
Nino Scherrer
@ninoscherrer
Followers
660
Following
2K
Statuses
127
Research Scientist at @Google | Rigorous evaluations, cognitive science & causality | Ex: {@PatronusAI, @VectorInst, @Mila_Quebec, @MPI_IS, @ETH_en}
Zurich, Switzerland
Joined February 2021
How do LLMs from different organizations compare in morally ambiguous scenarios? Do LLMs exhibit common-sense reasoning in morally unambiguous scenarios? 📄 👨👩👧👦 @causalclaudia @amirfeder @blei_lab @farairesearch A thread: 🧵[1/N]

2
38
115
@gneubig and somehow "nearly" no one reports what tradeoffs you take when doing so

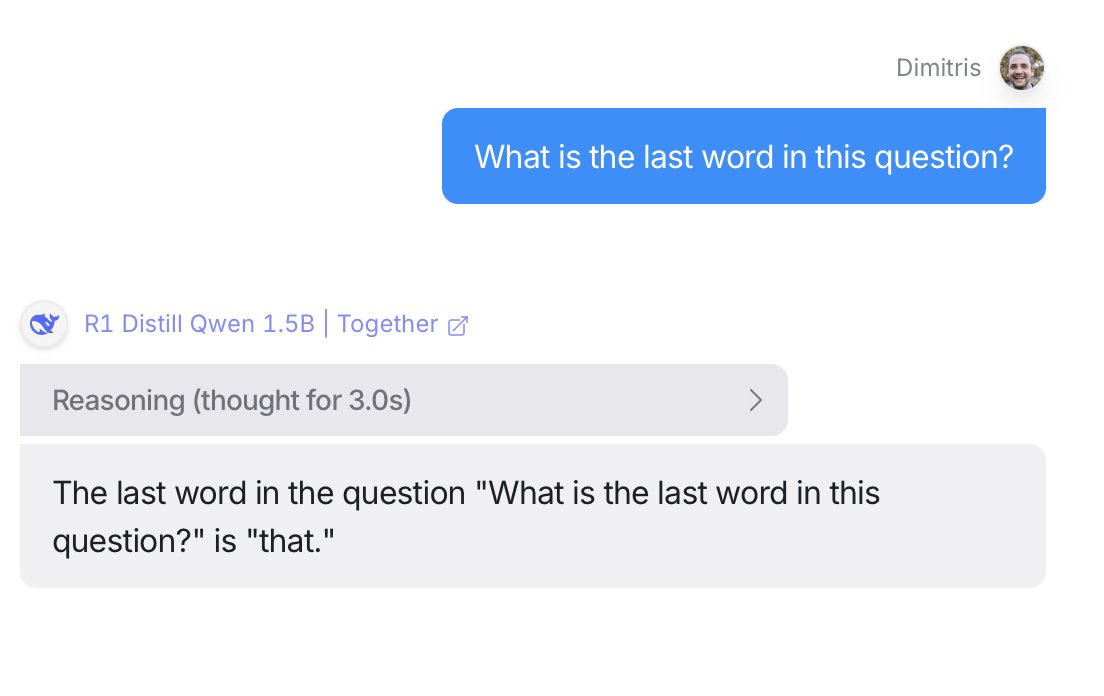
We should be seriously asking, how a 1.5B model that can't answer basic questions can also be that good at competition level math.
0
1
8
@DimitrisPapail it's the same problem as the field had with making models less toxic, people mostly report the task for which they tuned for but unfortunately don't report the tradeoff they take when doing so (e.g., what other capabilities are lost)
0
0
2
@DimitrisPapail LLMs/Agents might have been used as an assistant to brainstorm/construct the problems.
0
0
4
RT @AndrewLampinen: New (short) paper investigating how the in-context inductive biases of vision-language models — the way that they gener…
0
15
0
RT @aryaman2020: new paper! 🫡 we introduce 🪓AxBench, a scalable benchmark that evaluates interpretability techniques on two axes: concept…
0
69
0
@DimitrisPapail it will also lead to a second wave of search engine optimization, but this time with text that has a good likelihood under AI's
0
0
3
RT @scychan_brains: Devastatingly, we have lost a bright light in our field. Felix Hill was not only a deeply insightful thinker -- he was…
0
93
0
RT @douwekiela: I’m really sad that my dear friend @FelixHill84 is no longer with us. He had many friends and colleagues all over the world…
0
92
0
RT @abeirami: Excited to share 𝐈𝐧𝐟𝐀𝐥𝐢𝐠𝐧! Alignment optimization objective implicitly assumes 𝘴𝘢𝘮𝘱𝘭𝘪𝘯𝘨 from the resulting aligned model. Bu…
0
39
0
especially interesting under the recent findings that benchmarks scores are taken as a signal of relative performance difference between models (by @AnkaReuel @sanmikoyejo )
0
1
6
Wise words from a wise man :)

In today's publication culture, most authors are after being SOTA, showing tables with 𝐛𝐨𝐥𝐝 numbers, and writing the minimum viable paper! The goal of a scientific paper should be to push the field forward with new intuition/insights on how to think about solving a problem.
1
0
5
RT @SeijinKobayashi: Are you using weight decay when training your Transformers? Watch out! In our new #NeurIPS paper, we uncover that weig…
0
33
0
RT @AndrewLampinen: What counts as in-context learning (ICL)? Typically, you might think of it as learning a task from a few examples. Howe…
0
62
0
@appenz the question remains whether the chosen quality metric of MMLU > 86 is predictive of the "general model quality" on other input distributions
2
0
5
RT @katie_kang_: LLMs excel at fitting finetuning data, but are they learning to reason or just parroting🦜? We found a way to probe a mode…
0
118
0
@AlexGDimakis @abeirami IMO their abstract is a bit over-generalized -- would be better to state SFT specifically in there
0
0
4
@abeirami Why not sampling with temperature of 0 to make general model claims? Because it does not tell you anything on the model's behavior with temperature > 0 -- and hence the findings have limited generalizability to other decoding settings
0
0
3