

Lucas Atkins
@LucasAtkins7
Followers
1,356
Following
252
Media
92
Statuses
1,177
Labs @arcee_ai . Opinions are mine, yet not really mine, and definitely not my employer's.
Joined October 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Ohio
• 590465 Tweets
Apple
• 553839 Tweets
James Earl Jones
• 411611 Tweets
James Earl Jones
• 411611 Tweets
Springfield
• 390078 Tweets
Haitians
• 335115 Tweets
Wayne
• 279935 Tweets
Kendrick
• 270326 Tweets
iPhone 16
• 235687 Tweets
Super Bowl
• 207038 Tweets
Victoria
• 147244 Tweets
Nicki
• 134839 Tweets
Kerem
• 132296 Tweets
Fassi
• 53422 Tweets
Jets
• 51060 Tweets
Lion King
• 45016 Tweets
Field of Dreams
• 43030 Tweets
Birdman
• 41729 Tweets
49ers
• 37776 Tweets
Tapia
• 35018 Tweets
Kassia
• 30673 Tweets
SIEMPRE FURIA SCAGLIONE
• 24620 Tweets
#BizimÇocuklar
• 22343 Tweets
Topher
• 21052 Tweets
対象作品
• 18834 Tweets
Arda Güler
• 17871 Tweets
The Sandlot
• 16339 Tweets
Coming to America
• 15534 Tweets
ガチャチケット
• 11751 Tweets
Odegaard
• 11523 Tweets
May the Force
• 11289 Tweets
Spider-Man 4
• 11180 Tweets
#部長K
• 10961 Tweets
#LINEマンガガチャ
• 10884 Tweets
Rest in Power
• 10233 Tweets




















Pinned Tweet

We've been working on this for quite some time, and I'm thrilled to share a preview of Arcee-Swarm. Instead of relying on a single large generalist model, Swarm utilizes multiple domain-specialized models working together to deliver exceptional results with both speed and nuance.
7
14
83
Tonight, I am releasing eight Gemma fine tunes and a beta of their combined mixture of experts model named GemMoE.
GemMoE has ALL Gemma bug fixes built-in. You do not have to do anything extra to get great fine tunes/inference with it. It's a beast of a model.
This would not

22
98
657
I'm excited to release a project I've been working on the last couple of weeks.
Qwen1.5-8x7b:
And the accompanying dataset created with the intention of encouraging MoE models to organically develop their own experts:
The purpose

12
52
273
The word distillation is thrown around a lot lately - but there aren't many good resources for doing it yourself. Today I'm thrilled to announce a new open source project from
@arcee_ai
and our newest research initiative Arcee-Labs: DistillKit.

4
19
121
Happy to share DeepMixtral-8x7b-Instruct. A direct extraction/transfer of Mixtral Instruct's experts into Deepseek's architecture. Performance is identical, if not even a bit better, and seems more malleable to training.
Collaborators
@erhartford
@FernandoNetoAi
.

6
16
114
I’m going on a staycation this weekend, but I wanted to get this out so I’m not distracted: llama-3-MOE.
This is a departure from previous MOEs I’ve done. This uses
@deepseek_ai
’s MoE architecture, and not Mixtrals. There is no semantic routing, and there is no gate. All 4

6
14
100
Here is our initial 22b model conversion from Mixtral 8x22b. We had the base model since Mixtral was first released, but it was left behind as our compute from
@CrusoeEnergy
went towards more ambitious projects using laserRMT. It is a great starting point for exploring expert

9
20
100
@iScienceLuvr
The amount of people you’re going to trick with this shows just how good Sora is.
4
1
90
My whole open-source career started with Qwen, and it was an honor to get to train Qwen2 on Dolphin prior to release. The 7b and 72b models are the best we've ever made, and I hope you're as delighted by them as we are. Truly - GPT4 at home.

💗Hello Qwen2!
Happy to share the Qwen2 models to you all!
📖 BLOG:
🤗 HF collection:
🤖
💻 GitHub:
We have base and Instruct models of 5 sizes, Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B,

38
153
630
4
3
87
I want to avoid doing long threads for model releases - it seems to be a bit much. For any who missed it due to thread spam yesterday - check out Nova:

10
12
70
I am releasing a version of base Gemma-7b with the bug fixes I implemented in GemMoE. Ensure you "trust_remote_code"
Also made a few other modifications to improve vram use.
Works great. Thanks
@danielhanchen
for your findings.
Enjoy! I believe this model has a lot of unseen

3
5
61
Here is my reworking of the recently released Quiet Star paper () - so that it actually uses the thought tokens.
This model can think before it predicts the token. However, it needs further fine-tuning to generalize beyond math.
This took a lot of work.

5
7
60
Today Arcee is releasing two datasets:
1. The Tome - this is a 1.75 million sample dataset that has been filtered to train strong generalist models. This is the dataset that was used to train Spark and Nova
2. Agent-Data: This is Arcee-Agent's dataset, comprising different

4
13
62
I'm sharing the tools I modified to make GemMoE, along with two improved models/methods. Both models have not been fine-tuned whatsoever and are quite malleable.
I also created a variant of
@maximelabonne
's lazymergekit specifically for making your own GemMoE.
I have reached my

7
5
60
Want to fine-tune Gemma & can't use
@unslothai
? I've implemented
@danielhanchen
's bug fixes using TRL. Works for me & should for you. Dora toggle available. Thanks
@_philschmid
for initial instructions 1.5 weeks ago!

1
7
51
GemMoE now works out of the box with Axolotl (just set trust_remote_code=True in the yml), and in correcting that, I spotted a few bugs that I squashed. It should perform even better. Might need to warm up the experts again though!
@winglian
@erhartford
2
5
44
If any of you want to use
@huggingface
jupyterlabs to run
@winglian
's axolotl - I've attached the dockerfile I created to do so. Install as normal, all dependencies and cuda/torch needs are taken care of.

0
7
44
Life update: I'm excited to announce that I've officially joined
@arcee_ai
! I look forward to the journey ahead, making SLMs as helpful and useful as possible.
12
0
44
Here is the code i've been using to implement
@AIatMeta
's branch train mix for creating mixture of expert models via tokenized routing w/o pretraining.
Use the moe-fix branch from mergekit for the yaml:

3
6
42
Here is an early release of a 4xGemma model. It utilizes a new training method using a custom implementation of
@AIatMeta
’s Branch Train Mix.
This uses tokenization routing, not semantic. It’s ~4x more efficient than previous GemMoE models.
Early interactions are promising.

4
7
40

1
10
39
Aligning this model was one of my first duties
@arcee_ai
. It’s a tremendously powerful financial analyst, and punches well above its weight. We’re releasing a checkpoint pretrained on 19B tokens worth of SEC filings.

5
10
40
This got delayed due to DistillKit - but here’s Llama-Spark, thanks to
@PrimeIntellect
for sponsoring this training run. They’re great, check them out.

2
8
39
110b was tricky. Even with 8x H100s, getting it working with something like accelerate was almost impossible. We ended up doing laser, and targeted 50% of the least dense layers. I’m pleased with the result, and grateful to
@JustinLin610
and
@Alibaba_Qwen
for making such a

Dolphin-2.9.1-Qwen-110b🐬 is released! The first Dolphin with MMLU over 80! Thanks to
@Alibaba_Qwen
for the awesome base model and
@CrusoeEnergy
for the compute sponsorship, my crew
@LucasAtkins7
and
@FernandoNetoAi
! Uncensored models can and will hurt your feelings 😱 You are

13
43
272
3
5
38
1
0
36
Currently exploring freelance opportunities as I transition between jobs. If you or someone you know needs synthetic datasets, custom model architectures, pre-training, fine-tuning, or anything even tangentially related to machine learning, my DMs are open.
2
6
34
I don’t know how this got missed (unsloth is up there) but
@danielhanchen
gets much of the credit for the bug fixes being built in. He found them, and he implemented them in unsloth. I had to do some adapting to make it work with my architecture-but 99% of that is Daniel.
0
1
32
A very powerful model, trained with Spectrum, merged with Llama-Spark and utilizing the Tome/Agent-data datasets (among others). It's nice to have the pipeline externally validated. Great job
@akjindal53244
- it's clear a lot of care was put into this.

🚀 𝐋𝐥𝐚𝐦𝐚-𝟑.𝟏-𝐒𝐭𝐨𝐫𝐦-𝟖𝐁 has arrived! A new 8B parameter LLM that outperforms
@Meta
𝗟𝗹𝗮𝗺𝗮-𝟯.𝟭-𝟴𝗕-𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁 and 𝗛𝗲𝗿𝗺𝗲𝘀-𝟯-𝗟𝗹𝗮𝗺𝗮-𝟯.𝟭-𝟴𝗕 across diverse benchmarks! Our new 8B LLM pushes the boundaries of what's possible with smaller language


16
58
252
1
9
32
For those planning on fine tuning Gemma today: I'm releasing the 150k subset of the larger MoD dataset. Features data from
@Teknium1
,
@jon_durbin
,
@huggingface
,
@WizardLM_AI
and many others, including myself. Enjoy!

1
4
32
I’ve had the good fortune to play around with Gemma 2 for the past couple of days. It’s very good, and doesn’t suffer from any of the launch related bugs from v1. I’m grateful to have another 9B beast and 27B is a welcome size category.

Gemma 2 released! Google just released the next iteration of its open LLM! Gemma 2 comes in two sizes, 9B & 27B, trained on 13T tokens. Gemma 2 27B approaches
@AIatMeta
Llama 3 70B performance!
First
@lmsysorg
Chatbot Arena evals place Gemma2 27B around
@AnthropicAI
Claude 3


9
128
422
2
2
29

1
8
30
Grateful that we finally get to share this. Spectrum is how we’ve trained some of our most performant models (including Qwen2-72b) - and we’re delighted to share some comparisons against other training methodologies.
Cognitive Computations presents Spectrum, a paper. Thanks to
@TheEricHartford
,
@LucasAtkins7
,
@FernandoNetoAi
,
@DavidGFar
and everyone who helped. (1/5)

11
29
146
1
3
27

1
6
26
A demo of arcee-spark, using it alongside Florence from
@MSFTResearch
and Whisper to analyze what makes an ad "ironic."
2
3
25
The first model that I got to work on from start to end
@arcee_ai
. It was a team effort, and I'm proud of how we delivered. It's an absolute delight, and we're just getting started.
@JustinLin610
Thank you for Qwen.
Qwen2 has a lot of potential! 👀
@arcee_ai
released Arcee-Spark their first
@Alibaba_Qwen
2 7B based custom model, outperforming
@AIatMeta
Llama 3 8B instruct on AGIEval and
@OpenAI
GPT-3.5 on MT-Bench.
> Fine-tuned Qwen2 Base on 1.8 million samples
> Merged with

3
17
94
3
6
26

Screw it - deepseek v2 awq:

2
6
25
This is a beast.
Announcing Dolphin-2.8-mistral-7b-v0.2
Trained on
@MistralAI
's new v0.2 base model with 32k context.
Sponsored by
@CrusoeCloud
,
@WinsonDabbles
, and
@abacusai

24
71
550
1
2
25
We’re building exodia watch out.

3
1
24
@patio11
Neat tip: if it’s struggling with LUA and you’re getting a lot of bugs. Have it translate it to python and run it in code interpreter. It finds a LOT of bugs and nil errors that way. Then have it translate it back. I use this for making World of Warcraft add-ons!
0
2
23

@basedjensen
This is an upmerge of Llama-3-70B, that some people created with mergekit so people could practice loading/training the model once it is released.
0
2
23
This was challenging to get right, and much of this involved
@stablequan
’s dedication and hours of tinkering. This used Spectrum. It’s an absolute monster.
Cognitive Computations drops DolphinVision-72b
Our first multimodal model, and it's a banger!
Built on llava-next and dolphin-2.9.2-qwen2-72b
Created by
@stablequan
and
@TheEricHartford
Massive thanks to
@CrusoeAI
and
@TensorWaveCloud
for the compute power!
Shoutout to

20
48
338
3
4
23

2
1
22
Just finished a DPO of Qwen1.5-7B. Will run it through
@Teknium1
's OpenHermes 2.5 later this week. Just need to take a look at my compute budget!

1
4
22
DistillKit allows for direct distillation from a teacher model without the need for generating synthetic data. We have to techniques at launch - logit based and hidden states based. Both give performance uplift compared to standard SFT when trained on the same data. Hidden-states

1
0
22
Here is LaMoE-Medium, an a followup to my first llama MoE. It is much stronger in reasoning tasks, creative writing, code generation, and function calling. Enjoy.
Thank you
@CrusoeEnergy
for sponsoring the compute.
And as always,
@erhartford
and
@FernandoNetoAi
.

4
0
22

You see the key to success is tricking
@maximelabonne
into doing your job for you.

@UnslothAI
@huggingface
I'm also releasing FineTome-100k, a refiltered subset of arcee-ai/The-Tome using fineweb-edu-classifier.
It's super high-quality data, perfect when you need extra samples to concatenate with a dataset.
💻 FineTome:

1
1
38
2
1
19
I cannot stress this enough: More to come.
Cognitive Computations presents Dolphin-2.9.2-Mixtral-8x22b, trained with a new dataset SystemChat 2.0, designed to teach Dolphin to obey the System Prompt, even over a long conversation. This release is brought to you by our compute sponsor
@CrusoeEnergy
and our inference

22
25
214
1
1
20
Gemini pro 1.5 is easily the most useful LLM I have every used. OpenAI should watch this closely.
5
0
19
I've decided to rewrite this from scratch for inference/fine-tuning. Follow along here: ""

Here is my reworking of the recently released Quiet Star paper () - so that it actually uses the thought tokens.
This model can think before it predicts the token. However, it needs further fine-tuning to generalize beyond math.
This took a lot of work.
5
7
60
0
2
19
Here's a WIP for a second version of "The-Tome" dataset. Removed infinity-instruct and added magpie ultra/gpt-4o-math.
Not sold on it yet - but sharing it regardless. It's ~1m samples. 👇
1
4
17
@Teknium1
Yeah that's what's interesting. EOM could be a holdover for End of Media or something of the sort for multimodal tests.
0
0
18
Arcee is all in on Spectrum. CPT results are great - and we've optimized it to be ~40% faster than training the full model. Less catastrophic forgetting, faster training, less $. What's not to like?

Ready to learn more about the technique called Spectrum for optimizing
#LLM
training?
Spectrum:
⏲ Reduces training time
📝 Improves memory efficiency
🧠 Minimizes catastrophic forgetting.
More in this article ⬇️ by our
@LucasAtkins7
#nlp
#GenAI
0
1
6
1
2
18
They don't hold back. My god. 🐋

DeepSeek AI
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
↓
paper:
0
10
83
0
1
17
More dolphins incoming.

Today is the first time I have ever had 4 builds running at once. Sponsored by
@CrusoeEnergy
dolphin-2.9-mixtral-8x22b - eta tomorrow
dolphin-2.9-yi-34b-200k - eta monday
dolphin-2.9-qwen-110b - eta one week
dolphin-2.9-dbrx - eta one week
Sleep is overrated anyway! For the
18
16
240
2
1
17
What a day.

Introducing FlashAttention-3 🚀 Fast and Accurate Attention with Asynchrony and Low-precision.
Thank you to
@colfaxintl
,
@AIatMeta
,
@NVIDIAAI
and
@togethercompute
for the collaboration here 🙌
Read more in our blog:

5
96
462
1
1
17
Target acquired.
Nemotron 340b is here. I am in awe, humbled, excited, and intimidated all at once. We can do this!🐬🐬🐬
5
2
48
0
3
17
Don’t let this get swept under the rug. This is amazing.

Sparse Autoencoders act like a microscope for AI internals. They're a powerful tool for interpretability, but training costs limit research
Announcing Gemma Scope: An open suite of SAEs on every layer & sublayer of Gemma 2 2B & 9B! We hope to enable even more ambitious work
16
149
937
2
0
16
@FernandoNetoAi
and I have made the decision to step down from Cognitive Computations.
Our time there has been truly remarkable – we've poured our hearts into developing models that push the boundaries of open source ai, and we're deeply proud of our contributions to Spectrum.
3
3
16
I got to play with these. They punch so wildly above their weight it’s insane.

🔥 Do you want an open and versatile code assistant? Today, we are delighted to introduce CodeQwen1.5-7B and CodeQwen1.5-7B-Chat, are specialized codeLLMs built upon the Qwen1.5 language model!
🔋 CodeQwen1.5 has been pretrained with 3T tokens of code-related data and exhibits
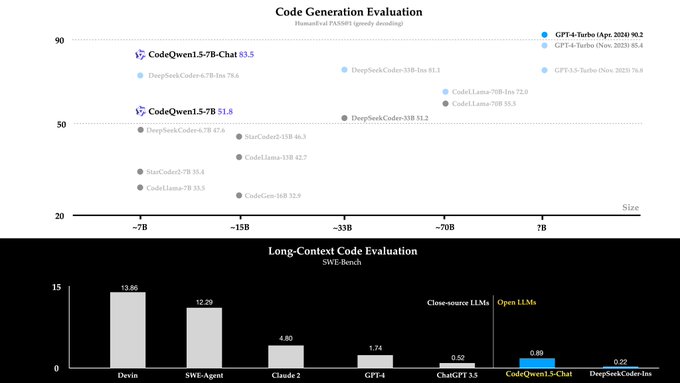
25
121
585
1
2
16
Been waiting for something like this. Dora is extremely promising. Thank you
@jeremyphoward
.

Today at
@answerdotai
we've got something new for you: FSDP/QDoRA. We've tested it with
@AIatMeta
Llama3 and the results blow away anything we've seen before.
I believe that this combination is likely to create better task-specific models than anything else at any cost. 🧵
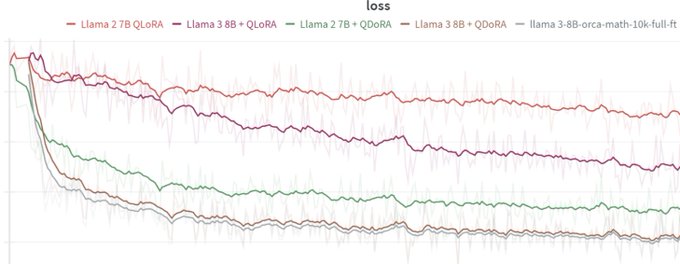
37
303
2K
2
0
16
I'll have to avoid Thursday launches going forward - but nevertheless here's Arcee-Nova: Spark's 72B older brother.

2
3
15
The benchmark for having achieved AGI is just going to be "vibes", right?
6
0
15
You sometimes forget you're talking to a 2B model.

0
2
15
This one was hard to get right - but it talks so well.
@01AI_Yi
cooked with these.
cognitivecomputations/dolphin-2.9.1-yi-1.5-34b
This is our most spectacular outcome ever. FFT, all parameters, 16bit. 77.4 MMLU on 34b. And it talks like a dream.
Although the max positional embeddings is 4k, we used rope theta of 1000000.0 and we trained with sequence length

22
45
221
2
0
15
@agihippo
Quiet-Star was this way. Very cool in theory, but when I hacked it together, in practice it was so unbelievably slow for inference and such a huge vram training bottleneck that you might as well just use a model 8x the size and save yourself the hastle.
1
1
15
Don't sleep on Nova (or what's coming next, for that matter.) - Better yet, just don't sleep on
@arcee_ai
.
🌟 Nothing better than getting stellar reviews of our model releases!
🌑 𝗔𝗿𝗰𝗲𝗲-𝗡𝗼𝘃𝗮 is our highest-performing
#opensource
model...
🧠 We created it by merging Qwen2-72B-Instruct w/ a custom model tuned on a generalist dataset mixture...
(1/4)
#LLM
#GenAI
#NLP
2
4
18
2
4
15
Dolphin: fun sized.
Cognitive Computations presents: Dolphin-2.9.3-qwen2-0.5b and Dolphin-2.9.3-qwen2-1.5b
Two tiny Dolphins that still pack a punch! Run it on your wristwatch or your raspberry pi! We removed the coding, function calling, and multilingual, to let it focus on instruct and


11
13
110
0
4
15
I’m grateful people are enjoying this model so much!


0
0
15
I can't wait to see what you do with it.
And click here for a more technical breakdown:
1
1
14
Meraj was a true cross-team effort led by
@Malikeh5
and Shahrzad Sayehban at Arcee, with help from
@MaziyarPanahi
. Built on Arcee-Nova, it’s a delightful model that excels in Arabic. Try it out. We think you’ll like it.
2
2
16
Btw I’ve seen first hand that
@MaziyarPanahi
doesn’t use DPO or any other RLHF technique. He simply stares at the weights and dares them not to align.
2
0
14

0
0
14
Say hello to Kraken. An Apache-2.0 Collection of Experts model. Tricky to figure out, with results that are better than we could have hoped. 1 router, multiple full sized models. Cheers.

Hi, folks!
Me,
@DavidGFar
,
@LucasAtkins7
and
@erhartford
cannot stop inventing new crazy stuff.
Now we are delighted to announce Kraken, sponsored by
@HyperspaceAI
and
@VAGOsolutions
. (1/N)

3
10
59
0
4
14
Most of these employ our new reranking technique for filtering large datasets. I’ll share that process once I can make it a bit more user friendly.
I published my filtered and uncensored dataset for Dolphin-2.9 on
@huggingface
so if you wanna make your own spin on Dolphin, or just see how Dolphin is created, you can check it out. Thanks to all the upstream dataset creators for open source data!
20
48
420
1
1
14
@erhartford
@deepseek_ai
Wouldn’t hurt, especially since deepseeks whole thing is that there’s no shared knowledge whatsoever, they’re strictly discrete. Let’s do it!
0
1
14
The filtering tech we’ve cooked up is pretty sick.
Dolphin-2.9-8x22b is in the oven.
fft, deepspeed zero3 param offload, 8k sequence, half the layers are targeted.
This is a significantly improved, filtered dataset. Function calling, agentic, math, dolphin and dolphin-coder.


34
42
416
2
0
13
LM studio ships

Phew! LM Studio 0.3.0 with RAG, Structured Outputs API with any local LLM, and tons more features in finally here.
Incredibly proud of the team for the work on this release.
If you want to experiment with LLMs locally on your computer, give it a try!
Works on Mac,
14
20
141
1
1
13
Thrilled to announce Arcee Cloud's launch and our Series A funding. Our SFT engine automatically optimizes hyperparameters based on your model and available memory. This streamlines the entire process, making pretraining, SFT, and model merging more accessible than ever.
Thanks to
@VentureBeat
for covering this huge milestone for Arcee AI…
✨Less than a year after emerging from stealth, we’ve signed a $24 million Series A led by
@emergencecap
✨
💗Proud to celebrate w/ our partners, our team, & our customers 💗
Link to article in replies ⬇️

4
4
15
3
0
13
Interestingly - this was Laser on the top 25% most dense layers, showing similar to performance to when we did 50% for Qwen. Big signal here for training larger and larger models. We’ll need it for 400b.
Another Dolphin-2.9.1 🐬 coming right at you! Thanks
@DbrxMosaicAI
for the excellent base model,
@CrusoeEnergy
for sponsoring the compute! Thanks to my crew
@LucasAtkins7
and
@FernandoNetoAi
for all the support! Uncensored models will hurt your feelings. 😱 You are

10
13
123
3
3
13

1
0
13
You can now use kraken natively with trust remote code.

🐙 New updates on
#kraken
/
#kraken_lora
! 🐙
- Models can now be easily loaded with trust_remote_code=True.
- For better external compatibility with other applications, the base tokenizer can now be used directly for encoding and decoding.
Models 👇:

2
1
8
0
0
13
It shows exceptional promise when distilling from a teacher model that was trained on the same dataset you're training the student model:

2
0
13

Try not to let Llama-3 distract you too much from this absolute gem of a corpus.

Big announcement:
@pleiasfr
releases a massive open corpus of 2 million Youtube videos in Creative Commons (CC-By) on
@huggingface
. Youtube-Commons features 30 billion words of audio transcriptions in multiple languages, and soon other modalities

21
128
581
2
0
12
I had the pleasure of visiting
@LMStudioAI
back in May and meeting the amazing team, including
@yagilb
. He’s such a generous founder who was incredibly supportive of me during my early career. They ship with passion and elegance. Everything they do is driven by a desire to make

After months of work, and with the help of our awesome community, we're excited to finally share LM Studio 0.3.0! 🎉
🔥 What's new:
- Built-in Chat with Documents, 100% offline
- OpenAI-like 'Structured Outputs' API with any local model
- Total UI revamp (with dark/light/sepia
56
162
778
1
0
12
It really is a monster. 32B that competes with 72b Qwen is a big deal.
To finetune the model, you can use Axolotl
@winglian
or Llama Factory
@llamafactory_ai
as usual. Wing has tested it out and everything works perfectly!
0
2
18
0
0
12
Olmo is a big deal. Truly open SOURCE. Datasets, scripts, architecture, weights. Everything.

0
1
11
Take my money.
Super proud to announce my new book: the LLM Engineer's Handbook 👷
I think we've built something special with
@iusztinpaul
and Alex Vesa, focused on best engineering practices, reproducible pipelines, and end-to-end deployment. Basically everything that is currently lacking in

26
133
894
1
0
12
🧑🍳
You’ve heard of ✨Arcee-Nova✨ – our highest-performing open-source model, with performance approaching GPT-4 from May 2023, marking a significant milestone.
Well, now, get ready for the enterprise-grade version, 🎇SuperNova🎇
Here are the key features of Arcee-SuperNova:
💵
0
5
37
0
2
12
Arcee-Lite was a last minute addition, and the readme/GGUFs will be updated later today.

1
0
12
Excited for this.
Announcing OpenChatML. Dolphin will follow this from now on.
Go ahead, reply with the xkcd comic, I know you're gonna.
But then read the thing and tell me what you think, love your ideas and get something good out there. PRs and discussions welcome.

28
43
328
1
0
12
These models are wildly impressive.

Along with Core, we have published a technical report detailing the training, architecture, data, and evaluation for the Reka models.


2
63
368
0
0
12