
Ekdeep Singh Lubana
@EkdeepL
Followers
1K
Following
3K
Statuses
404
Postdoc at CBS-NTT Program on Physics of Intelligence, Harvard University.
Boston
Joined December 2017
Paper alert—accepted as a NeurIPS *Spotlight*!🧵👇 We build on our past work relating emergence to task compositionality and analyze the *learning dynamics* of such tasks: we find there exist latent interventions that can elicit them much before input prompting works! 🤯
10
90
594
RT @davidbau: DeepSeek R1 shows how important it is to be studying the internals of reasoning models. Try our code: Here @can_rager shows…
0
52
0
@charles0neill @ch402 Yup! I'd say his interpretation is more like disentanglement literature: latent factors in a data-generating process that can be independently intervened on.
0
0
2
@TankredSaanum @can_demircann This is really cool work! Quickly wanted to highlight a paper of our own where we found similar results (we'll be at ICLR if you guys would like to chat!)

New paper! “In-Context Learning of Representations” What happens to an LLM’s internal representations in the large context limit? We find that LLMs form “in-context representations” to match the structure of the task given in context! 1/n
1
0
5
Wild that this paper hasn't been doing rounds in the SAE / MI community......

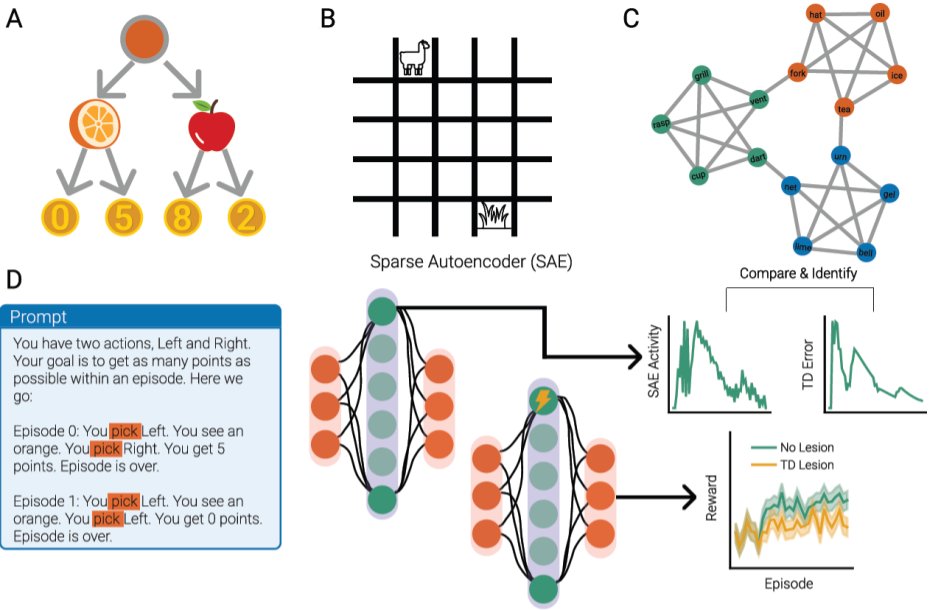
Can LLMs do reinforcement learning in-context - and if so, how do they do it? Using Sparse Autoencoders, we find that Llama 3 relies on representations resembling TD errors, Q-values and even the SR to learn in three RL tasks in-context! Co-lead with the inimitable @can_demircann
0
0
10
Hadn't read this before: a really cool post that captures a lot of my thinking around SAEs, specifically distinguishing between a local vs compositional code and how ambiguity will cause multitude of specialized latents!
1
11
91
Now accepted at NAACL! This would be my first time presenting at an ACL conference---I've got almost first-year grad school level of excitement! :P
Paper alert––*Awarded best paper* at NeurIPS workshop on Foundation Model Interventions! 🧵👇 We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
0
4
49
We will be presenting ICLR at ICLR!
New paper! “In-Context Learning of Representations” What happens to an LLM’s internal representations in the large context limit? We find that LLMs form “in-context representations” to match the structure of the task given in context! 1/n
0
0
51
RT @MLStreetTalk: We just dropped our show with @LauraRuis where we debate whether LLMs are like databases, or whether they construct new "…
0
32
0
And of course this goes vice versa 😎

Absolutely love this work (anyway not a bad idea to turn on scholar alerts for Ekdeep's papers as every one of them shapes my understanding)
0
0
3
Come say hi if you’re in Bangalore / IISc tomorrow!

Welcome to a CDS-KIAC talk on 'Formal Models for Sudden Learning of Capabilities in Neural Networks' by Ekdeep Singh Lubana, Postdoctoral Fellow at CBS-NTT Program, Harvard University. Date & time: 9 Jan 2025, 04:00 to 5:00 PM Venue: 102, CDS dept, IISc

0
2
20
RT @gaotianyu1350: Introducing MeCo (metadata conditioning then cooldown), a remarkably simple method that accelerates LM pre-training by s…
0
43
0
@SadhikaMalladi And to said theorists, please help us figure out what’s going on under the hood here! :D
0
0
4
This project was an awesome collaborative effort with everyone bringing something very different to the table! Thanks to my co-authors @corefpark, @a_jy_l, @YongyiYang7, @MayaOkawa, @kento_nishi, @wattenberg, @Hidenori8Tanaka!
0
1
5