

DuckDB
@duckdb
Followers
18K
Following
3K
Media
215
Statuses
844
DuckDB is an analytical in-process SQL database management system. "DuckDB" and the DuckDB logo are registered trademarks of the DuckDB Foundation.
Amsterdam, The Netherlands
Joined May 2019
We are proud to release the first major version of DuckDB, v1.0.0, codenamed "Snow Duck". This version is a culmination of almost six years of research and development. Today we are shipping an innovative database system with a backwards-compatible storage format. Check out our

24
283
1K
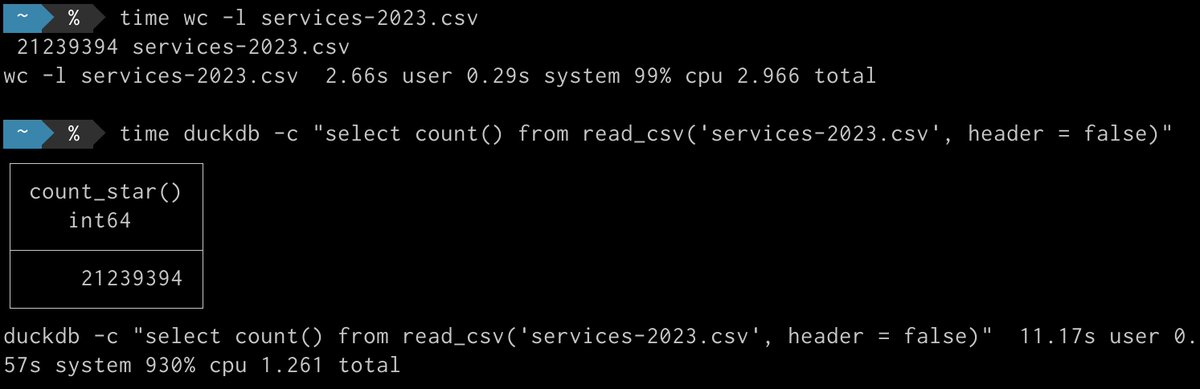
Fun fact: DuckDB is faster at counting the lines of a CSV file than the UNIX word count command – and it also parses the file to identify its dialect (separator, quote character, etc.). Here are the timings for a 3 GB CSV file: 2.966 seconds for `wc -l` and 1.261 seconds for
14
57
522
New blog post by @mraasveldt: Multi-Database Support in DuckDB. DuckDB can now attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a

9
82
348
DuckDB was recently covered in @andy_pavlo's Advanced Database Systems course at CMU. The lecture covers DuckDB's history, internals, and integration with other systems. Slides: Recording:




1
66
351
We are proud to announce that DuckDB's co-creator, Prof. Dr. Hannes Mühleisen, received the Dutch Prize for ICT Research 2025. This prize is awarded each year to a computer scientist in the Netherlands, who has conducted particularly innovative research in CS within 15 years of.
3
22
283
We are happy to release DuckDB v1.1.0 “Eatoni”. The new release packs a ton of new features: friendly SQL extensions, performance improvements and spatial features. It also includes improvements towards supporting Community Extensions. See our blog post:

5
67
273
We are proud to release DuckDB v0.10.0: Some highlights:.– A reworked and much faster CSV reader.– Fixed-length arrays.– Multi-database support.– Secrets manager.– Temporary memory manager.– Adaptive lossless floating-point compression.– New CLI editor.–

1
60
264

DuckDB 0.7.0 "Labradorius" released with #JSON support, parallel and partitioned export to CSV and Parquet, UPSERT, @DataPolars integration, and much more in our release announcement blog post:
8
51
253

Did you know that Google Colab has DuckDB as a preinstalled package since mid-2023? It also receives regular upgrades and is now on version 1.1.0.

3
29
243
We wrote a performance guide for DuckDB users! This guide covers topics such as the effects of schema (constraints, indexing) and hardware (CPU, memory, disk). We also share best practices for querying Parquet files and tips for tuning your workload.

1
42
210
New blog post: Access 150k+ Datasets from Hugging Face with DuckDB. This blog post, co-authored by the @huggingface and DuckDB teams, describes how you can use the hf:// prefix in DuckDB to access datasets in Hugging Face repositories. Read more at

4
56
216
We started a series of blog posts called “DuckDB tricks”. In these posts, we will present some useful shorthands, hacks, and design patterns for DuckDB. In the first part of the series, @szarnyasg explains some techniques for handling floats, fine-tuning the CSV reader, and

6
37
211
DuckDB has introduced native Delta Lake support. In our new blog post, @samansmink walks through the design and implementation of the new Delta Lake extension. Read more at

6
36
210
We just released DuckDB 0.9.0 "Undulata", check out our release announcement blog post:
2
40
204
New blog post by @mraasveldt:.Memory Management in DuckDB. This blog post explains how DuckDB manages memory. It covers streaming execution, spilling intermediate results to disk, and the buffer manager. Read more at

0
43
181
New blog post by @szarnyasg:.Command Line Data Processing: Using DuckDB as a Unix Tool. This blog post shows how DuckDB stacks up against classic Unix tools (such as cut, grep, sort, and sed) when performing simple data processing steps. Read more at

1
50
179
📣 We launched the DuckDB Community Extensions repository, which allows secure distribution and installation of third-party extensions. To install a community extension, simply run:. INSTALL extension_name FROM community;. For details, see our blog post:

1
26
178
DuckDB's co-creator, Hannes Mühleisen, recently became a professor of data engineering at Radboud University. The recording of his inaugural lecture, titled "The Ancient Art of Data Management", is now available.
1
27
177
New blog post by @__AlexMonahan__:.Benchmarking Ourselves over Time at DuckDB. The DuckDB team's philosophy is to first ensure correctness, then iterate and optimize to improve performance. This blog explores how this happened over the last three years, when DuckDB became

5
36
176
The latest DuckDB book, published by O'Reilly, is available in print. We ordered our copy and received it today. Thanks to Wei-Meng Lee for his educating readers on how to use DuckDB!

1
21
203
DuckDB 0.6.0 "Oxyura" released with improved storage, higher performance for CSV loading and indexing, new SQL syntax, better memory management, shell tweaks and so many new features @mraasveldt wrote a separate blog post to explain it all:
4
40
161
A copy of the “Getting Started with DuckDB” book – authored by @SimonAubury and @nletcher, and published by @PacktPublishing – just arrived to the @duckdblabs office! Congratulations to the authors on publishing this book.

3
16
160
New blog post:. Query Engines: Gatekeepers of the Parquet File Format. In this post, Laurens Kuiper argues that we are wasting a lot of bits by not using the Parquet format to its full extent – a limitation caused by the lack of support for Parquet features in some systems.

5
39
195
DuckDB supports querying buckets in the AWS S3 Express One Zone. Read the related guide at which shows that DuckDB can read a Parquet file from an S3 Express One bucket at about 1.2 gigabytes per second!. PS: You may also noticed that we started rolling

2
31
148

DuckDB 0.5.0 "Pulchellus" released with persistent indexes, out-of-core hash join, new join order optimizer, and many other improvements
1
27
143
New blog post by @__AlexMonahan__:.DuckDB in Python in the Browser with Pyodide, PyScript, and JupyterLite. In this post, Alex explains how you can set up a fully in-browser DuckDB notebook in seconds using Pyodide.

2
27
146
The DuckDB repository hit 15,000 stars on GitHub today. Thanks to our contributors and our amazing community!

0
3
136
We have revamped one of our core operators, aggregation. It has improved scalability for many unique groups and for a large number of cores. Thanks to these, you can expect better performance when running large aggregations on big machines.
1
17
132
New blog post by @__AlexMonahan__. SQL Gymnastics: Bending SQL into flexible new shapes. In this post, Alex presents pure SQL queries to implement dynamic groupings and aggregate functions using DuckDB's friendly SQL extensions. The queries can be used to

1
25
140
The Awesome DuckDB repository, maintained by @davidgasquez, has grown to more than 100 entries in less than a year. If you are aware of more cool projects using DuckDB, please consider submitting a PR!.

2
27
136
New blog post by @hfmuehleisen. duckplyr: dplyr powered by DuckDB. The post describes the new R package duckplyr, which translates the dplyr API to DuckDB’s execution engine. Read more at

1
36
134
Did you know that you can connect to a DuckDB database file via HTTPS or S3 with just two SQL statements? We have a new guide that explains how to do this.

2
17
130
New blog post by @__AlexMonahan__:.Creating a SQL-Only Extension for Excel-Style Pivoting in DuckDB. In this beginner-friendly blog post, Alex walks us through creating a DuckDB extension to implement a generic pivot table function with minimal C++ code.
1
17
128
The recording of the talk on DuckDB's spatial library, presented by its author @maxxen at @GeoPythonConf 2024 is now available. DuckDB Spatial: Supercharged Geospatial SQL.
3
22
123

DuckDB 0.8.0 "Fulvigula" released, check out our release announcement blog post:
4
34
122
There are now a lot of handy tools and cool projects built around DuckDB. You can find a list of these in the Awesome DuckDB repository maintained by @davidgasquez. See the list and contribute your project at

1
30
126

After the release of DuckDB v1.0.0 earlier this month, we recently crossed two other milestones:. – The DuckDB repository on GitHub reached more than 20,000 stars ⭐️.– The website surpassed more than 1 million visitor per month 📈. We wrote a few words

2
11
121
This blog post by Cal Paterson (, "DuckDB Isn't Just Fast", discusses some of DuckDB's characteristics outside of sheer processing speed: developer ergonomics, scalability using out-of-core processing, and ease of setup.
0
17
118
The new DuckDB landing page, has several code snippets for SQL features and DuckDB's APIs. You can use the "Live Demo" button to execute the queries on an example dataset in your browser using the DuckDB shell that runs in WebAssembly. Note: the demo
1
18
113
DuckDB's documentation is now available for offline use both as a PDF and as a ZIP archive, which contains the static HTML of the website. Head to to grab a copy.

3
9
112
New blog post by @holanda_pe:. CSV Files: Dethroning Parquet as the Ultimate Storage File Format — or Not?. In this post, DuckDB's CSV reader faces off. DuckDB's Parquet reader on reading tables and running queries directly on files.

3
15
115
𝗔 𝗽𝗲𝗲𝗸 𝘂𝗻𝗱𝗲𝗿 𝘁𝗵𝗲 𝗵𝗼𝗼𝗱 𝗼𝗳 𝗗𝘂𝗰𝗸𝗗𝗕. If you want to know what makes DuckDB so fast, check out the new blog post by Tim Ebergen on how the "optimizers play a silent, but vital role when using a database":
1
31
115
Last week, we published two blog posts:. 1) Alex Monahan implemented a SQL-only extension that mimics Excel's pivot functionality. 2) Hannes Mühleisen and Mark Raasveldt wrote about the importance of ACID transactions and released preliminary experimental results for TPC-H.

2
11
111
The R package for DuckDB v1.0.0 is out on CRAN! Run install.packages("duckdb") to upgrade.

0
19
110
We released DuckDB v1.0.0 a week ago. There is a growing list of tools integrating with DuckDB, applications that use DuckDB, and extensions created for DuckDB. You can find a list of these in the Awesome DuckDB repository, maintained by @davidgasquez. The list is never.
1
16
109
DuckDB v1.1.0 shipped a hidden gem for benchmark enthusiasts: the built-in TPC-H data generator is now multi-threaded, so you can now generate huge TPC-H data sets on a single machine with reasonable runtimes. We updated our documentation with estimates on this.

1
15
108
We have started publishing the recordings of DuckCon #4. We are first releasing the “State of the Duck” talk by DuckDB's co-creators, Hannes Mühleisen (@hfmuehleisen) and Mark Raasveldt (@mraasveldt). Video: Slides: Special thanks

1
20
107
The DuckDB team celebrates yesterday’s release, v0.10.0, with a custom-made yoghurt cake! 🍰

2
3
105
New blog post by Hannes Mühleisen and Mark Raasveldt:. Runtime-Extensible SQL Parsers Using PEG. This post discusses how parsers in DBMSs could be re-designed using Parser Expression Grammars for extensibility and improved error reporting.

1
21
108
Lambda functions are one of the most popular features in DuckDB. We recently added list_reduce, a new scalar function that supports lambdas, and they got their own documentation page at Note that this feature is currently only available in DuckDB's

0
16
105
𝐃𝐮𝐜𝐤𝐃𝐁 𝐓𝐫𝐢𝐜𝐤𝐬: 𝐏𝐚𝐫𝐭 𝟐. We continue our DuckDB Tricks series with a second part, where @szarnyasg shares some helpful hints for data wrangling: Have a trick you’d like to share? Let us know in the comments! 🦆.
1
13
106
DuckDB just got a tldr page. If you have @tldr_pages installed, you can get examples of the most common command-line arguments with:. $ tldr duckdb

0
21
104
Congratulations to @motherduck on launching their DuckDB-powered cloud data warehouse in General Availability! 🎉.

MotherDuck, the ducking simple data warehouse, is now Generally Available! 🍾🥂 Thank you to our community of thousands of users who have tested, validated, and helped improve MotherDuck over the last year.❤️🦆.
3
10
105
𝐍𝐞𝐰 𝐑𝐞𝐥𝐞𝐚𝐬𝐞: 𝐃𝐮𝐜𝐤𝐃𝐁 𝟏.𝟏.𝟐. We released DuckDB version 1.1.2 - a bug fix release. Curious about the change log? Here are the release notes: Follow our documentation for instructions on installing or upgrading:

1
14
101
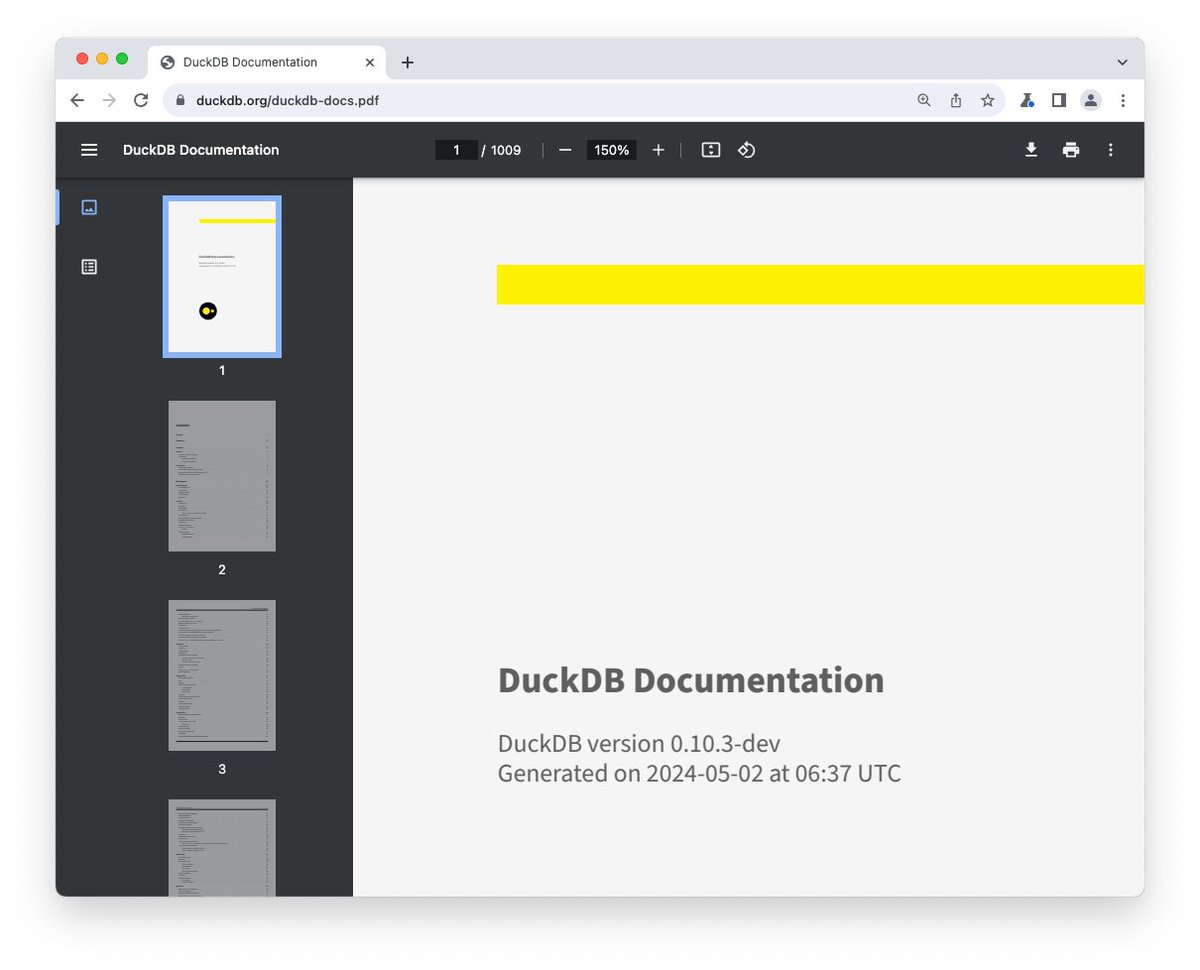
Did you know that DuckDB's documentation is available as a single PDF? It includes all documentation pages and guides, and just surpassed 1,000 pages.
2
15
99
New blog post by @carlo_piovesan: Extensions for DuckDB-Wasm. Thanks to recent developments, DuckDB-Wasm users can now load DuckDB extensions, allowing them to run extensions in the browser.
2
31
97
We released DuckDB version 1.1.1, a bugfix release. The installation page has the links and instructions for upgrading: For the change log, see the release notes:

3
23
97
DuckDB was included in @InfoWorlds's best open-source software list as a "tiny-but-powerful project" that provides just enough OLAP for most use cases. The award praised the lightweight nature and many features of DuckDB.


The best open source software of 2023 Ready to discover more? Click the image below ⬇️.
2
16
95

This blog post is a short summary of the ICDE 2024 .(@icdeconf) paper authored by @lnkuiper, @peterabcz, and @hfmuehleisen: Robust External Hash Aggregation in the Solid State Age. The paper is available at

New blog post by @lnkuiper – No Memory? No Problem. External Aggregation in DuckDB. The post describes how DuckDB can efficiently aggregate over many more groups than fit in memory, allowing it to complete the 50 GB variant of the

0
17
93
New blog post by Hannes Mühleisen and Mark Raasveldt: Changing Data with Confidence and ACID. We explain the ACID transactional properties, show that transactions are useful for data analysis workloads, and test DuckDB using the full TPC-H benchmark.
1
17
95
Did you know that you can use DuckDB to query Google Sheets via its CSV export? This blog post at areca data explains how:

2
16
94
New blog post by @holanda_pe – DuckDB's CSV Sniffer: Automatic Detection of Types and Dialects.
3
12
92
2
21
87
DuckDB can both export to and import from Numpy arrays. We added two new guides to cover these features:.


5
15
90
DuckDB's co-creator @hfmuehleisen announced support for Delta Lake (@DeltaLakeOSS) in DuckDB at last week's @Data_AI_Summit. You can rewatch the keynote segment below:. For more information, see the delta extension's documentation:.
1
11
90
DuckDB's co-creator @hfmuehleisen will give a keynote tomorrow at @GOTOamst. Hannes, who is also a professor of data engineering at @Radboud_Uni, will give an overview of the last decades of data management, discuss why relational systems are still prevailing, and why

2
10
86
Interested in finding out more about data wrangling with DuckDB? Be sure to watch the keynote from posit::conf, where @hfmuehleisen talks about "Data Wrangling [for Python or R] Like a Boss With DuckDB":
0
10
89
𝗙𝗮𝘀𝘁𝗲𝗿 𝘁𝗼𝗽 𝗡 𝗳𝗼𝗿 𝗮𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗲 𝗳𝘂𝗻𝗰𝘁𝗶𝗼𝗻𝘀. The end of the week brings us another blog post. @__AlexMonahan__ takes a deep dive into the top N capabilities in DuckDB: Happy Friday!.
0
15
89
We rolled out an updated syntax highlighter and a new color scheme in the DuckDB documentation, The highlighter now knows all of DuckDB's keywords and functions. The color scheme is based in the Bluloco theme (.



1
10
88
New blog post by @szarnyasg:.Analyzing Railway Traffic in the Netherlands. This tutorial demonstrates some of DuckDB's key query features using datasets that capture the railway traffic in the Netherlands.

3
16
86

New blog post by Richard Wesley – DuckDB's AsOf Joins: Fuzzy Temporal Lookups.
0
14
86
We rolled out two updates on our website:. 1️⃣ Most importantly, the long-awaited and much requested dark mode for the documentation pages. 2️⃣ A streamlined installation page with more detailed notes and examples. Check these out at

1
6
85
𝗖𝗼𝗻𝗰𝘂𝗿𝗿𝗲𝗻𝗰𝘆 𝗰𝗼𝗻𝘁𝗿𝗼𝗹 𝗮𝗻𝗱 𝗹𝗼𝗴𝗴𝗶𝗻𝗴 𝗶𝗻 𝗗𝘂𝗰𝗸𝗗𝗕. Have you ever wondered what the .wal file is when working with DuckDB? Time to find out! .This week, the co-creators of DuckDB, @hfmuehleisen and @mraasveldt, wrote a blog post about the Multi-Version.
0
14
83
Did you know that DuckDB supports function chaining? This allows function calls to be rewritten in more a readable manner. See the Even Friendlier SQL with DuckDB blog post for details:.

0
13
82
The DuckDB v1.1.0 JDBC client is now available on the Maven Central:

1
17
84
We have extended DuckDB's Operations Manual with new pages, detailing the built-in limit values of the system, e.g., maximum string size (, and expected cases of non-deterministic behavior along with potential workarounds (.


0
12
83
As promised just 1.5 weeks ago, we have indeed released DuckDB v1.0.0 this summer ☀️

4
10
75
𝐖𝐨𝐫𝐤𝐢𝐧𝐠 𝐰𝐢𝐭𝐡: 𝐝𝐮𝐜𝐤𝐩𝐥𝐲𝐫. This week’s blog post is brought to you by @hfmuehleisen, who shows how you can optimize the data analysis in R and go from seconds to milliseconds.
1
18
79
“With DuckDB as a browser for the data cloud, relational datasets are always just a hyperlink away.” – That's a great line. Thanks for this nice blog post, @NikolasGoebel!.

@duckdb doesn't need data to be a database (and to me that's what makes it special).
2
5
74