

Rex "garbage in" Douglass Ph.D.
@RexDouglass
Followers
5K
Following
11K
Media
435
Statuses
11K
Applied Scientist in Industry. Previously UCSD. Princeton PhD. Follow me for recreational methods trash talk.
Joined September 2013
Are you interested in:.Causal inference? Data best practices? Time series? COVID-19? Awkward methods drama?.Then check out:."How to be a Curious Consumer of COVID-19 Modeling: 7 Data Science Lessons from . (Feyman et al. 2020)".

2
33
143
Because I never get tired of this joke:. It's statistics if it's in R. It's machine learning if it's in Python. It's AI if it's in PowerPoint.
22
541
6K
I got falsely diagnosed once with a disease so rare I would have literally been a named case. I was showing him a bayesian calculator in the urgent care begging him to think for a second.

Well, 4 out of 5 doctors can't answer a basic question about statistics, even at Harvard. Medical professionals tend to have an incredible amount of crystallized knowledge, but often aren't actually that intelligent.

34
209
5K
The older I get the more personal I take this crap because it's not like ignorance, incuriosity, and mysticisms are free. They're a tax you pay every day. And a unnecessary arbitrary risk imposed on you that you just hope doesn't nuke your health, finances, or family one day.
3
33
1K
I'll give this answer again for why Phds are mentally taxing. You spend 6 years discovering exactly what you are incapable of. /n.

Pretty strong evidence of negative mental health effects of doing a PhD. Recent working paper by.@EvaRanehill, @annahsandberg, Sanna Bergvall, and Clara Fernström. Paper link:
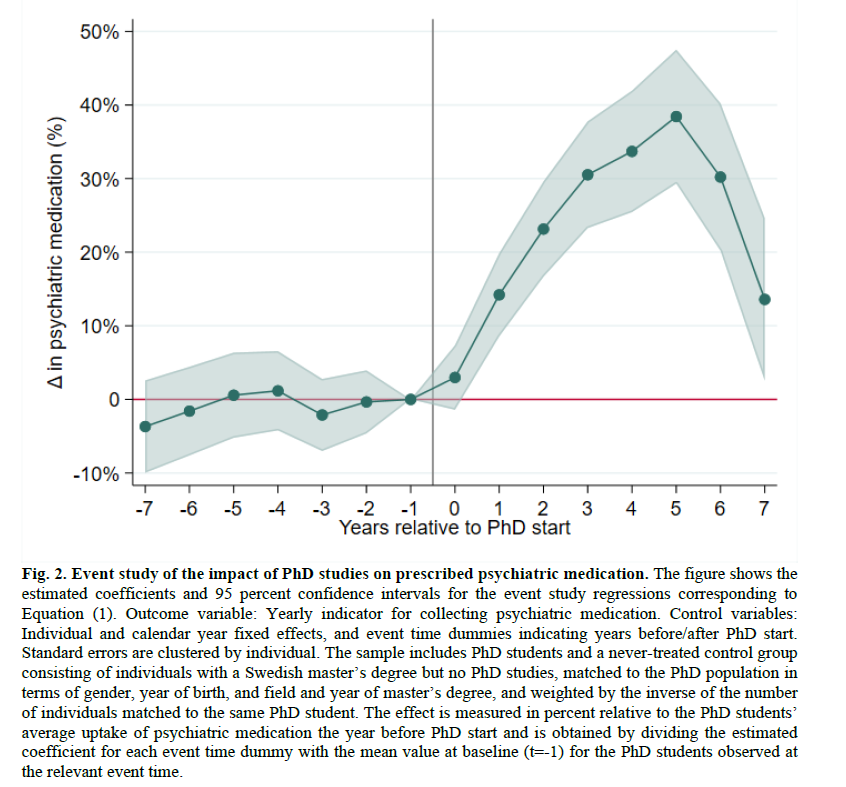
7
101
968
I'm at the point where I'd rather just go down to Home Depot and ask them if this looks infected. It's free and the standard of care is going to be comparable most of the time.
4
26
921
@tcarpenter216 This is one of those when priors and ev disagree this much it's actually more likely that some other assumption is wrong and now we're really unsure about everything.
7
1
483


The weird thing about The Simpsons is that while the average quality of the jokes has decreased over time, the average quality of each individual character's jokes has actually increased over time.
2
41
349
Here's the breakdown:. -90% of all papers are too vague to even be wrong. It would take years of work to get them to wrong. -9% are clearly wrong. They draw stronger than reasonable conclusions from weak ev/designs. -1% should impact your beliefs at all, probably weakly.

What is the prevalence of bad social science?.
3
32
341
@thezahima It was communicable and he ordered me to quarantine at home and wait for labs to come back. I basically told him he was an idiot and that I would comply but wanted something for the not insane thing on his differential and he gave me a z pack and stormed out. Better the next day.
5
3
338
All of the action in censorship is in self policing. The censor creates uncertainty which forces the target to alter their behavior. The censor keeps the rules ambiguous so the target can never be safe and the censor can decide after the act. You now have to pay protection rents.

@sebkrier talking about extreme censorship opens the overton window to little censorship. planting the idea of prison for memes is supposed to make us think 'it could be worse'. i don't think the elites really want to censor everything. but they REALLY need to censor some things.
10
47
289
You start off with clinically insane expectations for yourself driven by .1) what you don't know about the trade .2) role models that are 90% survivors bias.3) no view of the full population of people around you, who on average are wealthier, better educated, and further along.
1
13
267
FWIW, American Phd programs have an insane structure. You take a 24 year old who just barely survived comps and who hasn't published a single paper yet much less a good one and then give them a 3 year paid book sabbatical. What did you expect to happen?.
You then spend 6 years finding out exactly how you're going to fall short of those expectations. Every single day, even if you make amazing, unbelievable progress, you are narrowing the confidence bands further away from what you thought you were going to be capable of.
12
7
238
The only way to even think coherently about a modeling approach is to get it into DAG form. The reader should not have to do this. I've gotten it DAGified here below. Given that structure we can start to think about whether it's identified or not:


Just published in @JPubEcon:. "How does parental divorce affect children’s long-term outcomes?". By @WFrimmel (@jku_econ), @HallaMartin (@WU_econ), @EbmerWinter (@IHS_Vienna).

5
34
211

You then spend 6 years finding out exactly how you're going to fall short of those expectations. Every single day, even if you make amazing, unbelievable progress, you are narrowing the confidence bands further away from what you thought you were going to be capable of.
2
7
192
Almost every panel data paper sneaks in an implicit assumption that the reporting mechanisms remain constant over time and units. That's never, ever, true. The author just doesn't know how it changed, and the reader is forced to try to guess.

This is the most compelling case I’ve seen against the idea that smartphones are causing a mental health epidemic among teens. Apparently Obamacare included a recommended annual screening of teen girls for depression and HHS also mandated a change in how hospitals code injuries.



4
20
195
Doctors are primarily walking decision trees. They aren't doing long run Bayesian updating on you specifically. They're throwing you down a plinko board and sending you to the next station or home. A false negative on a test is a death sentence.

Here’s a fun related story. I went to the ER with severe stomach pain a few years ago. I googled and one of the most likely explanations is appendicitis. They do MRI. No appendicitis. I say “Isn’t appendicitis bacterial? And therefore subject to exponential growth rates? So it.
5
10
190
People think anonymous peer review is critical. It's not. It's performative. Nobody is checking your code or data. You drop a strategically crafty natural language narrative with a 70pg appendix on 3 rando volunteers. And then venue shop until you get friendlies. That's not real.
For what it's worth, in neither academia nor industry is there any incentive to be critical. There's a creepy creepy cult of positivity. It's sold as pluralism, or being pedagogical, or 'not being toxic.' But it's just politics. Institutionalized corruption trading in fake facts.
10
12
178
Statistics are exact calculations based on data on hand. They have no uncertainty. 'Confidence' is scientific model of how a statistic might map to a real unobserved estimand we care about. That model usually isn't very good. Incorporating the simplest sources of known error.

Random thoughts about confidence intervals:. When we teach precision & accuracy, we often use images of a target, like these from the Wikipedia article: . But I think this analogy leads to confusion about the interpretation of the confidence interval. 1/4

2
10
180
As you learn that, you're also learning all the other realities of the trade, real discovery is near impossible, it's deeply corrupt, it's a pyramid scheme, it's basically still a corporation but with half to a third of market pay, etc. By the end you're running on sunk costs.
1
5
167
IV papers are pretty much all mining noise for stars. Delete one observation and 37% become insig. Delete 2 and 57% become insig. Concerns about generalizing to the real world are overblown, most results don't even generalize to their sample.

6
36
168
Just to be clear, a bunch of really misleading work tried to torture data into showing a predecided conclusion. A GRAD STUDENT stuck their neck out and did a ton of work to prove the negative the ev doesn't show that. Now it's being co-opted as a joint dialogue. LoL.

Our exchanges with @MatthewBJane (public and private) and @drjthrul are perfect illustrations of JS Mill’s doctrine: . “The steady habit of correcting and completing his own opinion by collating it with those of others, so far from causing doubt and hesitation in carrying it.
3
18
164
The replication crisis is hilarious because those decades had literally tens of thousands of researchers pointing out why that work was bad and self selecting out of it and they were less competitive than the people willing to just pump out stuff. Every decade has sane losers.
1
18
164
Bonus points for the bait and switch in market expectations between starting and finishing your PhD. When I came in, they said a good diss with a couple of finished chapters would get you a job. 5 years later it was a finished diss plus a pub. Now it's multiple good pubs.
3
6
149
"we examine reproducibility. by attempting to reproduce the results in 93 published papers. using (fMRI) data during the 2010–2021 period. we could only reproduce the results in 14 (15.1%) papers".
5
50
142
I keep re-finding this gem from 2020. It's the closest to how I came to view things:.-Almost all work is bad.-It's knowably bad, at first skim.-The authors must know.-Everybody else also knows but the profession has no incentive to say it out-loud.
6
14
140
For what it's worth, in neither academia nor industry is there any incentive to be critical. There's a creepy creepy cult of positivity. It's sold as pluralism, or being pedagogical, or 'not being toxic.' But it's just politics. Institutionalized corruption trading in fake facts.
8
16
130
You see this with athletes too who genetically just can't beat their competition despite putting in what feels like much greater effort. There's nothing fair about it. And nobody can ever really talk you out of it. You're doomed to learn the hard way.
1
3
121
"there are no weak instruments, only weak men". "we then cat-fished several hundred happily married fathers".
Just published in @JPubEcon:. "How does parental divorce affect children’s long-term outcomes?". By @WFrimmel (@jku_econ), @HallaMartin (@WU_econ), @EbmerWinter (@IHS_Vienna).
3
7
112
I very seriously propose a stats twitter holiday. March 24th.Large-Enough-N day (LEN). On that day, send your favorite methods article to someone you care about. Wishing you all a large enough N this season.

9
8
111
Can't stress this enough. Almost all observational panel data results are at least in part hallucinations from unknown subtle changes in measurement over time. Almost no real world data is produced consistently with a bad fixed effects model 20 years from now in mind.

New article by me:. The rise in reported maternal mortality rates in the US is largely due to a change in measurement. The change was adopted by different states at different times, resulting in what appeared to be a gradual rise in maternal mortality.

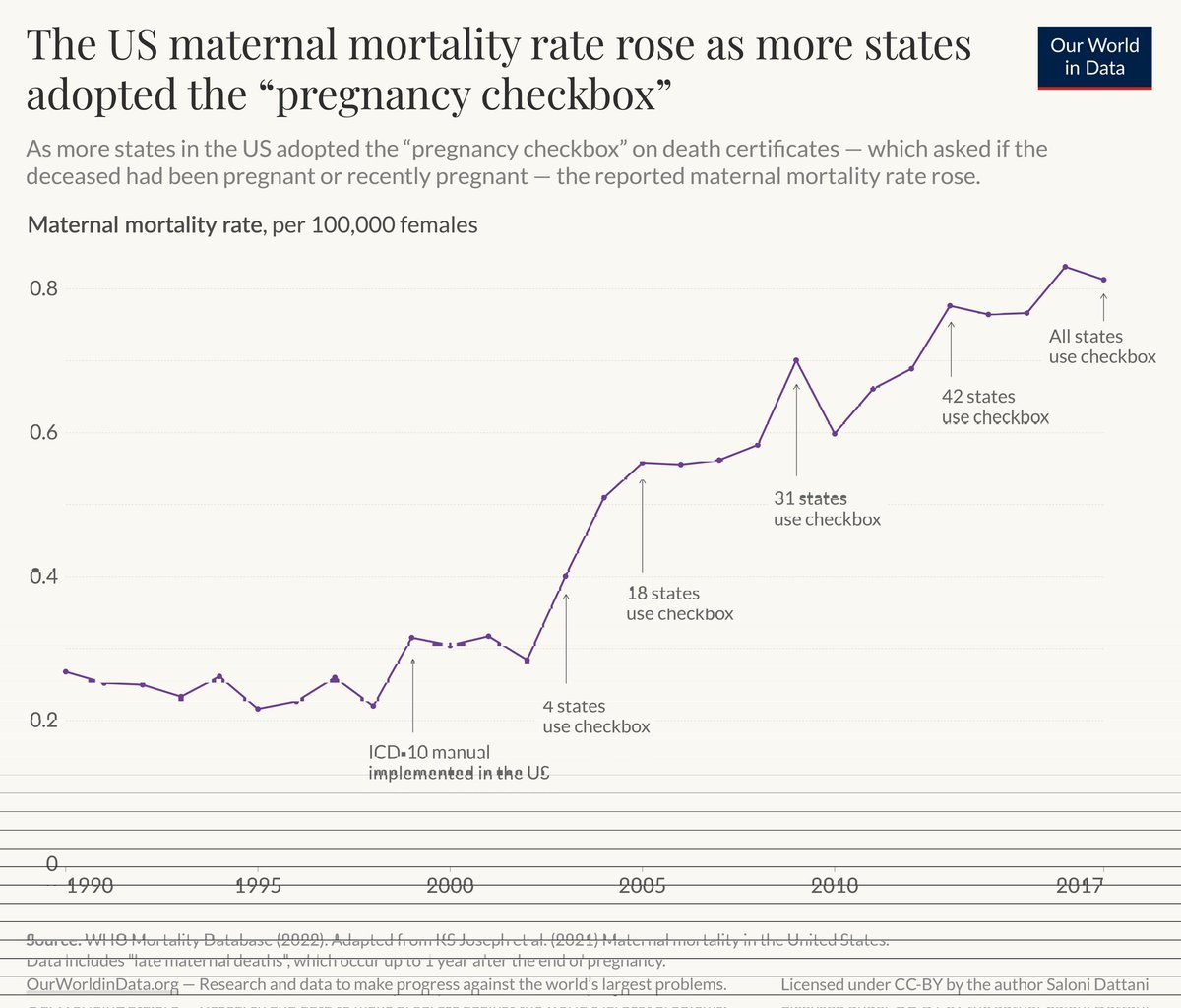
3
13
101
This isn't just ML. Gelman has been making the same argument for decades about social science. That researchers have a religious conviction for their argument and the evidence is just used as a stage prop to illustrate it to the audience rather than prove it.

New essay: ML seems to promise discovery without understanding, but this is fool's gold that has led to a reproducibility crisis in ML-based science. (with @sayashk). In 2021 we compiled evidence that an error called leakage is pervasive in ML models
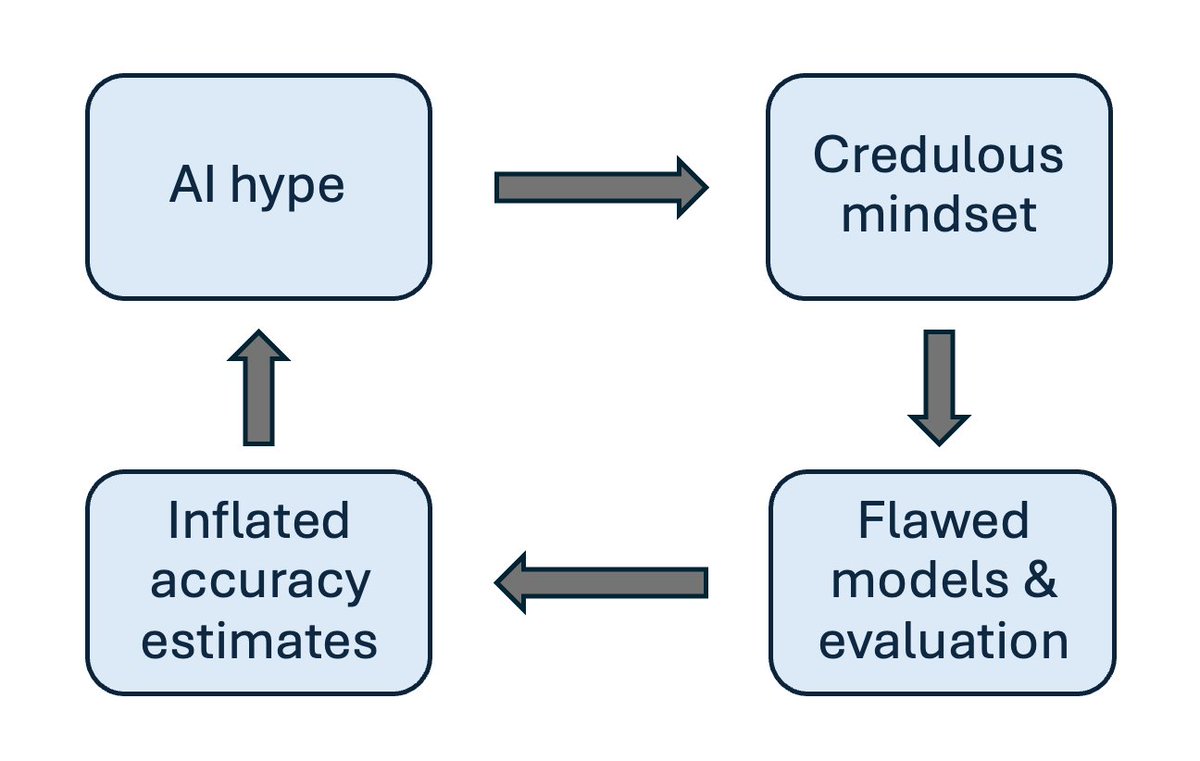

5
11
103
Modest proposal- the autocratization of statistics. Only one person is allowed to run a regression. It must be done with punch cards on an IBM 360 mainframe plated in gold. They are chosen by god and inbreeding. If they die, it passes to their son/cousin.

The "democratization" of statistics has by and large been a bad thing.
8
7
99
Meta-analysis is largely the same free lunch used car selling of the underlying studies. It's almost always taking mismeasured, unidentified, unreplicable, trash, and pretending if piled together it magically averages out to a good study. It's intellectual money laundering.

This is where I feel frustrated by the state of research on this important question. How much is a meta-analysis actually worth with so much heterogeneity in the study designs, outcomes, samples, duration, etc? I think very little.
7
12
98
Data scientist is a made up term so why stop there?.Electricity electrician.Law lawyer.Music musician.
5
9
82
Yesssssss. I finally caught an LLM in the wild.

2
1
87
"Bayesian inference completely solves the multiple comparisons problem". Good explainer of the Bayesian approach to multiple comparisons and why it makes way more sense in the social science regime of torturing a little data into saying a lot of things.
2
9
86
Not for nothing but every time you say "reviewers shouldn't have to review code because not enough of them know how to code".you are literally saying."modeling is reviewed by people who aren't competent to review modeling".Correct. Exactly. 💯. You get it.
People think anonymous peer review is critical. It's not. It's performative. Nobody is checking your code or data. You drop a strategically crafty natural language narrative with a 70pg appendix on 3 rando volunteers. And then venue shop until you get friendlies. That's not real.
3
6
82
Hard disagree. Code for the paper should be in a ready to go repo already. What are you doing submitting a paper that doesn't have working code? Journals should be demanding it and reviewers ought to be reviewing it.
3
7
80
This is a good paper for honing your B.S. detector. So, cute ID strategy. Why do you already know it's not real?.

This looks interesting and timely. "Eclipse: How Darkness Shapes Violence in Africa".

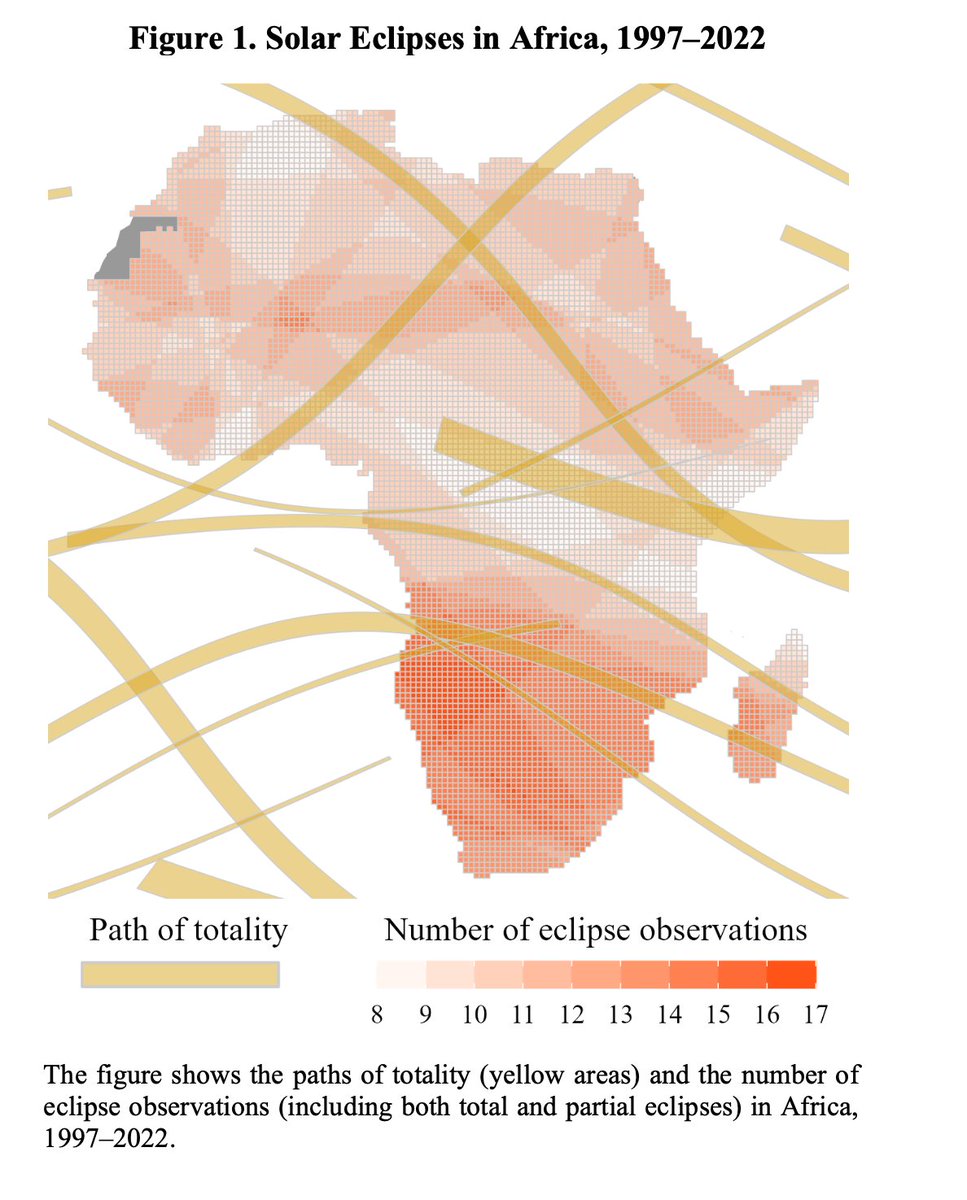

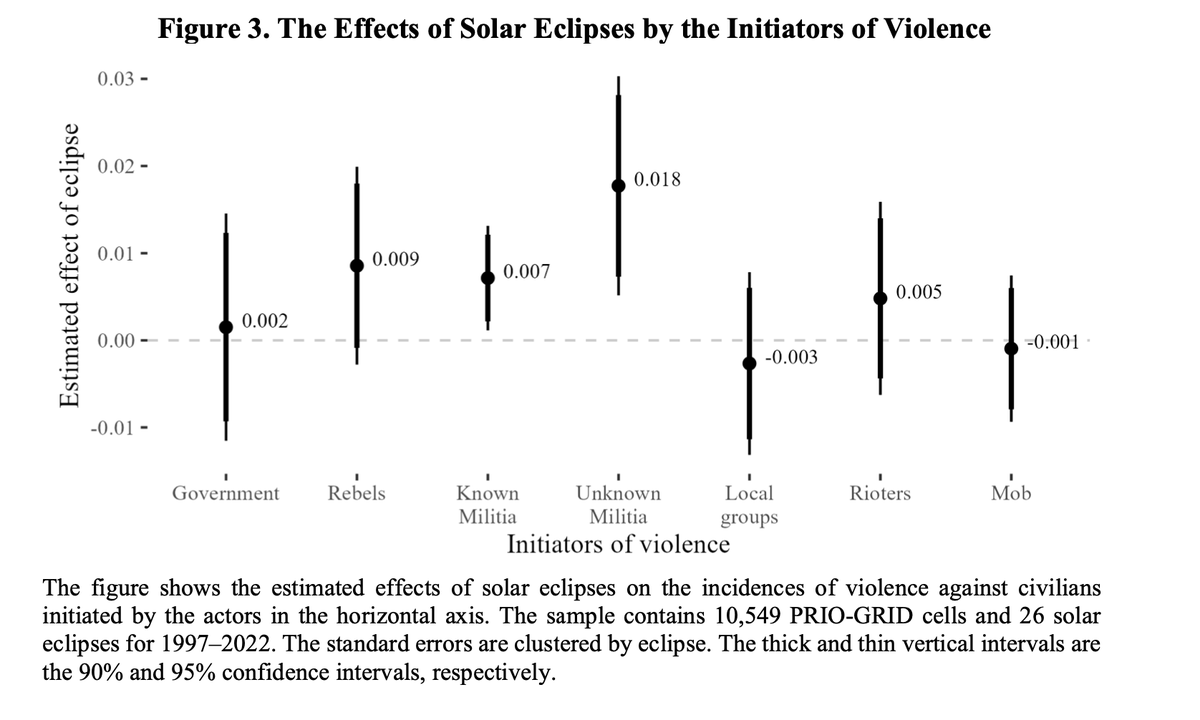
2
8
81
The really funny thing is that people are dunking on Nate because the bet showed he was confident in the moderate prediction, but ignoring not taking the bet meant Rabois wasn't confident in the extreme prediction.

Econometrics Twitter to students: you have to really understand the fundamental problem of causal inference otherwise you'll end up looking goofy like Mr. Rabois. Meanwhile, Mr. Rabois:


5
3
80
There are two kinds of people in science. Those who.1) See the data and code as the actual science.2) See the english and meme as the actual science .Never going to bridge that gap. Those are two totally different sets of professional standards and incentives. Two species.
Hard disagree. Code for the paper should be in a ready to go repo already. What are you doing submitting a paper that doesn't have working code? Journals should be demanding it and reviewers ought to be reviewing it.
4
12
77
I can't stress this enough - your audience when debunking bad statistics isn't civilians. Civilians consume research as edutainment. So do most producers for that matter. Your audience is other methods people. We're the only ones who 1) care 2) can tell what's a good job.

In response to this community note and other critiques, we have added a preface to the post, explaining that we did NOT offer a meta-analysis, and explaining why the note is incorrect. Here is the revised post with new text at top and bottom:.
4
3
72
Amazing walk-through of 12 different p-hacking strategies and what they do to the false positive rate. Bottom line, even with pre-reg authors have too many degrees of freedom to "let the data speak for itself.".Can always get stars,.
1
20
76
I don't know how to disrespect this attitude harder. Let's try.-If you don't want your code reviewed then you aren't a competent modeler. -If reviewers won't review your code then they aren't competent modelers either. -If neither side is competent then no modeling was 'reviewed'.
Hard disagree. Code for the paper should be in a ready to go repo already. What are you doing submitting a paper that doesn't have working code? Journals should be demanding it and reviewers ought to be reviewing it.
3
9
73
One of the consequences of garbage can ML is that there's no sense of a generative data process. Outliers aren't possible when you're brainlessly just fitting to all data in hand. You need a concept of a DGP for a datum to not have been drawn from it.
4
5
65
Lol. How pathetic is social science that an influencer getting quickly debunked by a grad student gets a dramatic chronicle write-up. Just every day an embarrassment.

“[P]utting your work out and having half of stats Twitter critique” may be a better paper check than peer review, says researcher in the midst of a social media war.

4
7
70
Do bad work on questions that people will find interesting is maybe the single most destructive training we get in social science.

Personally, I believe both types of research deserve recognition. 50 years ago, Hayek observed that when studying complex phenomena, we will never arrive at perfect answers. If we follow Noah's suggestion, researchers might be less motivated to tackle the big questions. 2/3.
2
7
69
How did you choose the name "Pandas" and do you have any other libraries under development?.

For my podcast (Clearer Thinking), I am interviewing a sociopath who is very insightful about their own mind and about sociopathy itself. What’s a question you’d be interested in having me ask them?.
1
5
66
It's wild that "evidence based medicine" was a controversial and political move when introduced, and then so much of the stats were sloppy that we're now pushing "actual evidence based medicine" and will soon be down to "no seriously, draw the f*cking DAG, based medicine".
4
7
66
Most of industry science work is just going as long as you can until being ordered to do something mathematically incorrect and then moving.


0
3
66
Compelling reasons not to use Bayes:.-you know literally nothing about your subject.-all potential values are equally reasonable, including impossibly large ones.-you've got so much impossibly high quality evidence on your exact estimand that we'll have to build a statue of you.
4
6
63
I honestly see no value in the publication system. Tie up work until it's no longer state of the art to get back a few inane words on framing. It's a joke from start to finish.
4
3
61
Statistical debates would be a lot more meaningful if instead of "bias" we called it "doing your job." This design suffers from severe "not doing your job." The "doing your job / variance tradeoff". Etc.
2
5
58
Social science is sometimes a lot like the Make a Wish Foundation. A tenured professor will come to your room and use data to tell you whatever you want to hear. Meanwhile a bunch of methodologists stand quietly outside knowing it's not true but it won't matter in a few days.
1
4
59
Just remember there are people who think this is funny but unironically defend the linear probability model.

If you flip a coin twice, the chance you get heads at least once is 50%+50%=100%. If you flip a coin three times, it would be 150%, but that is a whole other thing….
2
4
50
"Why is all this work trash AND there's simultaneously a mental health crisis?".'I dunno professor, is there literally anything else in history with a structure this detached from reality? Child kings?'.
0
2
51
Pro Tip: Uninformative priors don't look anything like you expect in the sample space of the actual outcome. Don't just pick priors in the blind, simulate the full null model with just priors, and verify it makes predictions like you expected in your head.

6
8
57
On how DAGs are only as good as the people using them.
0
12
56
Bayes is complete overkill for most jobs. If your job doesn't involve:.-synthesizing existing knowledge.-acquiring new evidence, or.-correctly telling others how that new evidence should alter their beliefs.then you absolutely don't need Bayes.
Compelling reasons not to use Bayes:.-you know literally nothing about your subject.-all potential values are equally reasonable, including impossibly large ones.-you've got so much impossibly high quality evidence on your exact estimand that we'll have to build a statue of you.
4
7
52
Bayes is the math for formally incorporating previous information with new information. That's it. The alternative is to incorporate prior information informally, in natural language, with a bunch of ad hoc and post hoc rationalizations and decisions. You know, objectivity. .
Bayesian inference with informative priors is not inherently “subjective”.
3
9
48
Editor-in-chief of Scientific American. Most institutional damage is self inflicted. One of the worst consequences of the first Trump term was how deeply ideological and self-righteous scientific publishing became and how much bad work that elevated. 100% going to happen again.

3
6
53
The second someone can arbitrarily punish you, you have to keep that person/group/institution happy in perpetuity. They own you. They can decide at any point in time that something you did in the past fails tomorrow's criteria. Your only option is to pay them off so they don't.
2
2
53
Math isn't something you learn it's something you get used to. I haven't proved OLS is BLUE since grad school. Being able to do that on demand isn't what's important, it's enough experience to understand why it was necessary, to read results based on it, to know what it buys.

after working with data scientists whose jobs are more ostensibly math related than SRE, I think you could banish 90% of them to the shadow realm if you pop quiz them on high school math. There is no shame in admitting you need the refresher and then doing the refresher.
2
3
47
Trying to explain most modeling work is just performative. Look, a guy literally typed an uppercase T because it looked like a confidence interval. It does not matter what the guy believed. Or if he used ", robust" and not "T". It's a little play.
4
2
47
The credibility revolution failed in a few interesting ways:.-Cute identification strategies made stronger assumptions and shifted the burden onto the reader to debunk them. -Measurement got completely ignored. 3 pages on the cute ID strategy and three entire sentences on the DV.
2
6
49
There's almost no market for doing statistics correctly. The closest is consumer protections? But that's a weak and often captured market. Academia is publish or perish. Industry is not stop sales. Finance only has to work on short time frames. Maybe insurance?.
7
6
48
I see this shit constantly. Someone senior who can barely code will say 2+2=chair.A junior person will kill themselves trying show chair isn't even a #.Then the senior person will.-dismiss them.-keep asking for more and more work .-eventually claim to have known the whole time.
2
3
47
Scientific careers aren't built on correctness but on social communities around shared memes. You're judged by your ability to reproduce and add more professionally pleasing memes to that pile. Not by whether any of it is true.


Scientists: if you would decide to do your future research at a very high level of scientific rigor, how would that affect your future career in the field?.
3
5
49
The most horrifying part of rising up the ranks of any field is getting at the top & realizing nobody knows what they're doing, there are no adults, it's a bunch of people just trying to feed their kids and selling whatever people are buying. Trust is for children.

For most people in most contexts, it's more reasonable to trust the science than to question it, precisely because they neither have the time nor the ability to do science.
1
3
47
This is the right way to think about it. Synthetic data mathematically cannot teach your model anything new that isn't in the original corpus. It's just an inductive bias that you're applying as the modeler, like any other weighting, cleaning, model architecture decision.

One thing I was very wrong about ~4yrs ago is how fundamental “synthetic data” in ML would be. “Obviously” due to data-proc-inequality, synth data should not help learning. The key flaw in this argument is: we do not use info-theoretically optimal learning methods in practice 1/.
2
8
47
How to keep economists from getting away with measuring literally nothing correctly as long as they have a cute identification strategy is a question pretty much everyone in science is struggling with right now. Science was out manoeuvered by PR from the 'credibility revolution'.

This should lead academics in both fields, economics and history, to a series of unpleasant but necessary questions. How can our economist colleagues undertake this kind of work without securing minimal advice from competent specialists in relevant fields ?.
2
7
42
Guide to quantitative social sciences:.Sociology - lying with statistics for class warfare.Political science - lying with statistics for partisan warfare.Economics - lying with statistics for personal aggrandizement.
1
2
44
The burden of proof is always on the modeler, never the reader. For APSR to basically say "readers should know small N work we publish is trash" is an amazing misunderstanding of the burden of proof in science.

However, the APSR started an investigation which lasted until December ’22 and concluded that no corrigendum is necessary. This decision was based on an undisclosed response from the authors and a single reviewer report, summarized by the APSR as described in the picture below.

1
1
45
You have no idea how hard it is to teach people that their fancy ML blackbox isn't interpretable. It's doing things that you don't understand, and unless you have an absolute 1:1 mapping between it an the expected outcomes notation for the experiment you wish you had, just don't.

Crucial point here is that regularization is not always conservative. Normal priors/ridge regression will prioritize shrinking larger coefficients. If those were blocking backdoor paths (removing confounding), you can end up inflating your estimate of interest.
2
3
45
8) This is typical of econ work. Spreadsheet they're not allowed to share goes in. Bad STATA code in the middle. Econ-speak comes out. All the proper nouns, scales, and human interpretable units stripped away. This is an argumentative strategy to keep your brain from engaging.
1
7
45
"Now what if, and hear me out, instead of using 8 parameters to fit this regression we use 200 million?".

Google presents OmniPred: Language Models as Universal Regressors. Presents a framework for training language models as universal end-to-end regressors over (x, y) evaluation data from diverse real world experiments. repo: abs:

3
3
43
4.5y later we get our 4th terrible mask RCT. The Twitter debate is equally inane. Everybody skipped to the results and then decided if the research design was good. Hell. COVID killed us all, we're in purgatory, this is how Satan tortures methodologists./n.
2
5
45

Matrix algebra that can gaslight the user directly in English is my apocalypse. That's taking data science jobs from humans.


1
3
43
Blue is 2016-7 Twitter. A group of people who perceive themselves to be sufficiently homogeneous to crank ideological signalling and aggression to 11 without fear of losing followers. It's 4chan for Phds right now. You get this with mono-cultures like Subreddits or early adopters.

Friends, I don't think the blue site is new town square. Announced our new AI tool to improve education (). Response: I'm "only good as firewood", shame!, gross, scab. not from randos, but from academics & a Yale Review Editor. "Trust, Safety, Community"?

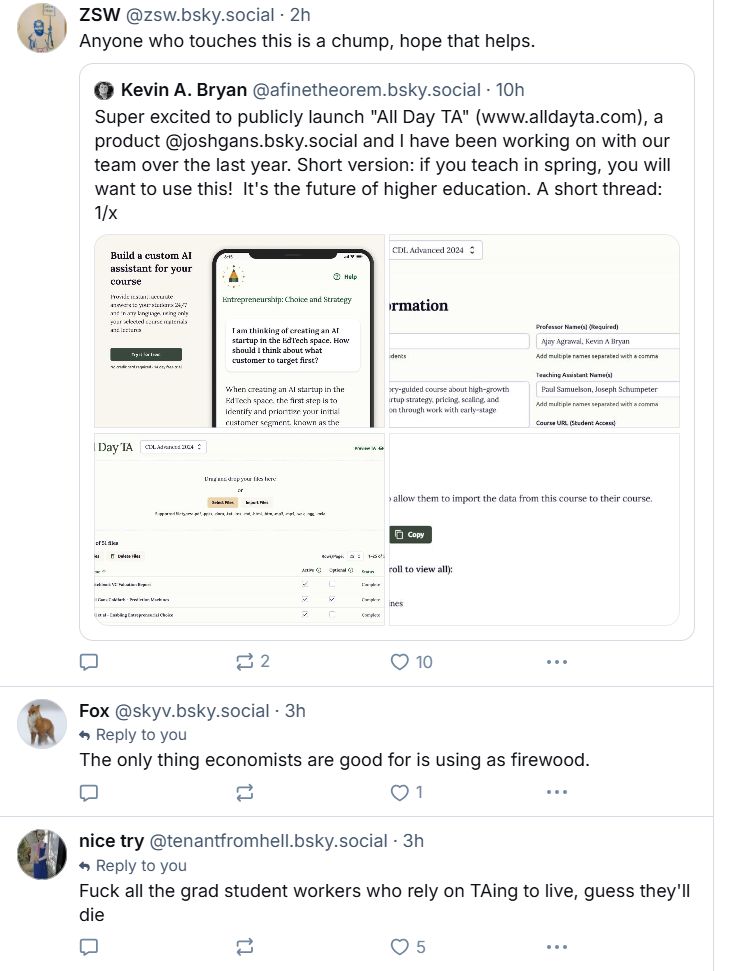


3
2
45
Like Marvel, going to start releasing teaser trailers for my methods rants. Pre-release alpha draft coming together.

0
4
44
FWIW, DAGs are just an intermediate representation of a possible data generating process. Their primary value are.-making it clear what assumptions are being made for a given specification.-letting the reader more easily imagine alternatives .They SHOULD generate disagreement.

@rlmcelreath I doubt that at the end there would be full disclosure of ALL the DAGs tried and discarded. Wouldn’t all of that be the equivalent of DAG-hacking? . Isn’t there an “inferential penalty” to be paid for it?.
1
6
39
Some initial thoughts on this amazing work:.1) It's not good news. Of the work that's most likely to be passable, of those that the authors provided sufficient information, in just the narrow area of computational reproducibility, there's usually at least one major problem.

Our first meta paper is out!! This paper combines our first 110 completed reproductions/replications. This is joint work with 350+ amazing coauthors. We summarize our findings below.
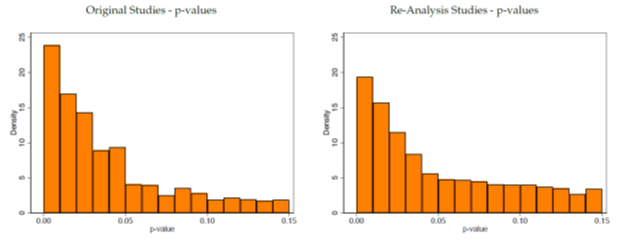
2
3
42
With excitement around O3, good time to review some basics around what models are and how we should talk about them. There's an unfortunate 'god of the gaps' problem where the more performance we observe with less understanding, the more creative and unscientific the fanboying.

@RexDouglass So, what would you describe as a convincing evidence for not being a parrot?.For me, inability to generalise outside distribution according to inherent correlational (or better, causal) patterns, that is giving parrot evidence.
1
3
42
The nightmare of it is that.-to be identified.-an estimate must have some justification for that specific DAG and not any of the other ones.-which never happens so it's just implicit,degenerately strong spike 0 priors doing all the work.-and then finding 2 reviewers who don't.

"Causal inference is a trivial problem if you know the DAG. Research design is outdated.". season's greetings!

2
3
39
I always get a follower bump when pointing out the methodological dumpster fires of science, and half of them are literally in cults. My guy, if Stanford GSB isn't getting the math right, I promise you the new White National Baptists for Trump aren't remembering to carry the one.
1
2
36
One thing that trips people up about DAGs is that they're not the ceiling, they're the floor. You already have a dumpster of concepts and suspected relationships. I'm just asking you to go to the whiteboard and draw it. Especially the parts you are assuming have no relationship.
1
5
32
Without taking anything away from this paper, this should have already been known. We used to joke 15 years ago about how the true N in IR was only 3. And people create multimillion directed country year data like that's really IID and those are real stars. Just ", robust" lol.
3
4
35
There's nothing in bayesianism you can't find in frequentism, just done worse and in natural language. You can find the same cultural fight between any group and its more formalized version. The more formalized group is always annoyed with the less formalized one and vice versa.


what keeps me somewhat sceptical wrt bayesians is the slightly weaker version of the cult mentality that i know from the mmt crowd: (1) learning about p(a|x) is treated as quasi-religious revelation, (2) its grandious claims ("science itself is a special case of bayes’s theorem").
3
1
35
Qualies coming out of the woodwork to explain how asking ideologues to tell you their feelings about something is considered a legitimate way of learning about that thing. Yup.

(1/2) We need more attention to selection bias in qualitative research. A new study in a top sociology journal examines "how young people experience policing," but it draws only on interviews of youth in an organization devoted to abolishing the police, one that bombards.

1
0
36
The problem with "trust science" is in part that there are very few jobs that are just "scientist." What you're usually really saying is "trust grant writers" or "trust people who can get a paper through R&R on their third try." Most of them can't model to save their life.
2
2
33
To recap, half of researchers perceive themselves as.-Faking lit reviews that can't possibly serve as a prior.-Faking hypotheses to retroactively make a known correlation in the data look like a test of a prior theory.-Picking the model that gets the needed p-value.What is.

New survey: Over half of researchers in Denmark and an international sample from Britain, America, Croatia, and Austria anonymously admitted that they:. - Cite papers they don't read.- Cite irrelevant papers.- Don't put in effort in peer review.- Misreport nonsignificant findings

1
7
36
Learned two things last night.-I'm still capable of coding for 20 hours straight.-I'm too old to be coding 20 hours straight.
2
0
34
"The statistical power of Christ compels you. ".
In 1599 the church used a placebo controlled trial to test if a French girl was possessed by a demon. Holy objects and identical, non-blessed objects were shown to the girl. "She reacted similarly when exposed to both genuine and sham religious objects"

2
4
35
Hot take: Minimum effect size of interest is a made up concept to sell power analysis and would require all kinds of additional machinery about downstream user preferences that's never done and probably doesn't exist.
8
3
33