

Emily Li
@EmilyLiJiayao
Followers
503
Following
713
Media
30
Statuses
186
@acadiaai , @zfellows_ | cs @ @carnegiemellon | prev research @modern_ai , ml @ evolution_devices |
San Francisco, CA
Joined May 2022
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Cheney
• 509910 Tweets
Michigan
• 165321 Tweets
England
• 136011 Tweets
YEONJUN
• 123060 Tweets
Ireland
• 117980 Tweets
Lookman
• 34058 Tweets
金メダル
• 33289 Tweets
リスアニ
• 29895 Tweets
Grealish
• 27821 Tweets
Gordon
• 24858 Tweets
Big House
• 22855 Tweets
Arkansas
• 20700 Tweets
#MustafaKamalinAskerleriyiz
• 19275 Tweets
Super Eagles
• 18417 Tweets
Lee Carsley
• 17323 Tweets
All Blacks
• 15581 Tweets
Waka
• 15260 Tweets
Penn State
• 15154 Tweets
Ann Arbor
• 11853 Tweets
Boniface
• 11118 Tweets




















Pinned Tweet

Super excited to introduce 🌳Acadia (
@AcadiaAI
) Playground, an interpretable data exploration tool to understand your evaluation data’s quality and help unlock insights into model performance using AI!
🧵
12
21
148
was wondering why my disk was so full that even git wasn't working and then realized that i have 77 GB of huggingface models cached locally oops

2
1
45
super thrilled to join the
@Contrary
squad as a VP and work with so many brilliant & fun ppl!

Thrilled to welcome our newest cohort of Venture Partners to the Contrary family! With nearly 1300 applications, this year was our most competitive yet.
We’re excited to work with you all to meet and invest in the next generation of exceptional founders and companies.
We also

8
10
88
0
0
26
from last minute late night ideas to fruition, the beautiful Figma offices to the inspiring ppl. true thanks
@hackclub
and the Assemble team for making things happen!
#assemble22
#sf



2
0
19
what are good "chat with a large code base" tools out there?
5
0
11
not tagged but excited to have worked on this
@AGIHouseSF
!

3/ Hierarchical semantic clustering
Clustering scheme that generates an interconnected hierarchy that links ideas together into a single post
Consolidate your notes into a blog post
🥇First place
@JvNixon
@_nathanmarquez_
@zvhgpyxqtnys


1
2
25
2
0
9




the most sf imagery from today is seeing two ppl squeeze into a waymo front seat and another waymo blow up from fireworks 😳 anways.. happy lunar new year!🧧


1
0
7
wanna play no-contact hologram style Tic Tac Toe? check out HoloTicTacToe open-sourced at
(initially built for Assemble workshop
@hackclub
)

1
0
7

This is our first of many steps towards bringing interpretability into datasets and evals of growing quantity, complexity, and modalities.
We want to make it easy to unlock high quality signal from the data for many LLM + multimodal applications.
6/6

2
0
7
and it continues…


1
0
6
it’s crazy how bad and unclear the openai docs could be given the amount of users they have

0
0
6
AI companies: introducing our new talented 👏 brilliant 👏incredible👏amazing👏show stopping👏spectacular👏never the same👏model
Also AI companies: you cant use it yet
0
1
6

Here's a new SOTA text-to-image eval metric that's much better at complex compositional reasoning than current ones (e.g CLIPScore, PickScore)!
We also show that it generalizes to video/3d evaluation + released a comprehensive t2visual meta-eval metrics benchmark.
Great to have

In text-to-image generation, evaluating how well the generated image matches the prompt is a major challenge. We address this with VQAScore: a SOTA metric that significantly surpasses CLIPScore, PickScore, ImageReward, TIFA, and more!
VQAScore works especially well on complex

5
39
194
0
1
6
🗃️ Combine "Topics" of choice to filter and inspect individual datums
🧐 Select a model of interest, toggle on failure case mode, log, and visualize where failure cases occurs
2/6

1
0
5
🛝You can define a custom set of task-specific "Topics" of interest, and Acadia Playground visually decomposes a target datasets' content into these categories
🔍 Explore dynamic embedding views of your data points--either embedded by overall semantics or “Topic” slices
1/6
1
0
5
Week 1 ✅ in the beautiful Austin TX. ft some amazing ppl and Archie the owl




1
1
5
current fastest route to agi feels like a data / continual learning problem
0
0
3

2
1
4
what i’ve more than anything else this summer:
ignorance is bliss
1
0
4
pulling out a weekend project from a few mos ago...
Fireo🔥, a neural net tensor shape debugger!
- Useful print statements only
- Only needs pseudo input + model class
- No more hours spent manually tracing through shapes in your dl model dev workflow

0
0
4
@AcadiaAI
Playground is multimodal! We used it to analyze
🖼️ Winoground (VLM image caption matching task)
💻 HumanEval (LLM code generation task)
More details coming soon :)
3/6

1
0
4
and so happened to be neighbors without ever knowing!! you’re cooler 🩷

love meeting online twitter friends irl, makes the world feel so small 🩷
@EmilyLiJiayao
you’re so cool!!

1
0
8
0
0
4

@AcadiaAI
Playground can also be used for:
- Cross comparison of various models to evaluate the best model for your use case
- Identify and target weaknesses in your dataset distribution (such as duplication or misrepresented categories), inform better data curation
4/6
1
0
3

200 on clip is crazy 😱. there’ll probably be a lot more on nerfs / 3d vision once 2d vision is solved (alr feels like it has by gpt4v but opensource still has a long way to go)

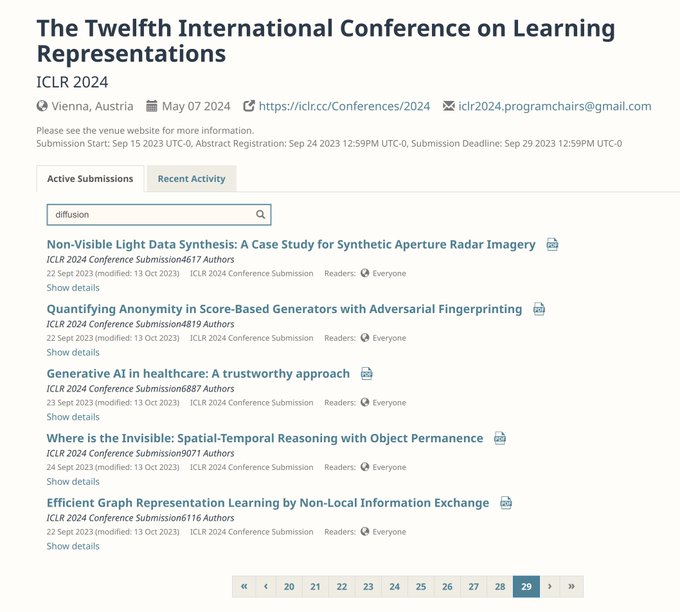
ICLR submissions are online:
Looks like there's:
- ~700 with diffusion in it,
- less than 100 with nerf,
- ~900 LLM
- ~100 chatgpt (8 bard, 16 claude)
- vs ~170 llama (yay)
- ~200 clip (but not "clipping")
- ~200 NLP
- ~750 vision(!?)
17
59
418
0
0
2
all the bad media that starship orbital attempt gets makes me sad. it's such a huge milestone. this rapid iterative process should be encouraged.
1
0
3
If you’re interested in using this for a particular dataset/use case, let us know here:
5/6
1
0
3
demo day was awesome. cv has always been extremely interesting to me but I had never first-hand witnessed how inspiring it may also be for others until today, esp by it’s real world applications that bridge imaginative sci-fi with reality. 🦾
#gangstaminecraft
0
0
3
@itsandrewgao
yea and i wonder how of it is scaling parameters/more training data vs consequential architecture improvements
0
0
2
new competitor AI org? 🤔

2
0
3
this year felt like two years in one. feb 22 doesn't sound like too long ago but when I look back at pictures, it feels like so long ago
0
0
2
1
0
3
when reading research papers, isn't it so annoying to click the link to see the citations but then have to scroll all the way back up or am i missing out on something?
1
0
3
data efficient & smaller models >>

JUST IN: Meta AI introduces LLaMA, a 65B parameter LLM.
LLaMa only relies on publicly available data and outperforms GPT-3 on most benchmarks despite being 10x smaller.

28
335
2K
1
0
3
@itsandrewgao
the swin transformer for example. also, although the naive attention’s work is in order n^2, multi-headed attention/parallelize-ability makes the span closer to linear or logn.
0
0
2
reliable models only result from robust evaluations and metrics. what are (relatively) non-subjective ways to eval generative models or is that just its nature?
0
0
2
@YiMaTweets
hmm feels like it's more prior ⊆ latter. classification/recog. are discriminative tasks whose objective is to learn conditional prob distribution P(X|Y) aka decision boundaries, which is a subset of generative models that learn a joint distribution P(X,Y) where we sample from
1
0
2
@akbirthko
awesome, this was what i was leaning towards. but in this case, what is the point of even having different heads if their end result is concatenated together anyways b4 the linear layer? don't the q, k, v operate independently between the different hidden dims anyway?
1
0
2
what i learned this past week:
- i love with all of my heart
- dunning kruger's effect is too real
- context switching is helpful for project fatigue
0
0
2




@HaoliYin
I've actually thought about this b4 haha! I feel like generating accurate and robust 3d mesh/point cloud/surface is pretty difficult and unsolved problem.
1
0
2
0
0
2
0
0
2
currently playing with
@runwayml
's gen-2 video gen models -- definitely something going on
"A baker pulling freshly baked bread out of an oven in a bakery"
send in some prompts👇
1
0
2
twitter >> tiktok >> insta content suggestion algorithm-wise (imo)
unasked for review - 🧵
1
0
2
@MarioKrenn6240
Due to the influx of papers, bec it's rare for any AI researcher to have read every single paper in their relative subdomain, there're undoubtedly lots of overlapping "novelties." So even just having a systematic approach for tracking defs and training paradigms would be helpful
0
0
2
these are so hard to remember🥲


0
0
2
Getting sick while living alone makes me miss my parents so much more 🥲
0
0
2
@tengyuma
@HongLiu9903
@zhiyuanli_
@dlwh
@percyliang
@StanfordAILab
@stanfordnlp
@StanfordCRFM
@Stanford
pytorch compatibility would encourage usage!
1
0
1
been waiting since aug 2020 😭

IT IS OFFICIAL!!! The world’s biggest, most powerful rocket ever, will attempt its first launch on the morning of Monday, April 17th!!! We have our stream ready to go with some amazing views and incredible audio to help bring you along!
157
758
7K
0
0
1
I asked dalle3 to generate myself wearing a sweatshirt I used to wear a lot.
and no i don't actually look like this...

1
0
2
@gdb
increase in RPD limits; random server errors occur at times; browser version feels like it’s much more willing to describe; log probs would be great!
1
0
1
wouldn't it be nice if we could also plot graphs in w&b after the model is trained? sometimes i just forget to run a cell
0
0
2
imagine if there exists an arXiv that consists of papers/logs of project ideas that failed or went nowhere. that way, actual innovation might progress much faster.
2
0
2
@O42nl
actually, the W_Q, and W_K don't have to be square matrices, they just have to be d_model x d_k, and W_V has to be d_model x d_v. d_k doesn't have to equal to d_v, but by convention it is, right?
1
0
1
1
0
1
quick technical question: does increasing # of heads in the transformer MSA increase param count? i've gotten mixed answers. if this is implementation dependent then is there a standard? for most implementation i've seen (pytorch & swin) the answer seems to be a no.
3
0
1
Apart from intention-based factors such as company direction and algorithm design, it’s interesting to note the dissimilarity of the current knowledge transfer ability bet. natural language-based (twitter) vs vision/img/vid based (insta, tiktok) mediums. language is clearly ahead
2
1
1
@HaoliYin
@alexfmckinney
i say try the former, if not good enough then the latter, we def have stronger text embedding models than vision. also i'm interested to see how close CLIP img encoder embeddings are to img->description->CLIP text embeddings, perhaps that could be a finetuning objective for CLIP
1
0
1
guess it’s

0
0
1
why is this soo true...is definitely something that wastes a lot of my time

The software engineering aspect of deep learning repos I've been watching closely is how they store, catalogue, override, manage and plumb hyperparameter configs. Have come to dislike argparse, YAMLs (too inflexible), and fully enumerated kwargs on classes/defs. Any favorites?
193
170
2K
0
0
1
so true 🥲

0
0
1
simple math shows that training
@MetaAI
's llama would have costed anyone ~ $4 mil to train according to A100's global pricing of $4/hr/GPU. 504hrs *$4*2048 GPUs. and it is only 65B params

1
0
1
seem to split up the hidden dim in attention up into nheads, and each heads operates on a different set of Q, K, V weights. and at last a linear layer is applied to the concatenated outputs from each head
0
0
1