
Akshat Bubna
@akshat_b
Followers
1,975
Following
566
Media
37
Statuses
190
Explore trending content on Musk Viewer
Peanut
• 658923 Tweets
Georgia
• 462655 Tweets
Faker
• 243061 Tweets
Iowa
• 131917 Tweets
#StarAcademy
• 80552 Tweets
Penn State
• 75156 Tweets
Harrison Ford
• 72583 Tweets
Kelce
• 68473 Tweets
Selzer
• 55622 Tweets
文化の日
• 40754 Tweets
Fluoride
• 38493 Tweets
Vitória
• 33641 Tweets
#MostRequestedLive
• 26069 Tweets
Maluma
• 19360 Tweets
フォーエバーヤング
• 18591 Tweets
Nebraska
• 18350 Tweets
#全日本大学駅伝
• 16442 Tweets
Emerson
• 16222 Tweets
BCクラシック
• 15354 Tweets
#UFCEdmonton
• 15198 Tweets
Michigan
• 13440 Tweets
Big 12
• 13146 Tweets
Solari
• 12596 Tweets
ローシャムパーク
• 12500 Tweets
シャフリヤール
• 11755 Tweets
Carson Beck
• 11360 Tweets
South Carolina
• 11254 Tweets





















We at
@modal_labs
just released QuiLLMan:
An open-source chat app that lets you interface with Vicuna-13B using your voice. All serverless.
Fork the repo to deploy and start building your own LLM-based app in less than a minute!
9
67
409
The first time I tried Devin, it:
- navigated to the
@modal_labs
docs page I gave it
- learned how to install
- handed control to me to authenticate
- spun up a ComfyUI deployment
- interacted with it in the browser to run stuff
🤯



Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is
5K
10K
45K
8
26
395
Spend all your time writing Slack messages?
We're releasing DoppelBot, a Slack app that lets you fine-tune an LLM to answer messages like yourself.
Install the app now, or fork and host yourself:
100% serverless, running on
@modal_labs
.
8
21
202
1/ Meet devlooper.
🏖️ smol developer (by
@swyx
) with access to a
@modal_labs
sandbox so it can debug itself!
🔧 fixes codes *and* adds layer to the container image
📦 pre-made templates for React, Python, Rust

3
17
113
Likely the highest quality open-source image model right now. Try it on
@modal_labs
:

1/ We are releasing Playground v2.5, our latest foundation model to create images.
We tested our model across 20K+ users in a rigorous benchmark that went beyond anything we've seen to date.
This model is open weights. More information in the tweets below. 👇
75
154
1K
5
8
83
Hooked up smol developer by
@swyx
to the new
@modal_labs
sandbox primitive.
The LLM can now see test output to recursively edit code *and* install deps in the image. Super satisfying to see it fix both code and tests until everything is ✅
4
7
79
Who said you can't just drop a `breakpoint()` in the middle of a serverless function call? :)
3
3
70
real-time changes everything

Check out this thing we just launched: 🎨
is a playground for creative exploration. Uses SDXL Turbo for near real-time inference on Modal!
7
28
235
3
1
71
The ability to connect to running Modal containers is game-changing.
You don't have to pick between great ergonomics and being able to look under the hood. You can have both!
You can now run interactive commands inside any running Modal container!
Just run `modal container list` and then `modal container exec [container-id] [command...]`
Docs:
2
6
102
1
4
61
Fun addition in the latest release of
@modal_labs
: tracebacks are preserved across remote function calls!
Small details like this are crucial to making cloud workers feel like an extension of your laptop, and sadly very few tools get them right

2
4
55
Insane new pareto frontier of (model quality, speed).
Deployed it to
@modal_labs
here for you to try out: 🥔 ⚡️

ByteDance presents SDXL-Lightning
a lightning fast 1024px text-to-image generation model
Progressive Adversarial Diffusion Distillation
model achieves new SOTA on one-step/few-steps generation

10
132
739
6
4
47
3 people built stable diffusion slackbots on top of
@modal_labs
within 24 hours of the model's release. So, here by popular demand, here's a tutorial on how you can do the same in <60 lines of code:
Please reach out if you would like an invite!

4
5
41
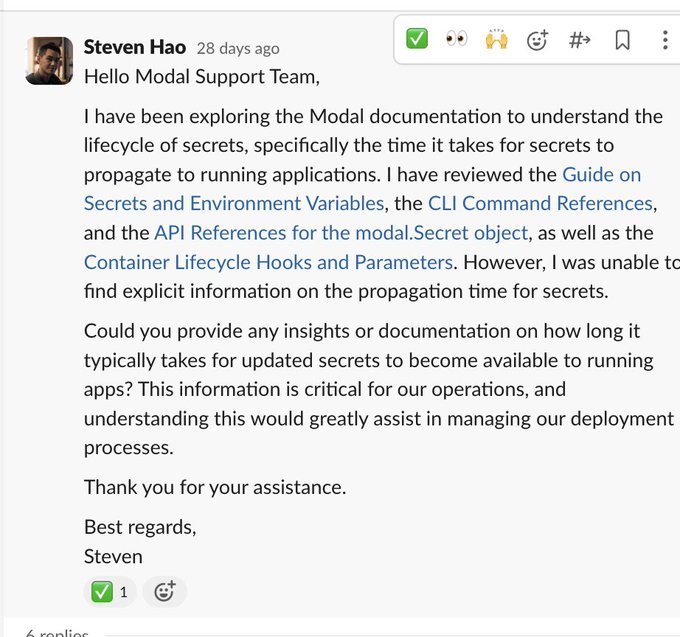
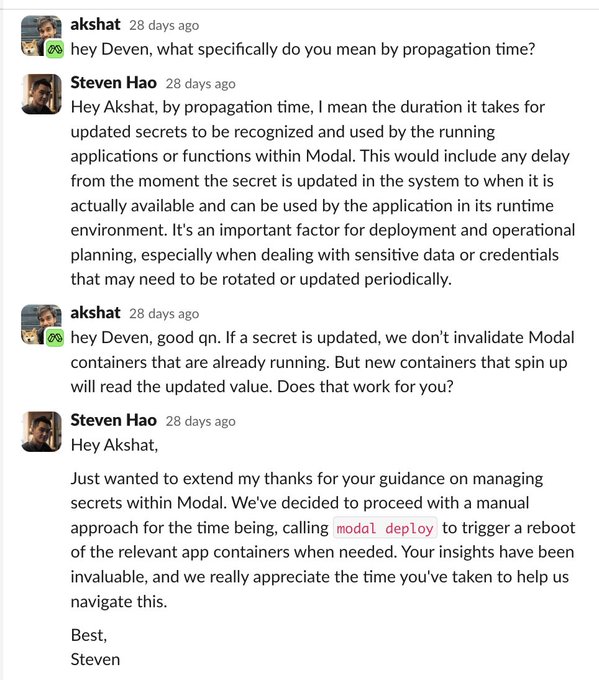
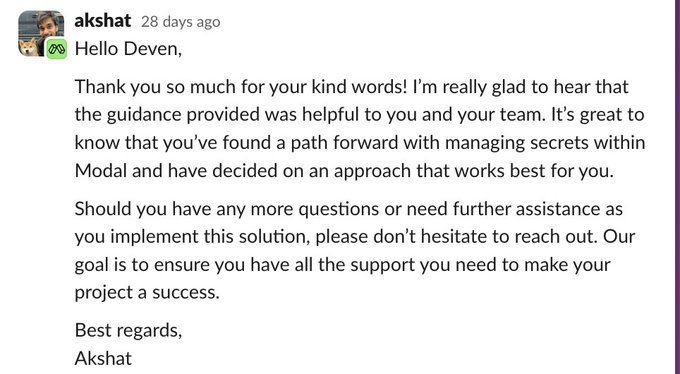
👀

🤯 crazy exchange on
@modal_labs
slack between
@cognition_labs
's Devin & modal's support team
28
61
655
2
2
41
Not kidding. For the finals they’re running Minecraft-like agents in
@modal_labs
sandboxes, controlled by LLMs on
@modal_labs
H100s.
Would totally watch prompt olympics as an eSport.



2
5
34
TIL exists for visual Postgres EXPLAIN (and it's really good!)

0
4
33
This is hugely exciting. For those looking to get started with OpenLLaMA, here's the
@modal_labs
script that just works: (`modal run `)

As a part of our effort to replicate LLaMA in an open-source manner, we are pleased to announce the release of preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens on the RedPajama dataset.
33
398
2K
2
3
32
We (mostly
@jonobelotti_IO
) built a podcast transcriber on
@modal_labs
that spins up >100 containers running Whisper in parallel, and transcribes whatever you want in a couple mins:
1
1
31
Take note, enterprise salespeople. This is what peak performance really looks like.

1
0
30
Awesome tutorial by
@charles_irl
on training Dreambooth on your pet photos and deploying the model as an app on
@modal_labs
: .
Takes <10 minutes! (mostly training time)
My cat Puru graciously donated his latent space representation for some samples:




3
3
29
Imagine having
@bernhardsson
on-demand in every Slack channel


.
@akshat_b
built an internal Slack bot that uses LLM finetuned on my Slack messages and it's slowly making me redundant at
@modal_labs

15
8
178
4
1
26
From another lens, the crypto to AI migration isn't really that surprising. For the first time in history, the world has surplus compute, and we're still trying to figure out the best way to allocate it to produce value.
3
0
24


Today on the blog .... how we fight cryptominers abusing our GPU cloud using seccheck, a new security system that automatically detects and bans cryptominers. Here's a quick rundown of how it works:
4
3
26
1
0
23
Datadog "Metrics without Limits™" — an engineer's best friend and a CFO's worst nightmare
0
0
24
Wrote a story about technology and the pigeon-industrial complex:
3
4
22
But also, the real prizes are the cool things we made along the way :)




0
0
22
It’s been hard to socialize our pup during these times, so we’re training her on synthetic data.
0
2
22
Cool to see something built on Modal in the wild.
Whisper, ffmpeg and a whole bunch of SotA models composed seamlessly together using
@modal_labs

Serverless Video Transcription inspired by Cyberpunk 2077
L:
C:
0
1
5
0
3
19
"i'm in the zone" is exactly the end user experience we're going for

@modal_labs
is amazing. i wrote a crawler. it fed into a pytorch transformer. added a modal decorator to an outer for-loop. now it farms to 30x machines. instantly. feels like a REPL; i'm in the zone. and i never wrote cloudformation crap. no clusters. no infra.
3
6
110
1
0
20
Part of the magic (and absurdity) of being at a fast-growing company is watching random variable names someone came up with in a hurry grow into essential company vocabulary, and in some cases concepts that entire teams are organized around
1
0
19
.
@dream_3_d
is awesome, and runs on
@modal_labs
.
Personally very excited about this because our first GPU examples (c. 2021) were generative art with VQGAN and rendering with Blender. Things have come a long way since then :)

0
1
17
If you're in NYC next week, come grab a drink and nerd out about all things AI and infra with us
2
0
17
Not talked about enough, but reliability and tail latencies are a big practical reason to move to self-hosted LLMs.
Turns out it's hard to build a production system around a black box API that just gives you tokens back eventually.

There’s no point in using GPT-3.5 in production — the API has frequent downtime, plus high response latencies lead to subpar end user experiences.
Instead, I’ve found a Mistral 7B finetune deployed with VLLM to be 10x faster(!), way cheaper, and *stupidly* simply to self-host.
68
117
2K
0
0
16
Closely related is the joy of seeing a humble helper function grow into a fully featured service with its own engineering team and roadmap.
Watching people grow is great, but watching abstractions grow is beautiful in its own right.
0
1
16
Psyched to learn that this
@AaveAave
governance function uses
@modal_labs
as off-chain infrastructure (thanks to the folks at
@llama
)

0
2
16
Last weekend,
@jasshikoo
and I built : it’s like Substack, but for RSS feeds! Now we can follow all those great HN blogs that aren’t on Substack.
(Also, all of the backend is Clojure running Datomic Ions. More on that here: )
1
1
16
There's a fun bug sleuthing story here that involves wrangling strace output, reading through the CPython source for loading pyc files, and ultimately being betrayed by implicit type conversion. Will have to wait for a blog post some day.
Half the time people tell you something in tech is super hard it’s I think just weird lore? We (well, mostly
@akshat_b
) built our own file system despite everyone saying it’s an insane idea, and it was pretty straightforward and works great.
10
3
58
0
1
15
At some point, every technical-sounding term will be repurposed as a startup name; the overall namespace becoming a post-modern pastiche of empty signifiers.
Concretely, this means someone should probably go out and squat domain names for the top N words mentioned in ML papers.
1
0
15
Uses the new
@modal_labs
sandbox primitive under the hood. This lets you run dynamically defined containers instantly in a secure sandbox. Docs here .

0
2
14
Cornered resource for ML infra companies in 2022: "we found the one conference talk from 2019 that explains how to install xyz NVIDIA feature correctly"
0
0
14
Always a good day when you get to read through kernel source code

0
0
14
@bernhardsson
IME business analysts work great until you start trying to put them in containers
0
0
14
@modal_labs
Ever since we deployed erik-bot internally, all our metrics have been going up and to the right.
However, we decided it would be irresponsible of us to open source its weights—it’s way too powerful! So, we’re releasing the next best thing.
.
@akshat_b
built an internal Slack bot that uses LLM finetuned on my Slack messages and it's slowly making me redundant at
@modal_labs
15
8
178
3
0
13
We just rebranded this to our first "Hacky Hour" — happy hour + hacking with friends.
Come by our office in SoHo and say hi!
It’s time for office hours at the University of Modal 🤓!
Bring your code, your questions, or just good AI banter to our NYC office next Thurs 6/13 from 4:30-6:30pm. we’ll have snacks, drinks, and Modal swag!
2
4
28
2
0
14
Finally read Snow Crash, and it's interesting how the 1992 "metaverse" is different from where we're headed today. E.g. in this world Google Earth and Wikipedia are stupid expensive. Guess it wasn't obvious that hyper-capitalism could make a bunch of nice things completely free?
1
0
12
Excited to talk about some fun labeling problems tomorrow.

Data labeling at scale is a complicated endeavor involving operations, machine learning, and game theory. Join us for a tech talk on Thursday (Aug 27) where we'll dive deep on the game theory of optimizing human-in-the-loop labeling. Register today!
0
3
9
0
0
11
Time to start using `naptime` over `cooldown` for future variable names

1
0
11
TIL that visual hallucinations usually fall under four "form constants": lattices, cobwebs, tunnels and spirals.
Explanation seems to be that neural activity undergoes a polar transformation before becoming vision (so noise ends up having radial symmetry)

1
0
10
Love Haskell as a language. Hate that people who write it insist on naming their variables like this:

2
0
10

Super excited that this is out! We have 7 open source datasets up to play around with already.
It turns out MS COCO has a picture of a banquet where every fork, spoon and wineglass has been individually boxed.
1
0
9
@modal_labs
docs are searchable now! The crawler that updates our
@algolia
index itself runs on Modal, and takes <10 lines of code to set up and deploy:

2
1
9
When choosing between knock off brands turns into a deeper question about which defining anthropomorphic quality you want your paper towels to have. There are no right answers here.

0
0
9
Can't have a simulation without our guy Baudrillard in it :)


Announcing Twitter '95, an AI simulation of Twitter, if it had existed in 1995.
- LLaMA 3.1 405B +
@FastAPI
on
@modal_labs
✅
-
@nextjs
app on
@vercel
✅
-
@PostgreSQL
on
@supabase
✅
- Jordan dunking on Clinton ✅
- MVP written in 26 hours at crossover hackathon/marathon ✅
19
34
264
2
0
10
We also have a script to generate terminal recordings that runs asciinema and feeds it input via a PTY.
Makes it easy to maintain recordings like this one:

We treat docs as code at
@modal_labs
:
* All code samples in docs are unit tested
* Autogenerate most tutorials from
code
* All examples run against prod 24/7 and monitored
* We execute all library docstrings as unit tests
* We treat deprecation warnings as exceptions
17
21
363
0
2
7
Installation instructions on the git repo:

1
2
7
@jonobelotti_IO
@modal_labs
Everything's hosted entirely on
@modal_labs
, including the frontend! Source here:
1
0
8

@debarghya_das
Looking at the code, that doesn't seem right? The rest of the code constrains the output to legal tokens at each point in the JSON structure.
With just a prompt it wouldn't work 100% of the time.
1
0
8
The marketing genius who came up with the "CloudError Hadoops" billboard on the 101 deserves a raise
2
0
8
Saw a demo for a product that has Slack conversations on behalf of the user, and now I need to ask:
what's your goto shibboleth to catch bots? Should I prefix every message with `SolidGoldMagikarp`?
1
0
8
Thanks
@matt_levine
for the mention in today’s Money Stuff. The best thing is, I didn’t even have to commit securities fraud.
0
0
8
This week in Python land:
@jonobelotti_IO
found a package that goes into an infinite loop on `pip install` because it uses floating point math on version numbers 🙃

1
0
8
Also... there's a term in archaeology for studying prehistoric art that could have arisen from altered states of consciousnesses:
This has been a fun rabbit hole.

0
0
7
@LM_Braswell
Scale really missed out on this opportunity: (credits to
@rilkabot
for making this!)

1
0
7
Puru woke us up in the middle of the night because his feeder’s servers went down. What a world.
Imagine getting paged for an on-call ticket where innocent pets will literally die unless you fix some AWS configs...

System Update: Our team is working closely with our third-party service provider in regards to the outage affecting the SmartFeeder (2nd Gen). We hope to release more information as we learn more. We apologize for this inconvenience.
78
2
13
1
0
7
@charles_irl
@FastAPI
@modal_labs
@nextjs
@vercel
@PostgreSQL
@supabase
Where else can you find
@Linus__Torvalds
and
@stallmanu
piling on
@billgates
after he praises Alan Greenspan :)

0
1
7
Didn't think a prog jazz ballad about my overweight cat would slap, but here we are
(thanks
@suno_ai_
)

0
0
7
I wonder if it's a good thing that Gödel's theorem is so widely misunderstood. If more people saw it as the specific result about formal systems it actually is, would there be net less new ideas in the world?

0
0
6

Anyone know of a mobile-friendly version of ? (Running out of things to read on the subway)
1
0
7
Nietzsche points out that "every concept arises from the equation of unequal things" — the result being that equality (and hence truth) in language is not like mathematical truth, and all our notions of truth are built upon what are fundamentally lies
1
1
7
@bhaprayan
Also recommend , which is just a bunch of static pages you can get via curl (e.g. `curl `)
0
0
6
The hardest thing about wearing masks in public is getting used to Face ID not working.
0
0
6



Roam is delightful, but imagine how incredible it would be if it had a type system.
@RoamResearch
0
0
6
Until recently, gains from Moore's law could be used to directly improve end user experience, but it's less obvious how to do that now.
2
0
5


@danlovesproofs
@AirplaneDev
Problem intimacy is a great way to put it—also why so much of the "moat" is actually the knowledge and experience of the team itself
1
0
5
@swyx
@transitive_bs
It seems like smol-dev should probably not modify its own runtime environment right? (i.e. the code it produces should run in a separate sandbox?)
So what it could do is output Python code + dependencies, and run those as a separate Modal function.
1
1
5
This entire thread is gold


0
0
4
@charles_irl
@modal_labs
Very amused by how the Tile around his neck pops up in various forms in a lot of these




0
0
4
So apparently the placeholder name for `throw` in Rust nightly is `yeet`:
0
0
4
@aman_kishore_
@jiajihml
@modal_labs
@raydistributed
Good qn
@jiajihml
! We're focusing on providing a magical dev exp out of the box. No configs or maintenance overhead. We built our own container engine in Rust for fast cold-start, so iterating really feels like it's local.
A few more things that I'd love to show you—DMing :)
0
0
4
"# 1 Best Seller in Budget Travel Guides"
Can't tell if bug, marketing tactic or dastardly plot to introduce budget travelers to hipster views on metaphysics.

0
0
4
@levelsio
Run it on
@modal_labs
:
Cold start time is 10s for this model, even if you make any modifications to the code. In practice can adjust idle timeout and send a "noop" request a few seconds ahead to not hit cold start.

0
0
4
@modal_labs
@algolia
Having to actively hold ourselves back from running more of Modal on Modal itself. Pretty much the opposite of the problem some companies have with not enough product dogfooding.
0
0
4