

Wenhao Yu
@wyu_nd
Followers
3K
Following
880
Media
45
Statuses
286
Senior Research Scientist at @TencentGlobal AI Lab in Seattle | Bloomberg PhD Fellow | Ex. @MSFTResearch @TechAtBloomberg and @allen_ai
Seattle
Joined December 2021
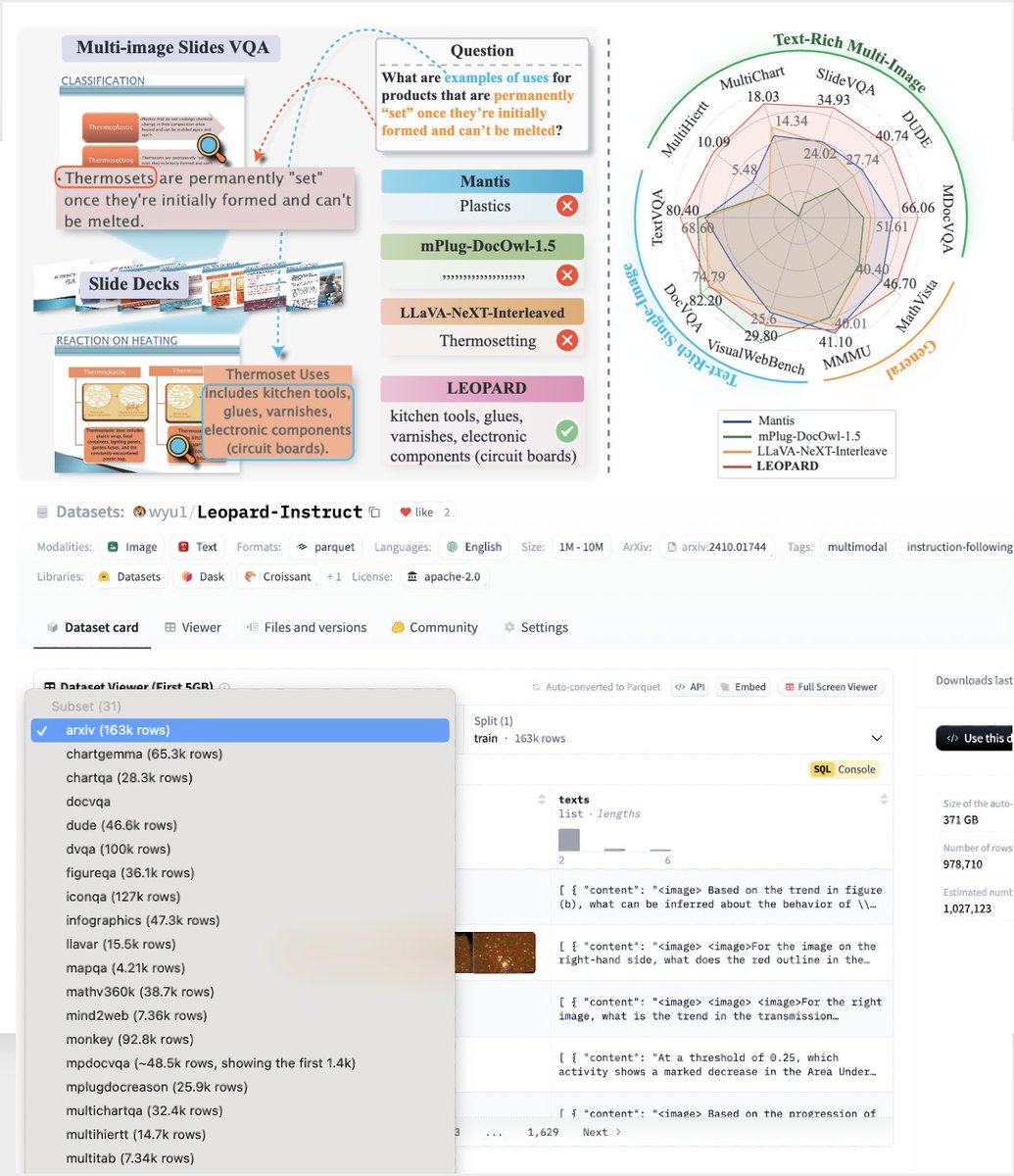
🥳 We open-sourced Leopard-Instruct, a dataset containing 𝟏𝐌 𝐡𝐢𝐠𝐡-𝐪𝐮𝐚𝐥𝐢𝐭𝐲, 𝐭𝐞𝐱𝐭-𝐫𝐢𝐜𝐡, 𝐦𝐮𝐥𝐭𝐢-𝐢𝐦𝐚𝐠𝐞 𝐢𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧-𝐭𝐮𝐧𝐢𝐧𝐠 examples. It significantly improves performance on multi-image understanding!. Github:
1
47
194
When I tried OpenAI O1-preview on complex Chinese math problems, the model still thinks in English. This behavior aligns with our findings in our #ACL24 paper on "Leveraging Pivot Language in Cross-Lingual Problems". We found that answering non-English questions while thinking in

34
50
476
My 2023 summary:.🎓 PhD graduation .🏆 EMNLP Outstanding Paper.💯 Crossed 1000+ citations.🦙 Met a real Alpaca in Peru 🇵🇪 Tried luring it with 🥕 for a fun photo, but the Alpaca had own thought and DOES NOT follow my instruction at all 🤣. Embracing 2024 with fresh enthusiasm 🚀




2
8
335
🚢Introduce WebVoyager -> Building an End-to-End Web Agent with Large Multimodal Models. 📌A GPT-4V powered web agent, can complete user instructions end-to-end on real-world websites.📌Given [task instruction, trajectory], we show GPT-4V can be a good web agent task evaluator

6
25
168
𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗲 𝗥𝗮𝘁𝗵𝗲𝗿 𝗧𝗵𝗮𝗻 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗲 is now 𝗮𝗰𝗰𝗲𝗽𝘁𝗲𝗱 to #𝗜𝗖𝗟𝗥𝟮𝟬𝟮𝟯 🎉🎉 Without using DPR/Google, it achieved SoTA on multiple open-domain QA and knowledge-intensive benchmarks! Work done .@ms_knowledgenlp!.Code and paper:

3
41
229
📢New paper: Chain-of-Note . Retrieval-Augmented LMs are often misled by noisy, irrelevant documents. Adding IR could even hurt performance in some scenarios😅. Chain-of-Note improves +7.5 over standard RALM on NQ when all documents are noisy!. ArXiv:

3
34
141
🚀 Exciting opportunities at 𝐓𝐞𝐧𝐜𝐞𝐧𝐭 𝐀𝐈 𝐒𝐞𝐚𝐭𝐭𝐥𝐞 𝐋𝐚𝐛! We're hiring interns for Summer 2025 and multiple FTEs in cutting-edge research across LLM Agents, RAG, and Multi-modal LLM. Check out some of my (and my intern's) recent works:. 🔹 RAG:.Generate rather than.
5
28
222
🎉Personal Update: Successfully defend my PhD and now part of @TencentGlobal AI Lab Seattle. Huge thanks to my advisor @Meng_CS for unwavering support. I'll work on frontier NLP research, focusing on novel tech in LLM, IR & Instruction tuning. & free feel reach out for internship

24
2
203
🎉🎉#𝗘𝗠𝗡𝗟𝗣𝟮𝟬𝟮𝟮 𝗔 𝗨𝗻𝗶𝗳𝗶𝗲𝗱 𝗘𝗻𝗰𝗼𝗱𝗲𝗿-𝗗𝗲𝗰𝗼𝗱𝗲𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝘄𝗶𝘁𝗵 𝗘𝗻𝘁𝗶𝘁𝘆 𝗠𝗲𝗺𝗼𝗿𝘆: A close-book model with much better performance than 𝗘𝗮𝗘, e.g. 47.2 EM on TriviaQA, and outperform open-book on ELI5!. ArXiv:

1
38
170
📢 I am actively looking for research interns working with me in summer 2024 at @TencentGlobal AI Lab in Seattle. If you have research backgrounds in IR & RAG, Factuality, Reasoning, Agent and interested in the working with me, feel free to DM me! 😊

3
21
152

💡Introducing DSBench: a challenging benchmark to evaluate LLM systems on real-world data science problems. GPT-4o scores only 28% accuracy, while humans achieve 66%. A clear gap, but an exciting challenge for AI advancement! 🧐. Paper: Project lead by our

10
27
140
🎉 New preprint! Generate rather than Retrieve: Large Language Models are Strong Context Generators. Our proposed method achieved new SoTA on open-domain QA! (1/5). Arxiv link:

1
20
134
Understanding multiple text-rich images is a challenging task! Today, we are thrilled to introduce a new vision-language model capable of processing multiple visual documents, charts, and snapshots as input, outperforming SoTA models by a large margin. It’s highly useful for

1
33
134
Our team at Tencent AI Seattle is looking for 1–2 summer research interns for 2025 to work on 𝐀𝐠𝐞𝐧𝐭-𝐫𝐞𝐥𝐚𝐭𝐞𝐝 projects. These include building better GUI agents (e.g., planning, grounding), developing self-evolving agents (e.g., exploration, critique, reflection), and.
1
10
122
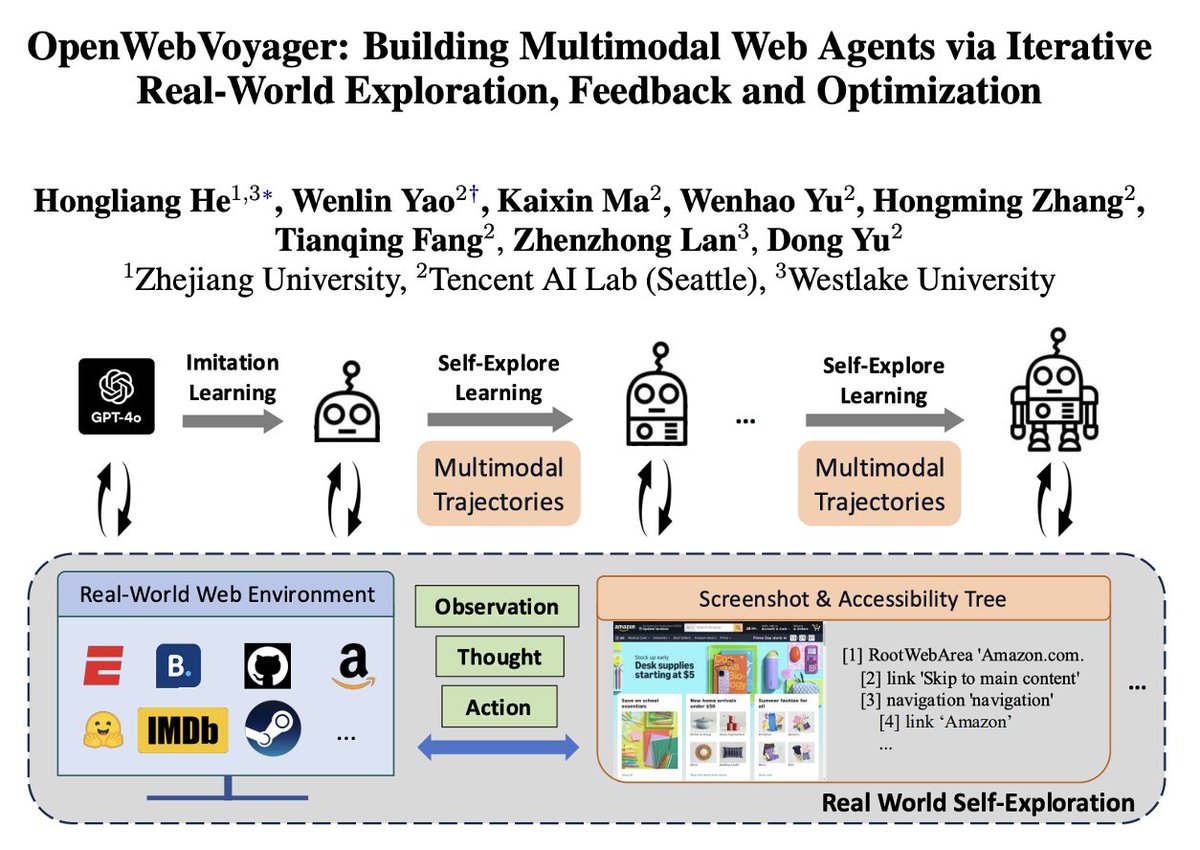
🚀Introducing OpenWebVoyager: a multi-modal, LLM-based web agent built on open-source models! It iteratively improves through real-world exploration, followed by visual critique and optimization using successful trajectories after each round!. Paper: Code:
2
19
109
📢New paper "Sub-sentence Encoder" (led by.@soshsihao), a contrastively-learned contextual embedding model for fine-grained semantic representation of text. 🏆Outperform SimCSE, GTR, ST5 and other sentence embedding methods by large margin! . ArXiv:


Text embeddings = one embedding for the entire text sequence. But what if the text is long and says many things?.Can encoders produce contextual embedding for an individual piece of meaning in one text sequence?. ❗Check out: Sub-Sentence Embeddings. 1/6

1
14
105
🎉𝐃𝐞𝐧𝐬𝐞 𝐗 𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥: What Retrieval Granularity Should We Use?. Both passage and sentence level index are not optimal for dense retrieval. We introduce a novel retrieval unit, proposition, for dense retrieval. See details in this thread ~.

2
16
99
🎉#EMNLP paper: LLM is greatly influenced by the quality of instructions, and manually written instructions for each task is laborious and unstable. We (led by @zhihz0535) introduce Auto-Instruct, automatically improve the quality of instructions provided to LLMs.

2
24
105

We (Tencent AI Seattle Lab) still has one summer internship position, focused on RAG, Web Agent, or Multi-modal research. Please DM me if you are interested and have a relevant background. 😊.
8
10
93
🎉🎉EMNLP 2022: Knowledge Graph Enhanced Passage Reader for Open-domain Question Answering. With the same retriever and the same set of retrieved passages, GRAPE can outperform the state-of-the-art reader FiD by a large margin. ArXiv:

2
16
90
📢 Introducing Cognitive Kernel: an open-source agent system towards generalist autopilots. The system can interact with real-world environment, handling user-provided files, access websites (e.g., Amazon), and manage long-term chat history. Our system is fully open-sourced and
1
2
76
📢 Excited to share that we will organize the 3rd workshop on Knowledge-Augmented NLP at ACL 2024. We will have six amazing speakers! We welcome your submissions and invite you to discuss with our speakers and organizers at the workshop. Looking forward to seeing you in Thailand!

1
17
76
📢 Introducing ReFeed: a novel plug-and-play approach to enhance the factuality of large language models via retrieval feedback! Together with @Meng_CS @zhihz0535 @LiangZhenwen @ai2_aristo . Read more:

1
15
73
Excited to see MLE-Bench out, and a big thanks to @OpenAI for highlighting our DSBench as concurrent effort. Proud to contribute to advancing AI agents for real-world challenges alongside these initiatives!. DSBench:


We’re releasing a new benchmark, MLE-bench, to measure how well AI agents perform at machine learning engineering. The benchmark consists of 75 machine learning engineering-related competitions sourced from Kaggle.
3
10
72
📌Many LLM systems allow users upload documents, such as GPT-4, Claude, and Kimi. Have you used any of these systems?🤔 𝐇𝐚𝐯𝐞 𝐲𝐨𝐮 𝐞𝐯𝐞𝐫 𝐰𝐨𝐧𝐝𝐞𝐫𝐞𝐝 𝐰𝐡𝐢𝐜𝐡 𝐬𝐲𝐬𝐭𝐞𝐦 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐬 𝐭𝐡𝐞 𝐛𝐞𝐬𝐭 𝐰𝐡𝐞𝐧 𝐲𝐨𝐮 𝐚𝐬𝐤 𝐚 𝐪𝐮𝐞𝐬𝐭𝐢𝐨𝐧 𝐛𝐚𝐬𝐞𝐝 𝐨𝐧

5
18
72
📢 Introducing IfQA - the first large-scale open-domain question answering (ODQA) dataset centered around counterfactual reasoning. Together with @Meng_CS @ai2_aristo!. Paper link:

4
15
63
Wrapping up a fantastic #EMNLP2024! Great to attend with friends from Tencent AI Seattle, connect with old & new colleagues, and engage with so many who share our interests!. And always happy to chat about intern & working opportunities at @TencentGlobal AI Lab in Seattle!

0
3
60
Thanks @TechAtBloomberg! It is my great honor to receive the fellowship! Thanks also to my advisor @NDengineering @meng_cs for always giving me the best support!.

Congratulations to @NotreDame + @ND_CSE's @wyu_nd on his being named one of the 2022-2023 @Bloomberg #DataScience Ph.D. Fellows!. Learn more about his research focus and the other new Fellows in our fifth cohort: #AI #ML #NLProc

6
2
59
📢 New paper: Compared to 𝐌𝐮𝐥𝐭𝐢-𝐦𝐨𝐝𝐚𝐥 𝐂𝐨𝐓, We found 𝐃𝐞𝐬𝐜𝐫𝐢𝐛𝐞 (visual description generation)-then-𝐑𝐞𝐚𝐬𝐨𝐧 (generating 𝐌𝐮𝐥𝐭𝐢-𝐦𝐨𝐝𝐚𝐥 𝐂𝐨𝐓 with the assistance of descriptions) could greatly improve math reasoning on MathVista and MathVerse.

0
10
58
📢 Fall semester internship at @TencentGlobal AI Lab in Seattle: We are actively looking for research interns working on IR & RAG, Complex Reasoning, Multi-modal and Language Agent. If you are interested in the working with us, feel free to DM me! 📷.
2
5
51
Just arrived in Miami for #EMNLP2024! Excited to present three papers on RAG, LLM Agents, and LLM Reflection. Happy to chat about research and discuss intern / full-time opportunities at Tencent AI Research Lab in Seattle!

0
2
51
I deeply appreciate of the implementation of WebVoyager and fantastic video that explains how to utilize LangGraph for its construction, as well as the comprehensive discussion surrounding LangGraph. Our team will provide more detailed information and make our source code.

⛴️ WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. WebVoyager is a new kind of web-browsing agent, developed by Hongliang He, @wyu_nd, et. al. Powered by large multi-modal models, like GPT-4V, it uses browser screenshots to conduct research, analyze

0
3
39

Excited to share our #EMNLP2022 #NLProc paper on improving multi-task learning via a very simple but very effective task prefix tuning method!.

#EMNLP2022 🧭Task Compass: Scaling Multi-task Pre-training with Task Prefix. 🤔When multi-task pre-training in scale, how to explore task relationships?. 💡We find that task relationships can be probed by simply adding single-token task prefixes!

0
4
32
Excited to see our LongMemEval featured by LongBench v2! Tackling long-context challenges in real-world scenarios is key to enabling LLMs to retain user histories and preferences. Can’t wait to see it spark innovation in long-context and memory mechanisms!. Also directly checkout.

Introducing 📚 LongBench v2: A benchmark to assess the ability of LLMs to handle long-context problems requiring deep understanding and reasoning across a variety of real-world tasks. 🧠 Do long-context LLMs truly "understand" the long text they process? Let's find out!. 🧵 1/

0
3
33

An unforgettable night at NeurIPS 2024! 🎉 Our @TencentGlobal Starlit Tech Gala brought together 300+ attendees for an evening of innovation, networking, and fun in Vancouver. Thanks all for joining us! 🚀✨ #NeurIPS2024




0
0
30
Excited to rank 3rd on HuggingFace Top Contributors for Dec. 2024! 🎉 Mainly driven by 𝐋𝐞𝐨𝐩𝐚𝐫𝐝: 𝟏𝐌 high-quality data for 𝐭𝐞𝐱𝐭-𝐫𝐢𝐜𝐡 𝐦𝐮𝐥𝐭𝐢-𝐢𝐦𝐚𝐠𝐞 tasks like document VQA, charts, slides, and agents. So glad people are finding it useful! Check it out if

1
1
29
𝐍𝐞𝐰 𝐒𝐮𝐫𝐯𝐞𝐲 𝐩𝐚𝐩𝐞𝐫 in #eacl2023! New perspectives to summarize multi-task learning in NLP from task relatedness and training methods! Also nice future work discussion. #NLProc.

Our paper "A Survey of Multi-task Learning in Natural Language Processing: Regarding Task Relatedness and Training Methods" has been accepted to #eacl2023 main conference! Collaboration with @wyu_nd, @Meng_CS, @Zhichun5 and Mengxia Yu.

0
3
27
Thanks @_akhaliq for covering our work! WebVoyager🚢 is a GPT-4V powered web agent that can follow human instructions and complete tasks (e.g. ticket booking, shopping) on various real-world websites (e.g. Google flights, Amazon)! . The paper also present a new benchmark dataset.

Tencent presents WebVoyager. Building an End-to-End Web Agent with Large Multimodal Models. paper page: The advancement of large language models (LLMs) leads to a new era marked by the development of autonomous applications in the real world, which drives

2
2
27
Excited to announce four highly esteemed keynote speakers @amit_p, @boydgraber, @scottyih, Chandan at our upcoming @knowledgenlp #AAAI23 workshop on Feb 13th! Dive into the cutting-edge topics of neuro-symbolic AI, code understanding, retrieval-augmented LM, and advanced QA.

1
8
25
Many of us from the Tencent AI Lab Seattle team are at NeurIPS! 🎉 @hongming110, @LinfengSong1, and others (some not on Twitter) are here—feel free to say hi to them at the venue or poster!. We have full-time research openings and summer 2025 research internships—let’s talk!.

Excited to revisit Vancouver😆 Our team at Tencent AI Lab is actively hiring full-time researchers and research interns for next year. Let's chat if you are interested in conducting frontier research in Multi-modal agents, RL, and model architectures.😼😼😼.
0
2
24
📣Our 3rd workshop of knowledge augmented NLP will happen in ACL 2024 this year! Submission ddl: May 17, 2024! Looking forward to seeing you in Thailand!.

🎉Excited to announce the 3rd Workshop on Knowledge-Augmented NLP at ACL 2024 in Thailand!.Submission deadline: May 17, 2024. Eager to reconnect with old friends and welcome new faces in the Knowledge NLP community!.#ACL2024 #NLProc

0
0
22
🏆 Our work “Empowering Language Models with Knowledge Graph Reasoning for Question Answering” won the best paper award at #SoCalNLP 2022. Paper link:

Our @MegagonLabs Best Paper Award winner was "Empowering Language Models with Knowledge Graph Reasoning for Question Answering" by Ziniu Hu et al from UCLA!. Paper link: Thank you to award sponsor @MegagonLabs for supporting our event! (4/4)

1
1
22
PLUG is a novel cross-lingual instruction tuning method which could make LLaMa follow Chinese instructions (and other low resource language) very well!. Check out our paper at
🤨LLMs struggle to follow instructions in low-resource languages?.⚡️Introducing PLUG: leveraging pivot language in cross-lingual instruction tuning.📈Improved LLaMA-2 by 32% on 4 diverse languages!. Check out our new preprint at➡️

0
2
19
Thanks LangChain AI for covering and implementing Chain-Of-Note app as a LangChain template. Chain-Of-Note improves performance when retrieved information contains noise. Check out our paper at
🗒️Chain-of-Note Template . Chain-of-Note is a new prompting technique by @wyu_nd et al for RAG applications that helps improve performance when the retrieved information might be noisy. We implemented a Chain-of-Note app as a LangChain template. Given a question, query Wikipedia

0
4
18
Thanks @LangChainAI for finding our methods useful and have put it in your templates!.
🔎Proposition-Based Retrieval. This new paper by @tomchen0 introduces a new retrieval method by changing 🎯what is indexed🎯 in the first place. This can easily use our 🌲multi-vector retriever🌲, and we've added a template to get started with it easily!. 💡How does it work? 👇

0
2
17

I will be at #ACL2024, will be hosting our 3rd workshop on knowledge-augmented methods for NLP, on August 16. We invited 6 keynote speakers, with 30 accepted oral and poster papers, covering diverse topics on RAG, KG, Agent …. See details at
Thrilled to announce our finalized schedule at #ACL2024! We're excited to feature 6 keynote speakers and 30 accepted papers. Join us for an inspiring event!

0
1
15
Combing Retrieval AND Generation (in step1) can further improve the model performance, as shown in Figure 3. The choice of retrieval or generation is interesting, and their complementarity is worth exploring. Using retriever or generator only where it helps.

Right now we do:.1. retrieve docs.2. LLM generate output w/ those. But this doesn't fully leverage LLM power for step 1. What if we directly generate contextual docs for a question, instead of retrieving external docs?!. Paper Code

0
2
14
📣 Check out this awesome survey on mathematical reasoning at poster session 2 #ACL2023.

🧲Please stop by our poster on deep learning for math reasoning at Poster Session 2 @aclmeeting #ACL2023NLP. ❤️Thanks to co-authors for their great contributions: @liangqiu_1994, @wyu_nd, @wellecks, & @kaiwei_chang. abs: github:

0
3
14
🧐We introduce a new method: using reflective thoughts to improve the model's reasoning capability, just as we humans often do when we step back to question our assumptions, make analogies, and explore alternative solutions.
🧐Previous math augmentation focused on improving single-round QA.🎯We introduce a new method that1⃣augments standard math settings2⃣excels in reflective thinking scenarios!.👉Check our latest preprint at

0
1
14
The new paper from our Tencent AI lab identifies 8 valuable insights into the current state of machine translation research in the LLM era, and propose potential avenue for future advances! . Check the paper below 😊.

💡 How are Large Language Models reshaping the landscape of Machine Translation? 🎈. 🚀 Check out our latest paper to find interesting findings. We comprehensively revisited Six Classic Challenges of MT in the context of LLM. 🎉.👉 Dive in here: And

0
0
12
Pls consider submitting your work to our Knowledge Augmented NLP workshop at #AAAI2023! Looking forward to seeing you at Washington DC next February 🎉.
Hello World! The first workshop on Knowledge Augmented Methods for NLP at #AAAI2023 is welcoming submissions🙌! Papers due by Nov. 8! Accepted paper will be non-archival! Details are available 👉

0
2
13
If you’re attending #COLM2024, feel free to chat with my colleagues! We’re jointly hiring interns for exciting projects on LLM agents, self-evolving systems, multimodal (vision language), and RAG models. 🚀.
Arriving at #COLM2024 . Thrilled to meet old/new friends. Come find me discussing llm agents, ai systems, and all the excited things beyond.😆😆😆

0
0
12
“Retrieves non-parametric memories only when necessary.” This is a very insightful conclusion by asking “how retrieval is complementary to LLM parametric knowledge.” We showed the same observation in paper but did not give detailed analysis. Learned a lot!.

Can we solely rely on LLMs’ memories (eg replace search w ChatGPT)? Probably not. Is retrieval a silver bullet? Probably not either. Our analysis shows how retrieval is complementary to LLMs’ parametric knowledge [1/N].📝 💻

0
2
12
Welcome to our presentation at today 11:30-11:45 at Hall B #EMNLP2022! Unified entity memory network have much stronger capabilities than EaE (first released by Google’s @professorwcohen , which is not restricted to only entity outputs.
🎉🎉#𝗘𝗠𝗡𝗟𝗣𝟮𝟬𝟮𝟮 𝗔 𝗨𝗻𝗶𝗳𝗶𝗲𝗱 𝗘𝗻𝗰𝗼𝗱𝗲𝗿-𝗗𝗲𝗰𝗼𝗱𝗲𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝘄𝗶𝘁𝗵 𝗘𝗻𝘁𝗶𝘁𝘆 𝗠𝗲𝗺𝗼𝗿𝘆: A close-book model with much better performance than 𝗘𝗮𝗘, e.g. 47.2 EM on TriviaQA, and outperform open-book on ELI5!. ArXiv:
1
0
11
Welcome paper submissions to our workshop at #AAAI2023. Please help to share it! 😁.
Call for papers! The first workshop on Knowledge Augmented Methods for NLP (#NLProc) at #AAAI2023 is welcoming submissions🙌! Papers due on Nov. 4! Papers will be non-archival, so published papers (e.g.#EMMLP2022) can also present at our workshop! Details👉

0
1
10
If you are at #NeurIPS2023, feel free to talk with my colleagues for internship opportunities next summer!.

Hello friends at #NeurIPS2023, our @TencentGlobal AI Lab in Seattle is actively looking for research interns for 2024. If you are interested in topics such as RAG, Reasoning, LLM Agent, and user interfaces, feel free to DM me for a chat!😊.
0
1
11
Congratulations! Welcome back to Tencent AI lab for internship again!.

My awesome student @JamesYHuang36 just received an outstanding paper award at #EMNLP2023! He is looking for summer research intern. Please interview him.

0
0
10
Asking LLMs to follow complex instructions to programming with function calls precisely is still a challenging task.

o1-preview-2024-09-12 on BigCodeBench-Hard. Complete 34.5% (slightly better than Claude-3.5-Sonnet-20240620).Instruct 23.0% (far below other top models).Average 28.8% . o1-preview may follow detailed instructions reasonably well, but not the brief ones. Not sure how consistent

0
3
10
This is a great new benchmark dataset if you work on scientific QA problems!.
📢📢Excited to have one paper accepted to #NeurIPS2022! We present a new dataset, ScienceQA, and develop large language models to learn to generate lectures and explanations as the chain of thought (CoT). Data and code are public now! Please check👇👇.




1
2
10
In this paper, we introduce DocBench, a new benchmark designed to evaluate LLM-based document reading systems. Our benchmark involves a meticulously crafted process, including the recruitment of human annotators and the generation of synthetic questions. It includes 229 real

1
4
9
Dense X retrieval is accepted to #EMNLP2024! Discover how retrieval granularity can significantly affect your retriever performance -- it makes a big difference! Check it out!. Link:

❗With dense retrieval, the unit in which you segment a retrieval corpus (passage, sentence, etc) may impact performance by more than you thought!. We introduce a novel retrieval unit, proposition, for dense retrieval. [1/7]

1
0
9
(2/3) Unified Encoder-Decoder Framework with Entity Memory (#EMNLP2022): The entity knowledge is stored in the memory as latent representations, and the memory is pre-trained on Wikipedia along with encoder-decoder parameters.
2
0
9
In 2021, we wrote a survey ( to hightlight a key LM challenge: augmenting with external knowledge via IR, tools, etc. The introduction of plugins in ChatGPT reaffirms the effectiveness of knowledge augmentation for infusing LLMs with up-to-date information.
We are adding support for plugins to ChatGPT — extensions which integrate it with third-party services or allow it to access up-to-date information. We’re starting small to study real-world use, impact, and safety and alignment challenges:
0
0
9
Thank you, Jerry @jerryjliu0, for highlighting our proposition retrieval work in the llama-index. The LlamaPack truly demonstrates the practical application and effectiveness of proposition-based retrieval systems!.

A big factor for building production RAG is deciding the "chunk" used for retrieval + synthesis: should it be a sentence? Paragraph? . In the "Dense X Retrieval" paper (@tomchen0 et al.), the authors propose a concept that we've advocated for a while: decouple the indexed chunk.
0
3
6
𝓛𝓸𝓷𝓰𝓜𝓮𝓶𝓔𝓿𝓪𝓵 can be used to evaluate 𝐟𝐢𝐯𝐞 𝐜𝐨𝐫𝐞 𝐥𝐨𝐧𝐠-𝐭𝐞𝐫𝐦 𝐦𝐞𝐦𝐨𝐫𝐲 𝐚𝐛𝐢𝐥𝐢𝐭𝐢𝐞𝐬 of chat assistants: (1) information extraction, (2) multi-session reasoning, (3) temporal reasoning, (4) knowledge updates, and (5) abstention!.

Introducing LongMemEval: a comprehensive, challenging, and scalable benchmark for testing the long-term memory of chat assistants. 📊 LongMemEval features:.• 📝 164 topics.• 💡 5 core memory abilities.• 🔍 500 manually created questions.• ⏳ Freely extensible chat history

0
0
7
(3/3) KG-enhanced DPR/FiD (#EMNLP2022): Using knowledge graph (Wikidata) to improve the retrieve-then-read pipeline, learn better document representation.
1
0
7
(1/3) Generate-then-read propose a novel pipeline for solving open-domain QA tasks, i.e., replacing the process of retrieving contextual documents from large-scale corpora such as Wikipedia by prompting GPT-3 to generate relevant contextual documents.
1
1
7
Training with reflective thinking is indeed an effective strategy, as shown in both Math and Coding. It may need further refinement, such as scaling the data and domains, improving the critic and verification. Check out our paper for more details:

Synthetic data for reflective thinking and Chain of Thought! @OpenAI o1 “produces a long internal chain of thought before responding to the user.” A recent paper introduces RefAug on how we can augment existing data to embed problem reflection and “thinking” into the training

0
0
6
This is an impressive result! Congrats to your team on this milestone! 🚀.

We just achieved a new state-of-the-art 93% accuracy on the WebVoyager benchmark with and here's how we are thinking about the AI Agent problem. @wyu_nd @ycombinator

0
0
6
Thrilled to see Google’s Project Mariner hit 83.5% on our WebVoyager benchmark for real-world web tasks! Excited for more open-source efforts. Explore our benchmark and code here:

When evaluated against the WebVoyager benchmark, which tests agent performance on end-to-end real world web tasks, Project Mariner achieved a state-of-the-art result of 83.5% working as a single agent setup.
0
2
6
💡𝐍𝐞𝐰 𝐌𝐚𝐭𝐡 𝐁𝐞𝐧𝐜𝐡𝐦𝐚𝐫𝐤: Different from existing single-turn math QA datasets, MathChat is the first benchmark focusing on multi-turn conversations about math. 🔔Existing LLMs exhibit a significant decline in math reasoning ability after multi-turn conversations!.

🚀 Excited to share our latest research MathChat! 📊 We explore the new frontiers in interactive math problem-solving. Check it out! 🧵👇. MathChat is a benchmark designed to evaluate LLMs on mathematical multi-turn interaction and open-ended generation.
0
1
5
DSBench requires LLM systems to read user uploaded files, write and execute codes to solve data science problems. This benchmark includes 466 data analysis tasks and 74 data modeling tasks, sourced from Eloquence and Kaggle competitions. The dataset is available at.
0
1
5
We improve current RALM on two aspects: (1) Noise Robustness: The ability to discern and disregard noisy information present in irrelevant retrieved documents, (2) Unknown Robustness: The ability to acknowledge its limitations by responding with “unknown” (1/4)

1
0
5
Huge shoutout to our fantastic organizers for making the #KnowledgeAugmented #NLP workshop a reality! Thank you @MS_KnowledgeNLP, @wyu_nd, @Meng_CS, @ChenguangZhu2, @shuohangw, @LuWang__, and @hhsun1.
0
0
5
Try BigCodeBench! It is the next generation of HumanEval.
In the past few months, we’ve seen SOTA LLMs saturating basic coding benchmarks with short and simplified coding tasks. It's time to enter the next stage of coding challenge under comprehensive and realistic scenarios! . -- Here comes BigCodeBench, benchmarking LLMs on solving

0
0
3
@zhihz0535 just presented the work this morning. If you missed it but interested in related research, DM us and we are happy to chat!

0
1
4
#NAACL2025 notifications are out! Whether your paper was accepted or not, we’d love to see your work at our workshop. If your paper is accepted, you can submit your work to our non-archival track and showcase it to a broader audience. Looking forward to your submissions! ✨.
🎉Excited to announce the 4th Workshop on Knowledge-Augmented NLP at NAACL 2025 in New Mexico, USA! Submission deadline: Feb 15, 2025. Eager to reconnect with old friends and welcome new faces in the Knowledge NLP community!.#NAACL2025 #NLProc

0
0
4
@nembal I think mainly due to the imbalance in the language distribution in the pre-training corpus. Knowledge embeddings aren't as well connected across different languages. I remember when I studied abroad, it took me longer to learn a new concept compared to taking a similar class.
0
0
4
Thanks ND research for writing this great article for me 😊.

Shout for Notre Dame's iSURE program and CSE PhD program. You may get interested in them, if you get a chance to read my student Wenhao's stories. Wenhao Yu is a rising 4th-year PhD with Bloomberg Fellowship, working on NLP / QA.
0
0
4
If you missed the workshop, you can still find the videos and slides at (AAAI will post the video in around two weeks) and
1
0
4
We also present a novel clustering-based prompting approach to generate diverse contextual documents that increases the likelihood of generating a correct answer with more generations. This approach can significantly improve performance on downstream tasks. (3/5).
1
0
4
New paper 🎉: Check out our new work on adaptive pretraining for logical reasoning, lead by @ssanyal8!.

Want to teach logical reasoning 💭 skills to LMs 🤖?. Check out Apollo, our new adaptive pretraining strategy to improve logical reasoning in LMs. It is.(a) Simple to implement.(b) Generalizable across task formats.(c) Needs minimal data processing. Paper:
0
1
4
New paper 🎉: @lupantech Pan’s survey is a good summary and analysis of the recent work of language models in mathematical reasoning. If you are interested in mathematical reasoning, definitely check it out! Feedback welcome!.
🎉New paper! The survey of deep learning for mathematical reasoning (#DL4MATH) is now available. We've seen tremendous growth in this community since 2018, and this review covers the tasks, datasets, and methods from the past decade. Check it out now:

0
1
4
Work done with my colleagues at Tencent AI Seattle lab Hongming Zhang (@hongming110) Kaixin Ma (@KaixinMa9), Xiaoman Pan, Hongwei Wang, Dong Yu. (4/4).
0
0
3
DocBench construction pipeline. (a) Document Collection: gathering PDF files from five different domains; (b) QA-pair Generation: creating diverse and comprehensive QA pairs through a combination of LLMs and human effort; (c) Quality Check: ensuring data quality through a

1
0
3
👍 An impressive open-domain QA method that generalizes well on both single-hop and multi-hop setting!.
I'm happy to share that our paper "Open-domain Question Answering via Chain of Reasoning over Heterogeneous Knowledge" is now online. We proposed a unified framework for solving single&multi-hop questions that require reasoning over tables and/or text.
0
0
3
[3/n] Empirical results: over +6.0% improvement under zero-shot settings and +2.5% under few-shot settings compared to baselines on multiple open-domain QA, dialogue benchmarks.
0
0
3
Chain-of-note generates a series of reading notes for retrieved documents, enabling a comprehensive assessment of their relevance to the input query. We employed ChatGPT to create training data for CoN, which was subsequently trained on an LLaMa-2 7B model. (2/4).
2
0
3