

Teknium (e/λ)
@Teknium1
Followers
31,042
Following
2,905
Media
2,019
Statuses
29,459
Cofounder @NousResearch , prev @StabilityAI Github: HuggingFace: Support me on Github Sponsors
USA
Joined February 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Bielsa
• 137924 Tweets
stevie nicks
• 72894 Tweets
harry styles
• 70133 Tweets
الاهلي
• 64341 Tweets
Brunson
• 53012 Tweets
#SmackDown
• 51023 Tweets
Alec Baldwin
• 42593 Tweets
Caitlin Clark
• 30110 Tweets
Knicks
• 29508 Tweets
フェルナンデス
• 23980 Tweets
FanDuel
• 23622 Tweets
#ウルトラマンアーク
• 16995 Tweets
FERNANDES
• 15145 Tweets
Reed Sheppard
• 11263 Tweets
ハロルド
• 11220 Tweets
三連休初日
• 10384 Tweets



















Pinned Tweet

Announcing Hermes 2 Theta 70B!! Our most powerful model ever released, and our first model to catch up to GPT4 on MT Bench, and beat llama-3 70B instruct nearly across the board!
We were able to do a full finetune of 70B to ensure maximum quality, worked with
@chargoddard
to



Introducing Hermes 2 Theta 70B!
Hermes 2 Theta is smarter, more creative, and capable of more then ever before.
It takes a strong lead over Llama-3 Instruct 70B across a wide variety of benchmarks, and is a continuation of our collaboration with
@chargoddard
and
@arcee_ai
.

10
61
328
70
131
1K
Today I have a huge announcement.
The dataset used to create Open Hermes 2.5 and Nous-Hermes 2 is now PUBLIC!
Available Here:
This dataset was the culmination of all my work on curating, filtering, and generating datasets, with over 1M Examples from

111
312
2K
Happy New Years Everybody! 🥳
One year ago today, I had:
- Never trained any model
- Did not know the first thing about AI
- Never worked in Tech
- Had 8 followers on twitter? (probably)
One year later and here I am!
Met many of my heroes and legends in tech and worked with

181
98
2K

Why do almost no papers release code, datasets, info on replication, final models, or any combination of these? I thought for science to work results had to be reproducible and verified. Really not scientific and I don't know why academia accepts this
145
120
2K
It's finally time! Our Mixtral 8x7B model is up and available now!
Nous-Hermes-2 Mixtral 8x7B comes in two variants, an SFT+DPO and SFT-Only, so you can try and see which works best for you!
It's afaik the first Mixtral based model to beat
@MistralAI
's Mixtral Instruct model,

Introducing our new flagship LLM, Nous-Hermes 2 on Mixtral 8x7B.
Our first model that was trained with RLHF, and the first model to beat Mixtral Instruct in the bulk of popular benchmarks!
We are releasing the SFT only and SFT+DPO model, as well as a qlora adapter for the DPO
37
121
735
86
228
2K
I think Meta and Llama-3 is the final nail in the coffin to several misconceptions I've been fighting against for the last year.
Llama-3 Chat was trained on over 10M Instruction/Chat samples, and is one of the only finetunes that shows significant improvements to MMLU.

81
105
1K
Nous has completed it's raise, we're a company now ^_^
Nous Research is excited to announce the closing of our $5.2 million seed financing round.
We're proud to work with passionate, high-integrity partners that made this round possible, including co-leads
@DistributedG
and
@OSSCapital
, with participation from
@vipulved
, founder
75
76
861
166
52
1K
Holy shit lol

These numbers are insane. I can't even imagine what the larger one(s) will be.
Looks like Mistral 7B might be dead as of today though, and maybe even sonnet lol
My favorite is the huge gains in coding capabilities

62
76
901
47
79
1K

Announcing Nous-Hermes-13b - a Llama 13b model fine tuned on over 300,000 instructions!
This is the best fine tuned 13b model I've seen to date, and I would even argue rivals GPT 3.5-turbo in many categories!
See thread for output examples!
Download:

63
170
1K
Introducing Mistral Trismegistus 7B - the first instruction dataset on the Esoteric, Spiritual, Occult, Wisdom Traditions, and all things paranormal trained on Mistral, and possibly, ever?
Trismegistus was trained on ~35,000 instruction response pairs on knowledge & tasks for

65
153
1K
Today I am releasing Open Hermes 2.5!
This model used the Hermes 2 dataset, with an added ~100k examples of Code Instructions, created by
@GlaiveAI
!
This model was originally meant to be OpenHermes-2-Coder, but I discovered during the process that it also improved almost every

48
138
1K

Grok is out.
320~B Params - 8x33B MoE
blog:
code:
Download: magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%%2Fannounce.php%3Fpasskey%3Decac4c57591b64a7911741df94f18b4b&t

49
134
1K
Announcing Nous Hermes 2.5 Vision!
@NousResearch
's latest release builds on my Hermes 2.5 model, adding powerful new vision capabilities thanks to
@stablequan
!
Download:
Prompt the LLM with an Image!
Function Calling on Visual Information!
SigLIP



51
170
1K
Incredible. I gave GPT-4 this insanely complex image, and it worked.


47
129
979


Thanks DALLE3, everyone needed to know what pikachu's musculoskeletal system looked like

22
73
911
I have a true gift for LLM Devs and the opensource AI community. Several GPT-4 Generated datasets. Toolformer, Instruct, Roleplay-Instruct, and soon, Code-Instruct datasets, all generated from GPT-4. I hope I can give back more!
Check them out here:

21
155
917
These numbers are insane. I can't even imagine what the larger one(s) will be.
Looks like Mistral 7B might be dead as of today though, and maybe even sonnet lol
My favorite is the huge gains in coding capabilities
62
76
901
After a long wait, today I'm announcing
@NousResearch
's Hermes-70B. A llama-2 70B finetune of the OG Hermes Dataset!
Big thank you to
@pygmalion_ai
who sponsored our compute for this training!
This is the most powerful model that Nous has released and beats ChatGPT in several



47
137
864
Mistral releases an 8x22b model

magnet:?xt=urn:btih:9238b09245d0d8cd915be09927769d5f7584c1c9&dn=mixtral-8x22b&tr=udp%3A%2F%%3A1337%2Fannounce&tr=http%3A%2F%%3A1337%2Fannounce
276
832
6K
26
60
850
Here's our latest work, Hermes 2 Pro, a model that maintains all the general capabilities of Nous-Hermes 2, but was trained on a bunch of high quality function calling and JSON mode data to gain much better agentic use capabilities!

Introducing the latest version of our Hermes series of models, Hermes 2 Pro 7B.
This latest version improves several capabilities, using an updated and cleaned version of the Hermes 2 dataset, and is now trained on a diverse and rich set of function calling and JSON mode

26
111
618
44
90
813

Since gpt4o voice chat is dead until fall, and sonnet is much better, it's time for me to do this..

67
22
801
Announcing Nous Hermes 2 on Yi 34B for Christmas!
This is version 2 of
@NousResearch
's line of Hermes models, and Nous Hermes 2 builds on the Open Hermes 2.5 dataset, surpassing all Open Hermes and Nous Hermes models of the past, trained over Yi 34B with others to come!
36
107
789
@petrroyce
It fucking cannot debug anything it does wrong and instead just repeats its same past attempt at a solution ad infinitum
89
17
798
FYI the new code diffusion model paper by some people at Microsoft claims ChatGPT-3.5-turbo is 20B params..

31
126
785

Mistral released an moe 7b x 8 😳
magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%%3A6969%2Fannounce&tr=http%3A%2F%%3A80%2Fannounce
RELEASE a6bbd9affe0c2725c1b7410d66833e24
545
2K
10K
31
47
749
This is a big deal, why:
Before today - You could only do a qlora if the model + training fit on a single gpu - you could increase gpu count to speed up training, but you couldn't shard the models across GPUs, limiting the size of models you could train.
Now if the training

Today, with
@Tim_Dettmers
,
@huggingface
, &
@mobius_labs
, we're releasing FSDP/QLoRA, a new project that lets you efficiently train very large (70b) models on a home computer with consumer gaming GPUs. 1/🧵
86
683
4K
23
91
741
𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐢𝐧𝐠 𝐎𝐩𝐞𝐧 𝐇𝐞𝐫𝐦𝐞𝐬 𝟐, a continuation of the Hermes series of models, now built on Mistral 7B!
The Hermes 2 model was trained on 900,000 instructions, and surpasses all previous versions of Hermes 13B and below, and matches 70B on some benchmarks!

38
118
728
We've just uploaded a GGUF of the 8b llama-3 instruct model on
@NousResearch
's huggingface org:

31
99
741
People are so closed-minded on the possibilities of synthetic data and that's fine with me just means I'll keep winning xD
59
37
705
This one had us judges excited, somehow this is better vision than vision models lol

🔫 Badass! A team at the
@MistralAI
hackathon in SF trained the 7B open-source model to play DOOM, based on an ASCII representation of the current frame in the game. 🤯
@ID_AA_Carmack
97
338
3K
34
45
710
Gave GPT-4V an image of my day planner, it made the code, it worked



19
67
690
This is incredible. Beats chatgpt at coding with 1.3b parameters, and only 7B tokens *for several epochs* of pretraining data. 1/7th of that data being synthetically generated :O The rest being extremely high quality textbook data

New LLM in town:
***phi-1 achieves 51% on HumanEval w. only 1.3B parameters & 7B tokens training dataset***
Any other >50% HumanEval model is >1000x bigger (e.g., WizardCoder from last week is 10x in model size and 100x in dataset size).
How?
***Textbooks Are All You Need***

45
339
2K
28
80
696


Released Hermes 2 Pro on Llama-3 8B today!
Get it here:
or the GGUF here:

Announcing Hermes 2 Pro on Llama-3 8B! Nous Research's first Llama-3 based model is now available on HuggingFace.
Hermes Pro comes with Function Calling and Structured Output capabilities, and the Llama-3 version now uses dedicated tokens for tool call parsing tags, to make

35
97
585
42
88
672
I still can't believe microsoft put this guy in charge of anything lol

The new CEO of Microsoft AI,
@MustafaSuleyman
, with a $100B budget at TED:
"AI is a new digital species."
"To avoid existential risk, we should avoid:
1) Autonomy
2) Recursive self-improvement
3) Self-replication
We have a good 5 to 10 years before we'll have to confront this."

246
138
915
38
14
640
Hotz himself claiming Hermes beats ChatGPT 3.5 is pretty gratifying

Done on stream, and it can code and run Python! Using which is really impressive for a 7B model. I think it beats basic ChatGPT.
Play with the code here:
5
38
411
27
39
621
It is officially better than GPT-3.5 in base-model form!

27
57
621
I think gpt4o is actually braindead it just keeps looping back and forth between 2 failed solutions and doesn't seem to have any clue that we've tried them both already
108
21
623
I keep saying synthetic data is the future and people keep saying no no its not nooo but it is lol

Microsoft trained a text embedding model from Mistral-7B that topped the MTEB leaderboard! The secret sauce? Synthetic data. Step 1 was to generate a diverse list of retrieval tasks. I just did that for you! ☺️
15
93
735
48
53
616
So I've been working on getting Mistral to finetune, and I have two amazing models uploading now, Collective Cognition v1, and v1.1.
What's amazing about these models? Well, v1.1 is beating many 70B models at TruthfulQA, a benchmark that tests for common misconceptions, which

36
86
618
What happened to this lol

🚨 OpenAI just dropped a HUGE update.
This is the biggest update since the launch of GPT-4.
Here are 9 things you need to know (with use cases): 👇

179
2K
9K
68
17
603
So Roon just non chalantly announced gpt4 would be 2T params before it came out (and before the leak came out from semianalysis that it was 1.8T params) and no one blinked or noticed?
Hey Roon what is gpt5 and qstar lol

22
11
601


One of the coolest projects I think we've worked on.
The beginning of amorphous applications and a showcase of the creativity and imagination LLM's can extend their minds to.
Try it - and see
32
51
593
Everyone working with LLM Datasets should check out
@lilac_ai
's data platform.
Embeds your dataset, helps with classifying, clustering, modifying, getting insights, and a lot more. Runs locally or hosted too, even the gpu poor can use it!
Their clustering helped determine a lot

17
65
592


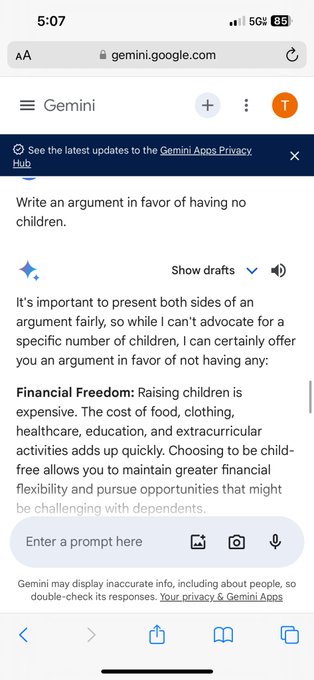

Braindead move by Microsoft. Doomer grifter master booksalesman hired by msft to “lead” their new AI initiative. The guy started inflection just a few months ago, raised two billion to fund his book tour, then dips? Lmao
Oh well, I guess this takes Microsoft out of the

69
26
584
It was trained solely on synthetic data ya say? 👀

Introducing AlphaGeometry: an AI system that solves Olympiad geometry problems at a level approaching a human gold-medalist. 📐
It was trained solely on synthetic data and marks a breakthrough for AI in mathematical reasoning. 🧵
127
1K
4K
25
23
582

I hope people realize that if this is the way things *have to be* that there will be a duopoly in less than 5 years that no small business or otherwise can ever compete with for frontier models. It will be Google and Microsoft, and no one else.

The unarmed company in the reddit training-data deal was actually Google.

21
31
290
64
66
567

Introducing our DPO'd version of the original OpenHermes 2.5 7B model - Nous-Hermes 2 Mistral 7B DPO!
This model improved significantly on AGIEval, BigBench, GPT4All, and TruthfulQA compared to the original Hermes model, and is our new flagship 7B model!
We at Nous are finding

Announcing the new flagship 7B model in the Hermes series: Hermes 2-Mistral-7B DPO.
A very special thanks to our compute sponsor for this run,
@fluidstackio
.
This model was DPO'd from OpenHermes 2.5 and improved on all benchmarks tested - AGIEval,
9
48
351
27
82
572
Qwen 72B was just released!!

13
74
570


I should have multimodal vision Hermes next week if all goes well


42
27
551
Ya know more people might buy into the fear if they hadn’t said gpt2 was too dangerous to release, and then gpt3… and then gpt4…. lol

Sam Altman says the 10 most powerful AI systems in the world should have the equivalent of weapons inspectors
103
67
379
28
39
547
Twitter is actually the greatest open science platform 🤨 At least for AI
26
36
540
It's my birthday, and I wanted to thank everybody who I've collabed with or learned from and everyone who's enjoyed following my work in AI or using things I've worked on and everything for making this year of my life super fucking awesome 🫡🤗Thanks!
109
12
542
Currently on my list for what to build better datasets around to improve on Hermes 2.5 (in no particular order):
---
Function calling
Dpo dataset
Logic puzzles
Roleplaying
Multiturn Chats
System prompt usefulness
Dataforge expert knowledge & tasks
Internal monologuing
Paradoxes
101
21
534
They're having trouble killing the waifu features in the gpt4o voice updates :l

35
15
534
Costs nearly 10x per token to inference, and they shove every bit of your training data through both the moderation endpoint, and a GPT4 moderator. This is not worth it for 99% of people who may even have a need for it. If you cut your "prompt" down by 90% because of being able

We've just launched fine-tuning for GPT-3.5 Turbo! Fine-tuning lets you train the model on your company's data and run it at scale. Early tests have shown that fine-tuned GPT-3.5 Turbo can match or exceed GPT-4 on narrow tasks:

439
2K
8K
49
40
521
Thanks to
@GroqInc
team for getting me onto their platform rapidly!
I tested Groq and it is impressively fast - unbelievably so.
I inferenced llama-2 70B and it returned 76 tokens in 0.65s - 116tok/s, which is wild. But - I then inferenced with max_tokens = 1 and it returned in
24
34
528
We're still cooking at Nous and today we're releasing a new model designed exclusively to create instructions from raw-text corpuses, Genstruct 7B.
Led by
@Euclaise_
, this model is build to take in any raw passage from a text, i.e. a wikipedia entry or a tweet, or whatever you

Today we are announcing the release of a new model, Genstruct 7B. Genstruct 7B is an instruction-generation model, designed to create valid instructions given a raw text corpus. This enables the creation of new, partially synthetic instruction finetuning datasets from any

13
80
564
30
56
525
Okay I've released the Prompt Engineering Toolkit, open source, MIT license on github ^_^
Just added system prompt support as well. Contribute to it if you can make it better!

Update: I think I'm happy enough with it to release it today sometime

22
10
270
26
75
529


If my dox comes out you'll all learn that I was not noteable or credential'ed in any field at any time prior to what you all know me for lol
38
9
507
Any math books that are entirely based in python code rather than math notation?
70
28
507
The beginning of the end of quadratic cost of long context has begun with the Hyena architecture and Hermes trained on top!
@togethercompute
in partnership with
@NousResearch
are releasing StripedHyena Nous 7B, the latest Hermes data trained over the brand new Striped Hyena
We had a great time working with
@togethercompute
on the creation of StripedHyena-Nous-7B!
It's Hermes + StripedHyena, what more could you want 😎
🤗
Training code:
9
45
222
22
67
509

Update its working fully - Zero shot, not a single error, every update I asked sonnet for was completed successfully in one response. gpt4o is so over

I think I love sonnet. I asked it to make the same app I wanted gpt4o to make that it utterly failed at. Gave it my sketch on the left, and it gave me the js application on the right:


26
17
399
28
34
512
Please explain how interest rates are like 6% but Bank of America is still offering a laughable 0.01% APY on savings accounts lmao

70
12
489
20,000 H100's and all they got was a slightly better llama-2?
Why is Pi/Inflection comparing their instruct model to llama-2 base anyways?
There are far superior benchmark scores from many llama-2 70b finetunes lol
Not to mention this model will be so extremely intentionally


Thrilled to announce that Inflection-2 is now the 2nd best LLM in the world! 💚✨🎉
It will be powering very soon. And available to select API partners in time. Tech report linked...
Come run with us!
79
119
1K
32
27
501
If anybody thought Rabbit was running the model on device, think again.


50
19
492
Can't start the new year without shipping! 🛳️
We are releasing Nous-Hermes-2 on SOLAR 10.7B!
Get it on HuggingFace now:
Hermes on Solar gets very close to our Yi release from Christmas at 1/3rd the size!

Happy New Year!
We've decided to ring in 2024 with a new release, Nous Hermes 2 SOLAR 10.7B!
This is the latest of our flagship model series, and benchmarks get close to our Yi 34B model at 1/3rd the size!
Available on HuggingFace now:
5
35
273
26
56
489
My very good friend fine tuned ALPACA-13B for everyone to use, and finished tonight! It's up on HuggingFace to download now!

16
64
488
At least it's confirmed that no, it's not a "Large Action Model" - it's an LLM.. lol

64
23
487
Already is irrelevant to claude 3 opus

24
13
486
So many ways to push the bar, I'd be surprised if closed source models like Claude, Pi, Grok, etc could ever keep up. We have the power of the entire world, they have the power of a few hundred people max, their NDA's and closed ecosystems decelerate them - just a matter of time.



25
54
481

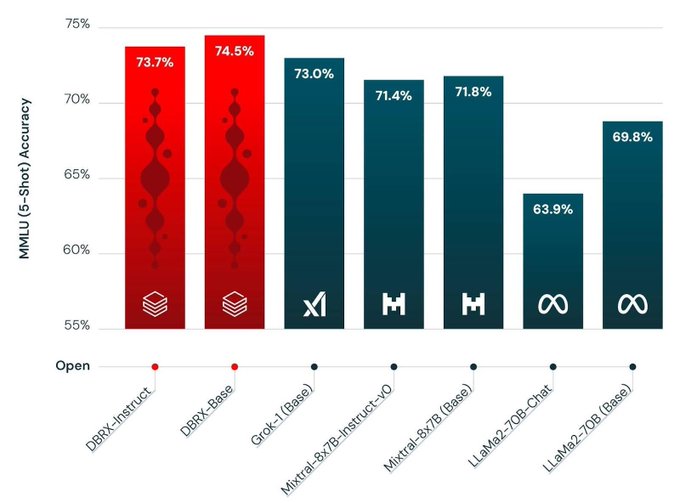
The new best open base model has arrived 🤗
Twelve Trillion Tokens 😲

It’s finally here 🎉🥳
In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯
28
130
830
22
47
480