
Michael Poli
@MichaelPoli6
Followers
2K
Following
2K
Statuses
352
AI, numerics and systems @StanfordAILab. Founding Scientist @LiquidAI_
Joined August 2018
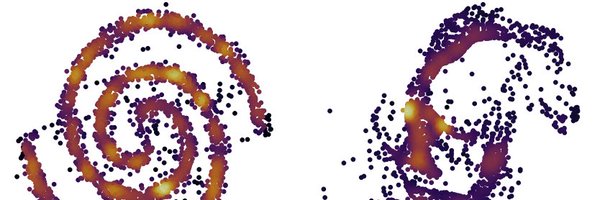
An absolute privilege to see our work on Evo🧬 highlighted on the cover of the latest issue of Science. Thank you to all the friends and collaborators at Stanford (@StanfordAILab) and the Arc Institute (@arcinstitute) @exnx @BrianHie @pdhsu @HazyResearch @StefanoErmon and more. A lot has happened since the first release of Evo. We have made public the original pretraining dataset (OpenGenome)—links below—and will soon release the entire pretraining infrastructure and model code. We continue to push the scale of what's possible with "beyond Transformer" models applied to biology, in what could be among the most computationally intensive fully open (weights, data, pretraining infrastructure) sets of pretrained models—not only in biology, not only with new architectures, but across AI as a whole. While it's super exciting to consider the potential impact of Evo on biology, I also think it's valuable to spend a few words on the implications that Evo and related projects have for AI. There has been a flurry of work over the last couple of years (from the great people at @HazyResearch and a few other places) on developing bespoke model designs as "proofs of existence" to challenge the Transformer orthodoxy, at a time when model design was considered "partially solved." We have seen time and again that various classes of computational units outperform others in different modalities, on different tasks, in different regimes. We've seen this in scaling laws, on synthetics, on inference. It's now undeniable that, with a little bit of creativity, improving scaling is not only approachable but also particularly rewarding—which is exciting at a time when pure train-time scaling appears to be under attack by some (oh no, we are hitting a wall!—rant for another day). We have the tools to develop and adapt foundation models to ensure they fit the requirements of different modalities. We have the means to remove questionable tokenization schemes and make sure AI remains true to its promise of learning "end-to-end." And while I'm obviously excited by convolution-attention hyena hybrids due to their balance of efficiency and quality across domains, there's a lot more to do, particularly when considering multiple angles during model design: deployment platforms, inference requirements, target benchmarks, effects of architecture design on sampling, post-training methods... Flexibility is what we need—and I'm looking forward to sharing more soon about how we're thinking about this problem.

A new Science study presents “Evo”—a machine learning model capable of decoding and designing DNA, RNA, and protein sequences, from molecular to genome scale, with unparalleled accuracy. Evo’s ability to predict, generate, and engineer entire genomic sequences could change the way synthetic biology is done. Learn more in this week's issue:

3
26
156
RT @adamlewisgreen: just one more striped hyena block bro, I promise. DNA is all you need dog, trust me. the only thing we're missing is ri…
0
12
0
RT @aaron_defazio: The sudden loss drop when annealing the learning rate at the end of a WSD (warmup-stable-decay) schedule can be explaine…
0
28
0
RT @linzhengisme: 🚀 Meet EvaByte: The best open-source tokenizer-free language model! Our 6.5B byte LM matches modern tokenizer-based LMs w…
0
84
0
@_arohan_ This is also another way to understand why certain types of hybrids work so well, most have decay built in
0
0
3
0
0
11
Regardless of what you think of their models, @deepseek_ai's tech reports are always top-notch. Their scaling laws report is still my go-to reference for folks getting into scaling. MTP ablation: great to see. The long context evals are a bit undercooked with just 128k NIAH, but that was clearly not their focus. Also, a reminder that ~40B active param model for ~15T tokens at shorter context is ballpark what you'd expect to be able to train on your average training stack on 2k H100s for ~2 months. What is particularly impressive is that they did this on nerfed hardware (H800), and how far they pushed the benchmarks.

🚀 Introducing DeepSeek-V3! Biggest leap forward yet: ⚡ 60 tokens/second (3x faster than V2!) 💪 Enhanced capabilities 🛠 API compatibility intact 🌍 Fully open-source models & papers 🐋 1/n

1
7
49
Exciting times ahead. Liquid is a special place, join us for the next phase!

We raised a $250M Series A led by @AMD Ventures to scale Liquid Foundation Models and accelerate their deployment on-device and at enterprises

0
1
16
Highly recommended! Being hosted by Eric is a treat - super fun to geek out over fundamental research with him

Internships, Office of the Chief Scientific Officer, Microsoft
0
1
11
Learned so much from @gdb, amazing human

During my sabbatical, one project I really enjoyed was training DNA foundation models with the team at @arcinstitute. I've long believed that deep learning should unlock unprecedented improvements in medicine and healthcare — not just for humans but for animals too. I think this work moves in that direction, as one fundamental step towards modeling virtual cells. So much of progress in modern medicine has come from improving our understanding of the biology. I predict in upcoming years we'll find that humans are just not that good at understanding biology compared to neural networks. Neural networks seem particularly well-suited for biology because: - DNA is the language of biology. For humans, our spoken languages are natural while DNA feels foreign. For neural networks, human languages and DNA are equally foreign. It'd be quite amazing to see neural networks as fluent in DNA as we've seen them be in human language... - As more biological knowledge has been discovered, biologists have had to become more specialized to compensate. It's possible to get a PhD by studying one specific mechanism in a cell. By contrast, breadth isn’t a challenge for a neural network — they can readily absorb all human knowledge. (Of course, with great progress to be made on depth of understanding and reasoning.) - For humans, the reams of available data make biology overwhelming. For neural networks, more data leads to better results. At a personal level, it was very fun to apply my existing skills with training and scaling neural networks to an entirely new domain. I felt lucky to temporarily join a great team which has already been making great progress. It was a good reminder of how versatile this technology is — in some ways, it's completely unreasonable that the same generic algorithm and engineering should yield results in DNA in addition to language, code, images, videos, etc.. Overall, it makes it feel like the AI field has been creating a “data abstractor” over these past 80 years, which can be pointed at any kind of data and derive some useful sense of its structure to help make all of our lives better. We made exciting progress, and the @arcinstitute team should have more to share in upcoming months! I had a lot of fun working with them, and think there’s a lot of exciting discoveries waiting to be had coupling computational techniques with their wetlab capabilities.

1
1
26
0
0
2
@AlexandreTL2 yes, STAR supports optimization of parallel interconnections across different LIVs, so those patterns are all in the search space
1
0
1
RT @ai_with_brains: Today, we report advances in automated neural network architecture design and customization that we have been working o…
0
6
0
RT @keshigeyan: 1/ [NeurIPS D&B] Introducing HourVideo: A benchmark for hour-long video-language understanding!🚀 500 egocentric videos, 18…
0
51
0
RT @morph_labs: Imagine if you could: Create instant parallel versions of a running cloud computer with zero overhead Explore millions of…
0
26
0
0
0
2