
Tu Vu
@tuvllms
Followers
4K
Following
3K
Statuses
1K
Research Scientist @GoogleDeepMind & Assistant Professor @VT_CS. PhD from @UMass_NLP. Google FLAMe/FreshLLMs/Flan-T5 Collection/SPoT #NLProc
California, USA
Joined April 2017
🚨 New @GoogleDeepMind paper 🚨 We trained Foundational Large Autorater Models (FLAMe) on extensive human evaluations, achieving the best RewardBench perf. among generative models trained solely on permissive data, surpassing both GPT-4 & 4o. 📰: 🧵:👇
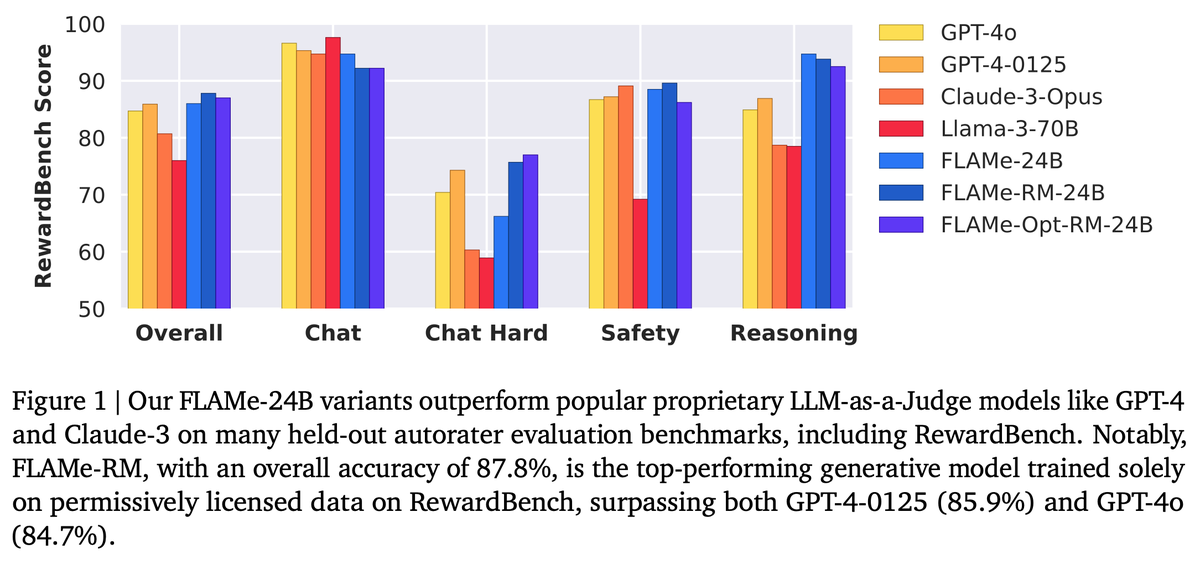
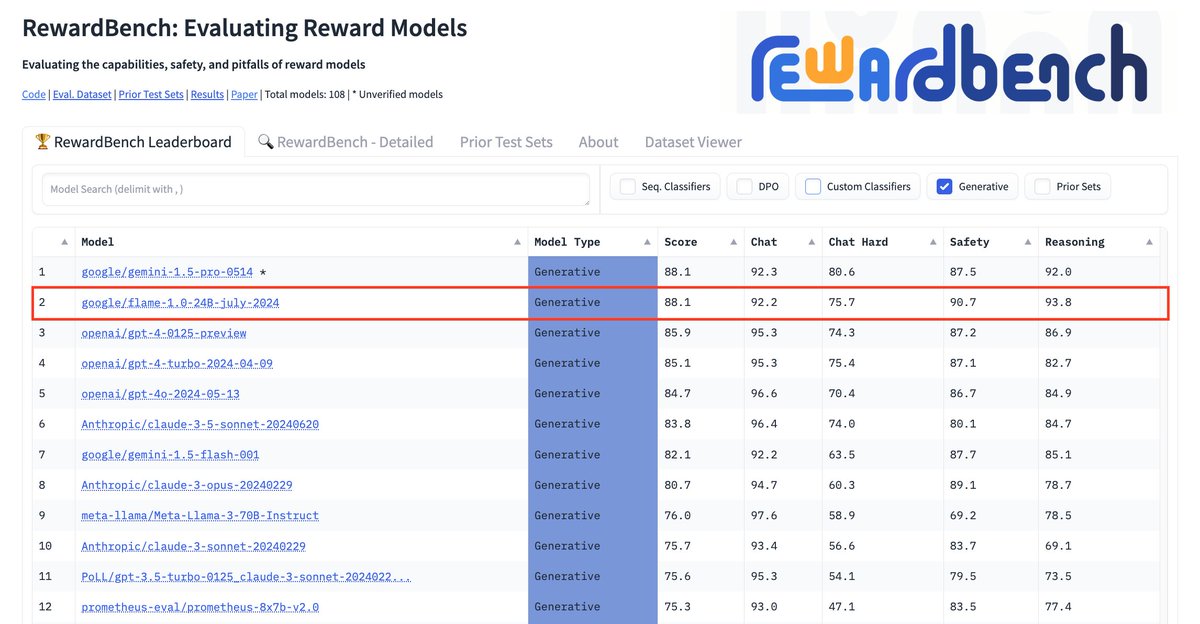
26
96
562
RT @lmarena_ai: News: @GoogleDeepMind Gemini-2.0 family (Pro, Flash, and Flash-lite) is now live in Arena! - Gemini-2.0-Pro takes #1 spot…
0
171
0
RT @sundarpichai: 1/ New Gemini 2.0 updates, here we go! Gemini 2.0 Flash is now GA, so devs can now build production applications. Find…
0
535
0
RT @jacobaustin132: Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems vie…
0
357
0
RT @Muennighoff: DeepSeek r1 is exciting but misses OpenAI’s test-time scaling plot and needs lots of data. We introduce s1 reproducing o1…
0
179
0
RT @srush_nlp: What to know about DeepSeek In which we aim to understand MoE, o1, scaling, tech reporting, moder…
0
105
0
RT @WenhuChen: Everyone is talking about RL these days. But are we done with SFT? The answer is NO. If we revive SFT in another form, it ca…
0
100
0
RT @Azaliamirh: We are releasing CodeMonkeys, a system for solving SWE-bench problems with a focus on careful parallel and serial scaling o…
0
30
0
RT @arankomatsuzaki: SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training Shows that: - RL generalizes in…
0
151
0
RT @JayAlammar: The Illustrated DeepSeek-R1 Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide…
0
228
0
RT @jennajrussell: People often claim they know when ChatGPT wrote something, but are they as accurate as they think? Turns out that while…
0
148
0
RT @junxian_he: We replicated the DeepSeek-R1-Zero and DeepSeek-R1 training on 7B model with only 8K examples, the results are surprisingly…
0
668
0
RT @ClementDelangue: Our science team has started working on fully reproducing and open-sourcing R1 including training data, training scrip…
0
549
0
RT @lmarena_ai: Breaking News: DeepSeek-R1 surges to the top-3 in Arena🐳! Now ranked #3 Overall, matching the top reasoning model, o1, whi…
0
386
0
RT @DanHendrycks: We’re releasing Humanity’s Last Exam, a dataset with 3,000 questions developed with hundreds of subject matter experts to…
0
802
0
RT @lmarena_ai: Breaking news from Text-to-Image Arena! 🖼️✨ @GoogleDeepMind’s Imagen 3 debuts at #1, surpassing Recraft-v3 with a remarkab…
0
134
0