

George Grigorev
@iamgrigorev
Followers
2K
Following
2K
Media
2K
Statuses
8K
now: exploring opensource; prev: training @togethercompute, chatbots&diffusion@snap rare specialty coffee lover
London
Joined June 2012
@Grad62304977 reached out and suggested value residuals trick from @cloneofsimo -- you keep values from first block and do weighted sum in every other layer # v1 is value vector from first block # alpha1, alpha2 - learnable params v = alpha1 * v + alpha2 * v1 seems to be visibly


3
2
55
MTP is becoming very popular -- who has reference implementation?

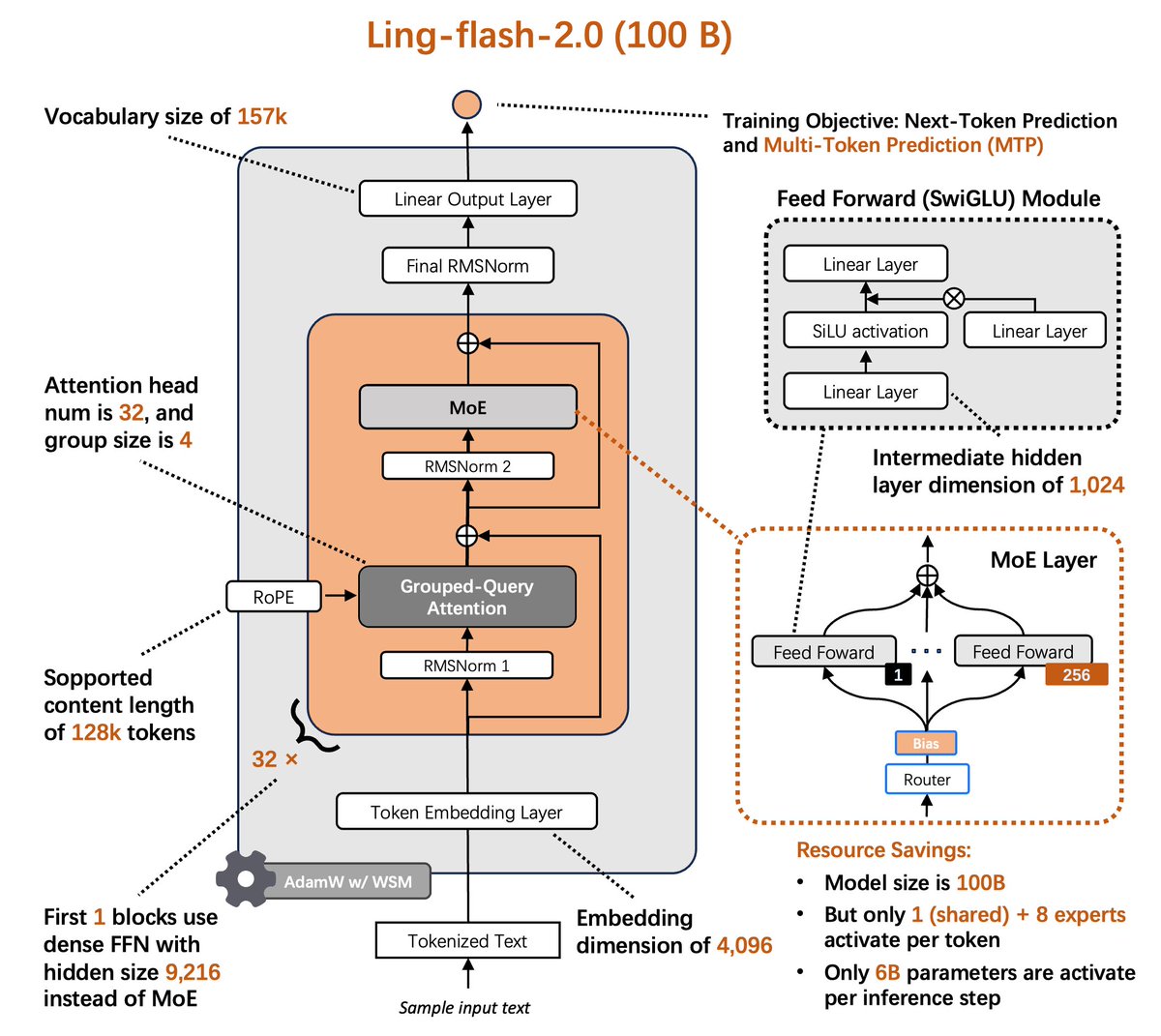
⚡️Ling-flash-2.0⚡️ is now open source. 100B MoE LLM • only 6.1B active params --> 3x faster than 36B dense (200+ tok/s on H20) --> Beats ~40B dense LLM on complex reasoning --> Powerful coding and frontend development Small activation. Big performance.


1
0
1
i need to seriously consider vscode instead cursor now whole ai coding stack became free* no need to pay for cursor, use vscode (-20$) no need to pay for claude code, you already have chatgpt plus / pro subscription, just use codex the only thing (that many people described) is
2
0
2
friendship ended with triton now gluon is my new best friend
0
0
1
simillar to the type of work i've been exploring, hope to get some more results by testing out different combinations!

swiglu-style gates working so well for attention (and not just in the ffn layers) is a beautiful thing. as it turns out, the "divine benevolence" might just be caused by better inductive biases for controlling where information goes.

0
0
3
We need to follow @yorambac on the updates for when ml experimentation agents should be capable of reproducing results of every paper listed here

0
0
3

and contents of repos incoming! i use ruff / biome to format files before uploading Total amount of tokens: ~100B https://t.co/a8q91OVuf7

huggingface.co
0
0
1

Original The Stack V2 which is used widely in open source research is outdated and too noisy. Today I am sharing the updated The Stack V2 dataset (filtered subset of smol-ids from the original dataset). All repos from original dataset were parsed with Github API and files
1
1
3
I’m so high on no alco drinks that we don’t need alcohol anymore: - very good rare specialty coffee (yes, caffeine is still a thing) - chinese/japanese tea or some special rare herbal tea extracts (buckwheat tea anyone?) - no alco craft beer (no lager, but sours or interesting
2
0
2
New AirPods Pro live translation demo when both people are in airpods are absolutely amazing
0
0
3

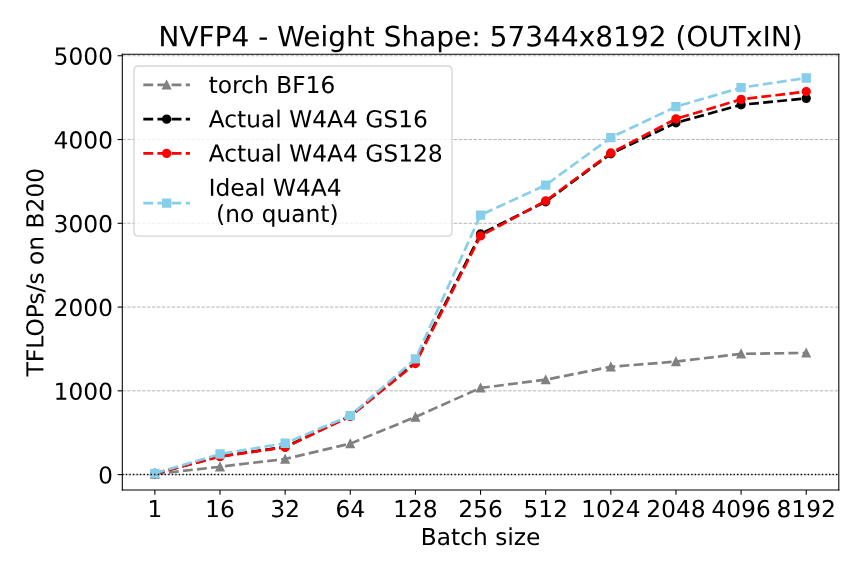
🚀 Excited to announce QuTLASS v0.1.0 🎉 QuTLASS is a high-performance library for low-precision deep learning kernels, following NVIDIA CUTLASS. The new release brings 4-bit NVFP4 microscaling and fast transforms to NVIDIA Blackwell GPUs (including the B200!) [1/N]
3
33
218
1. i don't quite understand where to put constexpr and where it expects ints 2. i'm not quite sure how ppl write softmax in streaming fashion (not materializing full row). Also don't understand how to put values in tensor properly (this tl.where with take and updates thing seems
0
0
1


Implemented SuperBPE in my codebase for training tokenizer from scratch. Notable differences: - In order to enable multi-word merges I first stop training at 80% of total steps and re-tokenize train set with existing merges. - Unlike normal BPE, SuperBPE no longer splits by
1
0
3
wondering how to improve speed of training further... i'm sure there's a way to "restart" learning during pre-training so the model is in state of 'chaos' but not diverging, and then finding good directions again, learning, then we restart again. instead of simply following one
@vikhyatk do you really observe weight norms plateau and loss of 'plasticity'? I wonder we should really track this for most efficient learning, like gradient norm shrinking → signals the model has little left to learn (flat loss landscape). maybe there's a very simple way to check that
0
0
0
i was stumbling with triton install, could not understand why during uv run python my `import triton` works fine and even `import triton.language as trl; trl.cdiv(10,3)` -- works, but showing error that it needs to be called inside a kernel. but when running a kernel i spent
1
0
8