

Joran Dirk Greef
@jorandirkgreef
Followers
5,163
Following
1,234
Media
112
Statuses
4,259
Founder & CEO of @TigerBeetleDB — the financial transactions database designed for mission critical safety and performance.
Joined October 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Israel
• 4518146 Tweets
Iran
• 3105209 Tweets
ايران
• 1173898 Tweets
Presidenta
• 469251 Tweets
Middle East
• 397775 Tweets
Halloween
• 333796 Tweets
イスラエル
• 137820 Tweets
Wizkid
• 109166 Tweets
John Amos
• 105584 Tweets
Adams
• 95035 Tweets
Davido
• 93316 Tweets
60 Minutes
• 80951 Tweets
Margaret
• 59132 Tweets
Tampon Tim
• 52939 Tweets
#WWENXT
• 50512 Tweets
Moderators
• 48966 Tweets
Raiders
• 46246 Tweets
#VPDebate2024
• 42998 Tweets
からくりサーカス
• 40039 Tweets
ケンタッキー
• 33339 Tweets
Orioles
• 27662 Tweets
Frogido
• 27281 Tweets
Brewers
• 25500 Tweets
Nora
• 17621 Tweets
Giulia
• 14930 Tweets
Roxanne
• 14920 Tweets
FURIA Y LUCHI EN VIVO
• 14703 Tweets
Aces
• 14479 Tweets
#GandhiJayanti
• 14020 Tweets
महात्मा गांधी
• 12875 Tweets
Go JD
• 12686 Tweets
#マックのコーヒー記念カキコ
• 11242 Tweets
Gago
• 10097 Tweets
第三次世界大戦
• 10066 Tweets



















Pinned Tweet

In 2020, we discovered a fundamental limit in the general-purpose DB design for transaction processing.
This led to the creation of TigerBeetle.
Today, I'm excited to announce TigerBeetle's $24 million Series A led by
@natalievais
of
@sparkcapital
.


Excited to announce TigerBeetle's $24 million Series A.
Led by
@natalievais
of
@sparkcapital
with participation from
@AmplifyPartners
and
@Coil
.
25
49
419
63
54
495
“What is a computer scientist?”
Teaching the next generation of computer scientists at my daughter's school.
To share the love of programming—what a joy.


11
16
243
The secret to TigerBeetle’s performance is not:
-
@ziglang
- io_uring
- static allocation etc.
Although these are all important for performance, the extreme 1000x performance technique in TigerBeetle is surprisingly simple:
A complete rethink of DBMS concurrency control.
Why do general purpose DBMS designs increasingly struggle to scale the growing OLTP workload?
Why is the effect counterintuitively worse with horizontally partitioned DBMS designs?
And what does TigerBeetle do completely differently to “unlock” 😎 three orders more OLTP scale?
0
3
40
9
32
243
From the creators of FoundationDB comes…
Antithesis
Deterministic Simulation Testing for the world.
Hard to overstate how big this is for distributed systems—DistSys suddenly became easy.

3
47
232
Some of the most beautiful systems thinking and architecture is in here.


2
23
229
OSTEP is my favorite systems book, up there with K&R.
It's not only by Remzi and Andrea Arpaci-Dusseau, whose own body of work inspired a ton of TigerBeetle, but it's also available completely free online.

implemented a bare bones x86 32-bit kernel in Zig
zig's build system is so powerful, it handles all the linking and even runs qemu
going to continue development on the kernel in parallel with my reading of OSTEP

10
10
355
4
26
212
Redis was my first encounter with databases beyond SQL—the idea that a bag of data structures, an append-only log (and excellent docs with big-O notation) could be useful.
What are some of the interesting (hard) problems you’ve seen solved by Redis beyond SQL?
16
7
196
Some exciting personal news!
I’m thrilled to share that
@Coil
will be spinning
@TigerBeetleDB
out as a startup and that I will be joining the team as founder and CEO.
27
23
165
@TigerBeetleDB
It’s been 2.5 years since
@TigerBeetleDB
began, with a dream to make ledgers more efficient.
Today, I’m excited to announce our Series Seed of $6.4M from
@AmplifyPartners
and
@Coil
, as we look to power the future of financial accounting infrastructure.

19
20
160
This paper was core to TigerBeetle’s design in 2020.
The idea that more than scalability in the cost-agnostic sense (“do more with more”), we should think of scalability also in terms of optimizing the unit of scale (“do more with less”).


2
20
156
Memory is fast becoming the new frontier:
- allocation and fragmentation,
- bandwidth (serialization overhead, hidden memcpy’s, Direct I/O and user space page caches),
- syscalls and context switches
will matter more and more.

Remember when they told you that your code could inefficient since your performance was limited by the speed of your disk?
“Samsung's 990 Pro 4 TB drive offers a 7,450 MB/s sequential read speed and a 6,900 MB/s sequential write speed”
15
13
144
6
19
154
Old faithful back on my desk at the office today (thanks Don Changfoot!).
What I appreciate about OSTEP is not only the design thinking you learn in passing, but the passion and paying it forward.
As the authors quote Yeats:
“Education is … the lighting of a fire”.

5
10
145
Look what arrived in the mail!
Thank you
@unmeshjoshi
for Patterns of Distributed Systems.
Excited to dive in.

0
12
138
We’ve discovered (at least in our own mental model) a common over-specification in consensus, with performance implications.
TLDR: State machine replication, with full durability, can be cheaper than single node “fsync always”—and the same techniques apply to single nodes.
1/8
5
20
134
Systems Distributed '23 is a new conference presented by
@TigerBeetleDB
:
- how to design, build and test systems,
- at work, as a hobby or as a business,
- from chips to compilers to databases and distributed systems,
- in a beautiful city,
- with some special speakers...

4
30
133

The cache eviction algorithm in
@TigerBeetleDB
’s user space page cache is CLOCK N’th Chance (2 bits).
We chose it intuitively, for performance and elegance. It’s a beautiful algorithm that makes sense.
Great to see this recent analysis now, showing that CLOCK can indeed be not

You might have heard about FIFO-Reinsertion/CLOCK being faster and more scalable than LRU. Do you know it is also more efficient/effective with a lower miss ratio than LRU? Take a look at our recent work on HotOS, which studied over 5000 traces collected from the last two
2
17
104
3
20
131
This is the most comprehensive tour of TigerBeetle yet.
We put everything in here:
- LSM optimizations like moving from RUM to RUMBA, and even
- consensus tricks like how a cluster with fsync can rival a single node without fsync (!).
Hope you enjoy.

“Redesigning OLTP for a New Order of Magnitude” by
@jorandirkgreef
at
@QConSF
is out!
A dense deep dive into TigerBeetle’s:
- network
- storage
- consensus
Plus Online General Purpose Processing (OLGP) vs OLTP, and looking ahead to speculative state machine execution.
Enjoy!
1
7
45
1
26
128
This is why I find TCP so hard.
And why we built
@TigerBeetleDB
’s networking instead on a message passing abstraction that makes _less_ guarantees…
The network fault model—indeed, even the boundary (!) between user/kernel space—must be explicit, not leaky.

Thinking about Distributed Systems and Message Loss?!
Although TCP is considered a reliable protocol, TCP will *not* save you!!
📨🕳️👇
#ThinkingInDistributedSystems
#Goals2023

1
25
169
6
12
127
The sheer engineering investment going into
@ziglang
as an extreme systems compiler and language (and what you can do with it already) is staggering.
Fantastic interview by Kris Jenkins with
@croloris
.

Zig might be the most ambitious language we’ve looked at on Developer Voices - it’s trying to replace C, compete with LLVM and be the foundation of the whole compilation story. It’s a feast for language fans…
🎧
📺
6
41
235
1
15
121
In 2015, I was working on a proprietary full-duplex file sync system.
The 1st version failed.
The 2nd version failed.
The 3rd version was perfect.
Rock solid. Surviving scenarios that would fail OneDrive or GDrive at the time and performing on par with Dropbox, albeit with
Enabling assertions in production is a core tenet of TigerStyle, a collection of principles employed at
@TigerBeetleDB
TigerStyle has been instrumental at
@resonatehqio
in crafting reliable software systems

2
5
25
4
11
124
A post on the power of Negative Space Programming and TigerStyle, even a cameo from
@ThePrimeagen
(Thanks Hendrik Nielaender and Felix Brilej for putting this together—great to see the ideas getting out there!)

6
20
118
@vaibhaw_vipul
For developing a “nifty” DistSys toolbox:
- OSTEP by the Arpaci-Dusseau’s is a favorite systems book—the design thinking in here was imbibed by TigerBeetle:
- Hacking bug bounties, finding CVEs, and composing cryptographic primitives (AEADs, HKDF etc.),
2
15
119
This is a deep dive into database durability.
Commemorating the 5 year anniversary of Fsyncgate, almost to the day—and with a twist in the tale...
See you on the 31st for the live chat!
Missed Joran's talk "A New Era for Database Design" from QCon London?
Pivotal moments in durability, I/O, systems languages and testing techniques, and how they influenced TigerBeetle's design decisions.
Premiering on YouTube, Wed May 31 at 9AM PT!

1
15
68
2
15
119
Excited to announce something new for systems programming soon…
3
10
116
@iamatradernoob
@sunbains
Tips for going deep on databases:
1. Pick a conference, like FAST (nice because it’s less DBMS and more focused on the broader hardware/software interactions) and follow the papers/talks from there each year. They might not make sense. Keep chewing the cud.
2. A DBMS at heart
1
20
113
Looking forward to a special stream with
@ThePrimeagen
🙌
Friday, Feb 23, circa 8:30AM PT


Tomorrow stream will be special, CEO and founder of tiger beetle will join us and explain how amazing the database is
20
19
373
5
19
104
One of the things I appreciate most about
@ziglang
is the vision, leadership and stewardship of Andrew Kelley…
…and then being able to support the Zig Software Foundation personally through a simple sponsorship on GitHub.
If you’ve never chipped in…
2
14
105
Incredibly proud of my sister, Ghita, who competes in the Women’s IRONMAN World Championship in Nice, France tomorrow.
#IMWC
#Nice2024
@TigerBeetleDB

5
2
104
This is the most incredible talk I have ever seen.
It was never published.
Until now.
Wed 17th — 11am PT / 2pm ET / 6pm UTC
Join us for a special live premiere.
The stealth talk by Will Wilson of
@AntithesisHQ
that brought the house down at the inaugural Systems Distributed in early '23.
The talk was only ever seen live...
Until now.
Wed 17th
11am PT / 2pm ET / 6pm UTC
4
32
155
1
20
102
This is the secret.
And why we have a zero dependency policy for
@TigerBeetleDB
given it’s foundational and that any performance faux pas add up.
There’s a time and a place. However, dependencies introduce not only safety risk but also performance risk, and we need to own this.

Breaking news: computers can be fast when you aren't forty two billion abstraction layers above the CPU instructions.
6
56
569
1
9
100
I'm excited to speak at
@QConSF
this Monday:
“Redesigning OLTP for a New Order of Magnitude”
Some thought-provoking OLTP and Scalability questions in here, with I hope some surprising (and defining) answers!

0
15
97
Hard to convey that feeling when you switch on a Deterministic Simulator for the first time.
This bug requires:
- multiple view changes, along with
- delayed disk writes,
- concurrent requests,
- successive crashes, and
- perfect timings (!)
to reproduce, plus assertions and online verification to detect.
This is the magic of Deterministic Simulation Testing.

4
17
158
1
12
97
@sunbains
@gesalous
@LewisCTech
At TigerBeetle, we like to make decisions on the basis of reasoning from first principles, drawing from research, and optimizing for quality and total cost of ownership—as opposed to making technological choices by appealing to authority or appealing to popularity (so common in
2
12
93
Direct IO can easily be misunderstood:
- Is it slow (if you use it wrong)?
- Is it fast (if you use it right)?
- Is it required for database durability?
There's plenty of anecdote (art and skill) around the first two questions (which come down to how you think of memory
2
16
92
A pleasure to read this over my morning coffee, and see TB next to heroes like Scylla, Seastar and Redpanda.
Glauber's writing on io_uring (already in 2020) made an impact on
@TigerBeetleDB
, and his advice here (to do meaningful open source) is also our secret...


Most of the career advice I see on this platform is not applicable to systems level software (OS, compilers, etc).
As I promised a cpl of weeks back, here's some tips from my career on how to develop your own career, including a real life story of how we hired
@iavins
:
12
41
273
1
11
85
One of my favorites. Because once you know how to optimize for the network, you can apply some of the same big ideas to disk, and then even memory.
Right up there, along with OSTEP.

High Performance Browser Networking is one of the most high-value books you can read as a programmer IMO.

17
111
1K
2
7
81
I see static memory allocation and
@ziglang
’s explicit allocator strategies as a sea change in systems programming:
“The gap between processor speeds and memory access latencies is an ever-increasing impediment..”
“…depending on the allocator, the performance can vary by 10x.”

“Just like a baby in a big family, the memory allocator is growing up. Time has come when we need to give it a new room (core) in our house (CPU).”
2
14
43
4
13
82
My old favorite is ZFS.
I learned so much about databases… from a filesystem.
Most of all, it was that spirit of ZFS that brought us together as a team to do
@TigerBeetleDB
today.


What’s your preferred
#database
of choice? No shame. No judgement. Just curious which one and why.
I’ll go first. Mine’s sqlite because of the low overhead so it’s trivial to get going. Plus, it handles more than enough traffic for my needs.
You?
42
3
50
6
9
81
Enjoying my copy of Database Internals in NYC before heading home...
(Thanks
@ifesdjeen
for your most valuable signature! 😉)



1
5
78
We use
@ziglang
comptime to compile our VSR consensus and LSM storage engine for
@TigerBeetleDB
’s data types to:
- reduce L1-L3 churn with zero copy deserialization, and
- eliminate length prefixes in disk/wire/cache formats to reduce write amp/bandwidth/memory usage.

I wonder how fast a database would accelerate if it was recompiled to be hard coded against the data model it serves. I know there’s optimizers that do JIT like compilations but the DBMS still has a ton of CPU branch predictions for decisions & lookups before the query itself
29
5
153
1
11
76
@ThePrimeagen
Zero deserialisation with
@ziglang
’s bitCast and cache line-aligned fixed-size structures.
Less is more.
3
4
74
Indeed.
TigerBeetle would not have been possible without being designed (from the beginning) as a Deterministic Distributed Database.
And now, having tasted the quality of Deterministic Simulation Testing (FoundationDB showing the way), we wouldn’t want to go back…

@isamlambert
Obligatory
@TigerBeetleDB
/ VOPR reference, but agreed for the most part.
Seen too many outages coming from trying to make existing SQL engines “distributed” and serverless, not worth the risk to try sometimes
0
1
11
2
12
73
We leverage
@ziglang
’s comptime in
@TigerBeetleDB
’s LSM-Forest to:
- generate LSM-Trees for different key/value types,
- eliminate key/value length prefixes, and
- optimize for the different “churn” workloads of different key/value types

Zig has a brilliant metaprogramming system that subsumes generics.
There are no type parameters, just value parameters, and types simply happen to be value parameters that are passed at compile-time.
Here's a generic 'max' function that works on any type:
fn max(comptime T:
12
6
101
2
6
73
One of the things that excited us in the creation of TigerBeetle was the lucky timing.
The opportunity to shine a spotlight on the incredible storage fault research by UW-Madison.
For the distributed database to embrace an explicit storage fault model and solve it with

You ever see the same term pop up in a few places and think "hmmm"?
@TigerBeetleDB
often talks of "fault models". Wonder if theres more to this idea than I think.
(Paper is "A Transaction Model", Jim Gray, IBM Research Laboratory 1980)

0
2
32
2
7
74
TigerBeetle’s LSM compaction is “the beating heart” of the database.
Bringing together ideas at the intersection of global consensus protocol and local storage engine.
matklad will present TigerBeetle’s LSM-Forest compaction at
@P99CONF
- storage determinism across replicas for faster recovery from disk faults
- perfect pacing to solve write stalls for predictable P100s
- and with static memory allocation
0
3
44
0
6
74
TigerBeetle is (and has been) massively shaped by having a clear set of technical values.
“Safety, Performance, Developer Experience”
These are TigerBeetle's technical values. Why these? And why have technical values at all?
Content Warning: More philosophy of software design than usual!
Join matklad live ⚡️on Twitch now.
0
2
24
1
4
69
Surreal to sit next to
@RattrayAlex
(at a dinner hosted by
@natalievais
on Wednesday):
- whose HN comment encouraged me to open source a security tool,
- leading to work with Microsoft, then
@Coil
on the Gates Foundation
@mojaloop
switch,
- from whence sprung
@TigerBeetleDB
!

Small world; I (~rattray in the screenshot) met
@jorandirkgreef
(~jorangreef) randomly at a dinner, and he recognized my name from an hn comment 5 years ago.
Apparently it led to a chain of events relating to the founding of
@TigerBeetleDB
, which is some extraordinarily cool
3
4
58
3
7
68
Something rare in TigerBeetle is:
- not so much that execution is deterministic (it is, for DST)
- but that storage on disk (!) is also logically deterministic across machines
- which TB verifies, even across upgrades.
Join matklad to discover TB’s Deterministic Recovery.

TigerBeetle implemented compaction for log-structured merge trees using only static memory location and guarantees identical data files across all the replicas. Find out how
@TigerBeetleDB
did it at our free and virtual
#P99CONF
on Oct. 23-24.
#ScyllaDB
0
10
49
1
11
68
Writing your own event loop over io_uring is such an awesome way into systems, with io_uring’s unified first-class API for async disk and networking.
Shoutout to
@axboe
for making single-threaded control planes cool again 😎
In our latest post, consider a tale of I/O and performance.
Starting with traditional blocking I/O, and working up to a libuv-style event loop, we explore TigerBeetle's (and
@oven_sh
's!) I/O stack.

0
18
90
2
12
67
@AndreyPechkurov
@ThePrimeagen
@ziglang
Starting on the design for TigerBeetle in 2020, I had this gut feel from prior work that it would be a good principle...
Always to think about alignment throughout the data plane:
- as you recv() data from the network,
- then write() to disk (with 4 KiB alignment for DIO, even
4
7
64
Deterministic Simulation Testing is not only Fred Brooks’ “silver bullet” in terms of developer velocity…
… with simulators such as
@AntithesisHQ
, it’s also the beginning of a “post-Jepsen” era for distributed systems.
@richardartoul
explains why:

1
17
66
Sound check done!
Excited to speak at
@money2020
Amsterdam tomorrow on The Next Thirty Years of Transaction Processing.
Thursday, 11:15am
Mastercard Horizon Stage

8
3
65
And we’re on our way from NYC to Cape Town for Systems Distributed ‘23! ✈️
(Where’s Andrew Kelley?)
@ziglang

5
2
65
All thanks to
@ziglang
. And TigerBeetle uses the same technique also for IO, Messaging and Time.
Anything non-deterministic, so that TB can test and simulate deterministically, plus accelerate time when testing.

Brilliant pattern by
@TigerBeetleDB
and
@ziglang
: pass an allocator only as a parameter, so you know if a function allocates just by looking at its params. I fully recommend the whole talk!
0
3
40
0
3
65
Amod Malviya, Co-Founder of Udaan and former CTO of Flipkart, is not only one of the clearest thinkers, but also one of the most generous, with a passion to pay it forward to the next generation of systems engineers.
Join us live on Monday for Amod’s talk from
#SD24
, Systems
Is systems engineering on a path of resurgence?
Join us this Monday for the live premiere of Amod Malviya’s talk from
#SD24
.
10am PT / 1pm ET / 7pm CET
1
5
47
0
8
65
When we started
@TigerBeetleDB
, I never imagined someone would describe this as a quest to “build the perfect database”.
Thanks to Kris Jenkins for having me on the show, to imagine a world where databases are planes, and testing is a flight simulator…
…safer for the pilots!!
How far would you go to build the perfect database?🤔
Let's go down a rabbit hole of performance problems, fsync gotchas and network reliability myths that may only get fixed with a new approach, and some smart testing… 🧪
🎧
📺
1
3
33
1
7
64
We flew a kite for systems programming.

1
9
62
This is why TigerBeetle’s global consensus protocol and local storage engine were co-designed:
- not only to share the WAL, but also to
- run directly on a raw block device
- without requiring a filesystem

Log stacking can happen when using Raft/Paxos to replicate DBs w/ their own WALs. Apache Kudu consolidates: the tablet WAL is also the Raft log. There have been experimental in other systems by disabling local WAL and using consensus log for recovery. Is there a generic solution?
6
6
49
0
8
63
We've connected TigerBeetle's deterministic simulator, The VOPR, to GitHub—to open issues automatically, classify bugs as { correctness, liveness, crash } and basically write a nice report.
This (and more) in our April newsletter... 📰

Our April newsletter is out! Read on for a ton of detail into all the code changes happening in TigerBeetle!
1
4
19
2
8
61
An accidental memcpy, buried somewhere in TigerBeetle's data plane:
- burning memory bandwidth,
- thrashing the L1-L3 cache, and
- destroying performance,
is something we think about...
And now verify, with a new character in the TB Cinematic Universe... CopyHound!
matklad has a super power he wants to share with you.
This is the super power: LLVM IR is text.

1
13
75
0
2
60
“Make it work, make it fast, make it pretty…”
…but design first!
(Because back of the envelope gets you to a better maxima)
You want to be staring up at the slopes of Mount Doom before you start the ascent.

2
11
56

@iavins
If you want something that’s faster to construct than XOR / Binary Fuse Filters (e.g. if write-intensive), and simple to intuit/implement as a middle ground, plus significantly faster than Bloom Filters…
…then take a look at the Split Block Bloom Filter in Apache Impala, which
2
8
56

And what if a disk was a distributed system?
- With latent sector errors (LSEs) partitioning you from performing I/O to a particular block/sector, temporarily or permanently?
- Or firmware/filesystem bugs sending your I/O but to the wrong address?
What algorithms would we use?
"Wait, it's all Distributed Systems?!" "Always has been"
Inspired by distsys astronaut
@ktosopl
🛰️

3
5
34
2
2
56
Most LSMs design the in-memory table for inserts, scans and lookups (after probing the cache).
The insight here is to NOT use the in-memory table for lookups, but only as a k-way log for inserts/scans.
And then use only the cache to serve lookups, since hash maps are optimal.
The in-memory data structure of an LSM-tree is hard to optimize:
- Do you design for point lookups?
- Or scans on the read path?
- Do you optimize for inserts on the write path?
- What about k/v caching?
- And undo?
PR 1180 has new TigerBeetle ideas...

2
4
54
1
3
55
If you’ve ever wanted to walk through TigerBeetle’s code... this is the perfect way to do it.
Tune in. We’re going deep!

Don't miss the 3rd show of IronBeetle🤘with matklad!
Live on Twitch today at 9am PT / 12pm ET / 5pm UTC.
(And if you missed the 2nd, well... here it is!)
0
1
18
3
10
54
“The story illustrates why our software is slower than it should be. We have layers of abstractions to fight against. […] It is a matter of architecture.”
Great thread from Daniel Lemire on how better architectures, from first principles, can unlock order of magnitude wins.
The fast JavaScript runtime Bun is much faster than Node.js 22 at decoding Base64 inputs. By much faster, I mean *several times* faster. But they both rely on the same underlying library (simdutf) for the actual decoding.
So what gives?
The problem is that Node.js needs to



35
253
2K
1
9
54
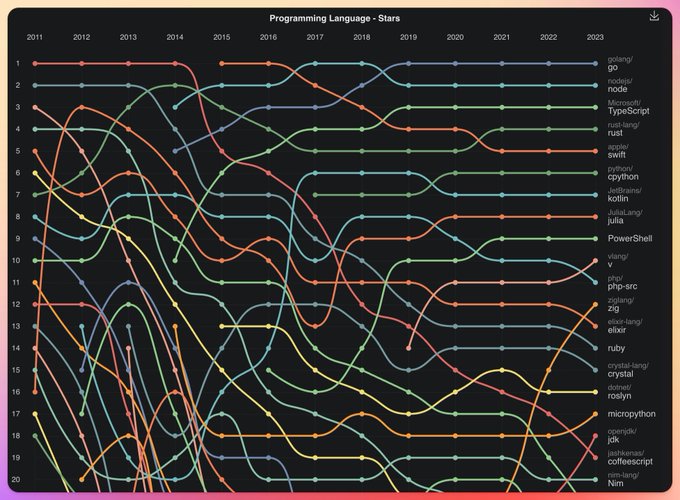
Look at that little orange line go… 🧡

The ranking of attention to open-source programming language repositories shows that Go, Node, and TypeScript maintain the top three positions. CoffeeScript is declining the fastest, while Zig is rising the fastest. Swift, which ranked first in 2015 and 2016, has dropped all the
4
26
90
0
4
54
The decision to embrace VSR’s message passing for TigerBeetle was valuable and subtle:
“Use the simplest building blocks you can, and then push control flow (and guarantees) up.”
We learned this from networking, to follow the end-to-end principle.
Why would Message Passing be superior to RPC for implementing consensus protocols?!
Couldn’t we simply reason about remote procedure calls in terms of two messages being passed, a request and a response?!
System Model
We will think in terms of two layers, the application

0
3
19
1
10
55
In our own experience with TigerBeetle, the most valuable thing that static allocation gives you (beyond the many performance and safety benefits)…
…is that it forces the developers of the DBMS to think through what we call “the physics of the database”.

@LewisCTech
@DominikTornow
@ziglang
@TigerBeetleDB
Static allocation upfront is probably the best way to write database (any?) software. InnoDB was written using this strategy. It was changed to dynamic allocation for some transient data in 5.1 IIRC. Once you let that genie out there is no going back, it slowly leaks everywhere.
2
1
12
5
4
53
Here’s a rough principle of scaling, in terms of linear/exponential resources, that I’ve been working on:
“The decision to linearly scale an exponential resource (e.g. CPU under Moore’s Law)… by introducing communication overhead (e.g. across the network)… becomes twice as
2
4
52
The Animal Database Alliance
#QConLondon
:
@redpandadata
’s
@jcsp_tweets
and
@maslankamichal
@duckdb
’s
@hfmuehleisen
@TigerBeetleDB
and our friends
@_belliottsmith
and Aleksey
Topics: “ECC”, work-stealing costs, and Hannes’ boat strategy for the Netherlands’ rising sea levels

2
9
53
There’s a moment in his talk when Andrew Kelley does a street poem about C++…
…in fact, so many incredible things in here (like writing an audio visualizer just to find a bug).
Excited to watch and take it all in and be there in the live chat this Monday.
SD'24 is happening again!
This time online.
Join us this Monday for the live premiere of Andrew Kelley's opening talk from
10am PT / 1pm ET / 7pm CET
3
36
180
1
5
52
Excited for our new
@TigerBeetleDB
blog post tomorrow.
@eatonphil
@kingprotty
Y’all got some smart people over there. 🥳 Your tech content is top notch, I’m excited anytime there’s a new blog post or talk.
0
1
23
3
3
53
That a distributed cluster can:
- run incremental, perfectly paced, and just in time compaction,
- to produce a logically byte for byte identical data file across machines,
- even across different binary versions,
is something about TigerBeetle we look forward to sharing.
.
@TigerBeetleDB
's compaction algorithm achieves full storage determinism across replicas and highly concurrent implementation. Learn how to use all available IO resources without starving normal transaction processing at
#P99CONF
.
#ScyllaDB
#devtalk

0
2
20
0
11
53
The year has gone faster than I could have imagined.
So many adventures, and yet more to come!
Cheers to everyone for your support.
Yesterday we celebrated TigerBeetle’s 1st birthday as a company—a year since we took the leap and left the Shire!
It’s a joy to be part of the fellowship with you all, and we’re looking forward to the year ahead...
“It’s going to be an adventure!”

2
5
76
5
1
52






If you could paint a database from first principles, for a write-heavy workload with extreme contention...
- How do you rethink networking to solve row locks and memory bandwidth?
- Do you use 1 LSM-Tree or 20?
- And can you apply speculative CPU techniques to consensus?

Our
@QConSF
talk is on YouTube!
- With the world becoming 3 orders of magnitude more transactional in the last 10 years,
- how can we take the 4 primary colors of systems (network, storage, memory, compute),
- and blend them into a new design for OLTP?
1
6
35
0
6
50
I find it fascinating that, for example Deterministic Simulation Testing (and the ability to accelerate the time of the system under test) is enabled almost entirely by the right abstractions.
The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise
-Edsger W. Dijkstra

4
22
119
1
3
50
This is what we at
@TigerBeetleDB
call “Edge”.
“The ability to make quality technical decisions from first principles, without being pressured by (or appealing to) popularity.”
We learned this from
@jamwt
@jamesacowling
@sujayakar314
(early adopters of Rust at Dropbox).

The best video so far (s/o
@jorandirkgreef
) on the what/why, and the wild ambition of Convex. We've taken some crazy bets against convention that feel very un-crazy after just a few hours building on our platform.
A big change is coming, and we aim to lead it.
1
3
15
0
7
50
DBMS gravity has inverted.

"This shift in hardware balance is probably the biggest change to fundamental assumptions in database architecture since SSDs started to become a thing, and most people haven't internalized the implications yet." -
@jandrewrogers
The race now is to optimise for latency.

9
36
221
3
6
50
Checking your model but against the actual code (and in accelerated time) means you can move so much faster.
It's also fun.
How do you catch up (and overtake) 30 years of test time?
- We've ramped to 100 CPU cores.
- 100 simultaneous TigerBeetle simulations, 24x7.
- Each simulation (in 3.3 seconds) tests 39 minutes on avg. of real world runtime.
10 cores = 20 years
100 cores = 200 years (every day)
1
18
115
3
9
49
It's been a special month at TigerBeetle.




June in TigerLand is out!
- The Next 30 Years of OLTP at Money 20/20 in Amsterdam,
- Systems Distributed ‘24 in NYC,
-
@ziglang
0.13.0,
- reduced memory, fixes and speedups,
- the Nasdaq tower in Times Square,
- and moments with friends, old and new.
0
6
27
0
2
49
Taking
@rbatiati
to see the cave on Table Mountain where I spent those 15 years coding before
@TigerBeetleDB
😎

5
1
49
Protocol-Aware Recovery's findings impact:
- DBMS WAL designs,
- LSM trees “bolted on” with off-the-shelf consensus protocols like Raft, and
- formal proofs that verify components like consensus protocols and stable storage in isolation.
Join us for the live interview...
Join us live on Twitch tomorrow, August 9th at 9am PT, as we discuss the ins/outs of Protocol Aware Recovery with the authors of the paper, Prof. Ram and Aishwarya!

2
8
26
3
7
47

The storage fault-tolerance in TigerBeetle has some of our favorite algorithms…
…join matklad for a tasting tour.
How a database with storage fault-tolerance stores data on disk might seem complicated at first, but it actually can be easy.
In today's episode of IronBeetle, we start looking at the on-disk data structures:
0
15
73
1
8
49
What are the toughest distributed systems to build?
23
5
48
@halvarflake
With TigerBeetle, it was refreshing to go back to recv/send…
…enforcing little endian, fixed size cache line aligned structs, and then casting bytes off the wire for zero-deserialization.
3
5
46
Beyond performance, the 2nd order effect of an engineering culture of static memory allocation can be powerful (and positive):
PR authors think through “the physics of the code” they contribute.
This deep understanding is so valuable (and the policy viral in achieving this).

even among performance minded folks, there's a persistent myth that malloc is "pretty fast" when in fact it's so performance hostile that big game productions ban it at link time, to eliminate the damage it causes
17
20
196
0
2
45
I love the Bitcask design.
Implementing a version of it years back was one of my first forays into storage systems.
We also use the pattern in
@TigerBeetleDB
to track all the tables in our LSM manifest, to log them to disk as they get created/compacted.

Beautifully simple and remarkably similar to Kafka’s early persistence layer.
1
4
39
3
4
45
@sunbains
To be clear, Deterministic Simulation Testing is more than simply fault injection or chaos engineering (common misconception).
To do DST, the “system under test” itself must also be written 100% deterministically.
Very few DBMS systems (I know of only 3!) actually do DST.
And
2
12
45
The trick in here, to compile Go to WASM to defeat non-deterministic scheduling, is a nice DST hack!

📖 Today on our blog: Learn how
@asubiotto
implemented (Mostly) Deterministic Simulation Testing for FrostDB using Go! It's pretty cool! 🧊
1
20
53
0
3
45
Fsyncgate marked the beginning of a new era for database design:
- DAIO and
@axboe
's io_uring
-
@ramnatthan
's “Protocol-Aware Recovery”
- Explicit systems programming and
@ziglang
- Deterministic simulation testing
Premiering tomorrow at 9am PT:

This is a deep dive into database durability.
Commemorating the 5 year anniversary of Fsyncgate, almost to the day—and with a twist in the tale...
See you on the 31st for the live chat!
2
15
119
0
9
44
@forked_franz
@fleming_matt
@AndreyPechkurov
@ThePrimeagen
@ziglang
Yes,
@TigerBeetleDB
was inspired by
@mjpt777
here, with his
@QCon
talk on the “Evolution of Financial Exchange Architectures”.
It came out right as we were in the middle of the “sketching” phase, and helped nail down some of the design decisions.

1
9
43
This follows my own optimization journey.
First, it was minimizing network requests with CRDTs back in ‘12, then random seeks with spinning disk, and then optimizing memory accesses for erasure coding, and now TB.
Network or spinning disk is a great way to think of memory.

After databases that optimise for spinning disks (Cassandra) and flash storage (Aerospike) now we are optimising for RAM allocation. In a way we are back to the basics.
TigerBeetle is written in Zig just like bun.js, the node.js alternative.
0
1
12
1
6
43