
μ
@michalwols
Followers
775
Following
5K
Statuses
3K
I like big vision models. doing DL since 2013, prev CS @columbia, 1st employee @clarifai, @nyufuturelabs, CTO @bite.ai, principal ML @myfitnesspal (by acq)
Greenpoint, NY
Joined November 2011

RT @tsarnick: Yoshua Bengio says when OpenAI develop superintelligent AI they won't share it with the world, but instead will use it to dom…
0
232
0
RT @cloneofsimo: Pytorch docs are sometimes lacking, especially new features lack of real-life code examples. You would read through implem…
0
21
0
RT @vanstriendaniel: Sora-video-generation-aligned-words: A video-text alignment dataset from @RapidataAI - 1500+ evaluators marking misal…
0
4
0
RT @depen_morwani: Excited to share this new work, where we draw connections between theoretical accelerated SGD variants and practical opt…
0
4
0
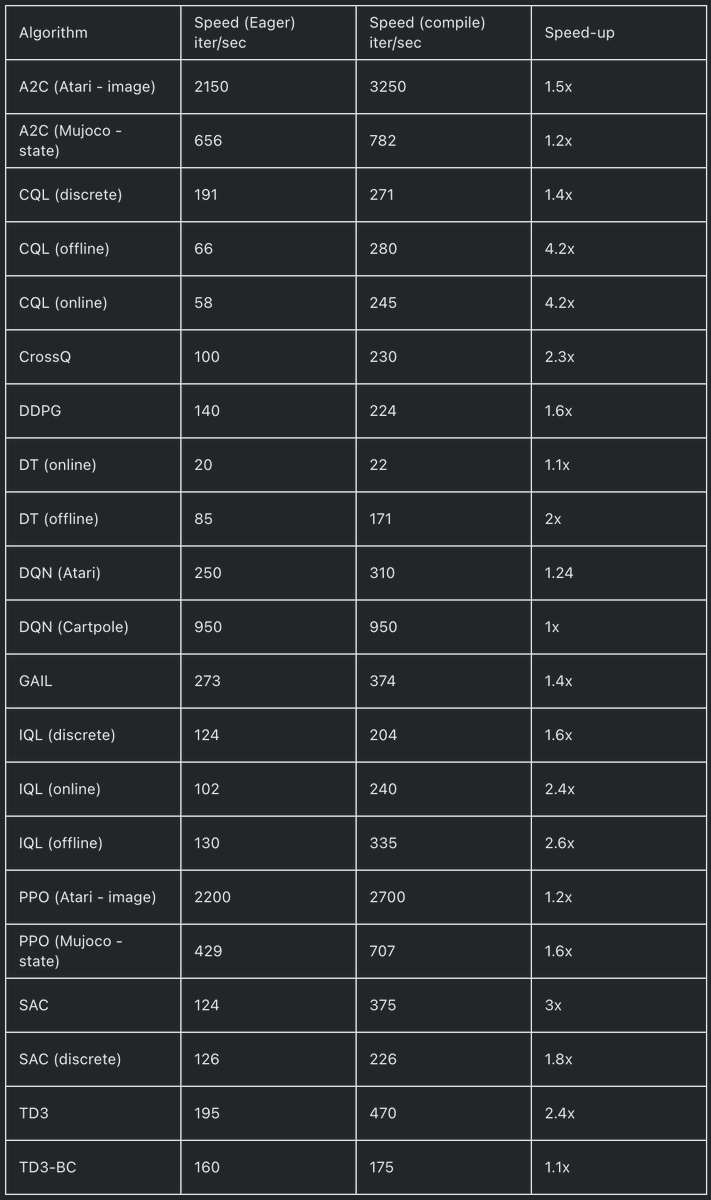
RT @torchrl1: TorchRL 0.7.0 is out! We brought in torch.compile and with it some considerable speedups!

0
2
0
RT @_reachsumit: Can Cross Encoders Produce Useful Sentence Embeddings? IBM discovered that early cross encoders layers can produce effect…
0
1
0
RT @_akhaliq: Llasa Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis

0
22
0
RT @gm8xx8: Ola is an omni-modal excelling in image, video, and audio understanding. It follows a progressive training strategy, starting w…
0
5
0
RT @danielhanchen: We managed to fit Llama 3.1 8B < 15GB with GRPO! Experience the R1 "aha moment" for free on Colab! Phi-4 14B also works…
0
288
0
RT @papers_anon: Metis: A Foundation Speech Generation Model with Masked Generative Pre-training From the Amphion team. Unified speech gen…
0
1
0

RT @MatanLvy: 📄Read more: Btw, who knows the answer? 😁 #ICLR2025 #ComputerVision #VisualPlaceRecognition
0
1
0
RT @cHHillee: Did you know that you can merge two separate attention calls in FlexAttention... and then differentiate through it? Thanks t…
0
23
0
RT @arankomatsuzaki: Masked Autoencoders Are Effective Tokenizers for Diffusion Models - Enables SotA performance on ImageNet generation u…
0
30
0
