

Michael Fester
@michaelfester
Followers
1K
Following
1K
Statuses
350
Building @markprompt: AI infrastructure for customer support (YC W24) https://t.co/PqFFXPukRA https://t.co/FdzQ5SoxRC
San Francisco
Joined June 2009
Excited to announce that @marieschneegans and I are part of the @ycombinator W24 batch! We’re building @markprompt, AI for customer support. 🌟
28
15
121
Once a week, I go for 1:1 meetings on the move with each team member, breaking away from the computer. It's a ritual we never miss. We usually go to Alamo Square Park. Walking side by side, we breathe fresh air, share candid feedback about the most important problems to solve, get creative, and build deeper connections. Breaking the formal meeting structure is key.

0
0
3
Over the past few weeks, we worked hand-in-hand with one of our flagship customers to overhaul the retrieval system behind our Agent Assist drafting functionality. The process? Meticulous and methodical. We carefully distilled each step in the reasoning process, mirroring what a skilled human would intuitively do if they had the time. This included fact-checking, synthesizing knowledge across sources, applying critical reasoning, and reranking outputs to ensure the result was both accurate and contextually relevant—whether it came from past tickets, knowledge bases, standard operating procedures, and custom instructions. The result? ✅ Evaluations against calibration dataset? All passing. ✅ Evaluations across remaining dataset? 95% success, no modifications needed. The second point was particularly exciting—it meant that our system was now able to generalize well beyond what it was tested for. We are now confident it will continue to do so for future, untested scenarios. We will keep monitoring as we collect new feedback, but the blueprint is there. This wouldn’t have been possible without breaking the problem down into manageable, measurable steps, with heavy use of sampling and structured outputs. Combining this with continuous human feedback from our customer, we built a retrieval system that generalizes beautifully while staying true to the content as it continually evolves. When set up right, a carefully designed RAG setup can go further than we had imagined—and we’re just getting started.

1
2
4
Tom @t0m_win flew nine hours during the December holidays to our Markprompt HQ in San Francisco for a hiring trial. The next day (on Christmas Eve 🎄), we made him an offer—and he signed! We don’t hire fast, but when we do, it’s the kind of people we’d bet on a thousand times over. Watching them bring their A-game even before writing a single line of code only helps us build even stronger conviction and excitement. One thing we’ve learned over the years is that great talent rarely falls into your lap—you have to go out and find it. That’s why we spend a lot of time doing outbound, working in close collaboration with our incredible recruiting partners, Steph and Eric, to identify exceptional candidates and reach out directly. In Tom’s case, I proactively messaged him through @ycombinator Work at a Startup (we’re part of the W24 batch). This hiring playbook was a decade in the making. At my previous venture, we scaled our team to 50+ ML researchers and engineers, working on complex, privacy-respecting voice AI, which ultimately led to an acquisition by Sonos. From day one, hiring was our top priority—and one of our greatest challenges. While technical excellence is table stakes, what’s truly difficult is finding people with agency and grit, who ship fast, and thrive in the trenches, solving customer problems day in and day out. This experience shaped how we hire at @markprompt today. So now, when we spot great talent, we go all in. We fly them down to our HQ, where we have space for visiting engineers. These in-person days give us a window into their mental models and whether we share the same work ethic, customer empathy, and striving for excellence. Here is a picture taken on December 23rd during Tom’s trial, hacking with our Founding Engineer Elliot on a very exciting new Grafana integration!

0
3
10
When two of our enterprise clients shared, a couple of weeks ago, that they spent 100+ hours every quarter compiling customer reports based on their support tickets—for their product, engineering, and executive teams—we immediately got to work. The result is now here, in the form of self-serve reports. These aren’t your traditional compilations of CX metrics. These are agents that, among others, - Analyze large volumes of customer interactions - Hone in on specific customers or topics - Extract highly precise actionable information Whether it’s identifying friction points in your product, recurring issues from a likely-to-churn customer, or monitoring a newly released feature closely, you can ask, and we report back. The reception so far has surpassed our expectations!
0
3
13
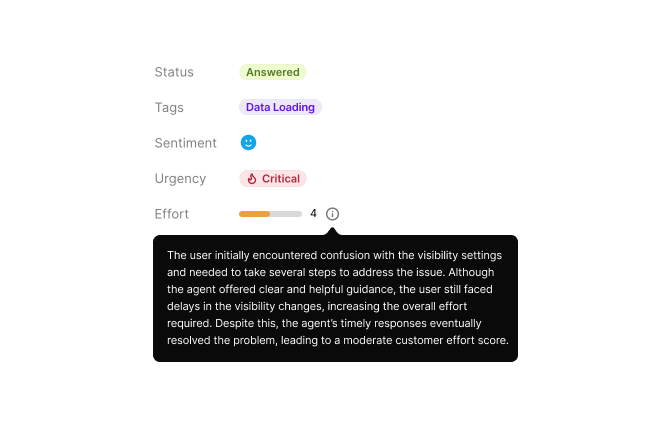
How do you capture the quality of a support interaction? It’s a nuanced question. A short chat can still feel draining, while a longer, step-by-step exchange might actually reduce customers’ effort if it effectively guides them or teaches something new. At @Markprompt, we’re tackling this problem in multiple ways. One of them is using a Customer Effort Score (CES), powered by LLMs. Pre-LLM, traditional measurements either demanded manual review or relied on crude metric combinations. This has some obvious pitfalls: - Fragmented analysis: Counting messages or flagging sentiment often misses the full story. - Rigid models: Fixed scoring rubrics don’t adapt well to evolving behaviors and don’t account for cross-correlations. - Lack of “Why?”: Traditional scores rarely tell why an interaction feels easy or difficult, especially when qualitative factors are linked. In contrast, using LLMs offers a much richer and detailed perspective: - Contextual understanding: Our LLMs read entire transcripts, evaluating multiple aspects—tone, complexity of the problem, time to the “aha” moment, and so on. - Adaptive: The scoring logic can be tailored to the specific factors that matter to you, while omitting others. - Explanatory feedback: Instead of a single score, our LLMs also explain why they gave a particular assessment, highlighting, for instance, the main friction points that led to a high effort score. When tracked at scale, these insights become a clear roadmap for product improvements. In short, that’s how we as humans would look at it—if we only had the resources!
0
2
7
In software, we rely on alerts and telemetry to detect issues in production code. At @Markprompt, we've been thinking a lot about how to create similar safeguards for LLMs. For enterprises, a key concern when using AI in customer service is that LLMs might ignore instructions, especially in highly regulated industries. This is a non-trivial issue, and it is tied to the non-deterministic nature of LLMs. A financial institution, for example, cannot risk a chatbot providing advice it’s not supposed to. Even with clear instructions and strict guardrails, there’s always a possibility that some combination of factors might drive the AI to break the rules. That’s why we are introducing our Policy Violations Detection feature. It covers: 1. Real-time violation detection: Think of it as an integrated compliance officer that immediately flags breaches such as unauthorized information sharing or policy deviations, allowing you to immediately take action. 2. Customizable rulesets: Whether it’s regulatory compliance or internal policies, the system is fully adaptable. 3. Audit-ready reporting: Keep detailed logs of flagged violations and audit trails of policy changes, making it simpler to track and refine compliance over time. We’re excited to see how this new feature will help enterprises maintain tighter control and build ongoing trust in their AI systems.

1
0
6
People often assume that because we run an AI startup, we are striving to automate everything internally ourselves. But honestly, a key driving force for clarity and alignment is our plain old whiteboard. We spend a lot of time in front of it. Together, alone, thinking, debating, organizing. Features to build this week, agent architectures to discuss, customer launches to prepare, business days left in the month. Ticking things off as we go. Then, on Sunday night, while we prepare for the week ahead, we wipe it all clean. This ritual keeps us focused and grounded. The physicality of the medium makes the small wins all the more tangible and worth the daily grind. No AI tool or productivity app can quite match that. Do you have a similar productivity hack?


0
0
11
The last major OpenAI downtime, which happened on Wednesday, lasted 1.5 hours. When you’re running critical LLM infrastructure for enterprise customer support, you can’t sit back and wait for the systems to fix themselves up. Customer support needs to be always on, and fast. Even with 99.85% uptime for OpenAI and 99.64% for Anthropic, there’s no margin for error at @markprompt . Downtimes happen. APIs fail. Systems slow down. It’s the nature of working with LLMs these days. That's why we have robust fallback mechanisms throughout our pipeline. For each model from one provider, we have a second, equivalent model from another provider on standby. And a third one. If the primary model goes offline, or even slows down, our system’s switching logic ensures a seamless transition, so our clients don't ever feel the disruption or sluggishness. For us, the real grind is making sure our clients never have to worry about downtime. That’s what reliability looks like and it’s what we’re building every day at Markprompt.

0
1
8
RT @EffectTS_: Learning Effect by Elliot Dauber, Founding Engineer @markprompt At our October meetup in SF, Elliot shared his experience o…
0
6
0




I am incredibly happy (and relieved!) to share that I’ve just been approved for my Green Card! 🇺🇸
8
0
63
@LukeHarries_ @markprompt Myra I believe - we let our customers choose what works best for them.
0
0
2
@alex_bitko @markprompt Not a bit. This all plugs into our core platform, and offers an additional channel to deploy conversational support agents.
0
0
0
RT @EffectTS_: Lessons Learning Effect – A talk by Elliot Dauber, Founding Engineer @markprompt. Join us at the Effect Meetup in SF on Oc…
0
5
0
RT @michaelfester: One of the things we see consistently at @markprompt is “knowledge base debt” - it’s like legacy code, but for customer…
0
4
0