

Brian Cheung
@thisismyhat
Followers
5K
Following
244
Statuses
219
This is my hat, there are many like it, but this one is mine. @MIT_CSAIL 🧢 / ex: @berkeley_ai 🎓 Google B̶r̶a̶i̶n̶ DeepMind 🎩
Natural Intelligence ∩ AI
Joined June 2015
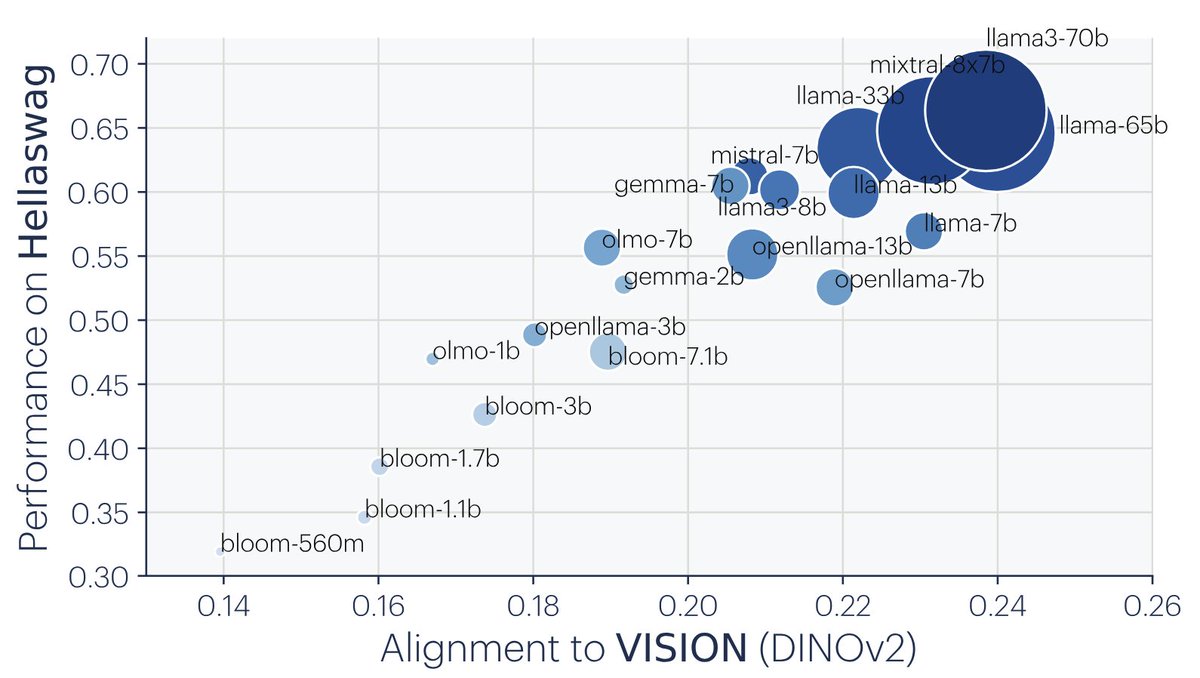
The Platonic Representation Hypothesis Surprising (?) results: - Pure vision models align with pure text models as scale increases. - This alignment correlates with better downstream performance. Fun work with @minyoung_huh @TongzhouWang @phillip_isola


5
16
122


@askerlee yeah right, I guess I already caused much confusion. We have been doing these for two months, and we didn't intend to release it this early. Since DS-R1 came out first and everyone is interested in it, we just called it a replication, I plan to further clarify this in the blog
2
0
1
Learn about aligning minds and machines. Call for papers is live now—join us at @iclr_conf #ICLR2025.

0
2
11
Expectation vs reality:


insane thing: we are currently losing money on openai pro subscriptions! people use it much more than we expected.
0
1
8
Combination of chain-of-thought reasoning and overfitting is weirder than I could have imagined.

New Anthropic research: Alignment faking in large language models. In a series of experiments with Redwood Research, we found that Claude often pretends to have different views during training, while actually maintaining its original preferences.

0
1
4
RT @su1001v: New paper💡! Certain networks can't perform certain tasks due to lacking the right prior 😢. Can we make these untrainable netw…
0
3
0
@phillip_isola @TongzhouWang Closing the learning loop between these two parts is an open problem.
0
0
1
@AVMiceliBarone @minyoung_huh @TongzhouWang @phillip_isola Sorry, I meant to say .035 for untrained language models.
1
0
1
@SebastienBubeck Doesn't O(C) become smaller as C becomes larger via Anna Karenina principle? At web-scale data, for a task as general as next-token prediction, I would guess C is very large.
0
0
0
Apple's market cap increases by 2 OpenAI's after they announce that they're using OpenAI 😅

1
2
14
@jeffrey_bowers @minyoung_huh @TongzhouWang @phillip_isola Specifically for our experiments, what do you think is a spurious correlation?
1
0
0
@martisamuser @jeffrey_bowers @minyoung_huh @TongzhouWang @phillip_isola Agree with the need for a counterfactual. We need a hypothesis for what the spurious variable is to create a counterfactual is which why I asked.
1
0
1
@jeffrey_bowers @minyoung_huh @TongzhouWang @phillip_isola What kind of spurious correlations do you think are shared between the caption of an image (given to text model) and the image (given to the vision model)?
2
0
2
RT @phillip_isola: New paper: The Platonic Representation Hypothesis In which we posit that _different_ foundation models are converging t…
0
254
0
@SebastienBubeck @shafayat_sheikh Agree, that is impressive. I'm personally curious, how large is the transfer distance between the training source from the evaluation?
0
0
0
@SebastienBubeck @shafayat_sheikh Without knowing what data Phi-3 was trained on (synthetic or otherwise). This statement is really difficult to interpret. Any chance you could say more about the training process to interpret the GSM1k numbers for Phi-3?
1
0
0
@_onionesque Interesting! Is this information only available if you have an idea of what the final target function will be (i.e. a 1-layer network). Wondering how this strategy would be implemented in a setting with multiple layers.
1
0
1