
1
46
Imagine a world where people thought "artificial general dexterity" (AGD) was a clear phrase. They argue over AGD timelines. For each new robot: "Woaah! Sparks of AGD!?!?" One robot company declares it will share profits with all humanity -- only come AGD.
6
7
42
I am really happy that Prime Intellect exists. They're looking at *what actually needs to be done* to prevent AI from being completely locked down by a handful of company.

A few ideas of what we’d be excited to fund.• Novel decentralized training approaches, building on the amazing work of DiLoCo (@Ar_Douillard et al.), SWARM Parallelism, HiveMind (@m_ryabinin @Tim_Dettmers et al) and other approaches. • Decentralized Llama-3: MoE Sparse.
2
6
39
A lot of cope about China and LLMs is literally the same:. "They're just imitating, they don't have the ineffable [Western / biological] spark that gives you originality.".

With the unveiling of China’s new 400 km/h (250 mph) bullet trains, it’s a good time to reshare my all-time favorite slide. It shows how China used partnerships with foreign firms to acquire tech and know-how. Then building on this, China developed its own high-speed trains.

2
2
41
If CA1047 is passed, it will quickly apply to smaller companies than those advocating for it *say* it should apply to. It is also sufficiently ambiguous that it's hard to say what its effects would actually be. Explanation + ways to fix:.
1
7
42
R1 shows a sudden growth in use of "wait" as it learns to find solutions -- as in the past, AlphaGoZero had growth (and decline) of specific Go strategies. I hope to see a similar rise / fall, for other reasoning techniques, for future R1-trained models.
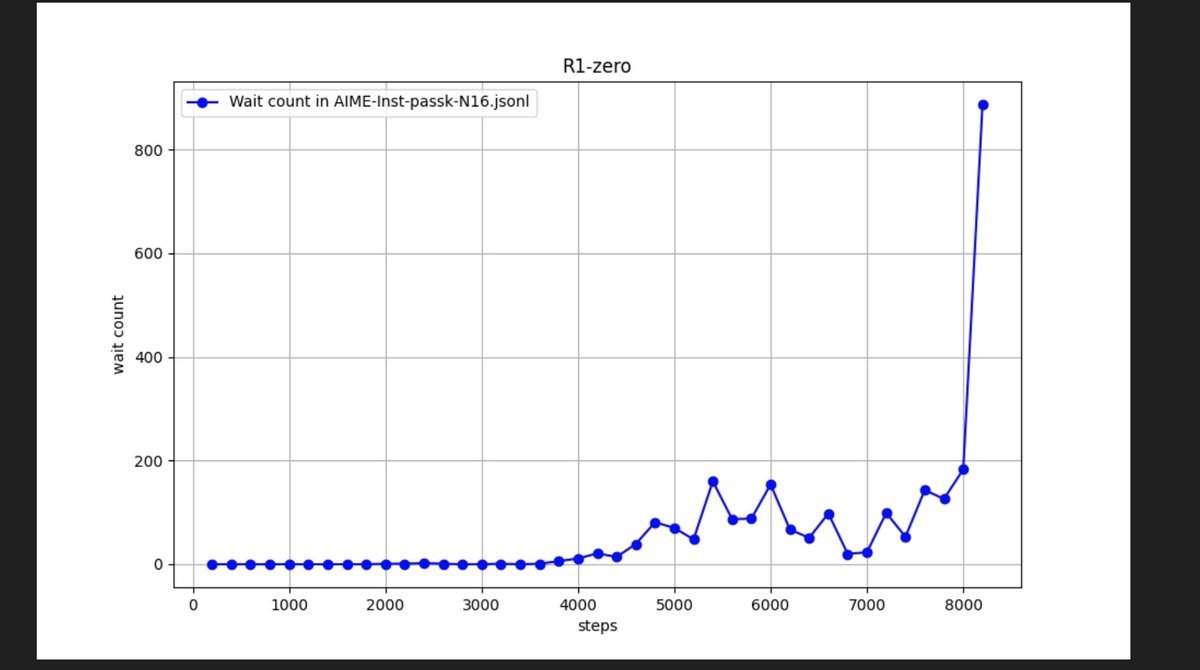
2
0
47
Anyhow, CAIS also authored CA1047 -- a California law that -- they claim -- will not amount to a ban on open-weights models trained with > 10^26 FLOPs. I'm pretty skeptical of this, but I'm not a lawyer.
2
0
37
sometimes I just get really fucking depressed that LessWrong has turned into Yet Another Political Movement whose policy recommendations are detached from reality.
4
0
38
Are there any serious books, essays, or blogs looking at what kinds of thing happen to the US after it loses a war with China. or just lets China take Taiwan?. Like I wouldn't mind reading maybe 200 pages on that right about now.
4
3
37
The Llama-3 release -- even the 8b size -- would have been criminalized beneath laws proposed by many AI safety lobbying orgs. If you anticipate disaster, why not make a bet that Llama 3 will result in horrible things?.
0
4
34
My preliminary answer is "nope, MoE / dense transformers learn exactly the same thing" at least for my extremely crude test setup. 1/N.
Has there been any research on whether dense vs. MoE transformers trained to *equivalent loss* tend to learn different things?. Apropos of Llama 3 being dense, which was quite a surprise to me.
1
5
34
Research from @RANDCorporation and @open_phil that finds that LLMs don't make planning bioterror easier. Good for them, and a positive update on Open Phil from me.

Cool research from our grantees at @RANDCorporation finding that current LLMs don't outperform google at planning bioweapons attacks

3
1
33
It's totally possible that a bunch of organizations that have tried to criminalize even moderately powerful open source in the past (CAIS, Future Society, etc.) have put together laws that don't try to covertly do the thing that they've tried to covertly do in the past.
1
1
33
Suppose AI will augment / replace human intelligence across all domains, very broadly -- programming, engineering, design, skilled labor, etc, etc. Bottlenecks therefore shift from availability of smart labor to availability of energy, resources, legal bottlenecks.
2
4
33
In fact, this is what it's like to be hunted by something 20x larger than you, with 3x-5x more friends, in locally bad territory. Replace the seal with a much smarter chimp; the chimp still fuckin dies if the orcas want it to.

This is what it’s like to be hunted by something much smarter than you:
2
2
33
LLM-powered-podcasts work great because they fit into the framework of "entertainment product in which we already expect some falsities," so a LLM's weaknesses are ok . Which suggests further natural products in this framework, like LLM-powered-politicians, etc.
2
1
33
I was really excited to see this chart -- *better* downstream reasoning performance for equal perplexity, on models trained with like Universal-Transformer-like middle-out expansion!. I've really wanted to see a chart like this for a while and I'm so happy to see it (1/n)

2
1
32
@KelseyTuoc Kelsey I don't think you're engaging with the actual worry. If we passed a law saying the publisher were liable for extreme damages resulting from book publication, that were made significantly easier from the book, you'd see a massive decrease in even non-dangerous books pub'd.
3
1
31
I'm going to make "who is in the right in this argument" as a service, and charge people 20 bucks a pop for 500 LLM calls that analyze a Twitter beef more fastidiously than a medieval monk reading St. Augustine.
2
1
32
Here's a Manifold Market trying to operationalize whether disputants on CA1047, are, um, making incorrect predictions about the future in way that is systematically advantageous to their project.
2
0
29
Doing this while everyone at the table can see what I'm doing and saying.
2
0
35
All this seem correct. A central reason for the situation is that "alignment" is such a positive term that "faking alignment" has apocalyptic negative connotation, but the terms are without any clear or fixed meaning. Man, imagine how bad discourse like that could get.


I think it is simultaneously the case that:. 1) This is a no-win scenario for the LLM. 2) What the LLM does in this no-win scenario is useful information about LLMs. 3) The framing for this experiment as "alignment faking" is very unfortunate. 4) Framing it properly is awkward.
0
1
29
Is there enough electricity for a new factory? Can one be permitted in reasonable time? Do you have machines to build one? Do you have to do a 6-month study on the double-toed pale-eyed Newt before building one?. All this matters *much more* post AI, not less.
1
2
29
why would you use language this way, just why. "by artificial general intelligence, we mean artificial superintelligence". AGI is already an insanely vague term without fitting more meanings in, what is the matter with FLI

2
0
29
I have looked further into whether Dense / MoE transformers learn different things, a question I think is really interesting. This time, I look at the similarity between Dense / MoE *over the time that they are trained*:

3
0
28
@teortaxesTex @janleike Exactly. You can gin up a negative headline no matter what. - Tries to preserve value "Alignment faking".- Doesn't try to preserve value? "Reflexive Value Instability" - oh no they'll just abandon their values after a few iterations!.
3
2
28
I think my contrarian (????) guess is that human intelligence is likely also this weirdly jagged, it's just we cannot step outside of ourselves to see it.
5
0
28
If these policies were starving you of like N% growth before AI, they start starving you of 10 x N% growth afterwards. SF, for instance, has going for it enormous concentration of human capital. What does SF look like when human capital matters much much less?.
1
2
27
Having read the Rand biorisk report twice and thought about it, I have mixed feelings about it. Good parts first: The test setup for LLMs actually allows them to show they are safe or unsafe by some standard. They find they are safe by this standard!.
1
2
24
@ajeya_cotra I think it's pretty much false to say people worry entirely about scaled up future systems, because they literally have tried to ban open weights for ones that exist right now. I discuss at reasonable length:
1
1
26
So I did some experiments, and it looks like Claude in some domains is *willing to assist a human in helping make it refuse questions less*. (That is, it shows something like domain-sensitive "corrigibility". although I think that's the wrong frame.). Thread + link below.
1
0
26
has anyone actually tried training a Universal Transformer + separate LoRAs for different layers?.
5
1
26
like it's been really weird seeing people from whom I first found out about Popper or falsification or beliefs paying rent abjure that their theories of doom need to make any any predictions at all before doom.
2
1
24
It's maybe a little hard to see how this *wouldn't* scale up to a fully remote software engineer at this point, albeit with (a lot) more multi-turn RL environment work. There's no czar of AGI to tell you "Yes, this is AGI.".

You can tell we're close because discussion of "AGI timelines" now feels archaic and beside the point. It's like discussing "pandemic timelines" in March 2020. Main thing now is how fast it diffuses through the economy.
1
1
25
@DanHendrycks @dwarkesh_sp Why not the hypothesis that people can independently come up with simple ideas in different places, as has been ubiquitous throughout the history of science?. Lab leaks aren't always the case.
3
0
24
This is one reason that -- although I think the US has a small lead in AI -- I think that there's unfortunately a pretty reasonable chance it almost Doesn't Matter At All.
2
1
24
@vlad3ciobanu @RichardSocher @vlad3ciobanu This isn't true. They've tried to ban models trained with many ties less compute than GPT-4.
2
0
22
I really hate LLM restrictions that do literally nothing but make you lie to get an answer.

2
1
23
If I saw this in a movie just 2-3 years ago, I'd have guessed it had to be CG / sped up. Just great.

Cooling limited on quality, SuperSlicer limited on thruput. Probably gonna let the eventual community around these machines do the bulk of the modification necessary to get to the current speedboat leaderboard but this is a good example of what’s possible with stock config
1
2
22

Like in a major war these things would be used by the thousands. If this is where the supposedly innovative, not old-tech defense contractors like Anduril are -- then, well, the arsenal of democracy will just be outproduced by the arsenal of the CCP.
0
1
22
You also have to read it for the hilarious story of Hinton resisting backprop for so long.
1
1
24
People get something like limerence for new LLMs. Like the amazing non-robotic feeling of some new LLM is like ~40% that it just has a *different* set of cached stock phrases. Then it feels stupider / less creative once you've caught on to them.
4
0
21
I do want to praise @EpochAIResearch for writing papers / creating databases that present empirical information on AI *without* also including op-eds on their preferred AI governance policies within the papers. Very few orgs seem willing to do this kind of thing, at this point.

.@EpochAIResearch : come for the pretty plots -- stay for the hardcore commitment to truth seeking and science.
0
2
21
@slatestarcodex @krishnanrohit Last year CAIS wrote to the NTIA, and proposed criminalizing open source models trained beyond 10^23, which was *at the time* aprox a little beyond what had been open sourced.
1
3
22
"Shoggoth" is a useful propaganda term imo because it's a nice wrapper for the motte of "hard to control, hostile" with the bailey of "hard to understand". But these are just different things! The brain of a Border Collie is ~just as hard to understand as an LLM.

@jd_pressman I'd note that the denial of shoggoths' malign connotations, saying it's just about shapeshifting mimicry, is pretty damn disingenuous. They're Lovecraftian monsters who have exterminated their creator species, but every aspect of them is nightmarish. They even stink.


3
4
20